Before Review
진짜 오랜만에 X-Review 인 것 같습니다. 이번에는 비디오 논문이 아닌 이미지 논문을 읽게 되었습니다. 요즘 Masking Model 들이 많은 연구가 이루어지고 있어서 저도 한번 읽게 되었습니다. 이번에 MAE를 읽고 VideoMAE도 읽을 계획입니다.
참고로 Kaiming He 선생님의 연구인데 참 연구를 잘 하시는 것 같습니다. 연구에 손 대시는 것마다 굵직한 연구를 하시는 것을 보면 재능의 영역인가..? 의문을 들게 만드는 사람인 것 같습니다.
이미지 도메인의 논문은 또 오랜만이라 논문의 모든 디테일을 이해하진 못했지만 부족한 부분은 다른 논문들도 읽어보면서 차근 차근 채워나가도록 하겠습니다.
Introduction
딥러닝이 2012년에 주목을 받기 시작하고 지난 십 년동안 딥러닝 모델들은 많은 발전이 있었습니다. 그러한 과정에서는 이제는 100만장의 이미지에도 과적합 될 정도로 모델의 크기가 커져버렸습니다. 모델의 크기가 커져 과적합 발생을 막기 위해 학습 시킬 수 있는 label data를 더 가져오는 것보다는 연구자들은 unlabeled data 상황에서도 효과적으로 표현을 학습할 수 있는 연구들을 하기 시작합니다.
대표적으로 GPT나 BERT를 예시로 들 수 있습니다. GPT는 autoregressive 형태로 다음 단어를 계속 예측하는 형태로 문제를 풀고 BERT는 단어를 마스킹하고 예측하는 형태로 문제를 해결합니다. 이러한 방식은 이제 100억개의 파라미터를 가지는 대용량 모델에도 일반화된 표현을 학습시키는 것이 가능하게 만들었습니다.
하지만 이런 BERT의 아이디어를 Computer Vision 도메인에 가져오는 시도는 여럿 있었지만 NLP 만큼의 성공을 거두지는 못했습니다. 저자는 이러한 원인에 대해 세가지 분석을 내놓습니다.
Computer Vision 도메인에서는 Convolution이 지배적이었기 때문입니다.
다들 Convolution의 연산 과정 자체는 알고 있을 것이라 생각합니다. 고정된 크기를 가지는 Filter(Kernel)을 가지고 local region에 대해서만 연산이 진행되는데 이러한 구조적 특성 때문에 NLP에서 사용하는 mask token이나 positional embedding을 추가하기 어려웠습니다. NLP와 Computer Vision 간의 이런 구조적 차이 때문에 문제가 있었지만 Vision Transformer(ViT)의 등장으로 이제는 해결 가능하다고 하네요.
NLP와 Computer Vision은 정보 밀집도 측면에서 차이가 있기 때문입니다.
NLP의 경우 문장에서 단어 하나가 가지는 semantic information은 상당합니다. 그렇기 때문에 학습 과정에서 단어에 대해 masking을 많이 하지 않아도 모델 입장에서는 충분히 reasoning 능력이 길러진다는 것이죠. Computer Vision의 경우 이미지에서 픽셀 하나가 가지는 semantic information은 어떨까요? 그렇게 크지 않을 것입니다. 픽셀 하나는 거의 없다고 봐도 무방하죠. 그렇기 때문에 모델 입장에서 학습을 하는 관점에서 픽셀 몇 개 지우는 것은 trivial solution(자명해)에 수렴할 수 있겠죠. 즉 Computer Vision 도메인에서 모델을 충분히 학습 시키기 위해서는 NLP에 비해 masking을 많이 해야 의미가 있다고 주장합니다. 실제로 제안된 MAE(Masked AutoEncoder)도 75%를 masking 했다고 하네요.

위의 그림을 보면 가장 왼쪽이 Masking된 이미지 가운데가 reconstruction 된 이미지 오른쪽이 원본 이미지 입니다. 결국 저렇게 이미지에 빈틈을 만들어두고 모델이 제한된 정보만을 가지고 원래의 정보를 복원시키는 과정을 반복하다보면 이미지 도메인을 관통하는 일반적인 표현을 학습할 수 있다고 보는 것 같습니다.
마지막으로 텍스트와 이미지는 서로 디코더의 역할이 다르게 작용합니다.
텍스트의 경우 디코더를 통해 missing word 에 대해 예측을 수행합니다. BERT가 이런 방식으로 학습 합니다. 여기서 missing word는 아까도 말했지만 상당히 semantic 하다고 볼 수 있습니다. 하지만 이미지의 경우 디코더를 통해 pixel의 intensity를 예측합니다. 텍스트에 비해 semantic gap이 존재하겠네요. 따라서 저자는 이미지의 경우 학습된 latent representaion의 semantic level을 결정하는데는 디코더의 역할이 중요하다고 주장합니다. 그렇기 때문에 encoder와 decoder의 구조를 비대칭적으로 가져갔다고 설명합니다. 인코더의 경우 VIT-16을 기본으로 사용하고 디코더의 경우도 transformer block을 사용했는데 비교적 lightweight하게 설계했다고 합니다.
바로 이어서 제안된 방법에 대해서 설명을 할 예정인데 굉장히 간단합니다. 다만, Transformer나 Vision Transformer에 대한 배경 지식이 없다면 조금 낯설 수 있습니다. Transformer 같은 경우는 제가 이전에 리뷰했던 X-Review를 참고하시면 되고 Vision Transformer는 홍주영 연구원이 이전에 잘 정리 했기 때문에 잘 모르신다면 참고하시길 바랍니다.
Approach
아래의 그림이 제안된 방법론의 구조를 나타내는 그림입니다.
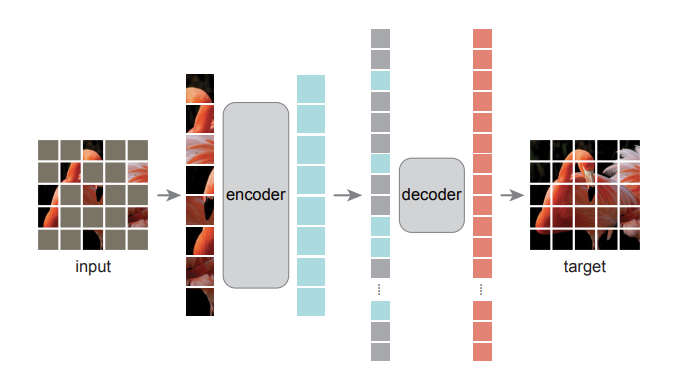
Patch 단위로 나뉘어진 입력에 대해서 Random으로 마스킹을 진행합니다. 가장 왼쪽 그림에서 input 부분을 보면 군데 군데 비어있는 것을 확인하실 수 있을 것입니다. 그리고 여기서 마스킹 되지 않은 visible token에 대해서만 ViT encoder를 태워줍니다. 그림으로 보면 확인할 수 있습니다.
이렇게 ViT encoder을 거쳐서 나온 visible token 들과 마스킹 된 token들을 모두 모아 디코더의 입력으로 넣어줍니다. 이때 모든 token 들에는 positional embedding이 더해져서 디코더의 입력으로 들어갑니다. 위치 정보 역시 추론 과정에서 중요하기 때문이겠죠.
디코더에서는 reconstruction이 일어나는 데 최종적으로 디코더를 거쳐서 나온 output은 원래 이미지와 동일한 사이즈로 reshape 될 수 있도록 만들어진다고 보시면 됩니다. 결국 인코딩 하는 과정은 원래 visible token에서 어떤 정보에 집중을 해야 하는지를 학습한다고 보면 되고 디코딩 과정에서는 인코딩된 visible 정보를 토대로 비어있는 정보를 어떻게 복원 해야 하는지 학습한다고 볼 수 있겠습니다.
원래 이미지와 복원된 이미지간의 pixel level로 MSE Loss를 가지고 역전파를 수행하는데 이때 마스킹된 패치 영역에 대해서만 Loss를 계산한다고 합니다. 이는 온전히 실험을 통해 복원된 모든 픽셀을 하는 것보다 마스킹된 영역에 대해서만 Loss를 계산하는 것이 더 좋은 결과를 만들었기 때문에 했다고 하네요.
Masekd AutoEncoder의 디코더는 사전 학습 단계에서만 사용이 되고 사전 학습이 끝난 후에는 인코더만을 가지고 image representation을 생성합니다. 저자가 제안하는 기본 구조는 디코더가 인코더의 10% 수준으로 computation을 가져간다고 합니다. 인코더에 비해 상당히 가벼운데 이렇게 되면 인코더에서는 애초에 25%에만 해당하는 visible token 만처리하고 디코더는 애초에 연산량이 별로 없기 때문에 저자가 제안하는 MAE는 꽤나 효율적인 학습 구조를 가지고 있는 것 같습니다.
방법론적인 내용은 이게 전부입니다. 상당히 간단해서 이해하는데 어려움은 없었습니다.
생각해보면 BERT가 등장하고 나서부터 분명히 masking prediction에 관련한 연구들이 분명히 나왔어야 했을텐데 이번 논문이 약간 교통정리(?)를 한 기분이 드네요.
Experiments
실험 부분 이어서 가겠습니다. 논문 자체 분량도 방법론적인 내용보다는 실험, 분석적인 내용이 더 많은 비중을 차지하고 있어 이쪽 글이 길어질 것 같습니다.
Baseline
ViT-Large 모델을 사용하고 있는데 참고로 이 모델을 굉장히 크고 overfit 하기도 쉬워서 지도학습 기반으로 scratch 단계에서 학습하는 것이 굉장히 어렵습니다.
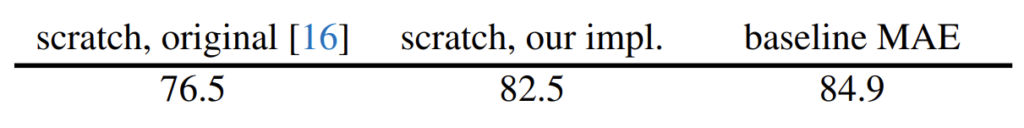
scratch, original(76.5%)는 ImageNet Validation에 대해서 원래 ViT 논문 성능입니다. sractch, our impl(82.5%)은 Facebook에서 여러가지 방법을 동원해서 학습을 한 성능입니다. 이러한 상황에서 논문이 제안하는 MAE를 통해 사전학습을 하고 image classification으로 finetuning을 했을 때는 84.9%가 나오고 있습니다.
Main Properties
자 이제 MAE를 본격적으로 분석하는 ablation이 진행됩니다.
Masking Ratio
일단 Masking Ratio 입니다. 놀랍게도 굉장히 높은 ratio 부근에서 가장 좋은 성능을 보여주고 있습니다. finetuning과 linear probing 둘 다 70~80% 사이에 좋은 성능을 보여주고 있는데 앞서 텍스트와 이미지의 의미론적 차이로 인한 masking ratio의 차이가 이런 실험을 통해 보여지고 있는 것 같습니다.
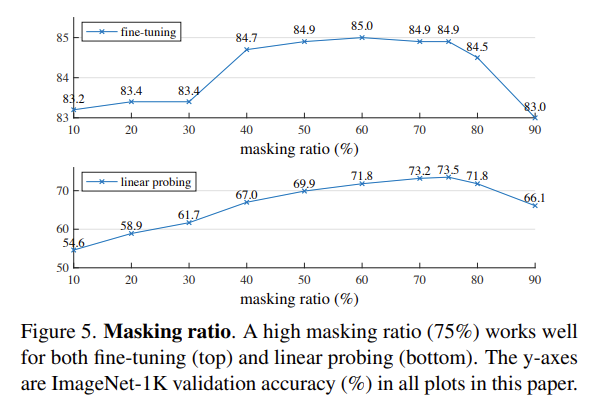
참고로 이 75%라는 수치는 다른 computer vision related work의 수치인 20~50% 보다 더 높은 수치로 MAE는 encoder 단에서 25%의 token 만을 연산하기 때문에 연산량이 적다는 것을 다시 강조하고 있습니다.
Decoder Design

다음으로는 Decoder Design 입니다. 간단하게 Transformer block의 depth나 width를 가지고 ablation을 진행하였네요.
우선 depth 먼저 살펴보겠습니다. finetuning과 linear probing 간의 차이가 조금 있네요. finetuning의 경우 decoder의 transformer block을 몇 개를 사용하든 크게 차이가 있지 않네요. 특히 block 1개를 사용한 것과 8개를 사용한 것이 차이가 없다는 점이 놀랍습니다. 이렇게 되면 사전학습의 시간을 더 효율적으로 단축시킬 수 있겠네요. 하지만 linear probing을 할 때는 decoder의 depth가 충분히 깊어야 어느정도 성능이 올라오는 것 같습니다.
논문에서 이에 대한 설명으로는 recognition과 reconstrunction task가 다르기 때문입니다. encoder와 decoder는 둘 다 reconstruction task를 target으로 사전학습이 되었습니다. 이 때 finetuning의 과정으로 image recognition task를 학습하면 encoder를 다시 recognition에 맞춰 최적화 시킬 수 있겠죠. 하지만 linear probing의 경우 reconstruction으로 사전학습된 encoder를 freeze 시키고 linear layer 만 학습 시키기 때문에 이와 같은 차이가 발생한다고 합니다.
ViT-Large의 경우 Encoder는 1024의 차원의 벡터를 입력으로 받는 반면 Decoder는 512의 차원만을 가지고도 가장 높은 성능을 보여주고 있습니다. 이를 통해 Encoder, Decoder를 비대칭적으로 설계할 수 있으며 Decoder를 좀 더 lightweight하게 가져갈 수 있음을 보여주고 있습니다.
Mask token
다음으로 Mask token에 대한 ablation 입니다.

앞서 사전 학습 단계에서 mask token이 아니라 visible token만을 가지고 학습을 했었습니다. mask token 도 모두 encoder에 입력으로 넣어주고 loss 도 모든 token에 대해서 계산을 해준다면 성능이 떨어지는 것을 볼 수 있습니다. 이게 inference 단계에서는 mask 된 이미지가 안 들어오기 때문에 오히려 사전 학습 때 mask token을 사용하면 오히려 성능을 떨어트리고 있는 모양입니다.
결국 mask token을 Encoder 단에서 제거할 수 있으니 연산량이 줄어들고 Large model에 대해서도 확장이 가능해집니다.
Reconstruction target
그리고 Reconstruction task에 대해서도 ablation을 진행합니다.
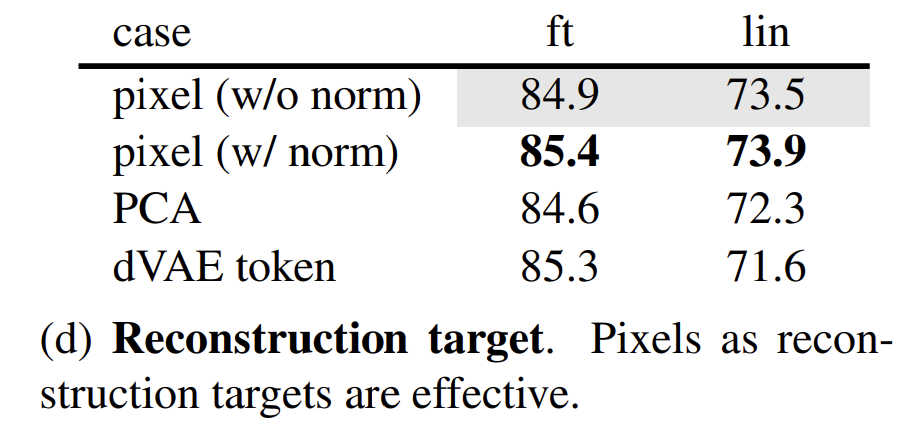
우선 pixel 단위의 regression task 기준으로 0~255 즉, pixel normalization을 하지 않은 경우와 0~1로 pixel normalization을 한 경우 비교해보면 normalization을 한 경우가 근소하게 더 높은 것을 확인할 수 있습니다.
PCA를 가지고도 reconstruction을 할 수 있는데 이때 PCA 계수를 예측하는 방식으로 문제를 해결하면 성능이 더 낮게 나오는 것을 확인할 수 있습니다.
dVAE token이라고 해서 저도 자세히는 모르지만 BEiT에서 했던 방식으로 token의 종류를 예측하는 문제로 풀었을 때 기존 베이스라인 대비 더 낮은 성능을 볼 수 있습니다. 특히 이 방식은 사전학습 이전에도 tokenizer를 학습 시켜야 한다는 overhead가 존재하기 때문에 저자가 제안하는 pixel reconstruction 방식이 더 효율적인 방식이라 볼 수 있습니다.
Data augmentation
Data augmentation도 ablation을 진행했는데 MAE 같은 경우는 data augmentation에 크게 영향을 받지 않는다고 하네요. Self-Supervised Learning에서 주목을 받고 있는 Contrastive Learning의 경우 data augmentation이 중요하게 작용하는 반면 MAE 같은 경우는 augmentation에 의존적이지 않다고 합니다.

그런데 이미 Random Masking 자체가 augmentation 역할을 수행하기 때문에 의존적이지 않는 성질이 있다고 하네요.
Mask sampling strategy
Mask sampling 전략에 대해서도 ablation이 있는데 직관적으로 Random 하게 해주는 것이 학습 다양성 측면에서 가장 좋다고 합니다.

아래의 그림을 보면 차이를 확인할 수 있습니다.

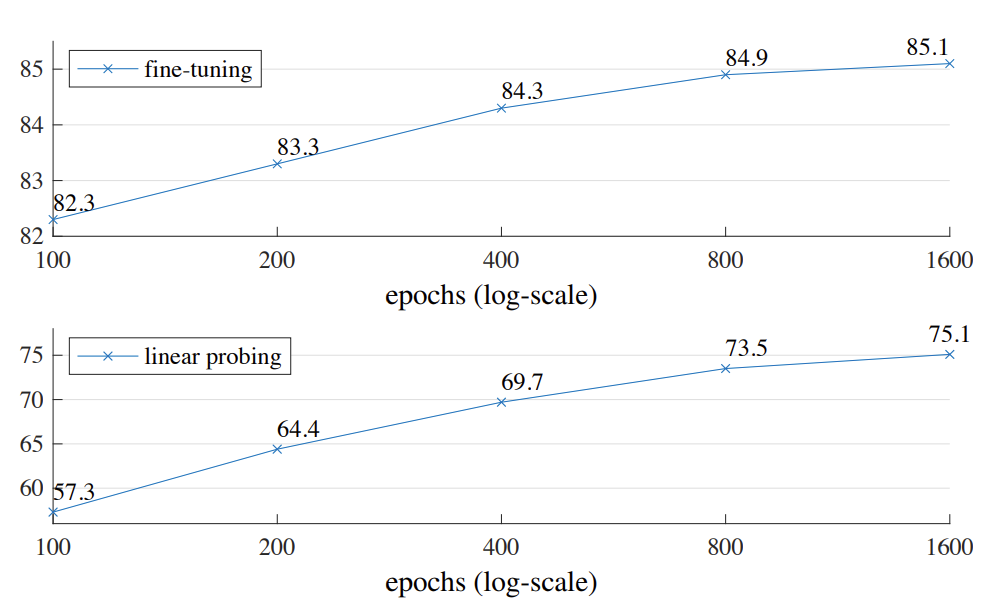
Training schedule
아래의 그래프를 보면 training epoch에 따른 수렴 정도를 나타내고 있습니다. 궁금한 것은 논문의 베이스는 800 epoch로 설정 했는데 그래프 추이를 보면 미세하지만 1600 epoch 에서도 아직 수렴을 하지 않은 듯한 경향성을 보여줍니다. facebook 이면 gpu도 남아 돌텐데 왜 saturation을 해보지 않았던 걸까요? 이 부분은 조금 궁금하네요.
Comparisons with Previous Results
제안된 방법론에 대한 ablation은 끝났고 이제 다른 사전 학습 모델과의 벤치마킹입니다.
Comparisons with self-supervised methods
일단 다른 Self-Supervised 방법론들과의 벤치마킹 입니다.
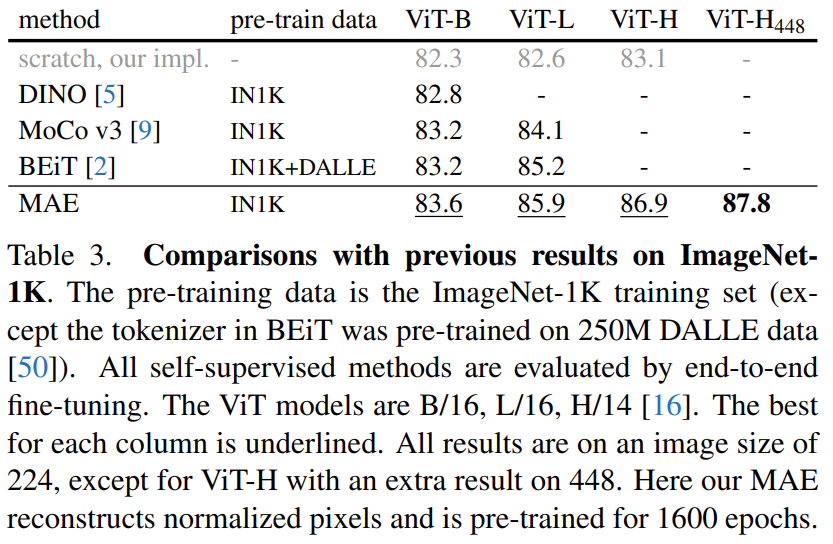
여기서 두가지 확인할 수 있는데 우선, Self-Supervised 방법론들 중에서 가장 정확도가 높다는 것과 ViT-Huge 모델에서도 SOTA를 달성했다는 것입니다.
그나마 가장 비슷한 BEiT와도 비교를 해보면 BEiT 같은 경우는 tokenizer를 미리 학습 시켜야 하고 이 과정에서 DALLE 이미지도 사용하는 cost가 있기 때문에 저자가 제안한 MAE가 훨씬 더 간편하고 효과적인 방법입니다.
또한 ViT-Huge 모델에 대해서도 기존의 SOTA는 512 size를 가지면서 vanilla ViT-H가 아니라 더 advanced model을 사용해야 87.1% 였는데 MAE는 512보다 작은 input size인 448을 가지면서도 vanilla ViT-H 만으로도 87.8%를 달성하였으며 이는 더 좋은 network를 사용하면 더 높은 성능을 기대할 수 있음을 시사합니다.
저자의 방법론이 간단했음에도 이렇게 좋은 성능을 보여주는 것이 인상 깊습니다.
Comparisons with supervised pre-training
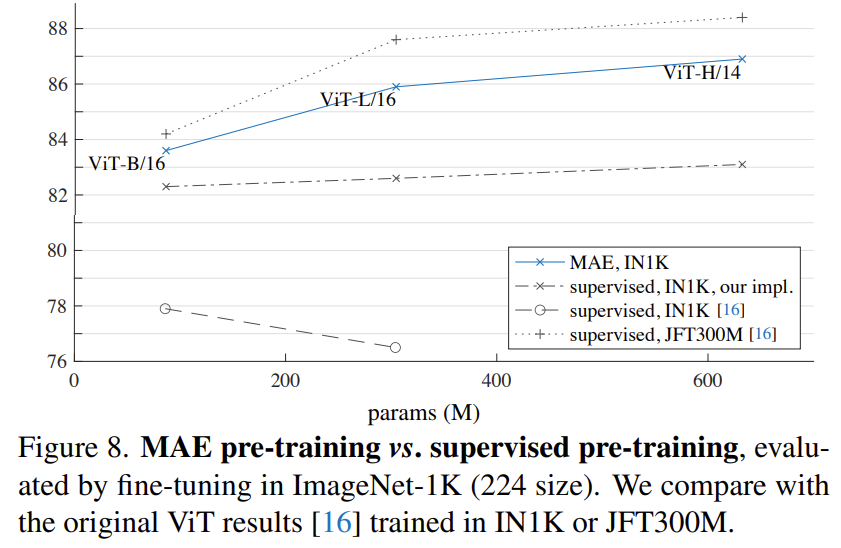
지도 학습 기반의 사전 학습과도 비교하고 있습니다. 우선 가장 아래의 그래프는 원래 ViT 논문이 처음 제안됐을 때의 사전 학습 성능인데, 모델이 커져갈 때 성능이 낮아지는 것을 확인해보면 overfit이 일어나는 것을 알 수 있습니다. 그래서 facebook 연구진이 ViT의 학습 방식을 조금 개선한 그래프가 그 위에 있는 그래프(our impl)입니다.
그리고 MAE의 그래프가 그 위에 있죠. 특히 MAE의 그래프 추이는 model의 크기가 커져도 성능이 준수하게 향상되는 것을 보아 좋은 확장성을 가지는 방법론임을 보여주고 있습니다.
한 가지 아쉬운 것은 Self-Supervised의 장점이 데이터의 갯수에 구애받지 않는다는 점인데 ImageNet1K만을 가지고 사전학습을 한 것이 아쉽습니다. MAE의 끝이 어디까지일지 궁금하네요..
Partial Fine-tuning
다음은 부분적인 fine-tuning에 대한 실험입니다. 논문에 “단순히 Linear-probing 만으로 protocol을 점검하는 것은 옳지 않다.” 라는 저자의 주장이 있습니다. 그래서 down-stream task로 학습할 때 Linear layer가 아니라 끝에서 몇 개의 Layer를 추가적으로 fine-tuning 할 지에 대한 실험을 진행했는데 결과는 아래 그래프와 같습니다.
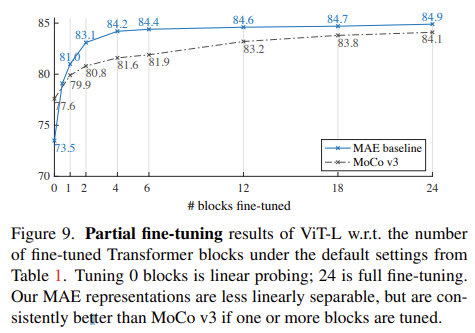
그래프의 x 축은 추가적으로 finetuning 하는 block의 갯수입니다. 0개라는 것은 Linear probing 이라는 것이고 1개라는 것은 Linear probing + 가장 뒷단 block 1개를 finetuning 하는 것이다.
MAE의 그래프인 파란색 그래프의 추이를 보면 하나만 더 추가해서 finetuning을 해도 73.5->81.0 되는 것을 볼 수 있습니다. MoCo 같은 경우는 이러한 증가폭이 적은 것을 볼 수 있습니다. 또한 MAE 같은 경우는 block 4개만을 추가해서 fine-tuning 해도 full fine-tuning과 비슷한 성능을 얻는 반면 MoCo는 갯수에 따른 성능 gap이 분명하게 존재합니다.
이러한 Partial fine-tuning 실험은 분명히 feature의 표현력을 검증하는 실험으로써 단순히 Linear probing 말고도 이렇게 검증을 해야 한다는 것을 저자는 주장합니다. MoCo 같은 경우는 Linear probing의 결과는 MAE 보다 높았지만 이런 non-linear representation 면에서는 다소 약한 모습을 보여주고 있네요.
Transfer Learning Experiments
자 이제 Image Classification 말고도 다른 Downstream task에서도 성능을 확인하여 좀 더 feature representation의 generality를 검증해보도록 하겠습니다.
Object detection and segmentation
detection과 segmentation을 동시에 할 수 있으면서 동시에 kaiming He 선생님의 또 다른 걸작인 Mask R-CNN을 가지고 실험을 진행했네요. COCO dataset 에서 진행됐습니다.
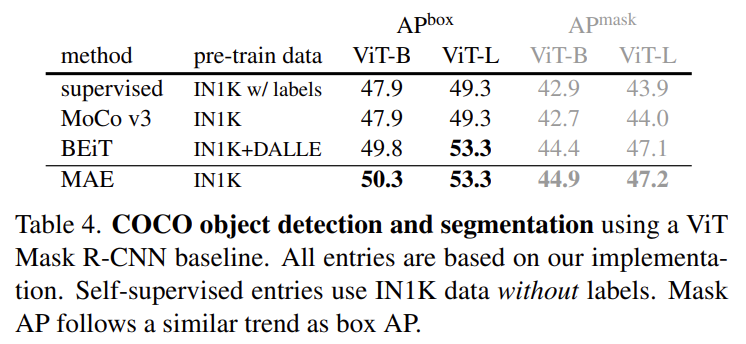
Supervised, Self-Supervised 비교할 것 없이 MAE의 사전 학습 방식이 가장 좋은 성능을 보여주고 있습니다. 저자가 계속 BEiT와 비교하고 있는데 classification 뿐만 아니라 detection과 segmentation task에서도 pixel 기반의 MAE가 token 기반의 BEiT 보다 더 좋은 결과를 보여주는 것을 강조하고 있습니다.
semantic segmentation
다음으로 semantic segmentation에 대해서도 실험을 진행했습니다. 특이사항은 없고 가장 성능이 높네요.
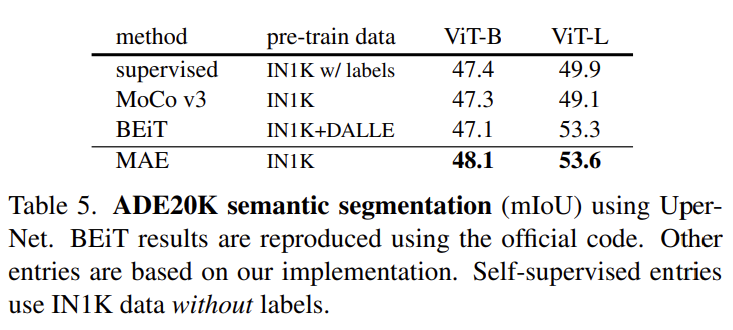
COCO dataset에서의 경향성이 ADE20K라는 데이터셋에서도 유지가 되고 있습니다. feature representation의 generality가 상당한 것 같네요.
Classification tasks
다음으로 Image Classification 인데 ImageNet으로 사전 학습 하고 다른 데이터로 fine-tuning 한 실험입니다.

이전의 SOTA 들을 높은 폭으로 상회하는 결과를 보여주고 있고 특히 Places205, Places365라는 데이터셋에서는 이전의 SOTA가 훨씬 더 많은 사전학습 데이터를 사용했음에도 불구하고 MAE가 더 높은 성능을 보여주고 있습니다.
Pixels vs token
본 논문의 마지막 실험 입니다. 실험 섹션에서 계속 비교했던 BEiT와의 직접적인 비교를 정리한 테이블이라 보면 되는데 아래와 같습니다.
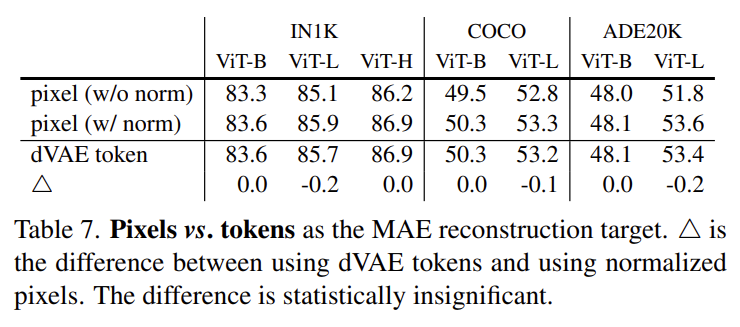
결론적으로 어떤 down-stream task라 할 지라도 MAE의 pixel reconstruction 방식이 BEiT의 dVAE token prediction 방식 보다 동등하거나 더 높은 결과를 가져가기에 불필요하게 tokenizer를 학습해야 하는 BEiT 보다 MAE가 더 좋은 방법론이다 이렇게 주장하고 있습니다.
Conclusion
간단하지만 확장성이 좋은 알고리즘들이 요새 딥러닝 연구분야에서 주목을 받고 있습니다. GPT나 BERT가 주목을 받는 이유도 휼륭한 확장성, 일반성을 가지는 것도 있지만 간단한 아이디어로부터 방법론이 설계되었기 때문이라고 생각합니다.
단순히 NLP에서 성공을 거두었다고 해서 그대로 접목하는 것이 아니라 텍스트와 이미지의 차이점에 기인하여 이미지에 최적화된 구조를 제안한 저자의 통찰력에 인상을 받은 논문이었습니다.
벌써 인용수가 1000이 넘는걸 보면 23년도 CVPR은 이 MAE를 가지고 응용한 다양한 논문들이 나오겠네요.
그렇다면 리뷰 여기서 마치도록 하겠습니다.
꼼꼼한 리뷰 잘 읽었습니다.
한가지 궁금한 점이 있는데 리뷰 내용 중
“missing word는 아까도 말했지만 상당히 semantic 하다고 볼 수 있습니다. 하지만 이미지의 경우 디코더를 통해 pixel의 intensity를 예측합니다. 텍스트에 비해 semantic gap이 존재하겠네요. 따라서 저자는 이미지의 경우 학습된 latent representaion의 semantic level을 결정하는데는 디코더의 역할이 중요하다고 주장합니다. 그렇기 때문에 encoder와 decoder의 구조를 비대칭적으로 가져갔다고 설명합니다. 인코더의 경우 VIT-16을 기본으로 사용하고 디코더의 경우도 transformer block을 사용했는데 비교적 lightweight하게 설계했다고 합니다.”
라고 작성해주셨습니다. 대충 pixel level information은 단어보다 semantic 정보가 약하기 때문에 이 gap을 커버해줄 무언가가 필요하다고 저는 이해했습니다. 그럼 여기서 latent representation의 semantic level을 결정한다는 의미가 정확히 무엇이 무엇을 어떻게 한다는 것인가요?
디코더를 통해서 semantic gap을 커버해야 한다는 것인가요? 그러면 디코더를 더 깊게 쌓아서 semantic gap을 메꿔야하는 것이 아닌가요? 아니면 오히려 decoder의 구조를 얕게 쌓아 부족한 decoder의 능력을 encoder가 더 좋은 representation을 가지는 feature를 추출하도록 학습이 된다는 것인가요? semantic gap을 줄이기 위해 encoder와 decoder가 비대칭하다라는 점, 그리고 이 때 decoder가 더 shallow하게 된 점에 대해서 그 이론적 흐름을 따라가지 못하여 질문합니다.
1. 그럼 여기서 latent representation의 semantic level을 결정한다는 의미가 정확히 무엇이 무엇을 어떻게 한다는 것인가요?
=> Encoder로부터 생성되는 latent representation은 pixel이 아닌 vector의 형태를 띨 것이고 이를 pixel로 직접적으로 변환 시키는 것은 Decoder 이기 때문에 pixel 들이 뭉쳐서 만들어내는 semantic information의 level은 Decoder가 조금 더 직접적으로 영향을 미친다는 의미인 것 같습니다.
2. 그러면 디코더를 더 깊게 쌓아서 semantic gap을 메꿔야하는 것이 아닌가요? 아니면 오히려 decoder의 구조를 얕게 쌓아 부족한 decoder의 능력을 encoder가 더 좋은 representation을 가지는 feature를 추출하도록 학습이 된다는 것인가요?
=> 디코더를 얕게 쌓은 것은 아닙니다. Baseline의 경우 Decoder에서도 Transformer block을 8개를 사용해야 finetunign 그리고 linear probing에서도 좋은 결과를 보여주고 있습니다. 비대칭적인 구조는 depth가 아니라 width 면에서 차이가 납니다. Encoder는 1024의 차원을 입력으로 받는 반면에 Decoder는 512의 차원을 입력으로 받기 때문에 연산량 측면에서 차이가 발생하게 되고 좀 더 효율적으로 가져갈 수 있는 것이죠.
제 생각에는 semantic gap을 줄이기 위해서 비대칭적으로 간것은 아니라고 생각합니다. 논문 구절에서 NLP의 경우 Decoder를 MLP와 같이 굉장히 단순하게 쌓는 반면에 MAE의 경우 Decoder를 Transformer Block 8개를 사용하였으니 이러한 차이를 바탕으로 텍스트와 이미지 간의 semantic gap을 줄이는 것이 아닌가 싶네요.
안녕하세요. 임근택 연구원님. 리뷰 잘 읽었습니다.
간단하면서도 좋은 성능을 보이는 것을 보면 리뷰에 적혀있는대로 다양한 응용 연구가 나올 법 하네요.
“이는 온전히 실험을 통해 복원된 모든 픽셀을 하는 것보다 마스킹된 영역에 대해서만 Loss를 계산하는 것이 더 좋은 결과를 만들었기 때문에 했다고 하네요.”라고 방법론 설명에 언급하시는 부분이 있습니다. 이 부분을 mask token 실험 결과와 연계하여 읽으면 될까요? 추가적으로 positional 정보가 중요하다면, mask token을 사용할 경우 얻을 수 있는 이점이 분명 존재했을 것 같은데, 단순히 성능을 제외하고 더 좋은 결과가 나온 것에 대한 설명이 더 있을까요?
1. 네 masking ratio에 따른 연산량에 집중하시면 됩니다.
2. 추가적으로 positional 정보가 중요하다면, mask token을 사용할 경우 얻을 수 있는 이점이 분명 존재했을 것 같은데, 단순히 성능을 제외하고 더 좋은 결과가 나온 것에 대한 설명이 더 있을까요?
=> 제가 질문을 잘 이해를 못했습니다. 일단 positional embedding은 visible token이든 mask token이든 원래 어디에 존재했는지가 중요하기 때문에 positional embedding을 추가했다고 보시면 됩니다.
깔끔하고 꼼꼼한 리뷰 감사합니다.
리뷰를 읽다가 몇가지 궁금점이 생겼네요.
1. ‘따라서 저자는 이미지의 경우 학습된 latent representaion의 semantic level을 결정하는데는 디코더의 역할이 중요하다고 주장합니다. 그렇기 때문에 encoder와 decoder의 구조를 비대칭적으로 가져갔다고 설명합니다.’ 에서 semantice level을 결정하는데 디코더의 역할이 중요한 이유가 뭔지 궁금합니다. 그렇기에 비대칭으로 가져간 이유도 궁금합니다.
2. 실험에서 fine-tunning과 함께 linear probing을 비교합니다. 이 두가지를 어떤 관점에서 차이를 두고 보면 될까요?
3. Experiment-‘이러한 상황에서 논문이 제안하는 MAE를 통해 사전학습을 하고 image classification으로 finetuning을 했을 때는 84.9%가 나오고 있습니다.’ MAE는 모든 실험들은 사전 학습된 ViT를 이용하여 실험이 진행된건가요? 맞다면 해당 기법은 사전 학습 방법을 제안했다고 생각이 드네요.
감사합니다.
1. 아무래도 reconstruction을 직접적으로 수행하는 것이 Decoder이다 보니 중요하다고 보는 것 같습니다. 제가 서술한 정도만의 언급만이 있고 더욱 풍부한 설명은 따로 없어 여기까지만 답변을 드릴 수 있을 것 같습니다.
2. fine-tuning은 MAE의 enocder까지 다시 down-stream task로 학습을 진행하는 것이고 linear probing은 MAE의 encoder는 freeze를 시키고 linear layer만 새로 붙여서 학습 시키는 것을 의미합니다.
3. ViT 같은 경우 원조 ViT 논문에 나온 setting을 유지했다고 하는데 사전학습 단계에서는 Random initialization된 ViT를 사용하기 때문에 MAE도 데이터셋 마다 사전학습 단계예서는 ImageNet Pretrain이 아닌 scratch로 학습하는 것 같습니다.
안녕하세요 근택님 리뷰 잘 읽었습니다. 인공지능 기초 연구들을 잘 알고 있지 못하단 생각에 계속해서 이전 연구들 중 굵직한 연구들을 찾아 공부하고 있습니다. MAE에 대해서도 공부해보고 싶어서 읽게 되었습니다.
NLP에서 단어가 갖는 정보와 이미지에서 픽셀 하나가 갖는 양이 상대적으로 적기 때문에 이미지에서 대해서 마스킹을 통해 충분한 표현이 학습되려면 이미지의 많은 양을 마스크 처리 해야한다는 점이 흥미로웠습니다. 그리고 이미지의 많은 부분이 가려짐에도 불구하고 원본과 거의 동일한 결과를 보인 것도 놀랍네요.
또한 간단한 구조이지만 인코더에서는 마스킹되지 않은 픽셀만을 넣는 거나 디코더에서는 masking된.패치에 대해서만 loss를 계산한다는 것처럼 모델 설계의 각 부분이 분명한 역할과 이유를 가지고 설계되었단 점에서 기반이 탄탄하게 갖춰져 있단 생각이 들더군요.
저도 리뷰를 읽으면서 디코더의 역할이 중요한데 lightweight하게 설계했단 점에서 의문이 있었는데 댓글을 참고해 이게 깊이를 깊게 하는 대신 width 측면에서 보다 작은 차원을 입력으로 받게 해 효율적이면서도 충분히 semantic gap을 줄일 수 있게 한 것이라고 이해하였는데요 제가 잘 파악한 걸까요?
감사합니다.