이번 x-review는 2차년도 감정인식 과제 베이스라인이 되는 논문입니다. 사실 이미 이전의 담당자들이 리뷰를 작성하였으나, 저 나름대로 이해한 것을 정리하면 좋을 것 같아 작성하게 되었습니다.

Introduction
기존의 멀티모달 감정인식에서는 two-phase pipeline을 주로 사용했습니다. two-phase pipeline은 feature extraction 단계와 end-to-end multimodal learning 단계로 구성되어 있습니다. 자세하게 설명하면 아래와 같습니다.
- <feature extraction> : hand-crafted 알고리즘을 이용하여 각 모달리티마다 feature representation을 추출한 뒤
- <end-to-end multimodal learning> : 추출한 feature로 end-to-end 학습을 합니다.
하지만 two-phase pipeline의 경우, 단점이 존재합니다.
- 추출된 feature는 고정되며(수정할 수 없다) target task에 맞춰 미세 조정할 수 없습니다.
- 수작업으로 적절한 feature extraction 알고리즘을 찾아야 합니다.
- hand-crafted model은 higher-level feature를 잘 반영하지 못해 유용한 정보를 놓치게 됩니다.
이러한 단점때문에 최적의 성능을 내지 못하게 됩니다.
논문에서는 위의 단점을 극복하고자 fully end-to-end model을 제안합니다. raw data를 input으로 받고 end-to-end 학습을 하면서 자동으로 feature들이 학습될 수 있도록 합니다.
또한, 기존의 존재하는 멀티모달 감정인식 데이터셋은 fully end-to-end 학습을 할 수 없는데요. (이 이유에 대해서는 뒤에서 설명드리고자 합니다.) 저자들은 이를 위해서 학습이 가능하도록 데이터셋을 reconstructing 하였습니다.
fully end-to-end 학습을 하게 되면 2가지의 장점이 있습니다.
- task에 최적화된 feature를 사용할 수 있습니다.
- 수작업으로 feature extraction 알고리즘을 고를 필요가 없습니다.
하지만 단점도 있습니다.
- two-phase pipeline에 비해 많은 computational overhead를 가져옵니다.
- 모든 데이터 포인트를 철저하게 처리하게 되면서 계산 비용이 많이들고 과적합이 될 수 있습니다.
논문의 저자들은 이러한 단점을 보완하기 위해서 Multimodal End-to-end Sparse Model (MESM)을 제안합니다. 이후에 자세히 설명드리겠지만, MESM은 sparse cross-modal attention mechanism과 sparse CNN으로 구성되어 있습니다. 이를 통해 task에 가장 관련된 feature를 선택하고 불필요한 information과 noise를 줄일 수 있습니다.
Contributions
논문의 contributions은 아래와 같습니다.
- 멀티모달 감정인식 task에서 fully end-to-end trainable model을 최초로 적용하였다.
- 멀티모달 감정인식 데이터셋을 end-toend 학습이 가능하게 restructure 했다.
- fully end-to-end model로 SOTA를 달성하였고, sparse 모델 또한 fully end-to-end model의 성능을 유지하면서 크게 computational overhead를 줄였다.
Data Reorganization
fully end-to-end model은 3개의 모달리티(video, textual, acoustic)에 대한 raw data를 input으로 사용합니다. 그러나 위에서 언급한 것처럼 현존하는 멀티모달 감정인식 데이터셋은 바로 fully end-to-end model에 사용할 수 없습니다. 이유는 아래와 같습니다.
- 데이터셋은 input으로 hand-crafted feature를 training, validatin, test split으로 제공하고, output으로 emotion혹은 sentiment label을 제공합니다. 하지만 split 인덱스가 raw data와 매칭 되지 않기 때문에 데이터셋 split을 raw data에 직접 맵핑할 수 없습니다.
- 데이터 샘플의 label은 text 모달리티에 맞춰 aligned 되었는데, raw data에서 visual, acoustic 모달리티는 text 모달리티에 맞춰 aligned 되지 않았기 때문입니다.
위의 이유로 논문의 저자들은 fully end-to-end에 맞춰 데이터셋을 2 step으로 재편성했습니다.
- text, visual, acoustic 모달리티를 align 한다.
- aligned data를 training, validation, test 셋으로 나눈다.
논문에서 사용한 IEMOCAP, CMU-MOSEI는 위의 2 step에 맞춰 재편성 해주었습니다.
Methodology
Problem Definition
- I : multimodal data samples
- X = \{(t_i, a_i, v_i)\}_{i=1}^I
- t_i : 단어 sequence
- a_i : 오디오 spectogram sequence
- v_i : 비디오의 RGB이미지 frame sequence
- Y = \{(y_i)\}_{i=1}^I ( Y는 각 데이터 샘플의 annotaion 입니다)
Fully End-to-End Multimodal Modeling
논문의 저자가 제안한 첫번째 모델입니다. fully end-to-end multimodal model은 두계의 분리된 단계(feature extraction, multimodal modelling)를 합쳐서 최적으로 학습하도록 합니다.
visual과 acoustic 모달리티에서 각 spectogram chunk와 image frame에 대해 사전학습된 VGG 모델을 이용하여 input feature를 추출합니다. 그 이후 linear transformation을 이용하여 vector representaion을 평탄화(flatten)합니다. 이를 통해 visual과 acoustic 모달리티의 representaion sequence를 얻을 수 있습니다. 이후에는 temporal information을 모델링하기 위한 positional embeddings를 포함하는 transformer 모델을 이용하여 sequental representation을 encoding 합니다. 마지막으로 “CLS” token에서 output vector를 취하고, feed-forward 네트워크(FFN)에 넣어 classification score를 얻습니다.
학습되는 과정을 나열하면 이와 같습니다. 저는 여기서 CLS token을 왜 output vector로 사용하는지 잘 이해가 가지 않아 좀 더 찾아봤는데요. [참고1] [참고2] [참고3]을 참고하여 설명드리겠습니다.
CLS token
우선, CLS token은 BERT에서 처음 등장하였습니다. 아래의 그림처럼 CLS token을 사용하는데, 이는 Special Classification token으로 모든 문장의 가장 첫 번째(문장의 시작) 토큰으로 삽입됩니다.
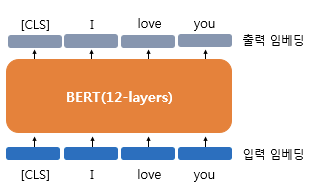
아래 그림은 BERT가 각 768차원의 [CLS], I, love, you라는 4개의 벡터를 입력 받아서(입력 임베딩) 동일하게 768차원의 4개의 벡터를 출력하는 모습(출력 임베딩)을 보여 줍니다. 왼쪽 그림을 더 자세히 볼까요?
BERT의 연산을 거친 후의 출력 임베딩은 문장의 문맥을 모두 참고한 문맥을 반영한 임베딩이 됩니다. [CLS] 벡터는 BERT의 초기 입력으로 사용되었을 때 입력 임베딩 당시에는 단순히 임베딩 층(embedding layer)을 지난 임베딩 벡터였지만, BERT 벡터를 지나고 나서는 [CLS], I, love, you라는 모든 단어 벡터들을 참고한 문맥 정보를 가진 벡터가 됩니다.
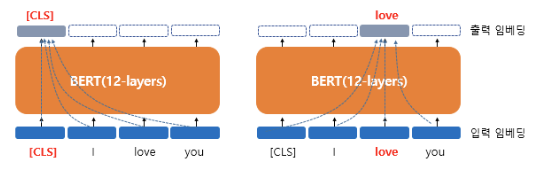
이러한 이유로 CLS token이 전체 문장의 representation vector로 사용될 수 있습니다. 이 때문에 MESM 논문에서는 CLS token을 output vector로 사용한 것이지요.
Multimodal End-to-end Sparse Model
다음은 Fully End-to-End Multimodal Modeling의 큰 computation overhead를 극복하기 위해 제안한 multimodal end-to-end sparse model(MESM) 입니다.
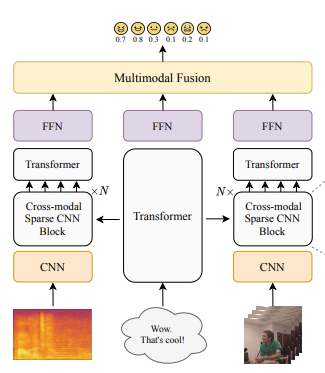
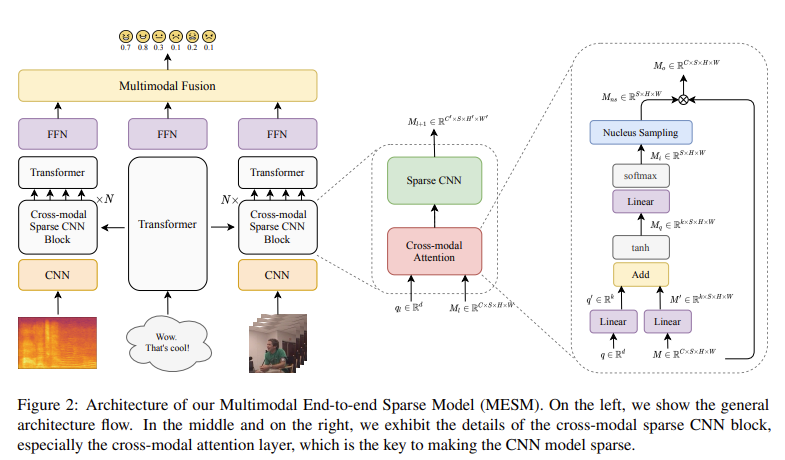
Figure2를 통해 MESM의 구조를 살펴볼 수 있습니다. (위의 그림은 설명을 위해 일부만 가져옴) fully end-to-end model에서 사용한 CNN layer를 low-level feature를 capture하기 위한 첫 레이러를 제외하고는 N개의 cross-modal sparse CNN 블럭으로 대체한 것을 확인할 수 있습니다.
cross-modal sparse CNN 블럭은 cross modal attention layer과 sparse CNN으로 구성되어 있습니다.
Cross-modal Attention Layer
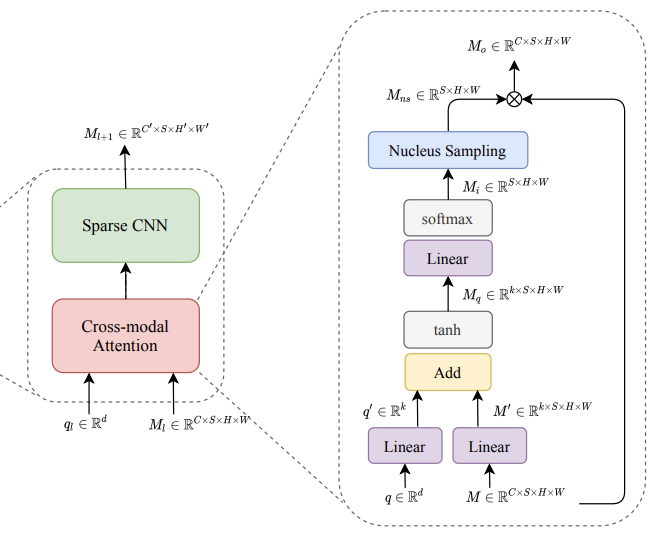
Cross-modal attention은 2개의 input을 받습니다.
- q \in \mathbb{R}^{d} : query vector
- M \in \mathbb{R}^{C{\times}S{\times}H{\times}W} : a stack of feature map (C는 채널 수, S는 sequence 길이, H는 height, W는 width 입니다)
query vector를 이용하여 feature map에 대해서 cross-modal spatial attention이 수행됩니다. 자세한 설명은 수식을 통해 설명드리겠습니다.

W_m \in \mathbb{R}^{k{\times}C}, W_q \in \mathbb{R}^{k{\times}d}, W_i \in \mathbb{R}^{k} 는 linear transformation의 weight 입니다. b_m \in \mathbb{R}^{k}, W_i \in \mathbb{R}^{I} 은 bias, k는 사전에 정의한 하이퍼 파라미터 입니다. \oplus 는 broadcast addition 연산을 의미합니다. 또한 식(2)에서 softmax는 (H{\times}W) 차원에 적용되며, 식(2)의 결과물인 M_i \in \mathbb{R}^{S{\times}H{\times}W} 는 각 feature map에서의 spatial attention score로 구성된 tensor를 의미합니다.
중요한 정보는 보존하면서 input인 feature maps M을 sparse하게 만들기 위해서 우선 M_i 에 대해서 Nucleus Sampling을 진행합니다. 이를 통해서 각 attention score map에서 probaility mass의 상위 p 비율을 얻습니다. (p는 사전에 정의한 하이퍼 파라미터로 (0, 1] 범위를 가집니다)
M_{ns} 에서 Nucleus Sampling에 의해 선택된 point는 1로, 나머지는 0으로 설정합니다. 이후에 M_{ns} 와 M 을 곱해 output인 M_{o} 를 얻습니다. M_{o} 는 어떤 position에서는 0을 갖는 sparse tensor라고 말할 수 있습니다.
Nucleus Sampling
논문에서는 Nucleus Sampling에 대해서 자세한 설명이 없어 이해가 어려워 이것도 CLS token과 마찬가지로 설명을 찾아봤습니다. 설명은 [참고1] [참고2]를 참고하였습니다.
NLP에서 자주 등장하는 용어인데, GPT 등의 생성 모델을 통해 문장을 생성할 때 여러 sampling 기법을 이용하여 어떤 단어가 나올지 결정할 수 있다고 합니다. 아래의 이미지를 통해서 Top-K 샘플링 방식을 확인할 수 있습니다. Top-K 샘플링은 확률이 높은 순서에 따라 k개의 토큰을 샘플링하는 방식입니다.

Top-k예시 그림을 보면 첫번째 단어는 평평한 분포에서 샘플링하고, 두 번째 토큰은 sharp한 분포에서 샘플링하는 것을 확인할 수 있습니다. 딱 k개만 샘플링하기 때문에 이로 인해서 첫 번째 분포에서는 괜찮아 보이는 단어 (people, big, house, cat) 등의 후보는 전혀 고려되지 못하게 되고, 두 번째 분포에서는 낮은 확률이라도 뽑게 되면 어색해지는 (down, a) 등이 샘플링 될 수 있습니다. 즉, 이상한 단어를 샘플링할 위험이 있다는 것입니다.
이를 해결하고자 Top-p 샘플링 방식 (Nucleus Sampling)이 등장하였습니다.

확률이 높은 순서에 따라 k개의 토큰을 샘플링하는 것보다, 누적 확률이 확률 p에 다다르는 최소한의 단어 집합으로부터 샘플링합니다. 가장 높은 확률을 가지는 토큰부터 시작해, 확률 값의 합이 Top-p로 설정한 값을 넘을 때까지 샘플링 합니다.
Top-p예시 그림을 보시면 확률이 비교적 평평한 첫 번째 분포에서 가능성 있는 nice, dog, —, big, house까지 총 9개의 토큰을 샘플링 해야 누적확률 0.94를 채울 수 있는 있습니다. 분포가 가팔랐던 두 번째 분포에서는 확률이 굉장히 높은 drives, is , turns만 샘플링하게 되고, 누적활률을 채웠기 때문에 더 이상 이상한 토큰을 샘플링하지 못합니다.
Sparse CNN
Cross modal attention layer이후에 sparse CNN을 사용합니다. 감정 인식 할때 데이터의 일부만 감정 인식만 관련이 있다고 가정하는데 이러한 점이 sparse setting과 일치한다고 합니다. sparse CNN이 cross modal attention layer의 output을 받고 active position에 대해서만 convolution 연산을 수행합니다. 이를 통해 연산량을 굉장히 줄일 수 있는데, 이론적으로 연산량을 구하면 표준 컨볼루션의 경우 z^2mnFLOPs가, sparse 컨볼루션의 경우, amn FLOPs가 나온다고 합니다. (여기서 z는 커널 사이즈, m은 input channel 수, a는 active points의 수 입니다)
Experiments
Evaluation Metrics
IEMOCAP 데이터셋의 경우 accuracy와 F1-Score를 evaluation metrics로 가져갑니다. CMU-MOSEI 데이터셋의 경우 weighted accuracy를 사용하는데 이는 데이터셋이 imbalanced 하기 때문입니다. weighed accuracy 식은 아래와 같습니다.
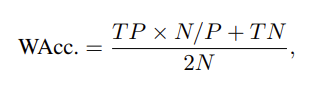
P는 total positive, TP는 true positive, N은 total negative, TN은 true negative를 의미합니다.
Analysis
Results Analysis
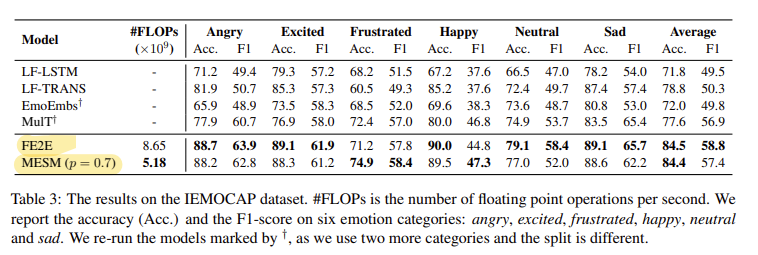
Table 3은 IEMOCAP 데이터셋에서의 실험 결과를 정리한 것입니다. 논문의 저자가 제안한 FF2F (fully end-to-end model)가 SOTA를 달성했다는 것을 확인할 수 있고, 연산량을 대폭 낮춘 MESM도 좋은 성능을 보이는 것을 확인할 수 있습니다.
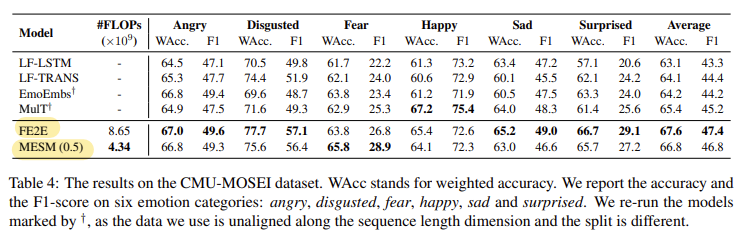
CMU-MOSEI 데이터셋에서의 실험 결과를 Table 4를 통해 확인할 수 있는데, 마찬가지로 SOTA를 달성한 것을 확인할 수 있습니다.
Effects of Nucleus Sampling
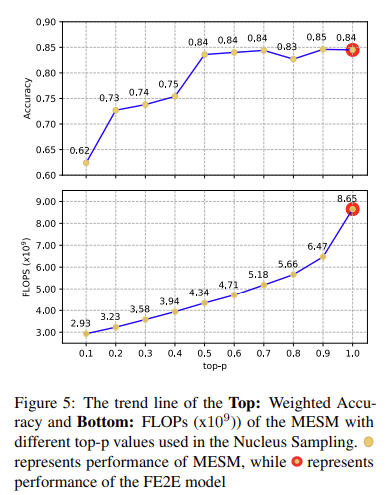
Figure 5를 통해, Nuclus Sampling에서 top-p를 0.1에서 1.0을 주었을 때의 Accuracy와 연산량을 비교할 수 있습니다. 위에서 설명한 것처럼 p를 크게 가져갈 수록 많이 샘플링할 수 있기 때문에 sparsity가 커지고 고려하는 정보도 많아지게 되니 정확도가 올라가는 것은 당연할 수 있습니다. 많은 정보를 고려하기 되니 연산량도 커지는 것은 당연하죠. 하지만 p가 1.0일 때와 0.9일 때의 정확도 차이는 별로 없는데 연산량은 2.18이나 차이가 나는 것을 보면 Nucleus Sampling의 굉장한 장점이 아닌가 합니다.
Ablation Study
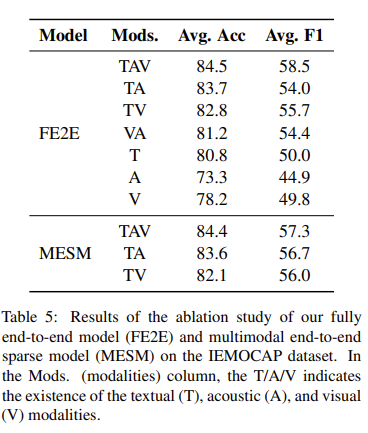
어떤 모달리티가 가장 성능에 많은 영향을 미칠까를 ablation study를 통해 확인할 수 있습니다. FF2E를 보시면 TAV를 모두 사용했을 때 성능이 가장 좋은 것을 확인할 수 있고, 싱글 모달리티에서는 Text만 사용했을 때 성능이 가장 좋은 것을 확인할 수 있습니다. (이 부분은 기존의 연구도 미슷한 양상을 보였다고 합니다)
대단한 것은 MESM인데 연산량을 대폭 줄였음에도 FF2E 모델과 동등하거나 조금 더 나은 성능을 달성한 것을 확인할 수 있습니다.
이렇게 논문 리뷰를 마쳤습니다. 중간에 생소할 수 있는 CLS token, Top-k sampling, Top-p sampling에 대해서 설명을 드렸습니다. CLS token이 이렇게 사용될수도 있다는 것을 알게되었는데 ViT에서도 마찬가지 방식으로 사용한다는 것을 새롭게 배웠습니다.
사실은 Figure 2에 FFN layer 이후에 Multimodal Fusion이 어떻게 이뤄지는지 자세히 확인하고 싶었는데 논문에서는 그렇게 설명이 나와있지 않아 아쉽습니다. 더 궁금한 부분은 code를 통해서 살펴보는 것이 좋을 것 같습니다. 읽어주셔서 감사합니다.