오늘 제가 X-Review에서 소개해드릴 논문은 2021년 WACV에 게재된 “Unsupervised Video Representation Learning by Bidirectional Feature Prediction” 입니다. 항상 비디오의 Weakly-supervised Temporal Action Localization task만 소개해드렸었는데, ETRI 과제의 차년도 방향이 정해져서 이제는 그와 관련된 최근 논문들을 계속해서 읽을 예정입니다.

2023년도 ETRI 과제는 “Self-supervised video representation learning”을 주제로 연구가 진행될 예정입니다. 구체적인 방향이 정해진 것은 아니지만, 과제를 수행하기 위해서는 방학 동안 Self-supervised 기반의 Video representation learning 최신 연구들을 익혀두어야 하기 때문에 위 논문을 읽게 되었습니다.
이쪽 분야의 논문은 처음 읽는 것이기 때문에 내용을 꼼꼼히 살펴보는 것에 초점을 맞춰 리뷰를 작성하겠습니다. 스스로 정리를 위해 중요도가 낮다고 판단되는 내용도 적어두었기 때문에 리뷰를 읽으실 때는 부분마다 선택적으로 읽으셔도 좋을 것 같습니다.
1. Introduction
Introduction은 여느 비디오 관련 논문과 마찬가지로, 비디오가 영상에 비해 시각적 이해 관점에서 더욱 풍부한 정보를 가지고 있기 때문에 비디오 연구가 중요하다고 말하며 시작합니다. 비디오가 담고 있는 고수준의 추상적인 정보가 많은 만큼 관련 downstream task들도 다양하고, 추상적 정보들을 뚜렷하게 represent하는 것이 downstream task들을 잘 수행하는데 큰 역할을 하겠죠.
다음은 Self-supervised learning(SSL)에 대해 이야기합니다. 대용량 데이터셋에 대해 각 downstream task에 맞는 annotation을 사람이 직접 만들어줘야 하는데, 이는 비용과 시간이 많이 들게 됩니다. 실제로 데이터셋 라벨링을 전문 업체에 맡기면 수 백 ~ 수 천 만원을 달라 한다고 합니다. 또 사람이 하는 일이다보니 오류와 실수도 있을 수 밖에 없을 것입니다. 이러한 문제들을 해결하고자 꽤 오래 전부터 SSL 관련 연구들이 활발히 진행되고 있습니다.
비디오의 Action recognition이라는 task가 존재하는데, 이는 시작부터 끝까지 action만 등장하는 비디오를 보고 그 action이 무엇인지 맞추는 task(분류)입니다. 만약 이 task에 대해 Supervised 방식으로 학습하면, 주어진 class 라벨에 의존하여 특정한 몇 프레임만 보고도 action을 맞춰버리게 된다고 합니다. 모델이 학습과정 때 비디오에서 중요한 temporal structure를 파악하려 하지 않고, 특정 몇 프레임을 통해 클래스를 예측하는데에만 편향된다는 뜻인듯 합니다.
개인적으로는 temporal structure를 덜 파악하더라도 어쨌든 Action recognition 성능이 좋으면 된게 아닌가 생각하지만, 비디오가 가진 추상적 정보들을 잘 표현하는 feature를 만드는 것이 중요하다고 보는 저자의 관점에서 이는 최적의 representation이 아니라고 주장하는 것 같네요. 아무튼 위와 같은 이유로 Self-supervised video representation learning의 필요성을 이야기 하고 있습니다.
저자가 제안하는 SSL task는 feature prediction의 일종입니다. Unidirectional feature prediction인 기존 연구들과 다르게 bidirectional feature prediction 방식을 제안하고 있습니다. 결국 제안하는 방법론의 핵심은 present 구간을 기준으로 past와 future 구간에 대한 joint bidirectional feature prediction, InfoNCE loss를 통한 contrastive learning이 전부입니다.
논문에서 이야기하는 contribution은 2가지입니다.
- We propose a novel bidirectional feature prediction pretext task for video representation learning.
- We evaluate our proposed method on several transfer learning benchmarks showing its superiority to its future prediction counterpart
저도 이 분야의 논문을 처음 읽는 것이라 기존 연구들이 어떻게 이루어졌었는지 잘 모르기 때문에 Related work를 보며 기존 연구와 저자의 제안이 어떤 차별점을 갖는지 살펴보도록 하겠습니다.
2. Related Work
Future prediction
앞서 말씀드린 대로 비디오의 temporal 축을 활용해 다양한 pretext task를 수행할 수 있습니다. Future prediction도 그 중 하나로, 비디오의 현재 구간이 주어지면 시간 상으로 미래에 해당하는 구간의 frame 또는 feature를 예측하는 기존 연구들이 선행되었습니다. 기존에는 미래의 RGB frame 자체를 예측하여 실제 미래 frame과의 reconstruction loss를 적용해 pretext task를 수행하기도 했지만, 이는 데이터가 가우시안 분포를 따라야 한다는 가정이 필요해 한계가 있었습니다.
이를 극복하기 위해 frame을 예측하는 것이 아니라, feature를 예측하는 방식이 등장하였습니다. 비디오의 현재 구간을 받아 미래 구간의 feature를 예측하고, InfoNCE loss를 통해 contrastive learning을 수행하는 방식이 그 당시 활발히 연구되었다고 합니다.
이 논문에서는 현재에 대해 미래 feature만 예측하는 것이 아니라 과거 feature까지 예측하고 InfoNCE loss를 통해 학습하는 Bidirectional feature prediction pretext task를 제안합니다.
InfoNCE loss
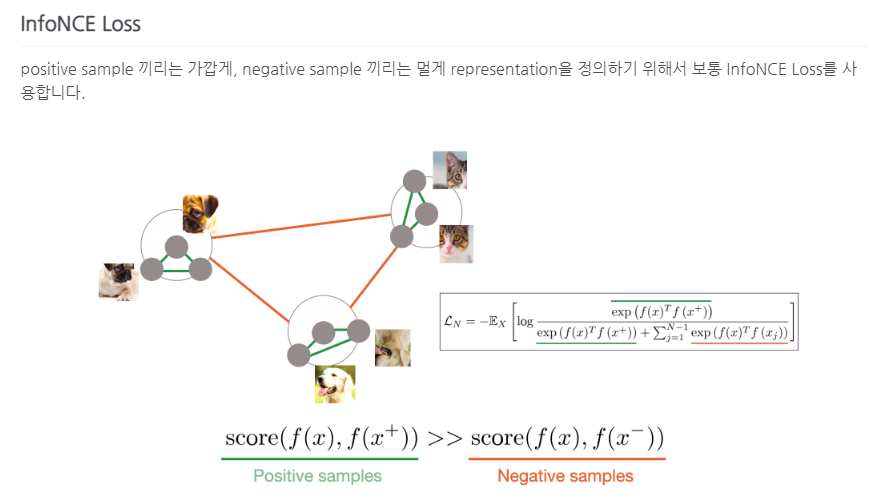
InfoNCE loss는 다들 잘 알고 계실것으로 생각합니다. 이는 contrastive learning을 위해 사용되고 당연히 positive sample 끼리는 feature representation이 가까워지고, negative sample 끼리는 멀어지도록 하는 것이 목적입니다. SimCLR 논문에서 MLP head(learnable nonlinear transformation)를 한 번 거친 후 loss를 계산하는 것이 성능이 좋다는 것을 보여주었기에 이 논문에서도 MLP head를 똑같이 적용해줍니다.
Pretext tasks for video representation learning
저자는 future prediction의 연장선 상에서 새로운 pretext task를 제안하였습니다. 이 외에도 많은 pretext task가 연구되고 있는데, 어떤 것들이 있는지 살펴보겠습니다.
영상 분야에서 적용되던 pretext task들을 비디오로 확장한 video rotation, cubic puzzle 등이 있습니다. 둘은 프레임의 spatio-temporal information을 활용하는데, 특히 cubic puzzle은 올해 연구실에 방문하시어 세미나를 진행해주셨던 김다훈 연구원님께서 발표하신 논문이니 궁금하신 분들은 찾아보셔도 좋을 것 같습니다.
또 비디오의 temporal 축을 중점적으로 활용하는 pretext task들도 많습니다. Frame 또는 clip을 뒤섞은 후 temporal order를 맞추기, egomotion, temporal coherency, video speed 예측 등이 이에 해당합니다. 논문에서는 future prediction 관련 pretext task를 제안하므로 나머지는 자세히 설명하지 않겠습니다.
3. Method
먼저 비디오를 아래와 같이 세 부분으로 나눕니다.
X = (P, V, F)
P, V, F는 각각 과거, 현재, 미래를 의미하고 InfoNCE loss를 통해 P, F의 joint representation을 학습합니다. 이 때 positive와 negative를 각각 어떻게 지정할 것인지가 중요하겠네요.
Past and future feature prediction
이제 past와 future의 feature를 예측한다는 것은 알겠는데, 이 둘을 어떻게 활용할 것인지가 관건일 것입니다.
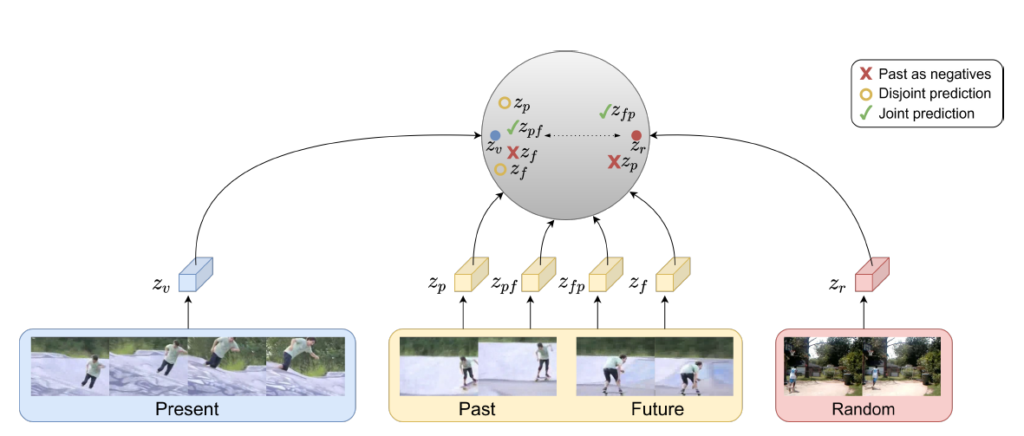
가장 단순하게는, 현재 feature를 보고 두 개의 모델을 통해 past feature z_{p}, future feature z_{f}를 예측해낸 후 각각의 loss를 통해 학습하는 disjoint 방식을 떠올릴 수 있습니다. Unidirectional feature prediction을 과거로 한 번, 미래로 한 번 하는 것과 같다고 이해할 수 있습니다. 그림 1에서 Disjoint prediction, 노란 동그라미에 해당하고 저자는 이렇게 하면 성능이 안좋게 나왔기에 더 나은 방법이 필요하다고 말합니다. 정량적 성능은 리뷰 후반 실험 부분에서 살펴보겠습니다. 결국 비디오 상에서 과거-현재-미래가 쭉 이어지는 것이기 때문에 temporal 정보를 좀 더 활용할 수 있는 방향으로 가야 할 것 같네요.
두 번째로 저자는 현재 feature를 보고 또 다른 feature가 주어졌을 때 이게 현재에 대한 과거인지, 미래인지, 아니면 아예 다른 장면인 random인지 분류하는 방식의 pretext task도 실험해보았다고 합니다. 이 방식도 마찬가지로 성능이 그렇게 잘 나오지는 않았다고 하네요.
위 방법론들을 뒤로 하고, 저자는 InfoNCE loss를 적용하는 방식을 채택합니다. InfoNCE loss를 통해 학습하려면 또 positive와 negative를 각각 어떻게 정해줄 것인지도 중요한데, 먼저 저자는 past는 negative sample로, future는 positive sample로 두고 실험을 해봅니다.
이렇게 set을 구성하는 것이 자명하다고 하는데, 바로 납득이 되지는 않았습니다. 아마 기존 연구에서 future feature를 positive로 두고 가까워지도록 학습했으니 자명하다고 한 것 같네요. 하지만 trimmed video에서는 당연히 past도 현재와 유사한 action의 맥락을 가지고 있을 것인데, negative로 둬버리면 저희가 원하던 past-present-future 간의 시간적 관계를 임베딩하기는 힘들 것입니다. 그림 1에서 빨간 X표시를 보시면 되는데, 현재 feature z_{v}와 미래 feature z_{f}는 유사하게 임베딩 되지만, 과거 feature z_{p}만 멀리 떨어져 임베딩 되어있는 것을 볼 수 있습니다.
아직 만족스러운 방식이 나오지 않았는데, 여기서 다시 한 번 우리가 원하는 임베딩 공간이 무엇인지 생각해보겠습니다. 일단 past와 future는 서로 구별될 수 있어야 합니다. 제안하는 pretext task 자체가 현재를 기준으로 어떤 feature가 과거-미래 순으로 잘 연결되어 있는지 파악하는 것이었기 때문입니다. 이렇게 구별됨과 동시에, past-present-future는 한 비디오 내에서 연달아 일어나는 사건이기 때문에 그 들간의 temporal structure도 표현할 수 있어야 할 것입니다.
단어들이 좀 애매하고 어려워서 잘 와닿지는 않았지만 결국 저자는 past-future 쌍을 positive pair로 사용하고, 그 순서를 뒤집은 future-past 쌍을 temporal hard negative pair로 사용하는 방식을 제안합니다. 목적은 past-future 순서를 잘 학습하여 future-past가 들어왔을 때 이게 역순이라는 것을 잘 구별해냄과 동시에 random한, 즉 아예 다른 비디오의 장면이 들어왔을 때에도 구별할 수 있게 만드는 것입니다.
Network architecture
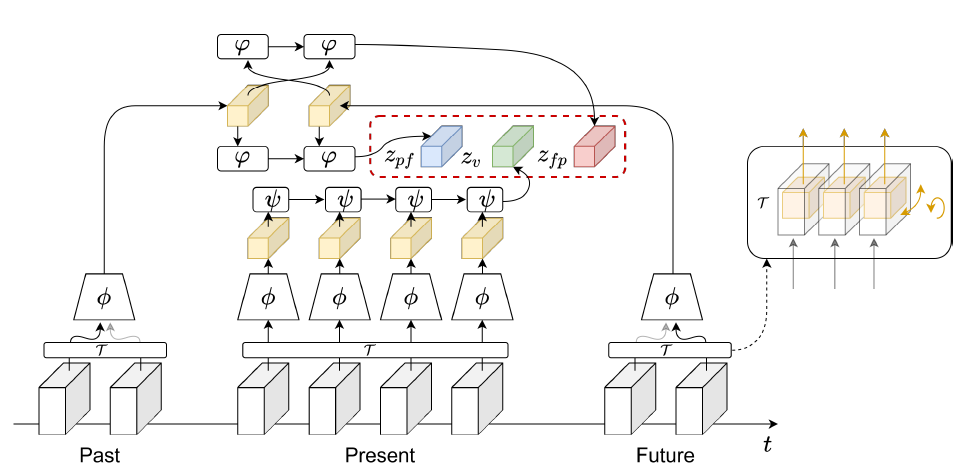
모델의 구조 자체는 크게 복잡하지 않습니다. 그림 2에서 우선 맨 아래 Past, Present, Future 블록들은 비디오에서 샘플링 한 clip 들을 의미하고, \tau{}는 spatial transformation들을 말합니다. 논문에서는 random crop, horizontal flip, rotation을 사용했다고 하네요.
Spatial augmentation을 거친 후 각각이 backbone \phi{}를 통과하여 노란 직육면체까지 만들어집니다. \phi{}는 2D3D-ResNet18로, 기존 ResNet18의 마지막 두 레이어가 3D Conv로 변경되어 있는 것이고, 그 당시 대부분의 다른 연구들에서도 해당 backbone을 사용했다고 합니다.
그럼 이제 노란 직육면체를 가지고 실제 학습에 사용할 final feature를 만들어 주어야 합니다. 이를 위해 그림 2에서 두 개의 aggregate function \psi{}, \varphi{}가 등장합니다. 둘은 모두 ConvGRU인데 현재 feature를 aggregate 하기 위한 ConvGRU \psi{}와 과거-미래 feature를 joint하게 aggregate하기 위한 \varphi{}로 나눠집니다.
그림 2에서 현재 feature를 \psi{}를 통해 z_{v}로 만드는 부분까지는 어렵지 않습니다. ConvGRU 연산은 무엇이 먼저 들어가는지에 따라 다른 결과가 나오는 비대칭 연산으로, past-future 순으로 연산하면 z_{pf}, future-past 순으로 연산하면 z_{fp}를 얻을 수 있습니다. 앞서 past-future를 positive로, future-past를 temporal hard negative로 사용하기로 했었는데 z_{pf}, z_{fp}가 각각에 해당하게 되는 것입니다.
잠시 위의 내용을 수식으로 한 번 정리하고 넘어가겠습니다.
- \phi{}: 2D3D-ResNet18, backbone
- \psi{}: ConvGRU, 현재 feature aggregate
- \varphi{}: ConvGRU, 과거-미래 또는 미래-과거 feature aggregate
- z_{v} = (\psi{} \circ{} \phi{})(V)
- z_{pf} = (\varphi{} \circ{} \phi{})(P, F)
- z_{fp} = (\varphi{} \circ{} \phi{})(F, P)
Contrastive Loss
만들어진 final feature들을 통해 contrastive loss로 학습하는 과정만이 남아있습니다.
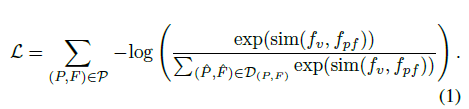
\mathcal{P}는 postive future, past 쌍의 전체 set을 의미합니다. 각 쌍 (P, F) \in \mathcal{P}에 대해 set \mathcal{D}_{(P, F)}는 positive 쌍 (P, F)에 대한 모든 negative까지 포함합니다. 앞서 Related Works에서 언급했던, 실제 InfoNCE loss 연산 전 적용해 줄 MLP head는 f로 표현합니다. 예를 들어 f_{v} = f(z_{v})인 것입니다. sim은 코사인 유사도를 사용합니다.
\mathcal{L}을 최소화 하기 위해 분자항이 최대가 되어야 하니 결국 현재 feature와 past-future feature 간 유사도는 최대로, 나머지 negative set들과의 유사도는 낮아지는 방향으로 학습할 것입니다.
그렇다면 실제로 positive, negative 쌍들이 어떻게 구성되는지 자세히 살펴보겠습니다.
Positives
\mathcal{P}는 positive past-future 블록을 의미합니다. 한 비디오 당 m개의 past 블록과 m개의 future 블록을 랜덤으로 선택하는데, 이렇게 past-future 쌍을 조합하면 총 m^{2}개의 positive past-future쌍을 얻을 수 있습니다. 그림 2에서는 2개씩 뽑았으니 총 4개의 조합이 나오는 것입니다.
Easy negatives
다른 SSL 방법론들과 비슷하게, 여기에서도 easy negative들은 한 미니배치 내 다른 비디오에서 가져옵니다. 다른 비디오에서도 또한 m개의 past와 future 블록을 정할 수 있습니다. 배치 사이즈를 n이라고 하면, 총 easy negative 개수는 2m^{2}(n-1)개입니다. (n-1)은 배치 내에서 자신의 비디오를 제외한 개수, m^{2}은 m개 블록에 대한 쌍 조합의 개수이고 2는 그 블록들이 past-future 쌍과 future-past 쌍, 총 2개의 조합으로 사용되는 것을 의미합니다.
Temporal hard negatives
이 부분은 계속해서 설명 드린 부분과 같습니다. 제안하는 pretext task를 위해, 비디오에 대해 얻은 past-future 쌍(positives)을 뒤집어서 임베딩한 z_{fp}를 말합니다. 개수는 얻을 수 있는 positive의 개수와 같겠죠.
이렇게 얻은 pos, neg sample 들을 \mathcal{D}_{(P, F)}로 두고 InfoNCE loss로 학습을 진행합니다.
4. Experiments
마지막은 실험 부분인데요, Self-supervised 기반으로 추출한 feature의 representation을 평가하기 위해서 어떤 파이프라인을 거치는지 살펴보겠습니다. 영상 도메인에서 Image classification이라는 downstream task로 많이 평가하듯, 비디오에서는 Action recognition task를 활용합니다. 리뷰 초반에 설명드렸듯, action recognition은 trimmed video를 보고 그 속에서 일어나는 action이 무슨 클래스인지 분류하는 task입니다.
먼저 Kinetics-400이라는 대용량 데이터셋을 이용해 저자의 학습 방식대로 2D3D-ResNet18 모델 \phi와 \psi를 사전학습 시킵니다. 저자의 표현에 따르면 사전학습 할 때에도 Kinetics 데이터셋의 라벨을 사용하지 않았다고 합니다. 이후 사전학습된 모델 마지막에 linear layer 하나를 붙이고 평가하고자 하는 데이터셋(UCF101, HMDB51)에 대해 finetune 시켜 action recognition 성능을 평가합니다.
4.1 Finetuning on UCF and HMDB
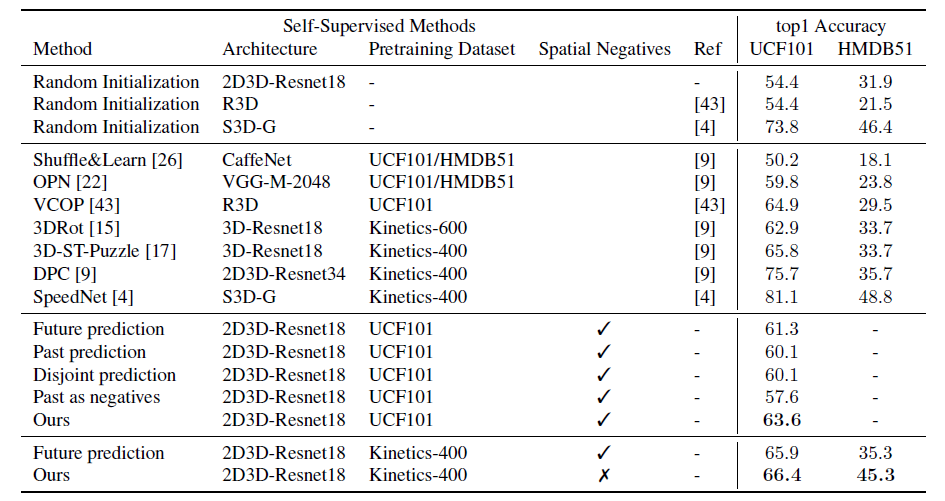
기존 연구와의 차별점이 바로 unidirectional prediction -> bidirectional prediction 이라는 점이었습니다. 표 세 번째의 Future, Past prediction은 각각의 방향으로 unidirectional prediction 수행에 대한 성능이고, Disjoint prediction, Past as negatives는 둘 다 bidirectional이지만 각각 past, future를 따로 예측하는 방식, InfoNCE loss를 사용하되 past를 negative로 두는 방식에 해당합니다. 저자가 제안하는 방식이 각 scheme 마다 가장 높은 성능을 나타내는 것을 확인할 수 있습니다.
성능이 월등히 높은 S3D-G 모델의 경우, 훨씬 무겁고 연산량이 많은 모델이라고 합니다. 또 UCF101 데이터셋으로 사전 학습하는 경우, 소규모의 데이터셋이기 때문에 사전 학습의 효과를 크게 보지 못했다고 합니다.
4.2 Layer-wise evaluation on Kinetics
Kinetics 같은 대용량 데이터셋으로 사전학습 후, UCF 같은 소규모 데이터셋으로 평가하여 제안하는 feature representation이 효과적이었다고 주장하는 것은 사실 설득력이 좀 부족할 수 있습니다.
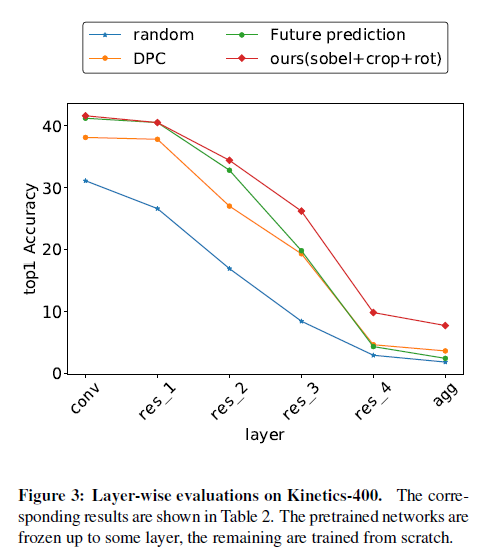
그래서 저자는 추가 실험을 하나 진행합니다. 표 가로 축의 res_1을 예로 설명드리면, 사전학습 대상인 \phi와 \psi(agg) 중 res_1 까지는 사전학습 된 가중치로 freeze 시키고, res_1 이후부터 끝까지는 저자의 SSL 방식대로 scratch부터 학습시켜 성능을 측정한 것입니다. 표에서 볼 수 있듯 사전학습 가중치를 많이 사용하고 finetune이 적을수록 성능이 낮아지는 것을 볼 수 있습니다. 이 말은, 향상된 성능이 Kinetics 데이터셋의 사전학습만으로부터 온 것이 아니라 저자가 제안하는 SSL 방식이 효과적이었다는 것으로 이해할 수 있습니다.
이 외에도 자세한 implementation detail이나 ablation 실험들이 논문에 있으니 궁금하신 분들은 참고하시면 좋을 것 같습니다.
5. Conclusion
Self-supervised video representation learning 분야의 논문을 처음 읽다보니 방법론이나 성능에 대한 개인적인 분석이 부족했습니다. 이번 리뷰를 통해 해당 task의 연구가 어떠한 구조로 이루어지는지 또는 평가가 어떻게 이루어지는지에 대해 기초를 다지는 시간이 되었습니다. 이 연구의 최근 동향을 빠르게 파악하는 방향으로 계속해서 논문을 읽고 리뷰해보도록 하겠습니다.
이상으로 리뷰 마치겠습니다.
상세하고 좋은 리뷰 감사합니다.
Past and future feature prediction을 contrastive learning으로 비디오에 대한 representation learning을 진행한 방법론 같습니다. 그런데 그림을 통해 든 생각이 스키타는 장면의 경우 오른쪽/왼쪽 웨이브하며 이동하면 결국 과거나 미래의 씬들이 비슷해서 오히려 contrastive learning에 방해가 될 것 같다는 생각이 문득드는데, 이런 특수 케이스를 제외하고는 bi-directional하게 학습하는 것이 더 효과적인걸까요? 성능테이블을 보면 uni에 비해 꽤 유의미한 성능 차이를 보이는 거 같긴 한데, 연산량 및 복잡도가 훨씬 커지지는 않나요? 또한 이런 contrastive learning이 엄청나게 큰 배치를 사용해야 성능이 좋은 경향이 있는데 혹시 비디오에서도 그런가요?
1) 말씀해주신대로 과거-미래가 비슷하다면 오히려 헷갈리도록 학습하는 경우도 생길 수 있다고 생각합니다. 논문에서 2개의 past, 2개의 future를 랜덤으로 샘플링하기 때문에, 같은 비디오 내에서 과거-미래가 비슷하지 않은 조합들의 temporal structure도 학습하며 좋은 표현력을 갖게 된 것이 성능을 올려주지 않았나 생각합니다.
2) 실제로 이 논문은 과거-현재-미래 feature, 저자가 unidirection 베이스라인으로 삼은 논문(DPC)에서는 현재-미래 feature만 사용하기는 합니다. 하지만 DPC가 한 비디오마다 8(5-3)개의 블록을 사용하였는데, 저자는 한 비디오마다 총 6개(2-2-2)의 블록을 샘플링함으로써 연산량 차이를 좀 완화해주려고 한 것 같습니다. 한 블록이 5프레임으로 이루어진 것은 동일합니다. 사실 백본도 같고 추가로 붙어있는 모듈도 ConvGRU로 같아 연산량 측면에서는 비슷할 것으로 생각합니다.
3) 비디오에서도 마찬가지로 배치가 클수록 효과적일 것이라고 생각합니다. 하지만 이번에 리뷰한 논문에서는 unidirectional(DPC) 베이스라인 논문을 기반으로 bidirection 방법론의 성능 향상을 보여주기 위해 배치 사이즈를 포함한 여러 세팅들을 DPC와 동일하게 맞춰주고 있었습니다. 따라서 또 다른 배치 사이즈에 따른 실험 결과는 논문에 나와있지 않았습니다.