- Introduction
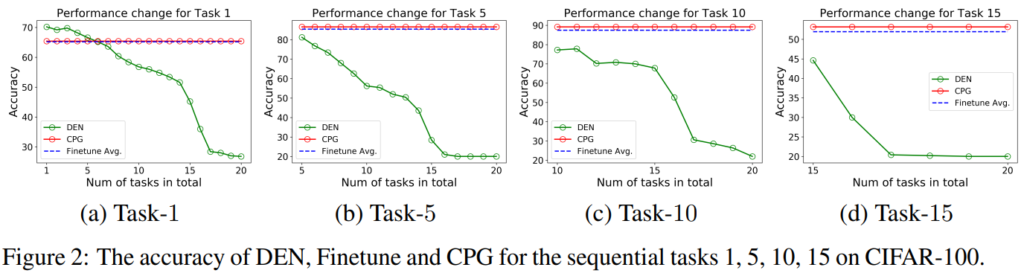
본 논문은 incremental learning에 관한 논문입니다. figure2에서 방법론의 저력을 확인할 수 있는데요 기존 방법론인 Dynamic-expansion Net(DEN)[1]대비 좋은 성능을 보임을 확인할 수 있습니다. 본 포스트에서는 incremental learning이 무엇인지, 제안하는 방법은 어떤 방법론을 제안하는지 소개하겠습니다.
2. Incremental learning
Incremental learning, Continual learning으로 불리는 해당 분야는 여러 Task를 학습하기 위한 방법론입니다. 기존 연구들이 pretraining 이후 task에 대해 fineturning을 진행하는데요, 해당 방법론은 이와 비슷하지만 task 확장이 필요한 상황에서 필요한 기술이라 생각하시면 될 것 같습니다. finetuning은 일반적으로 사전학습 task에 대한 성능을 보존할 필요는 없습니다. 이전 라운드에서 습득한 표현력을 더 개발하거나 확장하는 방식으로 학습이 진행되지요. 하지만 이전 라운드의 학습 task를 보존하되 새로운 task를 추가해야하는 상황도 존재합니다. 예를 들어 A사의 생산품을 분류하는 인공지능 분류기가 공장에 사용중이라고 합시다. A사가 신제품을 출시할 때 마다 모델은 업데이트가 필요하고 새로운 제품에 대한 카태고리를 추가해야 하지요. 이런 경우 기존 제품들로 구축된 데이터와 새로운 제품에 대한 데이터를 포함한 학습 데이터풀을 구축하고 이로 학습을 진행하는 것이 일반적입니다. 이러한 방법의 문제점은 학습 시간입니다. 기존 데이터에 대해 재학습까지 진행해야 하기 때문에 새로운 데이터만 추가학습 하는것 보다 더 많은 시간이 소요되기 때문이죠. 이런 문제를 다루는 것이 Incremental learning 입니다. Incremental learning은 새로운 Task를 학습하면서 기존 Task에 대한 표현력이 변화하고 새로운 Task에만 fitting 되는 망각문제(catastrophic forgetting)에 대한 해결방법을 주로 연구하는데, 그 해결책으로는 모델 학습시 파라미터 변화를 규제하는 regularization방법론과 이전 Task를 대표하는 proxy 데이터를 보존해서 새로운 학습시 같이 학습시키는 subset 구축 방법론, 기존 모델에서 일정 수준의 파라미터를 유지하는 방법론이 대표적입니다. 제안하는 방법론인 Compacting, Picking, and Growing(이하 CPG)은 Incremental learning의 catastrophic forgetting 문제를 효과적으로 해결하기 위해 이전 Task에 대해 학습한 모델의 weight를 변형하지 않고 남겨두는 접근법을 취했습니다.
3. Method
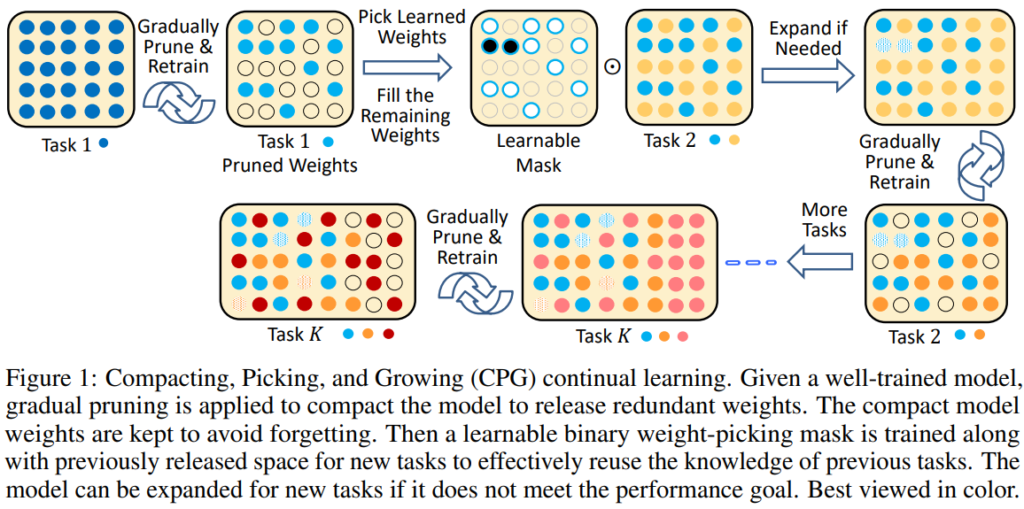
제안하는 방법론은 Task t에 대해 모델을 학습하고, 모델을 pruning 한 후, pruning 한 파라미터를 활용해 새로운 Task t+1을 학습하는 방식으로 Incremental learning을 진행합니다. 이때 상황에 따라 pruning을 통해 자유로워진 파라미터가 부족하다고 판단되면 모델을 키우는(expand) 과정을 추가하며 이것이 제안하는 방법론의 특징이라 볼 수 있습니다. 자세한 학습 방법론은 다음과 같습니다. 알고리즘 수도코드 먼저 첨부드립니다.

Task1: 주어진 Task에 대해 학습한다. 이는 기존의 지도학습 방법론과 같으며 논문의 실험을 기준으로 하자면 CIFAR-100 데이터셋 중 특정 Task로 설정된 5개의 classes로 구성된 이미지 분류 데이터셋을 학습하는 과정이다. 학습 이후에는 pruning과정을 거치는데, 한번에 모델을 pruning 하는 것이 아닌 목표 비율(hyperparameter ,10:1 제거비율)에 도달할때까지 반복적으로 pruning 하는 과정을 거친다. pruning은 파라미터의 절댓값, 즉 영향력이 작은 파라미터를 우선적으로 제거한다.
Task k to k+1: Task K+1을 학습할 때, Task K에 대한 학습 파라미터 중 pruning 과정을 통해 자유로워진 파라미터를 이용해 모델을 학습한다. 이때 학습 후 모델의 성능이 목표에 도달하지 못하면 모델 expendation 과정을 거치는데 모델의 너비를 약 0.5(hyperparameter)만큼 증가시키게 된다.
Compaction of task k+1: Task K+1에 대해 학습을 완료한 모델을 학습한 파라미터 (W_T+1)에 대해 pruning을 진행한다. 이 또한 앞서 소개한것과 같이 영향력이 작은 파라미터를 우선적으로 제거한다.
4.Proof
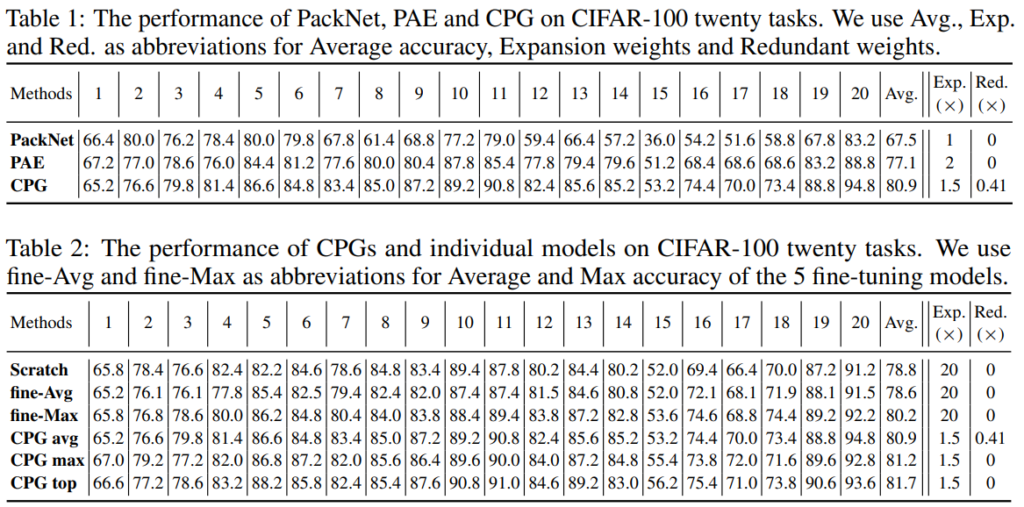
방법론에 대한 증명으로는 Figure2의 그래프를 참고할 수 있습니다. 제안하는 방법론이 기존 Incremental learning 방법론과는 다르게 Task 추가에 대한 성능하락이 없으며 finetuning과 유사한 성능을 보임을 확인할 수 있습니다. 그 외에도 정량적 수치를 Table1, Table2를 통해 비교하였는데, 제안하는 방법론은 Task 추가에 따른 성능 하락이 거의 없음을 확인할 수 있습니다. 실험은 CIFAR-100 데이터셋으로 진행되었으며 각 태스크당 5 class를 학습하였습니다. 기존 incremetal learing의 실험방식과 유사하게 test 시에는 20개의 테스크 중 하나를 선정하고 이에 대해 finetuning을 진행하여 해당 task에 대해 실험 결과를 리포팅 하였습니다. 실험은 이러한 과정을 5번 반복하여 평균을 리포팅하였다고 합니다.
5.Reference
[1] Jaehong Yoon, Eunho Yang, Jeongtae Lee, and Sung Ju Hwang. Lifelong learning with dynamically expandable networks. In Proceedings of ICLR, 2018.
안녕하세요 좋은 리뷰 감사합니다.
방법론이 동작하는 과정 중 Task k to k+1 단계에서 궁금한 점이 있습니다.
Pruning 된 모델을 학습시킨 후 성능이 부족하다면 모델의 가중치 개수를 늘리는 방식이라고 하였는데 이것의 기준이 되는 성능은 어떻게 정하나요?
새로운 task를 학습했을 때 성능이 얼마나 오를지, 떨어질지를 판단할 수 있는 방법이 있는 것인지 궁금합니다.
1. 코드를 확인해본 과 목표성능을 직접 json 파일로 설정하였습니다. hyperparameter로 생각하시면 될 것같습니다.
2. 새로운 task가 기존 task와 연합해서 학습이 가능할지에 대한 연구는 Multi Task Learning 연구 분야에서 task grouping 키워드로 있던것으로 기억합니다. 해당 키워드로 검색해보는것을 추천합니다.
좋은 리뷰 감사합니다.
해당 방법론은 작은 가중치를 가지는 파라미터들만 재학습시키는 것으로 이해를 하였습니다.
해당 태스크가 낯설어서 그런지 실험 결과가 잘 이해가 되지 않습니다.
표에 method에 해당하는 숫자는 태스크의 갯수를 의미하나요??
또한, catastrophic forgetting문제가 해결되었다는 것은 태스크의 숫자가 늘어도 다른 방법론에 비해 성능 하락 정도가 적다는 것으로 이해하면 되나요??
1. 표의 method는 task의 종류를 의미합니다. 각 테스크 당 5클래스에 대한 classification 입니다.
2. 넵 결과적으로는 이전 태스크에 대해 잊지 않아 하락 정도가 적을것 입니다.