우선 Re-Identification(Re-ID)라는 task에 대한 논문은 처음 다루기 때문에 간단하게 설명을 드리자면, 사람을 식별하여 동일한 사람은 동일하게 인식하고 다른사람은 구별하는 task입니다. 이러한 task도 retrieval task 중 하나로, 쿼리 영상을 던져 DB에서 동일한 사람을 찾아내는 것입니다. RGB와 Thermal 영상간의 retrieval 논문을 서베이하다 Re-ID중에도 RGB와 IR 영상간의 매칭을 목표로 하는 cross-modality/VI(visible-infrared) re-ID라는 연구가 있다는 것을 알게 되었고, 해당 task의 논문을 읽게 되었습니다.
Introduction
RGB-Infrared(IR) person re-identification은 모달리티간의 차이 뿐만 아니라 각 모달리티 내의 variation에 의해서도 매칭이 어렵다고 합니다. 해당 논문은 구별이 가능하도록 하는 feature representation을 학습하기 위해 새로운 네트워크를 제안하였습니다. 해당 네트워크는 1) 추가적인 metric learning 없이 데이터에서 end-to-end로 학습이 가능하고, 2) 모달리티간의 차이 뿐만 아니라 모달리티 내의 variation도 동시에 다루었다고 합니다.
Method
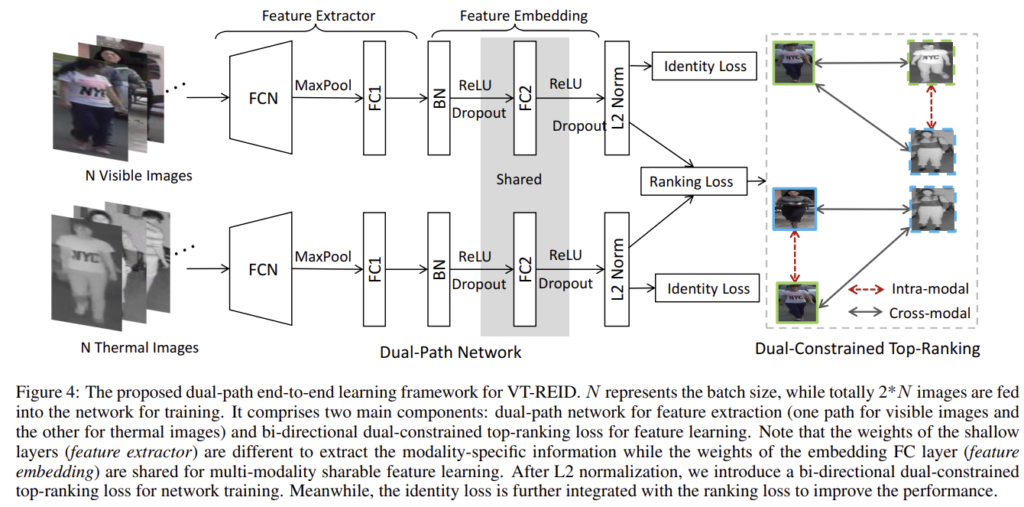
이 논문은 end-to-end의 feature learning 방식인 VT-REID를 제안하였습니다. feature를 추출하기 위한 dual-path 네트워크와 feature learning을 위한 양방향의 dual-constrained top-ranking loss를 포함하고 있습니다. 이때 dual-path는 파라미터의 일부분을 공유한다고 합니다. 이제 디테일한 내용을 살펴보도록 하겠습니다.
1. Dual-path Network
feature를 추출하기 위해 dual-path 네트워크를 제안하였다고 합니다. 이때 dual-path 네트워크는 feature extractor와 feature embedding 부분으로 구성됩니다. feature extractor는 모달리티별 정보를 추출하는 것을 목표로 하고, feature embedding은 두 모달리티의 차이를 연결하는 데에 집중하였다고 합니다.
- Feature extractor
두 모달리티의 feature 추출 네트워크는 유사한 구조를 가지지만 따로 학습이 됩니다. 이때 구조가 유사한 것은, thermal의 low-level의 시각적 패턴이 (texture, corner 등)가 RGB의 일반적인 표현과 유사하다고 가정하였기 때문이라고 합니다.
네트워크는 AlexNet을 베이스라인 모델로 하였고 ImageNet에서 사전학습 된 모델을 가져와 5번째 conv layer를 이용하고 뒤에 FC 레이어를 하나 추가했다고 합니다.
- Feature embedding
구별력 있는 embedding space를 학습하기 위해 파라미터를 공유하는 fully connected layer를 이용하였다고 합니다. 이때 파라미터를 공유하지 않을 경우 두 모달리티는 각자 다른 space로 학습이 되므로, 파라미터를 공유하도록 하여 두 모달리티가 동일한 space로 projection 되도록 하였다고 합니다. 이렇게 파라미터를 공유하는 역할을 하는 부분을 포함한 feature extractor를 \mathcal{F}_v(·), \mathcal{F}_t(·)라고 하고, 식으로 정리하면 다음과 같습니다.(첨자v는 visible, t는 thermal을 의미합니다.)
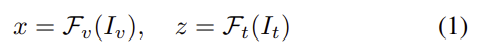
2. Dual-Constrained Top-Ranking
두 모달리티의 이미지는 feature를 임베딩 된 후, 해당 논문에서 새롭게 제안한 양방햔 dual-constrained top-ranking loss를 이용하여 학습을 진행하였다고 합니다.
- Ranking loss revisit
먼저 Ranking loss와 관련된 개념을 설명하도록 하겠습니다.
RGB 영상에서 추출된 feature를 x, Thermal 영상에서 추출된 feautre를 z라 표현하고 anchor feature는 _i, positive feature는 _j negative feature는 _k첨자로 표현할 때, anchor와 positive는 가까워지도록, negative는 멀어지도록 학습됩니다. 이때 feature들은 l2 normalization을 이용하여 안정적으로 수렴이 되도록 하고, feature 사이의 거리는 유클리디안 거리를 이용하여 구합니다. 이를 식으로 표현하면 아래와 같습니다. 이때, \rho_1는 사전에 정의된 margin입니다.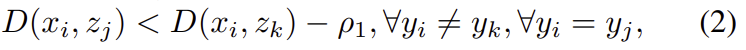
또한, 학습을 전반적으로 제한하기 위해 양방향 ranking loss 방식을 적용하였다고 합니다. 여기서 양방향 ranking loss란 visible to thermal(anchor가 visible이미지, positive와 negative가 thermal 이미지)와 thermal to visible(anchor가 thermal이미지, positive와 negative가 visible이미지)를 모두 고려한다는 것입니다. 이를 수식으로 표현하면 다음 식으로 정리가 됩니다.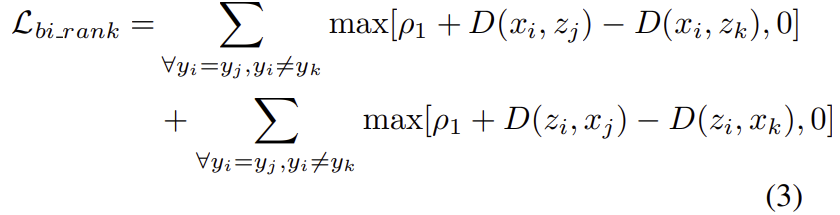
** 위의 식에서 i와 j는 동일한 identity, k는 다른 identity라 합니다.(Re-ID task에서의 identity는 사람을 식별하는 것으로 생각하시면 됩니다.)
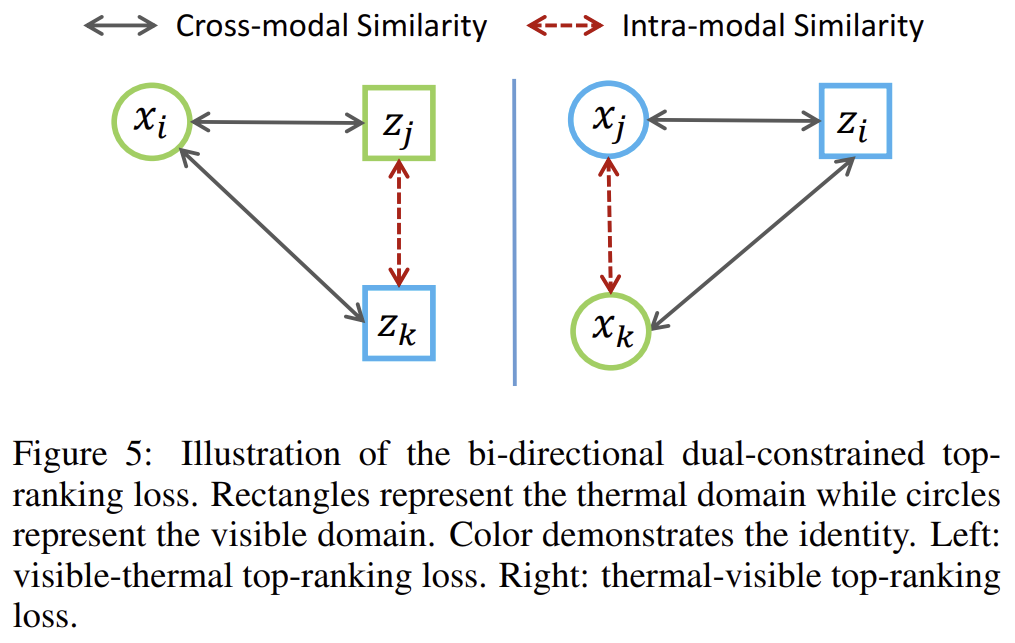
- Cross-modality Top-Ranking Constraint
동일한 클래스에 해당하는 feature들이 서로 다른 도메인에서 촬영된 영상이다보니 intra-class(클래스 내부)간의 차이가 inter-class간의 거리보다 커지는 문제가 있습니다. 이에 top-ranking constraint를 이용하여 구별력을 강화하였다고 합니다. 이 방식은 positive visible-thermal 쌍과 최소 거리의 negative visible-thermal 쌍을 비교하는 것이라 합니다.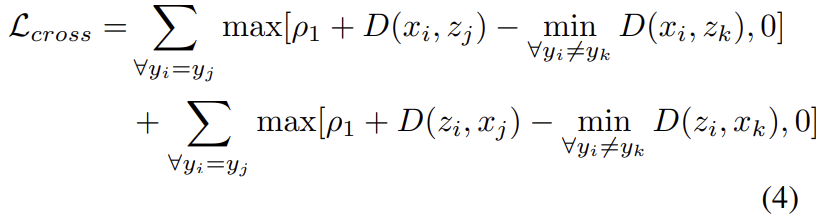
이러한 방식은 (1) top-ranking 제약 조건에 의해 cross-modality인 positive feature가 cross-modality간의 negative feature보다 가까이 있다는 것이 보장이 되므로 cross-modality의 변동성을 줄이면서 identity간의 차별성을 유지할 수 있고, (2) 양방향 훈련에 의해 학습된 feature가 모달리티 불변성을 가지도록 보장한다는 장점이 있습니다.
- Intra-modality Top-Ranking Constraint
re-ID는 동일한 사람이 여러 자세로 촬영될 수 있으며 여러 각도와 시점에서 촬영이 되므로 동일한 클래스 안에서도 variation 문제가 발생합니다. 해당 논문은 이를 해결하기 위해 intra-modality 유사도 제한을 도입하였고 아래의 식으로 정의하였다고 합니다.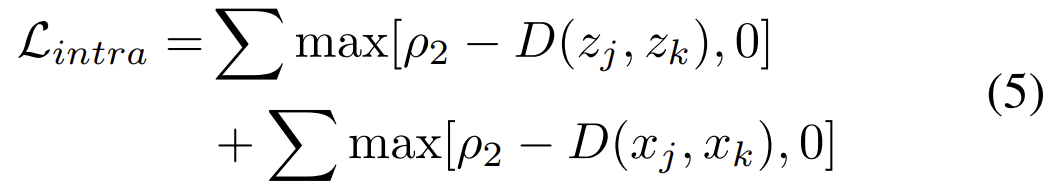
이때 \rho_2는 마찬가지로 사전에 정의된 margin값이고, 위의 제약 조건은 anchor와 다른 모달리티인 negative feature가 postive feature(마찬가지로 anchor와 다른 모달리티)와도 거리가 멀어지도록 역할을 합니다.
- Overall Embedding Loss
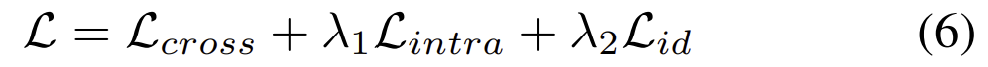
위의 식은 total loss로 앞서 설명한 loss들을 합치고 여기에 동일한 사람을 식별하도록 하기 위해 id loss를 추가하였다.(다른 논문들을 보았을 때 Re-ID에서는 id loss가 대부분 다 들어가는 것으로 보입니다. 일종의 classification loss라 생각하면 될 것 같습니다.)
- 학습 관련
dual-constrained ranking loss는 미니배치샘플링을 사용해야한다고 합니다. 이는 Cross-modality Top-Ranking Constraint에서 최소 거리의 negative visible-thermal 쌍을 구할 때 anchor와 모든 negative를 비교해서 가장 가까운 값을 찾아야 하기 때문에 전체를 고려하기 어렵다는 문제 때문인 것으로 이해하였습니다.
N(배치 사이즈)개의 id가 무작위로 선택되며 visible과 thermal에서 하나씩 선택하여 총 2N개의 이미지가 입력으로 들어가고, 여기서 N개의 visible anchor와 thermal anchor에 대해 loss를 구한다고 합니다.
Experiment
Dataset
cross-modal re-ID에서 많이 사용되는 두 데이터셋인 RegDB와 SYSU-MM01을 이용하였다고 합니다.
- RegDB
- 10개의 visible, 10개의 thermal 카메라로 촬영.
- 412 identity(사람) 포함.
- SYSU-MM01
- 4개의 visible 카메라와 2개의 thermal 카메라로 촬영
- 일부 사람이 실내와 실외에서 모두 촬영되어 challenging함.
Evaluation metrics
mAP와 CMC(cumulated matching characteristics)를 평가지표로 사용.
Experiment result
Ablation study
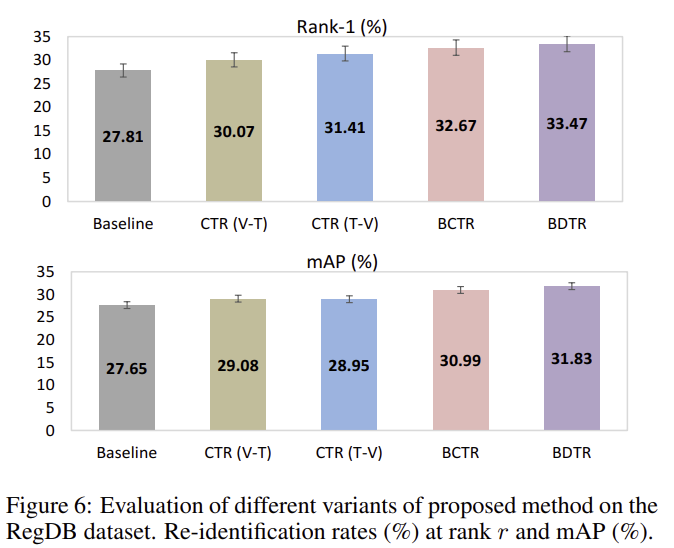
그림6은 RegDB에 대한 실험 결과로, “baseline”은 id loss와 일반적인 ranking loss를 이용한 결과, “CTR(V-T)”와 “CTR(T-V)”는 cross-modality top-ranking constraint를 추가한 결과, “BCTR”은 bi-directional 학습을 이용한 경우(visible to thermal와 thermal to visible을 모두 이용한 경우), “BDTR”은 intra-modality도 추가한 결과를 나타냅니다.
각 요소를 더할 때 마다 성능이 조금 씩 개선되는 것을 통해, cross-modality top-ranking의 효과와 양방향 학습의 효과, intra-modality constraint의 효과를 확인할 수 있습니다.
Comparison with the SOTA
다른 SOTA 방법론들과의 비교를 위해 visible to thermal 방식에 대한 실험 결과만을 정리하였다고 합니다.
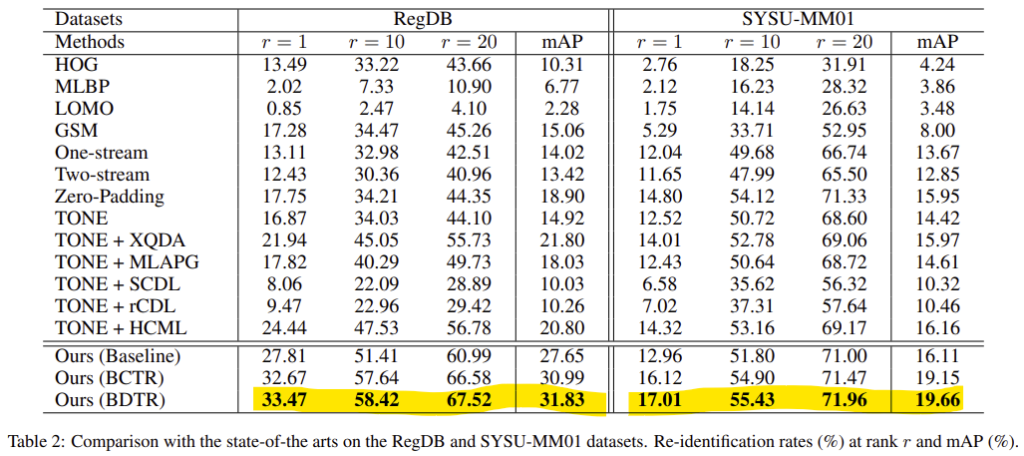
두 데이터 셋에서의 성능을 나타낸 것으로 다른 방법론에 비해 성능이 확연히 향상이 된 것을 확인하였습니다. 다른 방법론들과의 비교를 통해 제안된 방법의 장점은 두 가지로 요약할 수 있다고 합니다.
- 종단 간 학습을 통해 인간의 개입 없이 차별적 기능을 학습할 수 있다.
- dual-path 네트워크를 사용하여 제안된 dual-constrained top-ranking loss는 VT-REID에 대한 큰 cross/intra-modality variation을 해결하는 좋은 솔루션을 제공한다.
이번에는 thermal to visible과 visible to thermal에서의 결과를 모두 확인해본 실험입니다.
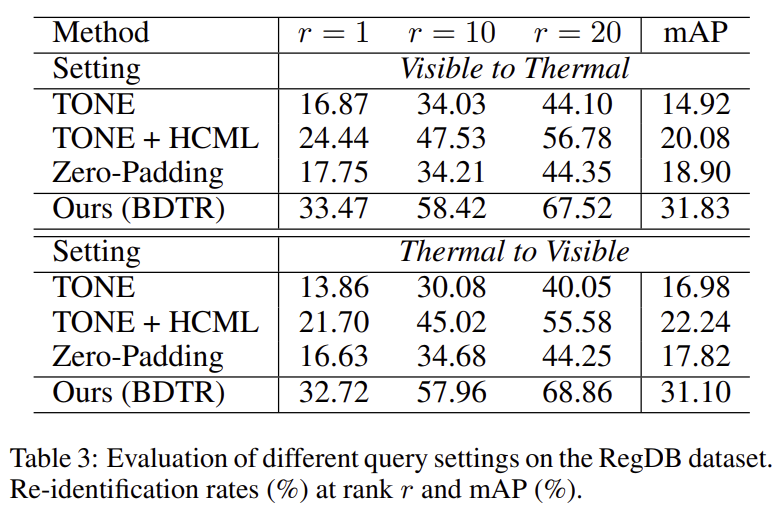
위의 표를 통해 visible to thermal와 thermal to visible이 유사한 성능을 내며, 다른 방법론들과 월등한 차이가 있다는 것을 확인할 수 있습니다.
좋은 리뷰 감사합니다.
논문의 contribution으로 ‘추가적인 contrastive learning이 없는 end-to-end 방식’이라고 나와 있고 마지막에도 인간의 개입없이 end-to-end로 차별적 기능을 학습한다고 되어있었습니다.
학습 과정 중 ranking loss가 존재하긴 하는데, 추가적인 contrastive learning이 없다고 말할 수 있는 이유가 무엇인지 궁금합니다.
‘추가적인 contrastive learning이 없다’는 것이 end-to-end를 의미하는 것으로 보입니다. 학습 과정에서 제약조건으로 loss를 줌으로써 학습 과정에서 바로 ranking loss를 이용해 학습한다!는 의미인 것 같습니다.
리뷰 읽어보다가 비슷한 의문이 생겼는데, 답변 주신 내용보고 이해가 되지 않아 질문드립니다.
우선, 말씀 주신 내용으로 보았을 때,
“추가적인 contrastive learning이 없다” = “학습과정에서 바로 ranking loss를 이용해 학습한다” 라고 말씀해주신 걸로 압니다.
이것으로 미루어 보았을 때, 저자는 여타 다른 loss function 없이 ranking loss만을 사용한 것이 contribution임을 주장하는 것으로 느껴집니다.
그러나, input이 어떠한 형태이든 (image, video, etc.) retrieval task에서는 기본적으로 사용하는 것이 ranking loss 인데 이 loss만을 사용하는 것이 어떻게 contribution이 되는지 의문이 듭니다.
실제로, 학습 과정에서 loss가 많아졌을 때 어떤 단점이 있는지 나와있지 않은 것 같구요.
결론적으로, 위 생각 하에 질문 드릴 것은 다음과 같습니다.
1. “추가적인 contrastive learning이 없다” 에서 단점으로 삼고 있는 “추가적인” 이라는 의미가, 학습 이전 행해지는 contrastive learning 이 필요없다를 의미하는 것인가요? (관련 연구에서 주로 사용되던)
2. 단순히 한번의 학습 과정에서 (모델이 수렴될 때까지의 한번) ranking loss만을 사용하는 것이 이점인 것이면(즉, 1번 질문이 아닐때), 어떤 측면에서 이점인건가요
오 re-identification이라니 뭔가 익숙하던 것 같았는데, 감정인식 제안서에서 봤던 테스크였네요. 그런데 피처 추출에 alexnet이라니 혹시 최근 워크도 같은 경향으로 연구가 진행되고 있나요? 사람 식별 및 얼굴과 관련된 연구는 더 빠르게 진행될거 같아서요. 그리고 두번째는 성능 향상이 정말 눈에 띌 정도로 큰 폭으로 향상되었는데, 저자가 생각하는 2가지 요약을 확인할 ablation study는 혹시 따로 있을까요? 아님 정성적 결과라든가..?
제가 서베이하며 찾아본 방법론들이 RGB와 Thermal 도메인을 고려한 cross-modality에서의 방법론이라 얼굴을 인식해 식별하는 네트워크는 잘 모르겠습니다. 제가 보았을 때 2020~2022논문들은 transformer나 resnet을 많이 쓰는 것 같습니다.
또한, 저자들이 ablation study 결과를 그림 6으로 표현하였습니다. 실험에 따르면 저자들이 제안한 cross-modality ranking loss를 추가한 경우가 CTR(V-T)와 CTR(T-V)에 해당하고, 여기서 양방향의 cross-modality ranking loss에 대한 결과는 BCTR, 마지막으로 Intra-modality Top-Ranking Constraint를 추가한 결과는 BDTR에 해당합니다.
안녕하세요. 좋은 리뷰 감사합니다.
동일한 사람은 동일하게 인식한다는 것이 흥미로운 task인 것 같습니다. Feature embedding을 같은 space에서 하는 부분이 감정인식 멀티모달에서 나오는 부분이라 더 재밌게 봤습니다.
Cross-modality Top-Ranking Constraint 부분이 잘 이해가 가지 않는데요. ‘positive visible-thermal 쌍과 최소 거리의 negative visible-thermal 쌍을 비교하는 것’을 통해서 어떤 효과를 가져올 수 있는지 잘 이해가 가지 않습니다. 이것을 통해서 어떻게 intra-class간의 차이가 inter-class간의 거리보다 커지는 문제를 해결할 수 있는걸까요?
loss 함수 자체가 positive visible-thermal쌍이 배치에 해당하는 이미지들 중 최소 거리의 negative visible-thermal 쌍보다는 가까워지도록 학습을 하기 위해 설계된 함수로, inter-class의 거리를 멀어지도로고 학습이 된다는 것에 초점을 맞추시면 이해가 될 것 같습니다.
안녕하세요 좋은리뷰 감사합니다
혹시 수식에서 로 가 의미하는바를 알 수 있을까요?
수식에서 rho는 margin을 의미합니다. 여기서 rho는 사전에 정의된 값으로, anchor feature와의 거리가positive+rho < negative 여야한다고 표현을 하는 데 사용합니다.