최근 제가 자주 리뷰하는 논문이 Self-supervised Learning 과 Active Learning 을 결합한 프레임워크와 관련된 것이었는데요. 이번에도 비슷한 논문입니다. 다만 이번 논문은 기존 Active Learning의 기본 가정인 “오라클(라벨러)는 항상 정답만 라벨링한다” 라는 것은 실제 환경과는 적합하지 않다고 지적하였다는 점에서 인상깊었습니다. 자세한 리뷰 바로 시작하겠습니다.
PAL : Pretext-based Active Learning

- Paper: BMCV 2021 [ 바로가기 ]
- Supplemental: [ 바로가기 ]
- Author Video: [ 바로가기 ]
- Code: [ Github ]
Background
Active Learning 이란 Annotation에 필요한 예산이 제한되어 있을 때 (예, 전체 데이터 중 N개의 데이터만 라벨링할 수 있는 상황) 모델에 가장 가치있을 하위 데이터셋을 선택하는 방법에 대한 연구입니다. 여기서 “가장 가치있다” 라는 말에 대해서 크게 두 가지 진영으로 나뉘어서 연구가 진행이 되고 있는데요. Uncertainty(혹은 Novelty)를 기준으로 데이터를 선별하는 진영에서는 ‘성능을 가장 큰 폭으로 향상시킨다’ 라고 정의를 내리고, Diversity를 기준으로 데이터를 선별하는 진영에서는 ‘데이터 별 중복을 줄일 수 있는 전체 분포를 아우른다’ 라고 정의 내리기도 합니다.

https://deepai.org/machine-learning-glossary-and-terms/active-learning
이런 Active Learning의 일반적인 프레임워크는 상단 그림과 같이 진행됩니다
- (Train) 소량의 Labeled dataset으로 데이터의 가치를 판단하는 모델을 학습합니다.
- (Inference) Unlabeled dataset에서 가치 있는 데이터를 M개를 선별합니다.
- (Data Query) 선별한 M개의 데이터를 오라클(어노테이터/라벨러)에게 라벨링을 하도록 쿼리합니다
- (Labeling) 오라클(휴먼 어노테이터/라벨러)는 M개에 대하여 직접 라벨링합니다.
- (Add & Re-Train) 라벨링한 데이터를 Labeled dataset에 추가한 뒤, 가치 판단 모델을 재학습 시킵니다.
- 2~5번의 과정을 라벨링 데이터가 사전에 정의한 라벨링할 예산 N개가 될 때까지 반복합니다.
보통 이 과정이 K번의 사이클로 구성되기 때문에 한 사이클에서 모델은 M=N/K개의 데이터를 선별하게 됩니다. 그런데 앞서 설명한 다양한 진영의 연구를 막론하고 기본 전제가 되는 가정이 있는데요. 그것은 바로 “오라클이 라벨링하는 것은 항상 정답이다” 라는 것이죠.
(저는 사실 처음에 오라클에게 요청하고 라벨링하는 과정을 연구진들이 직접하는 줄 알았습니다만) 오라클이 라벨링하는 것이 항상 정답이다 라는 가정때문에, 해당 연구의 코드는 5)번 과정에서 선별한 데이터의 GT를 가져오는 방식으로 동작하고 있습니다. 즉, 이미 x-y pair를 가지고 있는 상태로 선별 데이터의 y값을 추가하여 모델을 재학습하는 형태로 연구가 진행되고 있습니다.
Introduction
그런데 저자가 주목한 포인트가 바로 저 가정이죠. 실제 시나리오에서 오라클이 항상 정답을 반환할 리가 없다는 것이죠. 아마 어노테이션을 해보신 분들이라면 어느정도 공감하실 것 같습니다. 따라서 저자는 오라클이 반환하는 라벨링 데이터의 의존도를 줄여야만 한다고 주장합니다. 또한 오라클이 반환한 라벨 데이터로 모델을 학습하는 Task Network의 의존도 역시 줄여야한다는 것이 저자의 주장이죠. 오히려 노이즈가 될 수 있기 때문에, 저자는 이 라벨에 대한 의존도를 줄이는 대안으로 Self-Supervised LEarning 을 사용하였습니다. 즉, unlabeled sample이 SSL에 잘못된 예측을 주는 정도를 가치 있는 데이터를 판단하는 “Uncertainty 지표”로 사용하였습니다. 게다가 Self-Supervised Learning 을 통해 생성되는 Pseudo-Label은 오라클에게 라벨링을 요청하는 것보다 훨씬 효율적이죠. 따라서 저자는 Active Learning 에 Self-Supervised Learning (SSL) 를 적용한 PAL (Pretext-based Active Learning)을 제안하였습니다.
Method: Pretext-based Active Learning
기존 연구들이 Task Network 하나만을 사용해서, 데이터의 가치를 판단하고 Task 를 수행하였다면, 저자는 Scoring Network 라는 또다른 네트워크를 사용하여 데이터의 가치를 점수화하는 네트워크를 설계하였습니다. 다시말해, 저자는 데이터의 가치를 판단하는 기준으로 Scoring Network의 출력을 사용한 것이죠.
여기서 특징은 이 Scoreing Network는 두 개의 헤드를 가지는 Multi-Task Network라는 것이죠. 하나는 Self-Supervised Leanring 이고, 나머지 하나는 Classification을 위한 헤드가 되며, 이 헤드의 출력은 unlabeled image x_u에 대한 Confusion Score (Uncertainty) S 가 됩니다. 아래 그림이 바로 Scoring Network를 나타낸 그림입니다.
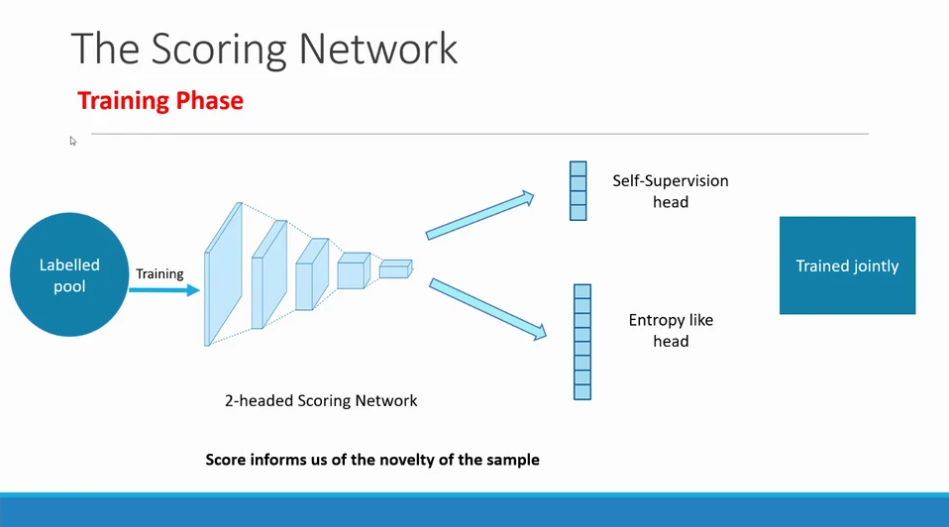
Method: [1] Self-Supervision head
Scoring Network의 하나의 헤드인 SSL head에서는 labeled 샘플의 분포 하에서 unlabeled 샘플의 likelihood를 추정합니다. 즉, SSL 학습을 통해 출력된 likelihood를 self-supervision score S_S 를 사용하게 됩니다. 여기서 SSL 기술로는 Randomized Rotation of Classification 예측하기를 사용하였습니다. 해당 방법은 제가 많이 언급했던 방법인데요. 이미지를 90/180/270/360으로 회전시키는 Augmentation을 적용한 뒤, 그 회전 각을 예측하는 기술입니다.
학습은 초기에 가지고 있는 소량의 Labeled Dataset인 D_L 만을 사용하였으며, 이에 대한 Score S_S는 다음과 같이 정의됩니다. 아래 수식에 따라 g_\phi는 회전각을 예측하는 네트워크가 되겠죠?
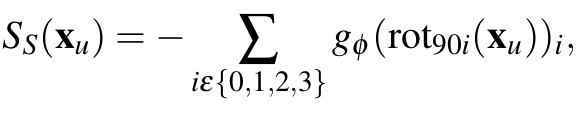
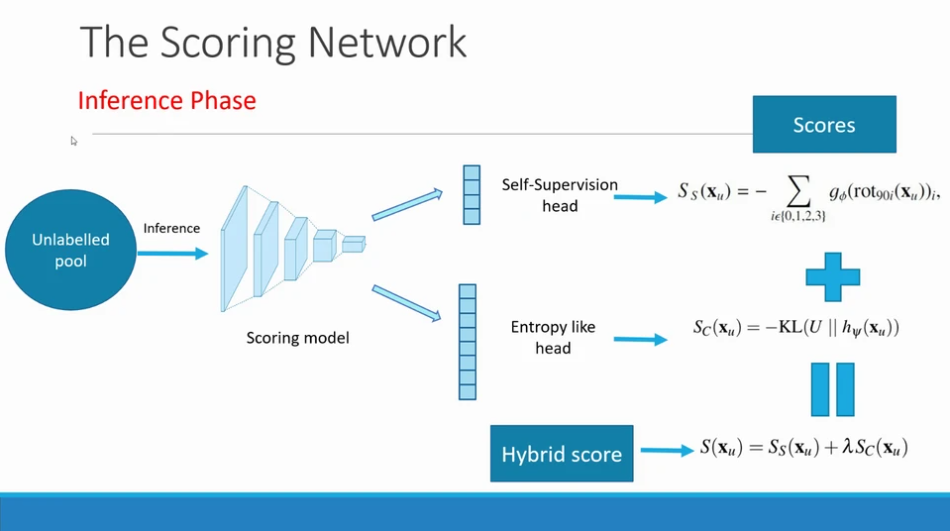
Method: [2] Classification head and Hybrid Score
Scoring Network는 Multi-task Network로 두 개의 헤드로 구성되어 있다고 하였습니다. 나머지 두번째 Head가 바로 Classification head 입니다. Labeled Data를 사용하여 지도학습 기반으로 학습하는 네트워크가 되겠죠. 보통 active Learning 에서는 이 classification head만을 사용하여 데이터의 가치를 판단하고는 합니다. 그러나 저나는 멀티 태스크 러닝을 사용함으로써 소량의 데이터를 학습하였을 때 가질 수 있는 한계를 네트워크 Regularization으로 극복할 수 있었다고 합니다. 또한 회전 대칭을 가지는 이미지와 같은 특정 종류의 이미지에 대한 ScoreS_S가 가지는 비신뢰성을 완화하는 데에도 도움이 되기도 합니다.
따라서 저자는 두 개의 헤드를 가지는 Scoring Network를 학습시켜서, 데이터의 가치를 점수화할 수 있도록 하였습니다. 따라서 Classification head의 output에 대하여 KL divergence를 두번째 Score S_C로 사용하였습니다. 그리고 이렇게 구한 S_C 와 S_S를 더하여 데이터의 가치를 평가하는 점수를 구할 수 있었다고 합니다. 아래 수식이 데이터의 가치를 판단하는 Score S에 대한 수식입니다. 아래 수식에서 h_\psi 는 Classification 헤드에 대한 네트워크가 되겠습니다!
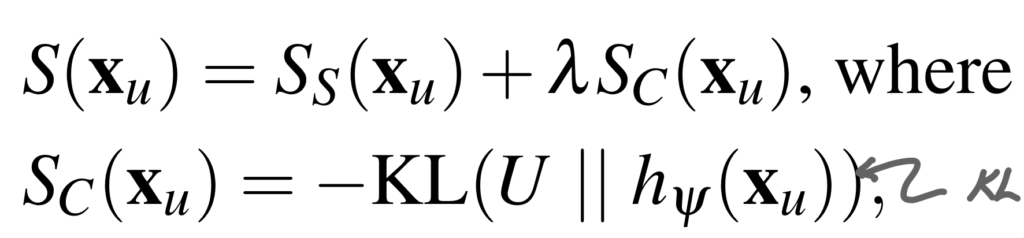
Method: [3] Diversity Score
이렇게 Scoring Network를 보면 저자는 Uncertainty를 기반으로 데이터를 선별하였음을 알 수 있습니다. 그러나 여기서 그치지 않고, 저자는 Diversity까지 고려할 수 있는 추가적인 아이디어를 제안하였는데요. 여기가 저자가 말한 Labeled 의 의존을 줄이는 방법을 제안한 부분이라고 할 수 있습니다.
우선 K번의 사이클이 수행되기 때문에 저자는 N/K 인 K개의 Sub-queries로 데이터를 분할하는 방법을 선택하였습니다. 우선 앞서 이미 Labeled 를 사용하여 학습을 마친 Scoring Network를 통해 반환된 S 에 따라 첫번째 사이클에서는 가장 높은 값을 가지는 N/K개의 데이터를 선별합니다. Background 중 Active Leanring 의 파이프라인 순서랑 엮어서 말씀드리자면, Scoring Network를 학습하는 과정이 1번 과정이 됩니다. 그리고 2번 Inference 과정으로 가장 높은 S를 가지는 N/K개의 데이터를 선별합니다. 그 다음, 3-4번에서 오라클에게 라벨링을 요청하는 과정은 동일한데, 5번 Re-train에서 Labeled 를 사용하여 모델을 재학습시키는 것이 아닌 SSL 방식으로 모델을 재학습합니다. 즉, 선별된 N/K개의 데이터를 회전 각도를 예측하는 방식으로 Scoring Network를 fine-tunning 합니다. 이 과정을 통해 Scoring Network는 그동안 보지 못한 새로운 분포의 데이터를 볼 수 있어 Diversity를 고려할 수 있다는 것이 저자의 주장입니다.
또한 첫번째 쿼리가 마치고 추가된 데이터로 튜닝된 Scoring Network를 사용하여 새로운 Score S를 반환할 수 있도록 재정의하였습니다. 아래 수식이 바로 2번째 사이클에서부터 사용되는 Score 입니다. 가장 마지막에 붙어있는 S_D 의 경우, 이전 Sub-queries에서 이미 선택된 포인트와 유사한 데이터의 경우 크기가 작고, 새로운 데이터에 대해서는 큰 값이 반환되기 때문에 다양성을 고려한 Active Learning을 제안하였다고 할 수 있을 것 같습니다. 아, S_D의 경우, 튜닝된 네트워크로부터 반환된 S_S입니다. 즉, SSL Head의 반환 값인 수식1과 같이 정의내릴 수 있습니다.
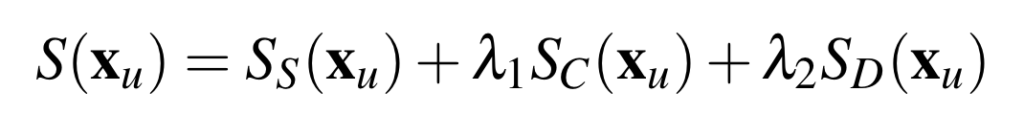
이렇게 PAL에 대한 과정을 알고리즘으로 정리하면 아래와 같습니다. 다소 복잡해보이지만, 생각보다 간단한 방법으로 SSL과 AL을 혼합하였다는 생각이 듭니다.

Experiments and Results
데이터셋으로는 CIFAR-10, SVHN, Caltech-101, Cityscapes를 사용하였습니다.
초기 데이터셋의 크기는 보통 10%이며, 한 사이클에서 추가되는 데이터는 5%입니다. 실험 결과는 5번의 결과를 평균 취한 것이라고 하네요
또한 비교 실험을 위한 방법론으로는 (1) Random Sampling (2) Entropy (3) VAAL (4) DBAL (5) Core-set을 사용하였습니다. Diversity 기반의 방법론(3,4,5)들이 많은데 정작 Uncertainty만을 기반으로한 연구들과 비교하지 않은 건 조금 아쉬운 부분입니다. (결국 저자가 제안하는 Scoring Network가 Uncertainty 인 것 같은데 말이죠... 물론 3, 4를 Uncertainty를 저자와 같이 DIversity를 동시에 고려한 방법론이라고 할 수 있긴 합니다. 그러나 Uncertainty만을 보는 방법론으로 가장 간단한 (2)번만 있다는 것은 약간 아쉽다고나 할까요..?)
Results: [1] Performance with error-free labels
우선 아래 보시는 것과 같이 기 방법론 대비 높은 성능을 보인다는 것을 알 수 있었습니다. 더욱 인상깊은 것은 PAL은 SVHN을 한개의 11GB GPU에서 학습하는 데 사이클 당 약 2시간이 필요한 반면, VAAL의 경우 24시간 이상이 걸렸다는 점을 주장하며 모델의 복잡도까지 잡았다고 주장하였습니다./
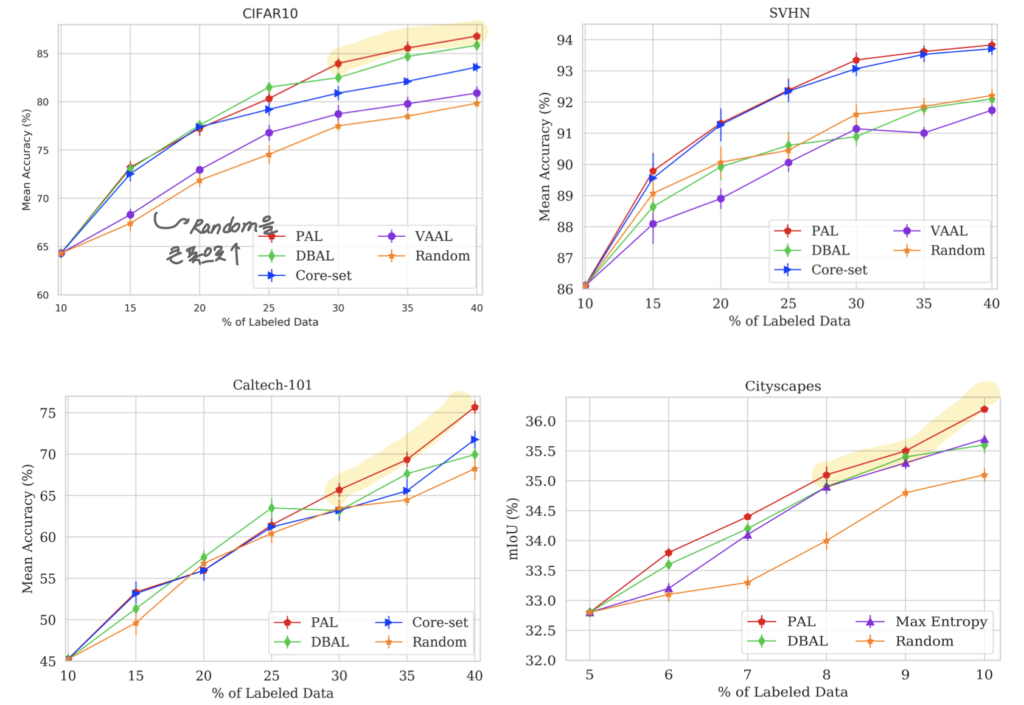
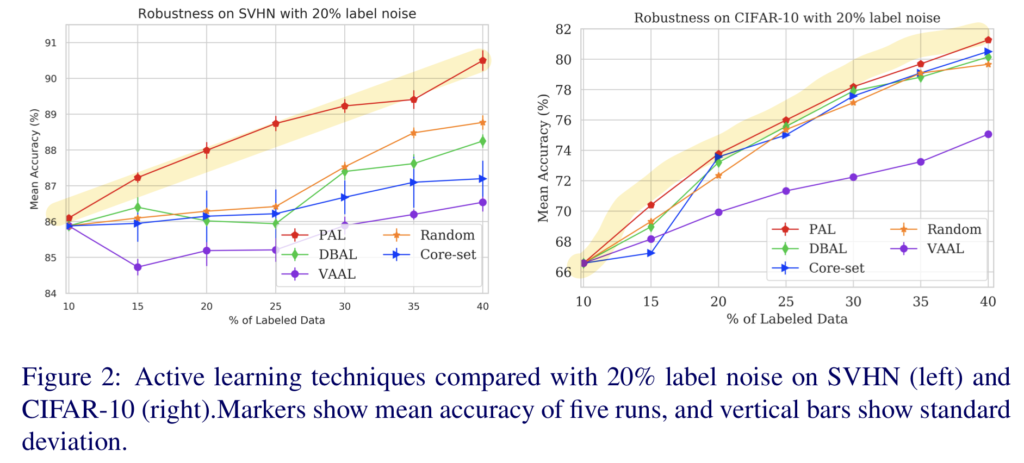
Results: [2] Robustness to sample mislabeling
이제 여기서 저자가 주장하는 mislabeling이 발생하였을 때의 효과를 비교한 파트입니다. PAL의 경우 가치 판단 모델을 업데이트하는 데에 SSL 을 사용하기 때문에 잘못된 라벨링이 발생되더라도 영향을 덜 받을 것이라고 저자가 주장하였는데요,
이를 확인하기 위해 20% 데이터셋 라벨에 오류를 넣어서 실험을 진행하였습니다. 그 결과 아래와 같이 기 방법론 대비 더 좋은 성능을 달성할 수 있었다고 합니다.
Conclusion
잘못된 레이블링에 대응하기 위한 Pretext-based Active Learning 을 제안한 연구였습니다. 그런데 SSL이라고 한다면 전체 Unlabeled 를 사용할 수 있었을텐데, 그 비교를 하지 않은 것은 다소 아쉬웠습니다. 멀티 헤드로 사용하는 것 굉장히 신박한 방법이었는데 좋은 아이디어를 얻은 논문이었습니다.
좋은 리뷰 감사합니다!
한가지 궁금한 것이 있습니다.
멀티태스크 러닝을 통해 ‘특정 종류의 이미지에 대한 ScoreS_s가 가지는 비신뢰성을 완화하는 데 도움이 되었다’고 하셨는데, 어떤 점에서 비신뢰성이 완화되었다고 할 수 있는 지 설명해주실 수 있나요?? 두 태스크에 대한 결과를 이용할 때 하나의 네트워크에서는 오류가 있더라도 다른 네트워크를 통해 어느정도 오류를 상쇄시킬 수 있다는 것인가요??
예를 들어 180도 회전해도 동일한 대칭을 이루는 이미지의 경우 180도 회전각이라고 예측해야하는데 360라고 예측한 결과에 대해 높은 신뢰도를 가지는 경우라고 생각하면 좋을 것 같습니다. 따라서 라벨이 있는 다른 헤드로 이에 대해 규제화를 해주는 것으로 이해하면 좋을 것 같네요
안녕하세요. 좋은 리뷰 감사합니다.
AL에 대해서 비판하는 논문이 많았던거 같은데 SSL이라는 방식으로 AL을 이용하여 다른 모델에 비해 높은 성능을 낸것이 굉장한 아이디어인거 같습니다.
중간에 ‘5번 Re-train에서 Labeled 를 사용하여 모델을 재학습시키는 것이 아닌 SSL 방식으로 모델을 재학습합니다’ 라고 하셨는데 제 생각에는 회전 각도를 예측하는 방식으로 fine-tuning 하지 않아도 labeled 된 데이터로 재학습하면 새로운 분포의 데이터를 볼 수 있어 마찬가지로 diversity를 고려할 수 있지 않을까 생각하였는데요. 주영 연구원님께서는 이 부분에 대해서 어떻게 생각하시나요?
음 저자는 일부로 labeled를 사용하지 않고 재학습하기 위해 SSL 기반의 학습 방식을 채택한 것입니다.
해당 논문의 저자는 오라클이 만든 라벨은 항상 정답일리가 없다는 것을 바탕으로 최대한 이 라벨 데이터의 의존도를 줄이도록 어떻게 모델을 학습시킬까에서부터 연구를 시작하였습니다. 다시 말해, 일부로 unlabeled만으로 모델을 재학습 시킨 것입니다.
김주연 연구원이 말한 방법은 이 해당 논문의 시작 및 동기에 맞지 않는 것 같고, 추가로 labeled만 추가하는 것은 ssl이 없는 기존 연구와 다를게 없어서 분포를 고려하긴 어려울 것 같다는 게 저의 사견이긴 합니다
안녕하세요 좋은 리뷰 감사합니다
Scoreing network가 기존의 uncertainty prediction network와 같은 작동을 하는것 인가요? Ssl을 고려하는 가치판단네트워크라면 ssl loss를 포함한 al방법론과의 성능비교가 궁금하네요..
네 저희가 베이스로 삼았던 Learning Loss와 비슷한 맥락으로 보시면 될 것 같습니다. 저도 그 부분이 궁금하기도 하고 SSL을 사용하는 것이 앞으로 저희가 나아가야할 방향성이라 생각해서 직접 비교해보는 것도 좋을 것 이라 생각이 되긴 합니다