논문 소개
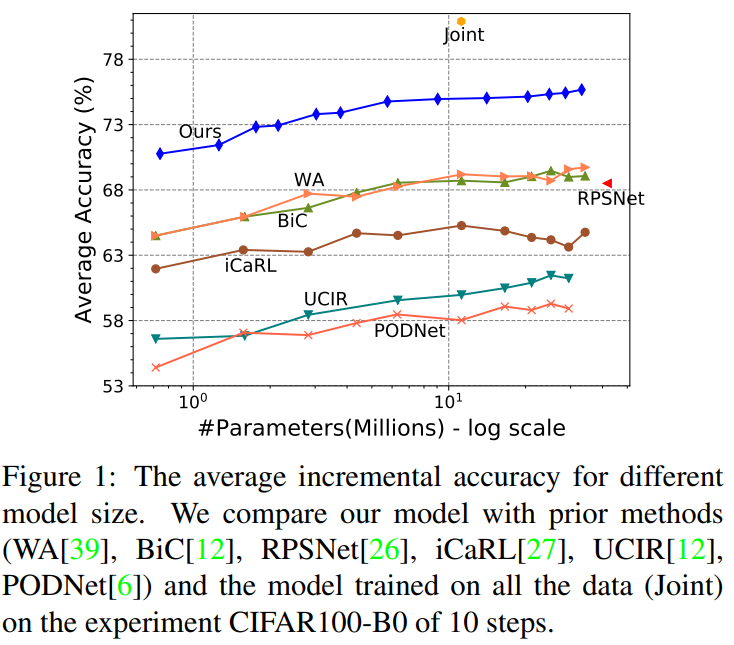
본 논문은 incremental learning 문제를 해결하기 위한 논문이다. incremental learning이란, 모델이 지식을 확장하는 학습 방법론 중 하나로, old data로 학습한 모델을 new data로 학습하기 위한 방법론이다. 그렇다면 새로운 데이터로 모델 재학습 시 대응해야할 문제점이 무엇일까? 바로 catastrophic forgetting, old data를 잊어버리는 문제점이다. incremental learning 분야에서는 stability-plasticity trade-off를 주요 문제점으로 보고있는데, new data를 잘 받아들이기 위한 가소성(plasticity)과 old data를 잊지 않고 통찰력 있는 모델로 개발하기 위한 안정성(stability)간의 균형이 있는 모델을 찾는 것을 목적으로 한다. 본 논문 역시 new data에 대한 수용성을 갖으면서도 old data를 잊지 않는 모델을 개발하고자 하였으며, 제목에서 드러났듯이 인공지능 모델이 확장가능하게 설계하므로서 문제를 해결하였다. incremental learning은 해당 문제를 해결하기 위해 old data의 좋은 subset을 저장해놓고 재학습하는 rehearsal 기법, 인공지능 모델 파라미터 변동에 제약을 가하는 regularization 기법 등이 있으며 본 논문이 접근한 모델 확장방식은 뇌의 학습방식인 신경가소성과 유사한 측면이 있다. 본 논문은 task 증가에 대해 new feature extractor를 설계해 feature map을 생성하며, task 확장에 따라 feature map 갯수가 증가하는 expandable representation을 허용한다. 이러한 방식으로 만든 feature를 super-feature라고 명명하였다. CIFAR-100, ImageNet-100, ImageNet-1000에 대해 실험을 진행하여 제안방법의 우월성을 보였으며 figure1에서 확인할 수 있듯이 모든 old 데이터를 사용하는 joint 학습성능에 가장 비교 방법롭 대비 가까운 성능을 보임을 확인할 수 있다.
방법론
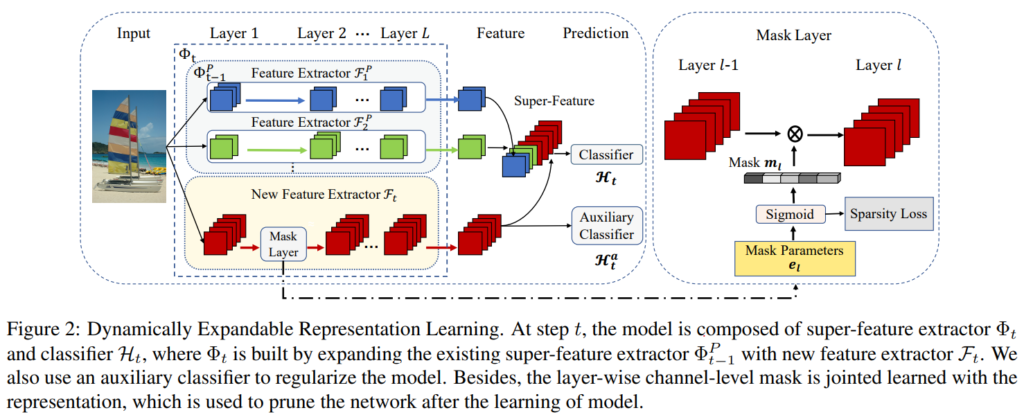
논문이 제안하는 모델 학습 프로세스, Dynamically Expandable Representation Learning(이하 DER)은 Figure2와 같이 명확하다. task 추가에 따라 새로운 feature extractor를 추가하였으며 해당 extractor로 추출한 representation map for new task으로 기존 모델의 feature를 확장하는 super-feature를 추출한다. 이때 feature의 복잡도가 task 추가에 따라 너무 증가하지 않도록 별도의 mask layer를 구성하여 복잡도를 줄였다. 복잡도 조정에 따른 비교 실험은 experiments의 ours (w/o P)로 같이 리포팅되었다. 새로운 extractor(F_t) 도입시, 기존 extractor(F_t-1)를 통해 초기화하여 사전 지식 활용을 통한 빠른 최적화를 유도하였다. 사전 지식을 이용해 과거에 지식에 대해 너무 동떨어지지 않으면서도 new data에 대한 학습을 제한하지 않음으로써 학습의 유효성을 최대화한 접근법이라 할 수 있다.
모델학습을 위한 목적함수는 new data(=incoming data)를 위한 target 함수(cross-entropy, classifier)인 H_t Loss, old task와 new task를 명시적으로 분리하도록 학습하는 보조 loss 함수(cross-entropy, auxiliary classifier)인 H_t^a Loss, 모델의 복잡성을 최소화하기 위한 Sparsity Loss로 구성되었다. 각 수식은 [수식1]과 같으며 H_t^a Loss는 입력 데이터를 y+1개의 class로 구분한다. (y는 new data의 class 갯수, 1은 old data를 의미)
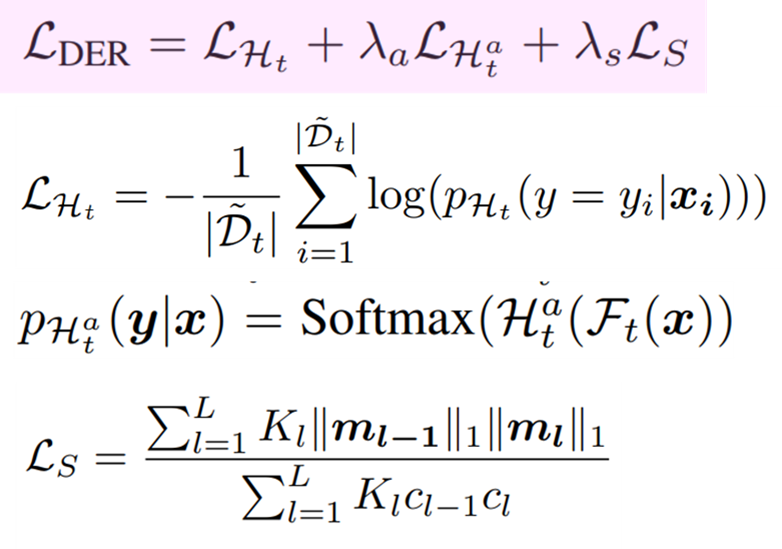
mask layer의 진행 과정은 channel-level로 진행된다. 새로운 extractor F_t의 출력 f_l는 마스크 m_l에 의해 channel-level의 masking 과정을 거친다. 이때 m_l은 [0,1]로 구성되어 feature를 이진화한다. m_l은 [수식2]와 같으며 σ는 sigmoid function, s는 상수, e는 mask layer parameter 이다.
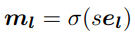
DER은 확장수용방식으로 위와같은 모델 학습을 진행한 이후 balanced로 가공된 전체클래스(old, new 포함)에 대한 subset으로 fine-turning과정을 포함한다. balanced dataset의 스케일은 데이터셋마다 다르며 실험파트에서 확인할 수 있다.
Experiments
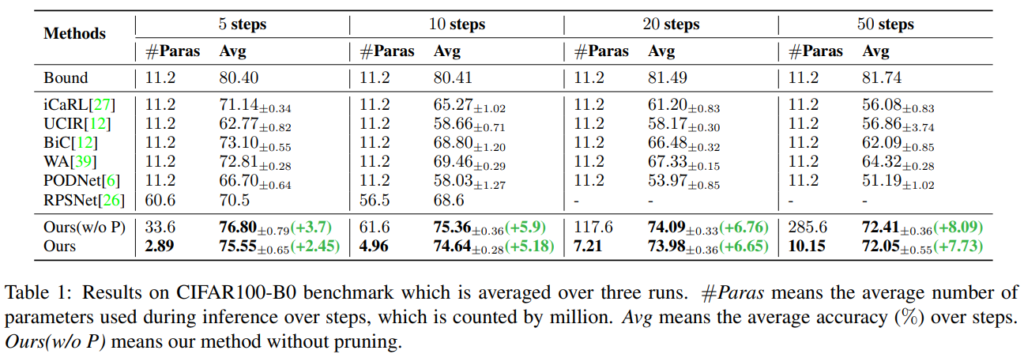
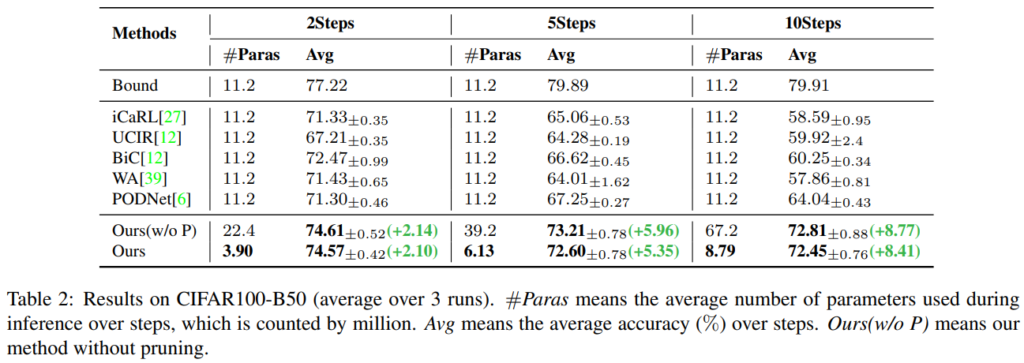
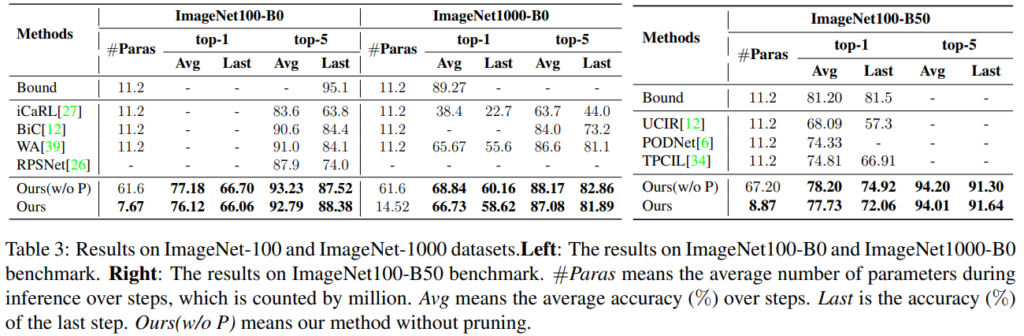
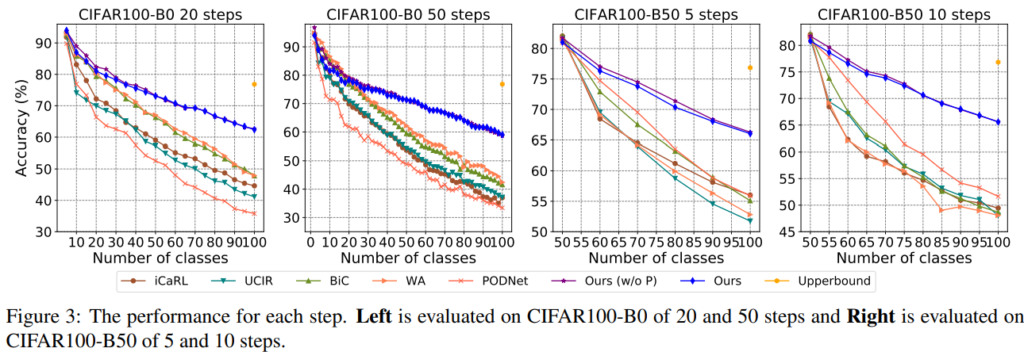
실험은 CIFAR-100, ImageNet-100, ImageNet-1000 데이터 벤치마크에 대해 Image classification 수행능력으로 비교진행되었다. 최신 연구들과 제안 방법론(DER, 표기 Ours)을 비교하였으며, 상한선으로 모든 old data를 활용하는 joint learning 성능을 같이 제시하였다. new data의 도입 사이클을 n step으로 나누어 실험을 진행하였으며 각 실험에서 비교군 대비 upper와 가장 가까운 성능을 보임을 증명하였다. 비교군과의 성능 격차는 figure3을 통해 시각적으로 명확하게 확인할 수 있다.
모델 fine-tunining을 위해 사용된 balanced subset의 스케일은 다음과 같다.

Discussion
본 논문은 모델을 확장한다는 직관적이고 확실한 방법으로 incremental learning분야의 문제를 효과적으로 해결하였다. 그러나 task의 확장 정도에 따라 모델의 크기가 선형적으로 증가하므로 추가하는 task가 무한대인 경우에 제안하는 방법론은 효과적이지 않을 수 있다.
마스크 생성 방식은 수식의 설명이 이해가 어려워 코드를 참조하려 하였으나 공개된 깃허브에 구현이 되어있지 않은 점에 아쉬움이 있다.
좋은 리뷰 감사합니다.
본 논문이 Task 확장에 따라 feature map 갯수가 증가하는 expandable representation 을 사용하였다고 하셨는데요, 그렇다면 이건 여러개의 태스크를 동시에 학습하는 멀티 태스크르 위한 방법론인건가요?
여러 태스크를 확장하기위해 사용은 가능하나 해당 논문이 공개한 실험처럼 class를 추가하는 정도로 적용하는것이 일반적입니다.
안녕하세요 좋은 리뷰 감사합니다.
1) ‘task 추가’라는 표현이 계속 등장하는데 이거는 말 그대로 기존task가 아닌 다른 task틑 의미하는 걸까요? 아니 new data가 추가된다는 표현으로 받아들이면 되는 걸까요?
2) 새로운 데이터로 모델을 재학습할때 old data를 잊는 문제가 있다고 하셨는데, 새로운 데이터로 모델을 재학습할 경우 이전에 학습한 모델의 파라미터만 가지고 다시 학습을 시키는 것과 같기 때문에 old data를 잊어버린다고 하는 건가요?
1) task 추가로 받아들이시면 되며 해당 논문에서는 classification에 대한 실험을 진행하였으므로 해당 논문 한정으로는 CLASS 추가로 이해하셔도 큰 문제 없습니다.
2) new 데이터에 대해서만 학습하므로 이에 맞추어 파라미터 업데이트를 진행하며 이전 데이터의 분포를 잊게되는 문제입니다.