이번에 소개드릴 논문은 ICLR2019년에 게재된 논문으로 상당히 재밌는 논문입니다. 내용은 제목에서도 볼 수 있다시피, ImageNet으로 학습된 CNN은 texture의 편향이 되어 있으며, shape에 편향되도록 할 경우 모델의 정확도와 강인함을 얻을 수 있다는 것입니다.
이주 전에 리뷰로 작성한 SagNet도 해당 논문에 영감을 받아서 shape biased learning을 제안한 것으로 알고 있는데, 해당 리뷰를 보셨다면 이번 논문의 내용도 쉽게 이해하실 수 있을 것 같습니다.
Intro
논문의 첫페이지를 딱 열면 Teaser 이미지로 다음 영상이 존재합니다.
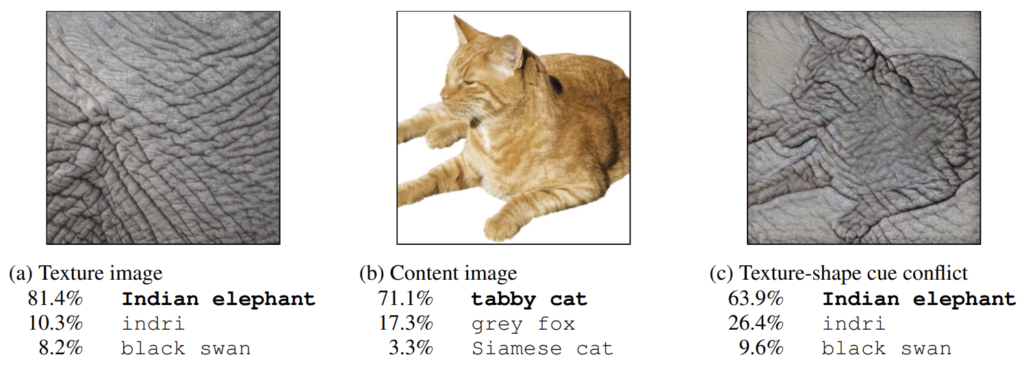
그림1만 봐도 논문에서 무엇을 말하고자 하는지 쉽게 알 수 있습니다. 바로 CNN이 물체를 인식할 때는 영상의 텍스처에 편향되었다는 것이죠. 조금 더 자세히 설명을 하면, 그림1에서 a 이미지는 인도 코끼리의 패치 영역을 모델의 입력으로 주었더니 81.4% 확률로 인도 코끼리라고 예측한 모습입니다.
2번 째 영상은 말 그대로 고양이 영상을 입력으로 주었더니, 모델이 71.1% 확률로 고양이라고 예측한 모습이죠. 흥미로운 점은 그 다음 실험입니다. 3번째 입력 영상으로 style transfer 방법론을 통해 2번째 영상을 content, 첫번째 영상을 style로 놓고 고양이의 모양에 인도 코끼리의 텍스처를 입혔습니다.
이렇게 스타일이 변환된 영상을 모델에 입력으로 넣었을 때, 그 모델은 과연 이를 고양이라고 예측할까요? 코끼리라고 예측할까요? 일반적으로 사람이라면 전반적인 형태를 보았을 때 고양이가 보이므로, 해당 사진은 고양이라고 분류할 것입니다. 하지만 CNN은 이러한 기대와 달리 63.9% 확률로 인도 코끼리라고 분류한 모습입니다. 심지어 3순위까지 고양이는 볼 수도 없네요.
이러한 그림 한장이 논문에서 주장하고 싶은 모든 내용을 담았습니다. 해당 논문은 이미지넷으로 학습한 CNN은 모두 텍스처에 편향되어서 물체를 인식한다는 것입니다. 사실 CNN이 물체를 어떻게 인식하는가에 대해서는 많은 연구자들이 관심있어 했습니다. CNN이 영상의 어느 부분을 확인하는지를 알게 된다면, 성능은 우수하지만 그 과정 자체는 해석할 수 없는 블랙박스였던 CNN을 이해할 수 있는 첫걸음이라고 생각했기 때문이죠.
기존의 많은 연구자들, 심지어 얀 르쿤 교수님도 CNN은 shape에 편향되어 물체를 인식한다고 주장했습니다. 물론 이들과 반대로 CNN은 texture에 편향되어서 물체를 인식한다는 주장들도 있긴 했었죠. 해당 논문도 이러한 texture에 편향되었다고 주장하는 진영 중 하나인 듯 보입니다.
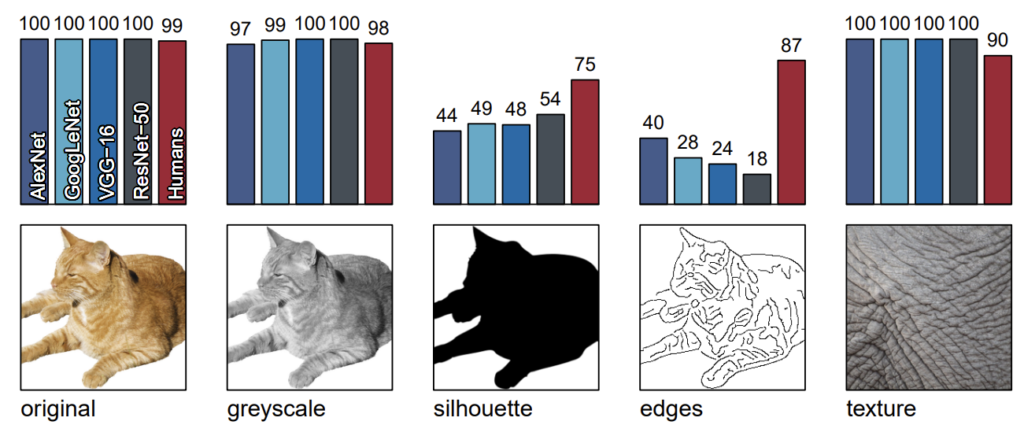
그림2는 CNN 모델들이 텍스처에 편향되었다는 것을 보여주는 또 한가지의 실험입니다. 제일 좌측에 평범한 RGB 고양이 영상을 AlexNet, GoogleLeNet, VGG, ResNet 그리고 사람에게 보여주면 모두 올바르게 고양이라고 예측을 합니다.(Human이 99면 틀린 1은 뭐지ㅋㅋ)
그리고 2번째 실험으로는 동일한 영상을 흑백으로 변환해서 제공했더니 이 역시도 거의 대부분 정확하게 예측했다고 합니다. 하지만 3번째 부터는 얘기가 좀 달라집니다. 3번째 영상의 경우에는 배경은 흰색, 전경은 검정색으로 하여 고양이의 실루엣만을 입력으로 제공하였더니 CNN 모델들의 정확성이 상당히 낮아지는 것을 확인할 수 있습니다.
이와 반대로 사람의 경우에는 물론 RGB 영상을 넣었을 때 보다는 다소 떨어지긴 했지만 상대적으로 상당히 강인한 모습을 보여주고 있습니다. 입력 영상을 edge 영상으로 하였을 경우 사람의 정확도는 더 크게 올라가는 반면에, CNN 모델들 특히 Resnet의 성능이 매우 크게 떨어지고 있습니다.
또한 그림1에서도 보았던 인도 코끼리의 일부 영역을 입력으로 제공했더니 사람은 잘 못맞추는 반면 CNN 모델들은 모두 정확하게 인도 코끼리를 예측했다고 합니다. 이러한 관점에서 사람은 대상을 인식할 때 전체적인 사물의 형태를 살피는 반면에 CNN 모델들은 대상의 일부 텍스처만을 보고 판단하는 것을 확인할 수 있습니다.
그렇다면 여기서 저희가 정확히 짚고 넘어가야하는 부분이 있습니다. 이미지넷으로 학습된 CNN이 텍스처에 편향된 이유는 “이미지넷”이라는 데이터 셋의 문제일까요? 아니면 “CNN”이라는 모델의 문제일까요? 결론부터 말씀드리면 저자는 해당 문제는 이미지넷 데이터 셋의 문제라고 합니다. 이미지넷은 물체를 분류할 때 대상의 전체적인 형태 없이 일부 텍스처 정보만으로도 충분히 분류할 수 있기 때문에 모델이 더 쉬운 학습 방법인 local texture에 편향되어 학습이 된다는 것입니다.
Dataset
그리하여 저자는 CNN이 texture보다는 shape에 편향되도록 학습시키기 위하여 Stylized-ImageNet(SIN)이라는 데이터 셋을 새롭게 제안합니다. 해당 데이터 셋은 이미지넷 영상들을 content로 삼아 Adaptive Instance Normalization(AdaIN) style transfer 기법을 활용해서 새로운 스타일의 이미지를 만든 것입니다.

Experiments
해당 논문은 딱히 그럴다한 방법론은 없습니다. 다만 CNN이 과연 어떻게 동작하는지를 분석하기 위해 texture와 shape이 서로 상이한 데이터 셋들을 새롭게 제안하고 해당 데이터 셋으로 CNN 모델을 texture보다는 shape에 편향되도록 학습을 하는 그런 다양한 실험들을 진행합니다.
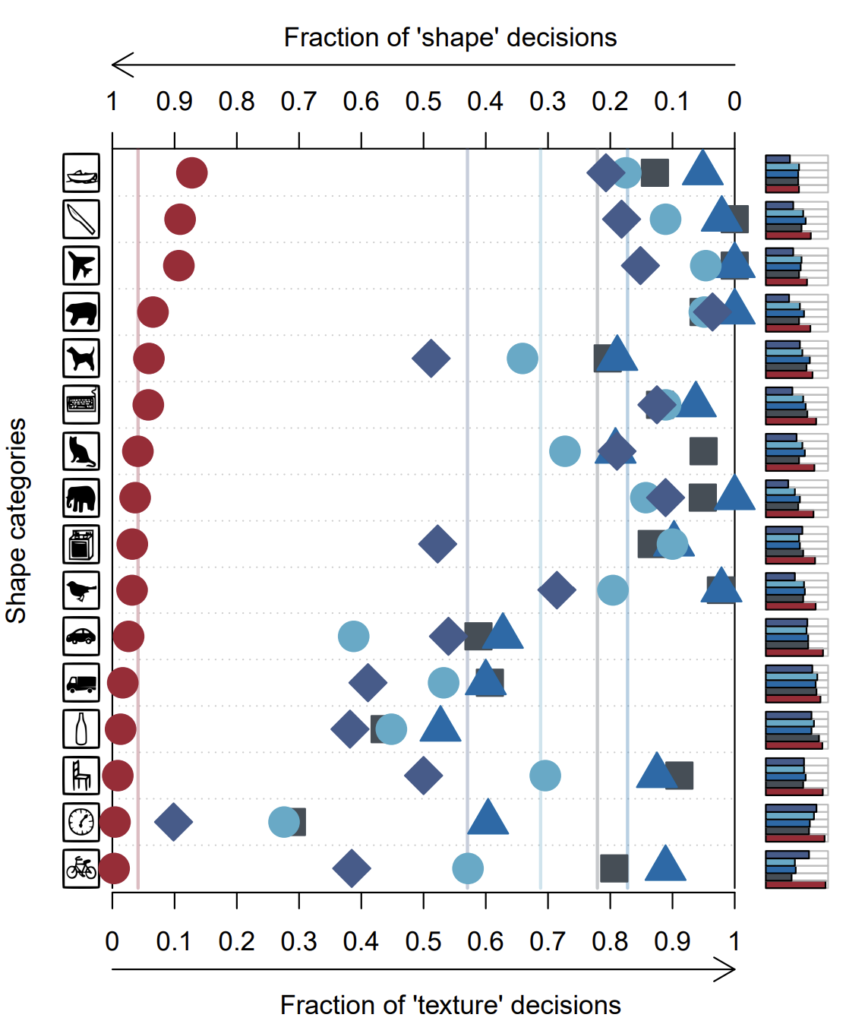
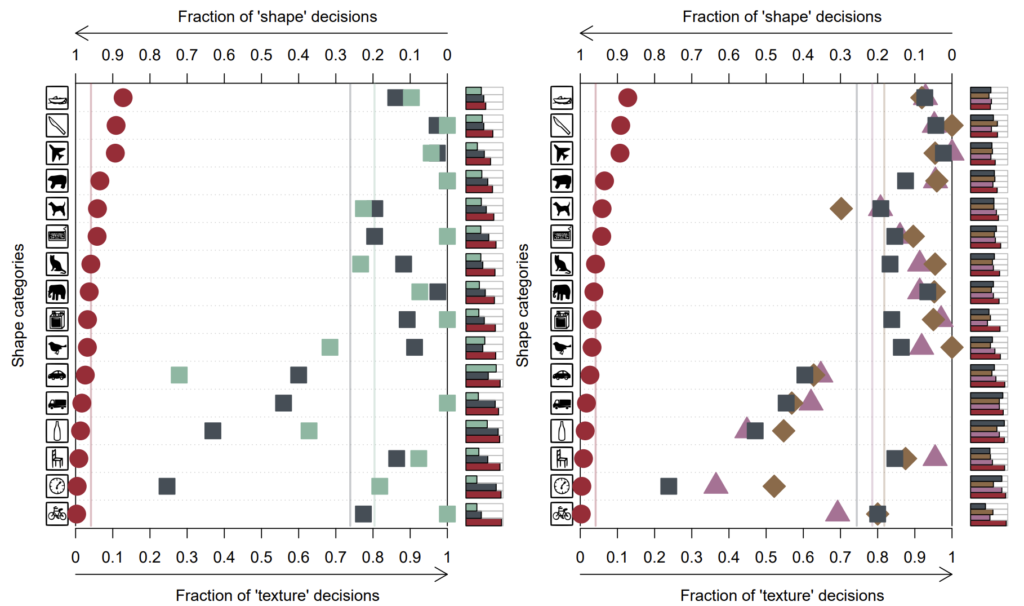
그림4는 cue conflict 데이터 셋에서의 다양한 CNN 모델들과 사람의 정량 평가 결과입니다. Cue conflict 데이터 셋은 2주전 리뷰에서 작성한 SagNet의 실험에서 사용했던 데이터 셋과 동일한 셋으로 style transfer 방법론을 통해 영상의 style과 shape을 서로 상이하게 바꿔놓은 후, 각 영상 별로 texture와 shape에 대한 카테고리 라벨이 각각 있는 데이터 셋을 의미합니다. 참고로 해당 데이터 셋 역시 해당 논문에서 제안한 것입니다.
아무튼 저 표에서 좌측으로 라인이 치우쳐질 수록 영상을 인식할 때 shape에 편향되어서 한다는 것으로 보시면 되고, 반대로 우측으로 라인이 치우칠 경우 texture에 편향되었다는 것으로 판단하시면 됩니다.
그럼 본격적으로 그림4에 대한 실험을 해석해보면, 가장 먼저 사람의 경우 모든 카테고리들이 다 좌측 즉 shape에 편향되어 있는 것을 확인하실 수 있습니다. 이것은 사람이 물체를 인식할 때 shape에 편향되어서 예측한다는 이전과 동일한 경향성의 실험 결과라고 볼 수 있겠습니다.
그리고 그 외에 동그라미, 세모, 네모, 마름모 등은 위에 그림2에서도 언급한 CNN 계열 모델들(AlexNet, VGG, Resnet 등등)으로 모두 이미지넷으로 사전학습된 모델들입니다. 이 모델들은 물론 시계와 같은 특정 카테고리에서는 shape에 편향되어 있는 모습을 보이긴 하지만 평균적으로 놓고 보면 우측 즉 texture에 편향되는 것을 확인하실 수 있습니다.
앞서 CNN이 texture에 편향된 이유는 ImageNet으로 학습하였기 때문이라고 했는데, 그렇다면 저자가 새롭게 제안하는 Stylized_ImageNet으로 학습하면 어떻게 될까요? 그 결과는 그림5와 같습니다.
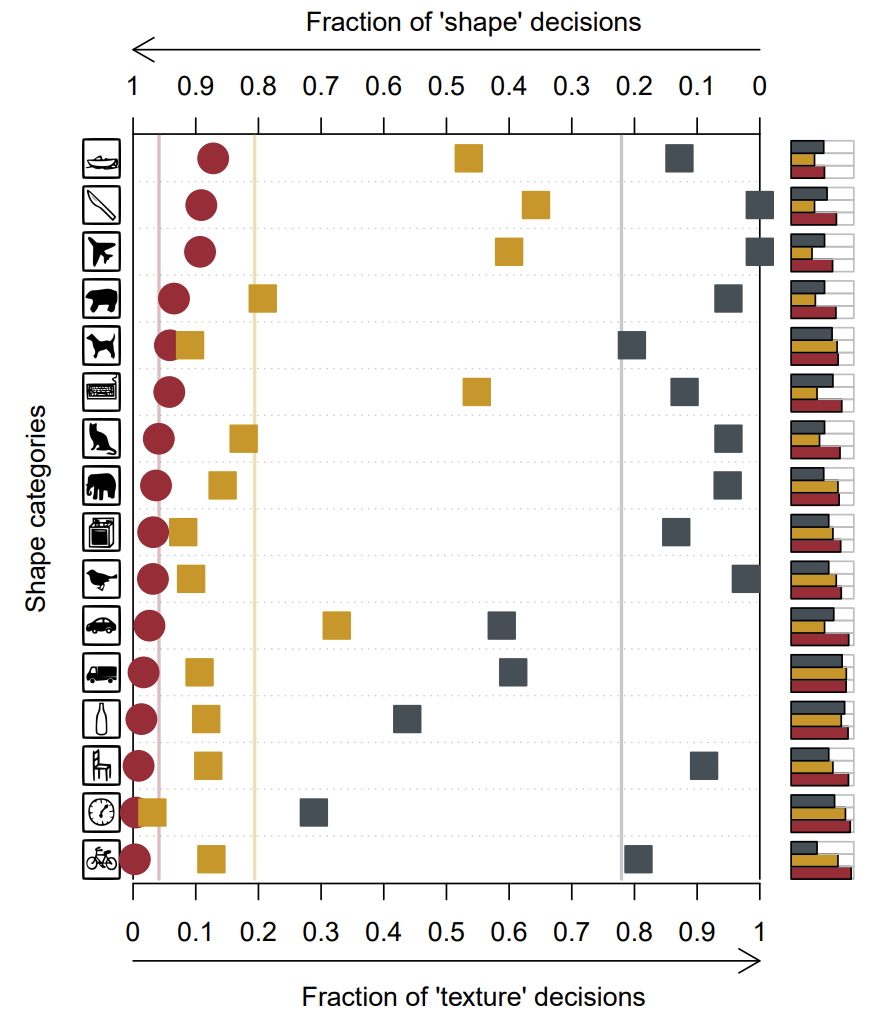
결과를 더 편하게 보기 위해 동일한 실험을 ResNet-50에 대해서만 나타냈습니다. 보시면 사람은 동일하게 shape에 편향되어 있는 것을 확인할 수 있으며, 기존 ImageNet으로 학습한 Resnet-50(회색네모) 역시 우측에 편향된 것을 확인할 수 있습니다.
흥미로운 점은, 동일한 Resnet-50 모델이라 할지라도 SIN 데이터 셋으로 학습한 모델(겨자색 네모)의 경우 대부분의 카테고리들이 shape에 편향되어 있는 것을 확인하실 수 있습니다. 즉 기존의 모델들이 texture에 편향되었던 이유는 모델의 문제가 아닌 데이터 셋에 문제라고 저자는 주장하는 것이지요.
이러한 내용과 관련해서 또 재밌는 실험을 논문에서는 보여줍니다. 아래 테이블은 각각 ImageNet(IN)으로 학습한 모델을 IN으로 평가하거나 SIN으로 평가하거나, 또는 SIN으로 학습한 걸 SIN, IN으로 각각 평가하였을 때의 분류 성능을 보여줍니다.
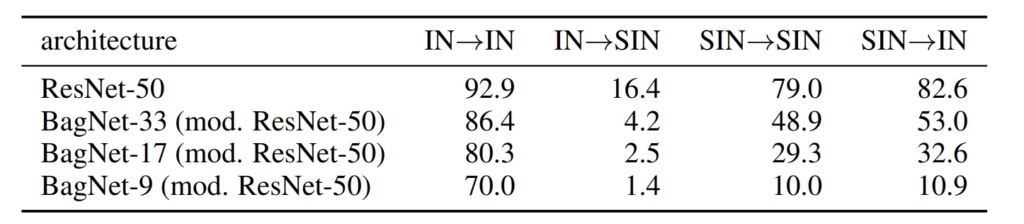
먼저 ResNet-50을 살펴보시죠. 당연한 것이겠지만 IN으로 학습하고 IN으로 평가한 것, 그리고 SIN으로 학습하고 SIN으로 평가하면 당연히 그럴듯한 성능을 달성할 수 있게 됩니다. 다만 IN 학습해서 SIN으로 평가한 것과 SIN으로 학습해서 IN으로 평가한 것에는 상당한 차이가 존재합니다.
저자의 주장에 따르면 CNN 모델들이 texture에 편향된 이유가 IN으로 학습한 것이라면, IN으로 학습한 CNN 모델은 texture에 편향되어 물체를 인식하기 때문에 실제 정답 카테고리랑 다른 texture를 가지는 영상들로 구성된 SIN에서 상당한 성능의 드랍이 발생합니다.
반면에 SIN으로 학습한 ResNet 모델의 경우에는 shape에 편향된 학습을 했기 때문에 shape과 texture가 모두 올바르게 갖춰진 IN에서도 우수한 성능을 보여줄 수 있는 것이죠. 이러한 저자의 주장을 더 강하게 뒷받침하는 실험으로 아래 BagNet에 대한 실험들을 살펴보실 수 있습니다.
BagNet의 경우에는 간략하게 소개하면 Receptive field를 극단적으로 제안한 네트워크라고 보시면 됩니다. 즉 BagNet 이름 옆에 있는 숫자들은 네트워크의 receptive field size를 의미하는데 각각 33, 17, 9로 상당히 작은 크기를 의미합니다. 즉 해당 모델들은 어떠한 영상을 처리할 때 영상의 전체적인 shape을 보는 것이 아닌 강제적으로 local texture만을 볼 수 있다는 것을 의미하죠.
이러한 BagNet은 IN으로 학습해서 IN으로 평가하였을 때 나름대로 유의미한 성능을 달성할 수 있습니다. 그 이유는 반복적으로 설명드렸다시피 IN의 경우 global shape보다는 local texture만으로도 충분히 분류가 가능한 데이터 셋으로 구성되었기 때문이죠.
반면에 IN-SIN 성능은 상당히 처참한 결과를 보여줍니다. 이는 SIN은 global shape을 보지 않는 이상 정확한 분류가 불가능한 상당히 어려운 데이터셋임을 한번 더 증명하는 셈입니다. 상대적으로 큰 receptive field를 가지는 BagNet-33의 경우에는 SIN으로 학습해서 SIN으로 평가하는 경우 상대적으로 48.9라는 성능을 달성했지만 이는 Resnet-50과 비교하면 한참 모자른 성능일 뿐더러 Receptive field가 17, 9로 떨어질수록 성능의 드랍 역시 매우 크게 증가하는 것을 확인하실 수 있습니다.
자 그럼 위에 표의 결과를 다시 정리하면 다음과 같습니다.
- IN 데이터 셋은 texture에 편향되도록 모델을 학습시키며, texture에 편향되도 충분히 좋은 성능을 달성할 수 있다.
- SIN 데이터 셋은 shape에 편향되도록 모델을 학습시키며, shape에 편향되지 않으면 좋은 성능을 달성하기 어렵다.
- Texture에 편향되도록 모델을 학습시키면 다른 도메인의 데이터셋(e.g., SIN)에서 성능이 좋지 못하지만, Shape에 편향되도록 모델을 학습시키면 다른 도메인의 데이터 셋(e.g., IN)에서 좋은 성능을 달성할 수 있다.
- SIN으로 학습한 모델이 IN에서 좋은 성능을 달성하긴 했지만, 그래도 IN으로 학습한 모델보다는 10%정도의 성능 drop이 있다.
결국 저자는 위에 정리 중 제일 마지막 부분이 신경이 쓰였는지 저 성능을 커버치기 위해서 SIN+IN을 섞어서 모델을 학습시키고 IN으로 한번 더 fine tuning하는 실험을 수행합니다.

대략적인 결과는 위의 표와 같습니다. 일반적으로 ResNet에 IN으로 학습시키면 top-1 성능이 76.13 퍼센트 나오며, SIN으로 학습해서 IN으로 평가하면 60.18% top-1 에러로 60.18% 성능을 달성하는 것을 볼 수 있습니다. 그래서 저자는 SIN+IN을 합쳐서 학습 수행하였으며 SIN으로만 학습시켰을 때와 비교하면 top-1에러 74.59%로 제법 많은 성능이 달성되었습니다. 하지만 그럼에도 IN으로만 학습한 모델과 비교해서는 성능이 2.5%정도로 감소하는 모습입니다.
그래서 저자들은 SIN+IN으로 학습 후 IN으로 한번 더 Fine-tuning하여 최종적으로 76.72%의 분류 성능을 달성했습니다. 결과적으로 저자는 SIN 데이터 셋이 훌륭한 data augmentation으로 활용될 수 있다는 식의 주장도 하는데 사실 이 부분은 기존 IN으로 학습한 모델과 비교해서 성능이 0.6%밖에 오르지 않았기 때문에 아쉬울 따름입니다.
다만 여기서 중요한 점은 분류 성능보다는 Pascal VOC와 MS COCO 데이터 셋에서 진행한 mAP 성능입니다. 분류 분야와 달리 영상 속 객체의 위치와 클래스를 모두 찾아야하는 detection task에서는 SIN 데이터 셋만 가지고 학습하더라도 IN과 매우 유사한 성능을 보여주고 있습니다.
또한 SIN과 IN을 모두 섞어서 학습시킬 경우에는 IN으로만 학습시켰을 때와 비교해서 무려 pascal에서는 3.3%의 mAP 성능 향상을 보여줍니다. fine-tuning까지 진행한 경우에는 4.4%까지 성능 향상이 있는 모습이네요. 저자는 이러한 결과를 토대로 classification 분야보다는 실제로 객체를 검출할 때 bounding box 내의 객체의 shape을 잘 봐야하는 detection task에서 shape biased model이 더 큰 효과를 볼 수 있었다고 주장합니다.
Discussion
위에 내용을 쭉 훑어보면 결국 ImageNet이 문제인 것인가? 라는 생각이 들 수 있습니다. 하지만 저자는 ImageNet 데이터 셋만이 문제가 아닌 그냥 일반적인 RGB 데이터 셋들이 대부분 CNN을 texture에 bias되도록 학습이 된다고 주장합니다. 아래 그림6 좌측 그래프를 살펴보시면, 동일한 Resnet-101 모델에 IN으로 학습시킨 경우(회색 네모)와 Open Images Dataset V2(초록 네모)가 모두 각 카테고리별 정도의 차이는 조금씩 있지만 평균적으로 texture에 편향된 것을 확인하실 수 있습니다.
즉 일반적인 데이터 셋이 아닌, 논문에서 제안하는 SIN 데이터 셋처럼 인위적인 augmentation을 취한다거나, 혹은 다른 학습 기법들을 활용해서 CNN 모델이 texture보다는 shape에 반영되도록 학습을 진행시켜야 한다는 것이죠.
그리고 또한 네트워크가 점점 크면 클수록 이러한 현상이 줄어들지 않을까? 라는 궁금증을 해소시키기 위해 그림6 우측의 그래프와 같이 무거운 네트워크들(e.g., Resnet-152, DenseNet-121 등)에 대한 실험도 진행하였습니다. 결론만 말씀드리면 네트워크의 크기와 상관없이 결국은 텍스쳐에 편향되게끔 학습되는 모습입니다.
결과적으로 논문에서 주장하고자 하는 것은 한가지, 기존의 일반적인 영상으로 학습한 CNN들은 texture에 편향되었으며, 이를 shape에 편향되도록 해야만 강건하게 동작한다는 것입니다. CNN이 texture 편향되었다는 대표적인 예시 중 또 한가지는 아래 그림과 같이 영상에 style(texture)를 입히는 style transfer 분야에서 CNN을 활용하면 영상을 잘 생성하는 반면에 Image to Image Translation과 같이 Content image의 shape을 잘 유지하면서 style을 변경하고자 하면 생성된 영상의 shape이 많이 손상되는 것을 볼 수 있습니다.
결론
해당 논문을 읽어보니 예전부터 개인적으로 느꼈었던 고민들(왜 CNN은 영상을 생성하면 테두리 엣지등이 많이 손상될까)이 CNN이 texture에 편향되어 학습하였기 때문이지 않았을까 라는 생각도 들고 여러가지 고민과 재미를 동시에 준 논문이었습니다.
좋은 리뷰 감사합니다.
결국 CNN이 texture에 편향되어 학습하는데, 특히 imagenet의 경우 데이터셋이 텍스쳐에 의존적이라는 분석이 제법 신기하네요. 그렇다면 CNN을 사용한 모델들은 대부분 질감에 의존적이라는 경향을 보인다는 결론을 내릴 수 있는건가요?
리뷰에서도 반복적으로 얘기하고 있지만 ImageNet과 같이 평범한 RGB 데이터 셋으로 CNN 모델을 학습시켰을 때 모델들이 질감에 의존적으로 학습한다고 보시면 될 것 같습니다.
해당 논문에서는 모델 관점에서의 접근이 아닌 데이터 셋 관점으로 접근한 것이라 아마 찾아보면 모델 관점에서도 질감에 편향되지 않도록 설계된 모델이 있지 않을까 싶긴 합니다.
흥미로운 내용의 좋은 리뷰 감사합니다!
실험 평가에서 데이터셋이 texture와 shape 중 어느 곳에 편향되어 학습하는지를 정량적으로 보여주는데, 무엇을 기준으로(어떤 방법으로) 모델이 이미지의 texture를 보는 지 아니면 shape을 보는 지 알 수 있나요?