Introduction
CNN은 강한 inductive bias와 translation equivariance와 같은 특성으로 이미지 관련 task에서 엄청난 성능 향상을 불러일으나, 큰 receptive fields에 대한 scaling properties가 좋지 않아 long range interactions이 어렵다는 단점이 있다.
이러한 long range interactions 문제를 해결하기 위해서 attention 이 등장하게 되었다. attention은 NLP에서 좋은 성능을 거두었는데, CNN에서도 이를 따라 attention을 함께 적용하여 성능을 끌어올리려는 연구를 하였다. 예로, Squeeze-Excite Network(SENet)와 spatially-aware attention등이 있다.
이 논문에서 저자는 CNN에 attention을 부분적으로 적용한 것과는 달리, convolution을 대체할 수 있는 attention block을 제안하여 Attention만으로 이루어진 vision model을 제안한다.
Background
Convolution
CNN은 일반적으로 작은 범위 내의 상관관계를 학습하는 데 사용된다. h\times w\times c 크기의 입력 영상 x가 주어졌을 때, x_{ij}주변의 k\times k 범위에 convolution 필터의 가중치를 곱하여 하나의 결과값이 출력된다. 이를 영상 전체에 걸쳐 반복하는 것을 convolution연산이라 하며 수식으로는 다음과 같이 나타낼 수 있다.
y_{ij} =\sum_{a,b\in N_k(i,j)}W_{i-a, j-b}x_{ab}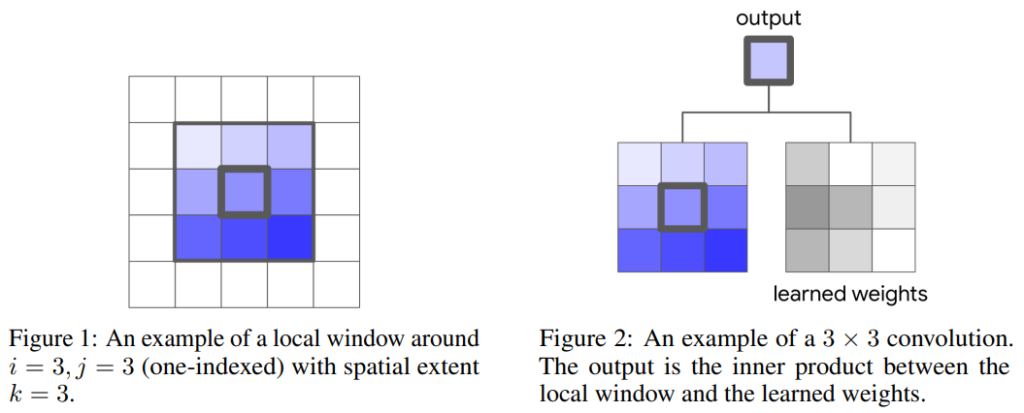
self-attention
local attention block
논문에서는 stand-alone한 attention model을 위해 local attention layer를 제안하였다. convolution과 비슷하게 크기가 k인 window를 활용하였다.
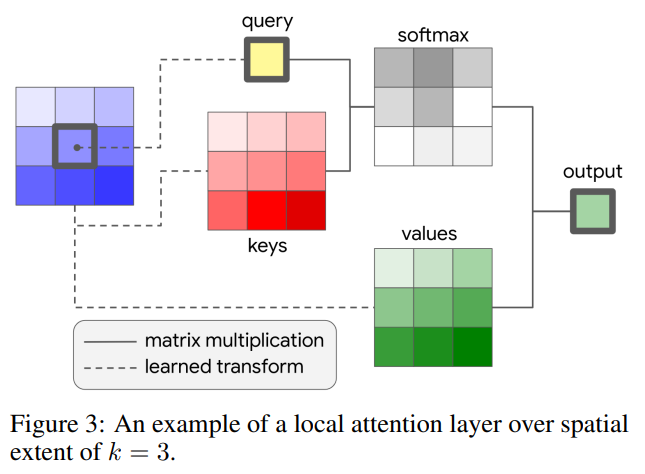
[그림 3]은k=3인 경우의 local attention layer의 구조이다.
입력 영상의 한 픽셀 x_{ij}\in R^{d_{in}}가 query, query를 기준으로 주변 k\times k 범위를 key, value로 사용한다. 이때 해당 값을 그대로 사용하지 않고 각각 가중치 W_Q, W_k, W_v를 곱하여 transform해준다.
self-attention에서, query 픽셀과 key 픽셀들 간의 내적과 softmax를 취해 similarity matrix를 만들고 이를 values픽셀들과 내적하여 output을 냄으로써, 해당 픽셀과 주변 픽셀들 간의 relational information을 학습한다.
CNN과 local attention layer의 가장 큰 차이점으로는 window size와 파라메터의 수가 서로 independent하다는 것이다. convolution 연산의 경우, kernel의 크기가 증가하면 그만큼 파라미터 수도 증가하지만 local attention은 window size에 상관없이 1*1 conv로 transform을 진행한다.
single headed attention의 출력값은 아래와 같다.
y_{ij}=\sum_{a,b\in N_k(i,j)}softmax_{ab}(q^T_{ij}k_{ab})v_{ab}Relative distance computation

attention 방법론 에는 위치 정보가 인코딩되어있지 않다. 이는 permutational equivariant를 일으키며, vision task의 표현력을 저해시킨다. 마찬가지로, self-attention mechanism은 positional 정보를 알려주지 못하기 때문에 별도로 이러한 정보를 넣어주어야 한다. 논문에서는 “relative positional embedding”을 사용한다. 이는 [그림 4]와 같이 query기준으로 주변 픽셀들의 상대적인 위치 index들을 사용한다. 실제로는 위와 같이 (0, 0), (-1, 0) 등의 index value를 가지는 matrix가 아니고, learnable look-up table을 만들고서 해당 index의 값들을 가져오게 된다. 좀 더 자세히 설명하면, row offset과 column offset에 대해서 각 따로 learnable matrix가 look-up table로 존재하고 해당하는 offset의 벡터를 가져와서 이를 concat해준다.
이를 식으로 나타내면 다음과 같다.
y_{ij}=\sum_{a,b\in N_k(i,j)}softmax_{ab}(q^T_{ij}k_{ab}+q^T_{ij}r_{a−i,b−j})v_{ab}positional information이 더해짐으로써 self-attention은 translation equivariance 특성을 가지게 된다.
3. Fully Attentional Vision Modls
논문에서는 두 단계를 거쳐 local attention 레이어로 fully attentional한, 즉, attention만으로 이루어진 stand-alone 모델을 완성하였다.
3.1 Replacing Spatial Convolutions
spatial convolution layer를 attention layer로 모두 대체하였다. 이 때, 1×1 conv는 spatial conv가 아니므로 제외되었다. 그리고 downsample이 필요할 때는 2×2 average pooling with stride 2를 사용하였다.
3.2 Replacing the Convolutional Stem
stem이란 보통 network의 매우 초반 layer를 말한다. 여러 실험을 통해 edge와 corner같은 local features는 이러한 stem layer에서 학습이 되고, object의 detail(ex. texture)과 같은 global features는 후반 layer에서 학습이 된다고 알려져 있다.
저자들은 이러한 stem block에 local attention layer를 사용하면 성능이 떨어진다고 한다. 초반 input은 rgb 채널을 가진 이미지일 것이고 R, G, B 값들은 개별적으로는 아무런 정보를 담고 있지 않지만 spatially correlate한데 self-attention으로는 이러한 Input에서 좋은 정보를 뽑아내기 어렵다는 것이다.
이러한 점에서 저자들은 stem 부분을 제외한 부분은 attention이 아닌 convolution으로 유지하는 c-stem attention모델을 제안하였다.
4. Experiments
4.1 ImageNet Classification
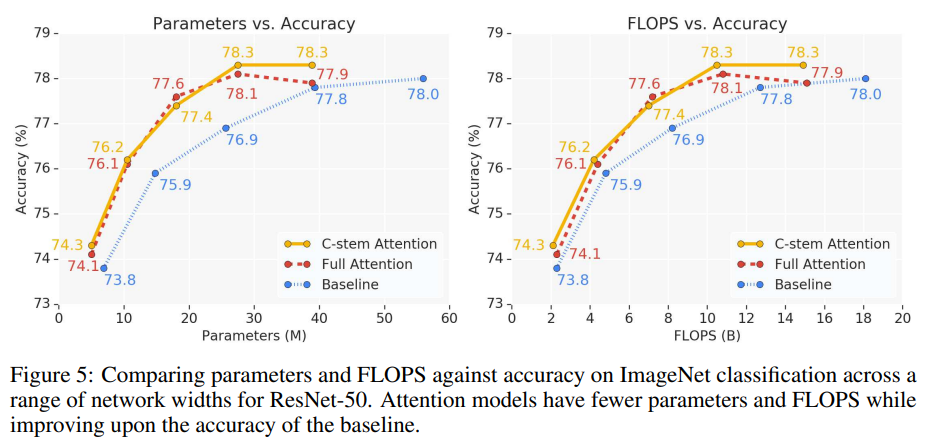
ImageNet 데이터셋에 대해서 Classification 성능을 평가하였다. Baseline은 ResNet 50으로 Convolution만으로 이루어진 모델, Conv-stem + attention은 stem만 convolution을 사용한 모델, full attention은 모든 layer를 attention으로 만든 모델이다.
[표 1]은 ResNet의 depth가 26, 38, 50일때 FLOPS, 파라미터 수, 정확도를 평가한 결과로 resnet의 깊이가 깊어질수록 conv-stem보다 full attention의 성능이 높아지는 것을 확인할 수 있다.
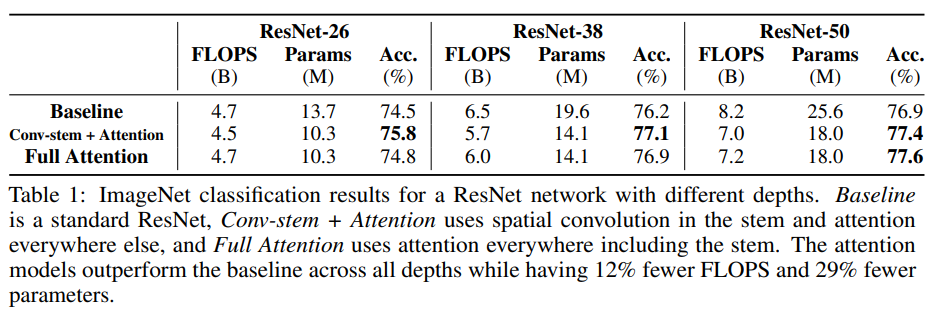
각 모델들의 파라미터 수와 FLOPS에 따른 Accuracy를 비교하였을 때, C-stem Attention과 Full Attention 모두 Baseline보다 높은 성능을 기록하였다.
4.2 COCO Object Detection
COCO Object Detection의 성능을 평가한 결과이다. Detection Head와 Backbone에 각각 convolution과 Attention을 적용하여 평가했을때, conv-stem+attention과 full attention 두 모델은 크게 성능 차이가 나지 않으나, detection head가 attention인 경우 효율적인 연산이 진행된다.