간단한 소개
본 논문은 test time에 적합한 instance-level의 data augmentation을 위한 방법론을 소개한다. 제안하는 방법론은 입력값을 transformation한 후보들의 loss를 예측하는 보조모듈을 이용하는데, loss가 낮게 예측된 후보군을 입력으로 선정하는 형식이다. 실험을 통해 다양한 image classification benchmarks에서 제안하는 방법론이 다양한 변동에 대응하고 강인한 성능을 냄을 확인하였다.
방법론
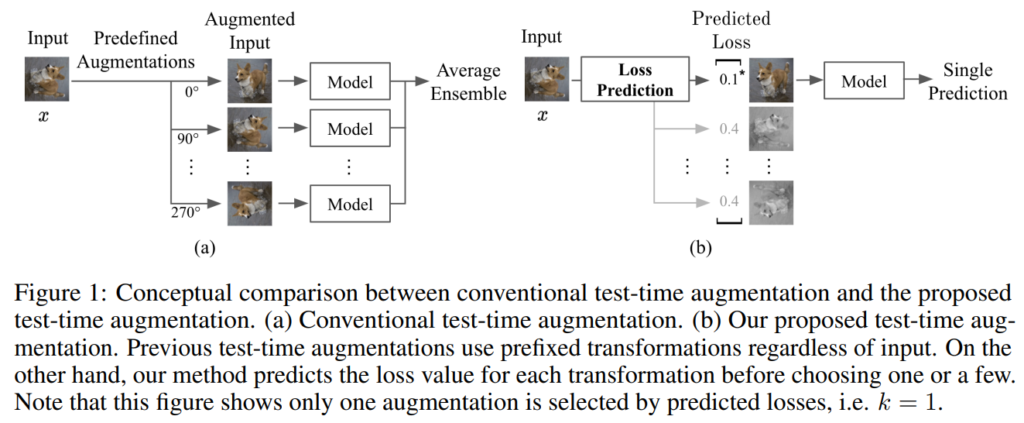
Figure1의 (b)가 제안하는 방법론이다. 간단한 소개에서 언급하였듯이 loss를 예측하는 보조모듈을 통해 test time에 사용한 transformation 방법론을 선정한다. Figure1의 (a)는 Test-time augmentation 으로 기존연구가 train 구간에 augmentation에 집중했던 것에서 확장하여 crop, mixup과 같은 augmentation 기법을 test 구간에 적용하고 그에 대한 모델의 예측값의 평균을 최종 예측으로 하여 모델의 정확도를 개선하는 방법론이다. 이는 불안정한 모델의 안정도를 높일 수 있지만, augmentation 정도가 심하거나 모델이 데이터에 대한 확신도가 낮은경우 오히려 노이즈가 될 수 있다. 따라서 제안하는 방법인 Figure1의 (b)는 생성한 augmentation 중에서 모델이 가장 예측하기 쉽다고 판단되는 데이터를 입력으로 선정하도록 하였다.
Loss prediction 모델
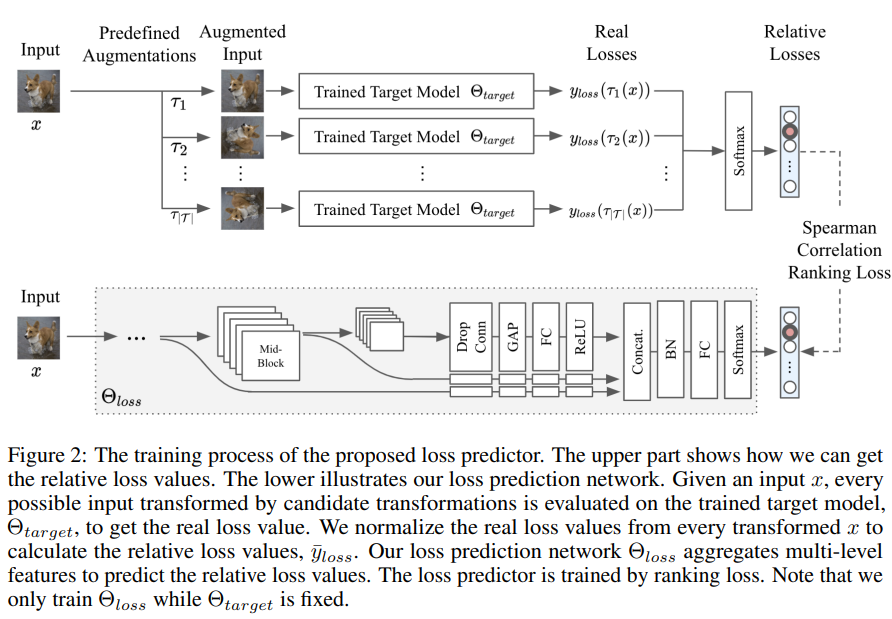
자세한 loss predictor의 구조는 Figure2와 같다. 입력 데이터 x를 T개의 augmentation(T = {τ1, τ2, …, τ|T |})을 적용하여 augmented input을 생성한다. 이 입력을 target 데이터에 학습한 모델 Θ target의 입력으로 하여 예측값을 생성하고 이를 실제 정답값과 비교하여 loss를 생성한다. 해당 loss를 groud truth로 하여 loss predict 모델을 학습한다. 이때 Θ target는 고정하고 Θ loss predictor만 학습한다. 이때 Θ loss predictor는 각 augmented image의 loss의 순위를 학습하는 ranking loss를 통해 학습한다. 이때 transformation의 종류는 Figure4의 12가지(identity, rotate-20, rotate+20, zoom0.8, zoom1.2, autocontrast, sharpness0.2, sharpness0.5, sharpness2.0, sharpness4.0, color0.5, color2.0)와 같다.

실험
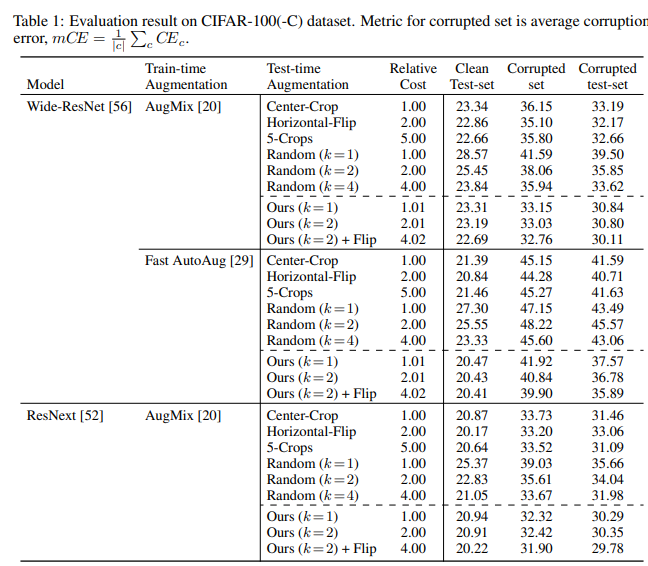
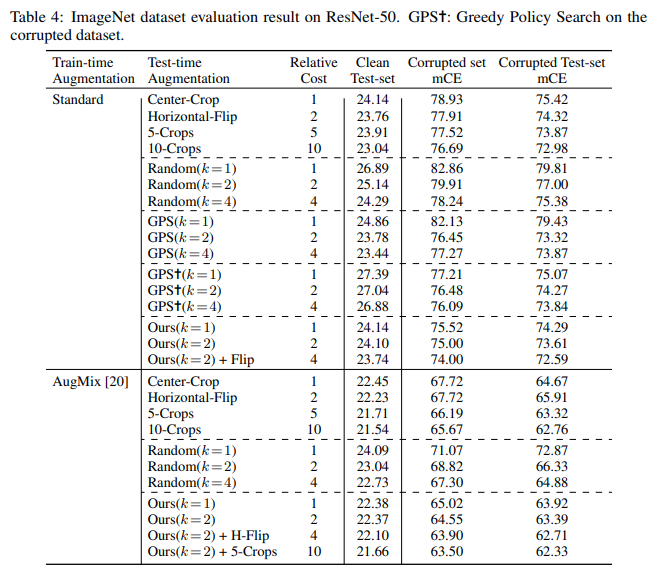
실험은 CIFAR-100과 ImageNet 벤치마크에 대해 진행되었다.
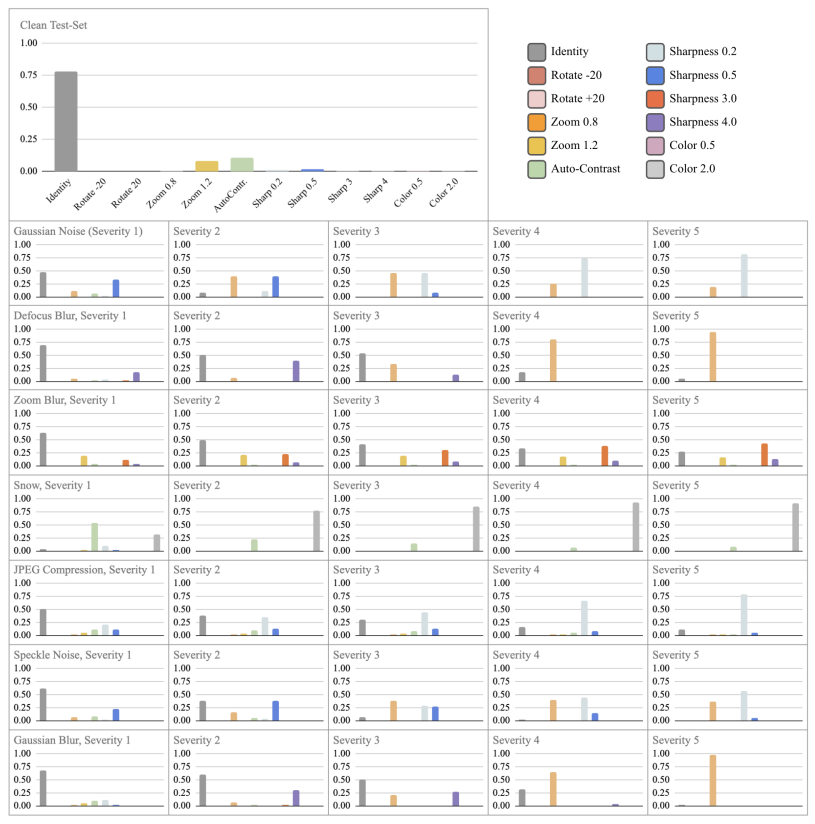
아래 Figure 5를 통해 다양한 노이즈를 통해 제안하는 방법론이 더 효과적인 test 이미지를 선별함을 드러내는 실험이다. 가장 큰 plot은 test 데이터가 clean 한 상황이며 이때는 원본 이미지가 가장 많이 선별되었다 그러나 test 이미지에 gaussian noise가 적용된다면 sharpness0.5 transformation이 적용된 이미지가 높은 확률로 선별됨을 알 수 있다.
와, TTA라는게 뭐였는지 궁금해하고 뭔지 몰랐는데 이런 방법이였군요.
핵심적인 컨셉은 이해했는데 어떻게 동작하는지에 대해서는 알기 어려워서 조금 아쉽네요.
리뷰해주신 논문의 분야가 어디인지는 모르겠으나, 연구하시는 분야랑은 다른 분야 같다고 생각합니다.
어떻게 하다가 해당 논문을 찾아보시게 되었는지 궁금하네요.
그리고 검출 분야에서도 해당 방법론을 사용하는 것을 보았는데 코드 레벨에서 적용 난이도가 어느정도 인지 궁금합니다.
해당 논문은 domain shift 관련 논문이나 정보를 찾다가 보게되었습니다. 디테일은 시간날때 추가해보겠습니다.
추가로 검출분야의 TTA는 Test-Time Adaptation 이라는 키워드로 찾아보시는게 더 좋을 듯 힙니다. 해당 방법론이 더 일반적인 TTA라고 생각되네요. Test-Time Adaptation은 코드 레벨로도 충분히 적용 가능하실 것 같습니다.
안녕하세요 유진님 좋은 리뷰 감사합니다.
이 논문에서 제안된 방법론은 Test-Time Augmentation 보조 모듈로 모델이 더 좋은 예측을 할 수 있는 기회를 제공하는 것 같습니다. 예를 들어 classification 테스크에서 이미지를 얻고 모델을 통해 예측을 실행해야 할 때 기존에는 해당 예측을 올바르게 얻을 수 있는 기회가 한 번 있는데 이 기술은 데이터 증강 기술을 사용하여 원본 이미지의 변환된 이미지를 생성하여 더 많은 예측을 할 수 있도록 만들었고 증강을 통해 모델이 동일한 이미지를 보는 방법의 수를 늘려서 모델의 예측값의 평균을 최종 예측으로 하여 모델의 정확도를 향상시키는 방법으로 이해했습니다. 그런데 다른 도메인 영역에 이 방법론을 적용시키는게 이해되질 않는데 이는 어떻게 이루어지는 건가요?