이번에 작성할 논문은 Indoor 환경에서의 Monocular Depth Estimation 분야입니다. 제목에서도 알 수 있다시피, Indoor Depth Estimation을 보다 더 실용적으로 수행할 수 있도록 하기 위해, self-supervised learning 및 합성 데이터 등을 활용합니다.
Intro
일단 Monocular Depth Estimation 분야는 상당히 연구가 활발하게 진행되고 있는 분야 중 하나입니다. 영상을 통한 깊이 추정은 Lidar 또는 Depth Camera와 같은 추가적인 센서의 필요성을 해소시킬 수 있으며 이러한 Depth 정보 역시 자율주행, AR/VR, Localization 등등 정말 다양한 분야에서 활용이 될 수 있기 때문이죠.
이러한 Monocular Depth Estimation 분야에서는 또한 Supervised Learning보다는 stereo image 또는 video sequence를 활용한 Self-supervised Learning이 더 많은 각광을 받고 있습니다. 이는 당연히 영상에 해당하는 깊이 정보를 같이 취득하는 것이 쉽지 않기 때문이죠.
근데 또 재밌는 점은 이러한 Self-supervised monocular depth estimation 분야가 Indoor 보다는 outdoor 환경에서 많이들 연구가 되고 있다는 점입니다. 이쪽 분야에 논문을 써봤던 제가 느끼기에도 학회에 제출된 Depth Estimation 분야를 살펴보면 대부분 outdoor 환경에 대해서 다루고 있지 indoor 환경에 대해서 다루는 논문은 그리 많지 않았습니다.
저자는 기존의 연구들이 indoor 보다는 outdoor에 치우칠 수 밖에 없는 이유에 대해서 먼저 indoor 환경과 달리 outdoor 환경에서는 대부분 차량을 통한 driving scene이며 이러한 장면들은 강한 구조적 prior를 지니고 있다고 합니다. 이게 어떤 의미냐면, 주행 환경에 대한 영상은 대부분 상단이 하늘 또는 빌딩 등으로 구성이 되어있으며, 하단에는 도로가 일관성 있게 나타난다는 점이죠.
이와 대조적으로, indoor 환경에서는 구조적 prior가 상대적으로 약하다고 합니다. 이는 실내 환경의 경우 장면 자체가 상당히 다양할 뿐더러 등장하는 물체가 상당히 뭉쳐있거나 매우 가까이 있는 등 변화가 더 다양하다는 것이죠.
두 번째로 indoor 환경에서의 깊이 추정이 어려운 이유는 바로 “분포”입니다. 주행 환경에서는 대부분 도로 위에 깊이 분포가 근거리에서 원거리까지 고르게 분포되어 있습니다. 즉 장면 자체가 나타내는 깊이 분포가 크게 변화하지 않지만 이와 다르게 indoor 환경에서는 때로는 천장을 혹은 책상을 측정해야하는 등 가까이 있는 것과 멀리 있는 대상에 대한 상당한 깊이 분포의 변화가 자주 발생합니다. 이러한 것들이 모델이 올바른 깊이를 추정하도록 하는데 어려움을 줄 수 있게 되는 것이죠.
셋 쨰로는 indoor 환경에서 촬영되는 물체들은 outdoor와 비교해서 textureless 한 지점들이 많다는 것입니다. 이 textureless한 영역이 많으면 많을수록 self-supervised learning이 어려워지게 되는데 이는 뒤에서 다시 설명드리겠습니다.
아무튼 결과적으로 이러한 문제들을 해결하고 indoor 환경에서 강인하게 동작하는 monocular depth estimation 방법론을 만들기 위해 논문에서는 다음과 같은 contribution을 보여줍니다.
- 선행 학습된 깊이 추정 네트워크를 활용해 Structure distillation을 수행하여 보다 정확한 깊이를 추정함.
- 기존의 제공되는 indoor dataset의 한계를 극복하고자 매우 방대한 스케일의 indoor simulation dataset을 공개함.
- Distilation, Self-supervised learning 및 simulation dataset 등 활용하여 효율적인 학습 방식으로 좋은 성능을 달성.
먼저 1번에 대해서 간략하게 소개드리면, Transformer for Dense Prediction이라는 논문에서 제안한 DPT 모델을 expert model로 활용, 해당 모델의 depth map에 대한 structure distillation을 수행하는 새로운 loss를 제안합니다.
그리고 2번째의 합성 데이터의 경우에는 기존의 indoor dataset(Middlebury, NYUv2)들은 데이터의 개수가 너무 부족하거나 또는 stereo setup이 아닌 monocular camera로 촬영한 데이터 셋업이기 때문에 self-supervised learning을 수행하기에 한계가 있었습니다. 따라서 이러한 문제를 해결해줌과 동시에 데이터 취득에 많은 시간 및 노동이 들어가지 않도록 simulation dataset을 취득하였습니다.
Method
일단 간단하게 해당 방법론의 학습 방식 및 문제 정의에 대해서 정리하겠습니다. 해당 방법론에서 하고자 하는 것은 단안 영상을 입력으로 넣어 깊이를 추정하는 것을 의미합니다. 그리고 이 때 학습에 사용하는 영상으로는 left image I_{t} 와 그에 대응되는 right image I'_{t} , 그리고 현재 프레임 기준 앞, 뒤 프레임 영상을 의미하는 영상들( I_{t+k}, k \in [-1, 1] )이 존재합니다.
깊이 추정 네트워크를 f_{d} 라고 했을 때 f_{d}(I_{t})= D_{t} 가 될 것이며 당연히 D_{t} 는 Depth map으로 볼 수 있습니다. 그러면 이제 저희한테는 I_{t}에 대한 깊이 정보를 알고, 카메라에 대한 내부 파라미터 K와 stereo camera 사이에 baseline T를 알고 있다면 우리는 left image를 right image로 warping이 가능합니다. 즉 수식으로 표현하면 \hat{I'_{t}} = I_{t} <proj(D_{t}, T_{t}, K)> 로 표현할 수 있습니다.
이렇게 warping된 영상 \hat{I'_{t}} 는 이론상으로는 I'_{t} 와 동일해야하므로 이 영상 사이의 유사도를 비교하는 photometric loss를 아래와 같이 계산할 수 있습니다.
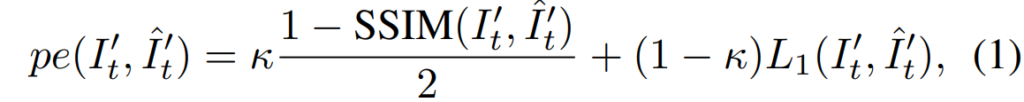
대충 두 영상의 유사도를 계산하기 위해 SSIM과 L1 loss를 적절한 비율로 섞어서 계산하셨다고 보면 됩니다. 일단 지금 위에서 소개드린 방식은 stereo image가 있을 때 self-supervised learning을 하는 방식에 대해서 말씀을 드렸고, 해당 논문에서는 stereo image 뿐만 아니라 비디오 sequence 영상에 대해서도 self-supervised learning도 함께 진행합니다.
동일하게 I_{t} 영상에 대한 Depth map D_{t}를 추출하였다면 내부 카메라 파라미터 K + camera pose network를 통해 계산된 앞 또는 뒤 프레임 사이에 외부 파라미터 T를 계산하여 동일하게 photometric loss를 적용하면 되는 것입니다.
일단 이러한 stereo와 video에 대한 self-supervised learning이 해당 방법론의 main objective function이 됩니다. 그럼 본격적으로 해당 방법론이 어떠한 방식으로 학습하고 있는지를 살펴보시죠.
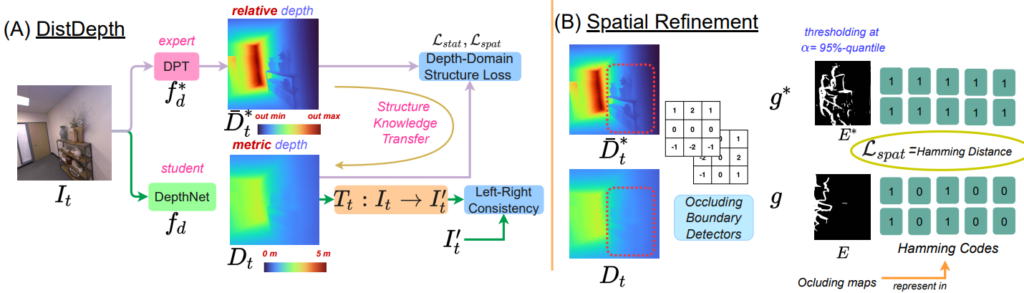
그림1은 논문에서 제안하는 전체 training flow 및 loss function을 나타내고 있습니다. 먼저 그림1-(a)의 학습 과정부터 살펴보시면 어떠한 입력 영상 I_{t} 가 있을 때, 해당 영상은 각각 DPT 모델과 DepthNet 모델의 입력으로 사용됩니다. 이를 통해서 각각의 Depth map \bar{D}*_{t}, D_{t} 가 생성이 되며 이 때 DPT의 output인 \bar{D}*_{t}는 D_{t} 에게 Strucuture Knowledge Transfer를 수행하게 됩니다.
이와 별개로 DepthNet f_{d} 는 stereo image와 video frame을 통한 self-supervised learning을 동시에 진행하게 됩니다. 그림1에서는 left-right consistency를 통한 self-supervised learning 밖에 표기되어 있지 않지만, 실제로는 video frame을 활용한 self-supervised learning도 동시에 수행한다고 합니다.
결국 해당 논문에서 새롭게 제안하는 것은 이 DPT의 output을 가지고 student network에게 어떻게 structure knowledge distillation을 하였는지 부분이며 그 내용을 설명하기 앞서 왜 DPT의 output으로는 structure knowledge만을 distillation하고 실제 깊이 추정 값 자체를 distillation하지는 않는지에 대해서 짚고 넘어가겠습니다.
사실 직관적으로 생각해보면 DPT라는 이미 잘 학습된 모델이 있다고 하였을 때 해당 Depth map을 pseudo depth로 활용하면 되지 굳이 복잡하게 stereo image를 통한 self-supervised learning을 할 필요가 있는가?에 대한 의구심이 들 수도 있을 것입니다.
하지만 해당 방법론에서 DPT의 output을 곧바로 pseudo GT로 활용하지 못한 이유를 알기 위해서는 DPT라는 모델의 학습 방식에 대해서 아셔야 합니다. 간략하게 소개하면, DPT는 학습 시에 정말 다양한 데이터를 통해서 학습이 됩니다. 이는 말 그대로 in-the wild 이미지들을 통해 학습을 하기 때문에 취득된 학습 영상들은 각각 카메라의 내부 파라미터도 다르고 stereo 영상인 경우 baseline 길이 조차도 모릅니다.
그러다보니 DPT의 경우 절대적인 깊이 값을 의미하는 map을 뽑는 것이 아닌, 상대적인 거리를 추정하는 relative depth map을 추출하게 됩니다. 이러한 relative map은 영상을 보고 상대적으로 A라는 물체가 B라는 물체보다 더 가깝구나 라는 것은 알 수 있지만, 실제 이 A 물체가 몇 미터 밖에 있고, B 라는 물체가 몇 미터 안에 있는 지 등을 알 수는 없습니다.
따라서 저자는 student network가 절대적인 거리를 측정한 metric depth map을 취득하기 위해서 stereo image 등을 활용한 self-supervised learning이 필수적이며, 다만 indoor 환경과 같이 다양한 물체가 나오는 상황에서 DPT의 매우 정교한 depth map의 구조적 정보들을 distillation 하고자 하였다고 합니다.
Structure Distillation from Expert
그럼 본격적으로 DPT의 depth map을 어떻게 활용하여 distillation 하는지 살펴봅시다.
먼저 저자는 DPT의 output depth map을 D*_{t} 라고 했을 때 단순하게 D_{t} 와의 정합이 맞도록 하는 scale factor a_{s} 및 shift factor a_{t} 를 least-square optimization을 통해 계산했다고 합니다.
해당 부분은 제가 봤을 때, 물론 위에서 DPT의 depth map이 relative depth map이기 때문에 structure 정보만을 distillation한다고 하긴 했으나, 그래도 최대한 alignment를 맞추어 statistical loss를 부과하기 위함으로 해석됩니다. 실제로 논문에서는 scale과 shift factor를 이용해 정합을 맞춘 \bar{D}*_{t}를 가지고 SSIM loss를 아래와 같이 계산합니다.
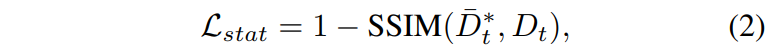
기존의 수식 1처럼 L1 loss도 적절히 섞을 수 있어 보이지만, SSIM만을 적용한 이유는 SSIM의 계산 특성 상 luminance 와 contrast를 계산할 때 mean과 standard variation을 비교하는 통계적인 관점에서의 접근과 달리, L1 loss와 같이 단순히 픽셀레벨의 오차를 계산하는 방식은 모델의 학습을 상당히 불안정하게 만들었다고 합니다. 그래서 수식1과 달리 수식2의 경우 SSIM loss만을 활용합니다.
Spatial refinement loss
아무튼 이러한 SSIM loss는 단순히 depth distribution에 대한 통계학적인 부분에서의 비교 loss 이며 다시 본론인 spatial information에 대한 loss를 계산하기 위하여 spatial refinement loss를 제안합니다.
과정은 단순한데, 먼저 각각의 depth map에 대하여 Soble filter를 적용해 depth map에 대한 gradient map을 생성합니다. 그 다음에는 해당 graident map에 대하여 alpha = 95% 분위수 이상에 해당하는 gradient 값들을 살리고 나머지는 제거합니다. 즉 \hat{D}*_{t}, D_{t} 로 부터 alpha의 임계치를 넘기는 값에 대하여 0과 1로 구성된 binary map E*, E 를 계산하는 것 입니다.
이렇게 이진 마스크를 각각 계산하였다면, 이제 이 이진 마스크 둘에 대하여 Hamming distance를 다음과 같이 계산합니다.
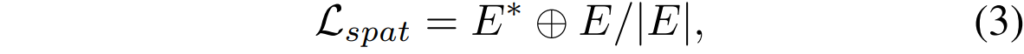
여기서 저 + 표식은 Xor 연산의 기호로 해당 마스크 들이 각각 0과 1로 구성된 이진 마스크이다보니 두 이진 값에 대해 XOR 연산을 수행한다고 보시면 될 것 같습니다.
결과적으로 논문에서 제안하는 DistNet이라는 깊이 모델을 학습하는 total objective function은 다음과 같습니다.
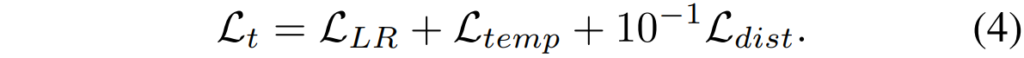
이러한 structure distillation loss는 self-supervised learning을 통해 학습한 depth network가 한번도 보지 못한 texture에 대해서도 정확한 추정이 가능하도록 도와주었다고 합니다.
Dataset
다음으로는 데이터 셋에 대한 설명을 하고자 합니다. 먼저 해당 방법론은 Habitat simulator라는 저는 처음 들어봤지만 이 분야에서 상당히 유명한 simulator를 통해서 합성 indoor dataset, SimSIN을 구축했다고 합니다. stereo baseline은 13cm, 영상의 해상도는 512 x 512이며, Habitat simulator는 가상의 imbeded robot이 실내 환경에 대하여 쭉 돌아다니는 과정에서 취득 가능한 실내 영상들 입니다.
또한 이와 별개로 저자는 ZED-2i라는 스테레오 카메라 셋업을 통해서 real dataset도 함께 취득하였습니다. 이는 simulation dataset으로 학습하였을 때와 real dataset으로 학습하였을 때의 모델의 성능 차이를 분석하고자 했다고 합니다. 해당 데이터 셋의 명칭은 UniSIN입니다.
평가에 활용한 데이터 셋으로는 Virtual Aprtment(VA) 데이터 셋과 NYUv2 dataset을 활용했다고 합니다. VA dataset의 경우에는 서로 다른 조명을 지닌 캐비넷이나 얇은 구조, 복잡한 데코레이션 등이 자주 등장하는 매우 어려운 데이터 셋이라고는 하는데, 결과적으로는 real dataset이 아닌 합성 데이터 셋으로 보입니다. 반대로 NYUv2는 Kinect v1으로 취득한 real dataset이구요.
Experiments
그럼 실험 내용에 대해서 간략히 소개 후 리뷰를 마치도록 하겠습니다.

일단 위에 표는 VA 데이터 셋에서의 정량적 결과입니다. 모든 방법론들은 SimSIN으로 학습하여 VA 데이터 셋으로 평가된 것이며 노란색의 Single-Frame과 초록색의 Multi-Frame은 각각 테스트 할 때 사용한 영상의 장수를 의미합니다. 즉 노란색 쪽 방법론은 single imaeg에 대한 inference를 하는 것이며 초록색 쪽 방법론은 multi-frame을 입력으로 받아서 깊이를 추정합니다.
결과적으로 논문에서 제안하는 DistDepth가 가장 좋은 성능을 보여주고 있는 것을 확인 가능합니다.
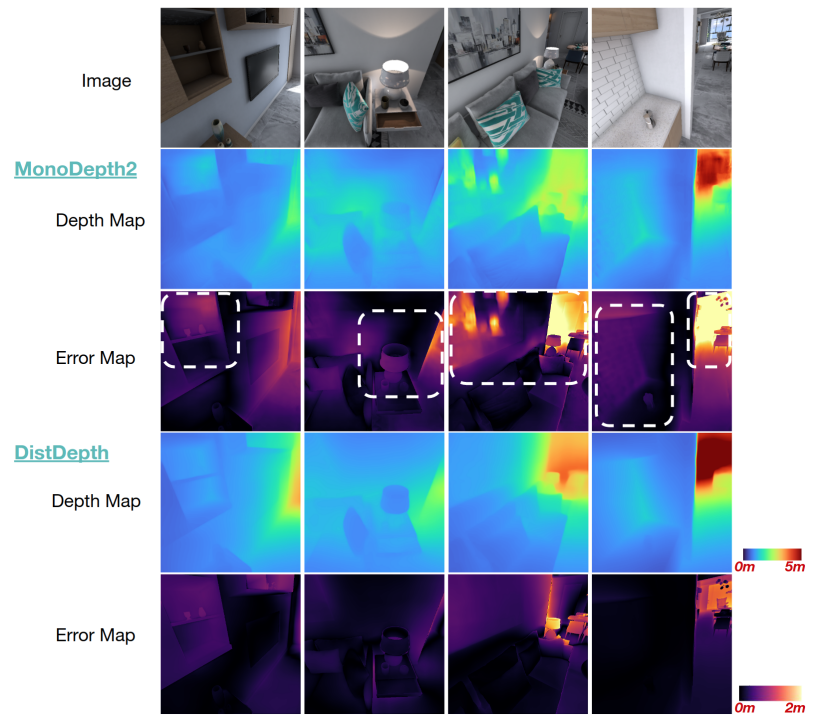
그림2는 VA 데이터 셋에 대한 monodepth2와 DistDepth의 정성적 결과를 비교한 것입니다. monodepth2의 경우 벽의 그림이나 벽돌 타일과 같은 texture가 있는 영역에서 depth map이 노이즈 한 것을 볼 수 있는 반면에 제안하는 방법론은 상당히 부드럽고 선명하게 잘 표현한 것을 확인할 수 있습니다. 저자는 DPT의 relative depth map으로 부터 structure distillation을 잘 수행하였기에 가능하다고 주장합니다.
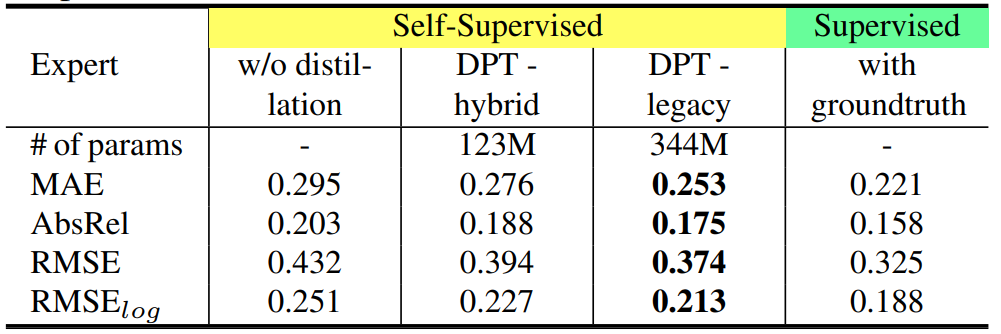
다음 표는 expert network의 종류에 따른 모델의 정량적 성능 결과를 나타낸 것입니다. 뭐 당연한 것이겠지만 DPT-hybrid보다 DPT-legacy가 더 큰 파라미터 크기를 가지는 것으로 보아 더 모델이 무거운 것으로 판단되며 따라서 더 좋은 성능 향상을 보여주고 있습니다. 그리고 distillation을 했을 때와 안했을 때의 성능 차이가 제법 나는 것을 통해 distillation이 제법 효과적이었다고 볼 수도 있겠습니다.

이러한 structure distillation의 효과는 위에 그림3을 통해서 더 정확히 확인이 가능합니다. 입력 영상을 통해 뽑은 depth map으로 각각 RGB 영상을 3D point cloud로 올렸을 때, monodepth2의 경우 object의 point cloud가 부정확하여 tail이 생기는 반면, Distdepth의 경우에는 어떠한 흐트러짐 없이 정확하게 재구축하였다는 것을 보여줍니다.
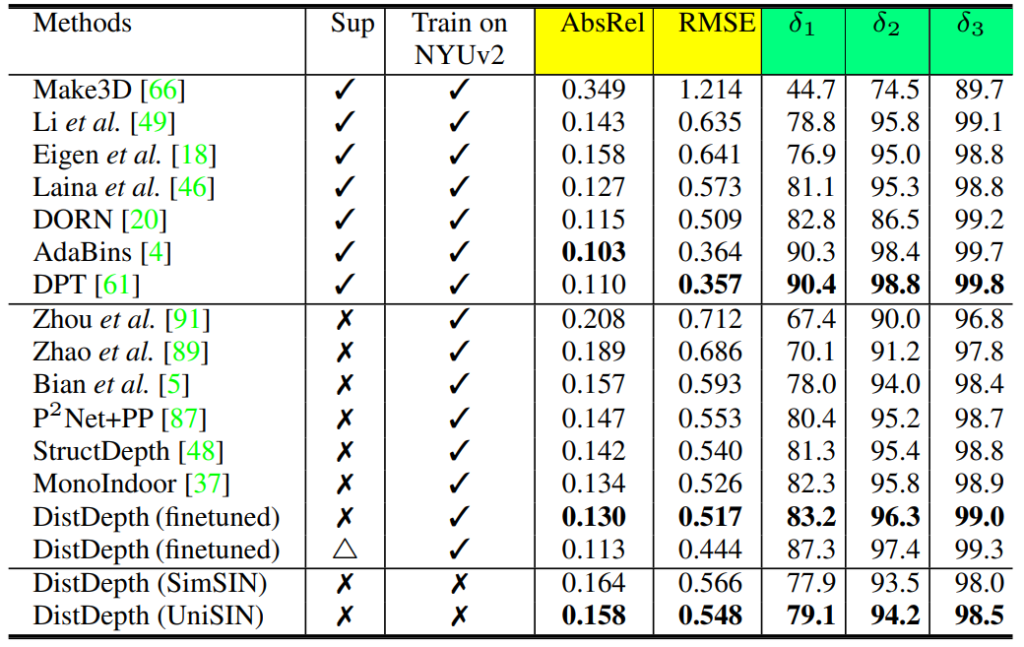
다음은 NYUv2 데이터 셋에 대한 정량적 결과 표입니다. NYUv2 방법론의 경우 stereo image를 제공하지 않기 때문에 본인들의 방법론을 먼저 SimSIN으로 학습시킨 후 NYUv2를 fine tuning할 때 video sequence만을 활용하여 학습하였다고 합니다.
일단 결국 해당 방법론은 self-supervised learning이기 때문에 supervised 방법론 보다 성능이 떨어지는 것은 어쩔 수 없는 사실이나 self-supervised learning 방법론들과 비교하였을 때는 가장 좋은 성능을 달성했다고 주장합니다. 또한 NYUv2로 fine-tuning을 하지 않고 simulation dataset으로 학습하더라도 몇몇 self-supervised learning 방법론보다 더 좋은 성능을 달성한 모습입니다.
다만 아쉬운 점은 본인들이 self-supervised learning에서 가장 좋은 성능을 달성했다는 저 AbsRel 0.130의 수치가 결국 SimSIN으로 fine-tuning을 한 모델인 것인데, 다른 방법론들은 NYUv2에서만 학습을 한 성능을 리포팅하여 비교하는 것 같아서 공평한 비교는 아닌 것 같습니다.
결론
일단 Indoor에서의 monocular depth estimation 분야가 생각보다 그리 활성화되지 못하는 상황에서 데이터 셋 취득 및 효과적으로 distillation 하는 방법 등 실용적인 측면에서 많은 고민과 노력을 한 논문임은 확실합니다.
다만 실험 섹션에서 평가하는 방식이 과연 공정한 평가 방식인지 의문이 드는 부분들이 많이 존재하였으며, 결정적으로 NYUv2와 같이 real dataset에서 생각보다 큰 성능 향상을 보이지 않은 것에 대해 simulation dataset으로부터 domain adaptation 하는 부분이 많이 부족하지 않았나 라는 생각이 조금 드는 것 같습니다.
안녕하세요. 리뷰 잘 읽었습니다.
서론을 읽다보니 궁금한 점이 생겨서 질문드립니다. Indoor 연구가 없는 이유에 대해서 설명한 부분을 읽어보면, 때로는 천장 때로는 책상을 측정해야 한다고 설명해주셨는데요. Outdoor 데이터셋들의 경우에는 주행 영상이기 때문에, 카메라의 높이(?)와 촬영 각도가 일정한 것으로 봤는데요. 그럼 Indoor에서는 촬영 각도와 높이가 달라지는 식으로 촬영되어 있어서 이러한 어려움이 발생한다는 것인지 궁금합니다. 예시에서는 확인하기가 어렵네요.
음 저도 처음 글을 읽었을 때는 저자가 말하고자 하는 의도가 무엇인지에 대해서 완벽히 이해를 하지는 못했었는데, 지금 생각해보면 먼저 indoor는 질문하신 내영처럼 촬영 각도가 매번 바뀐다는 의미는 아닙니다.
다만 indoor의 경우에는 직선구간이 짧고 장면이 크게 변하기 때문에 (예를 들면 처음엔 복도였지만 조금만 움직이고 회전하면 금새 책상과 쇼파 등 다양한 가구가 나타나 영상의 큰 영역을 차지한다던지, 아니면 금새 벽에 가로 막힌다던지) 깊이 추정 네트워크가 dataset의 depth distribution을 학습하는 것이 어렵다고 보시면 될 것 같습니다.
좋은 리뷰 감사합니다.
DPT가 상대적 depth를 추정하기 때문에 depth 정보는 knowledge distillation을 하지 않고, structure 정보만을 knowledge distillation 한다고 하셨는데, depth map에서의 sturcture 정보는 이미지에서의 structure 정보와 동일한 것인지 궁금합니다.
네네 맞습니다. depth map에서 object의 contour를 의미한다고 보시면 됩니다.