
안녕하세요. 이번에는 2015년에 Google에서 발표한 논문을 가져와 봤습니다. 이번 학기에 수강하고 있는 수업에서 이미지 캡셔닝이 언급되어서 궁금하여 읽어보게 되었습니다. 이미지 캡셔닝 분야에서는 Show and Tell 논문이 가장 유명한 논문이라고 합니다.
1. Introduction
1.1 Image Caption
우선 Image Captioning에 대해서 간단하게 말씀드리자면, 어떤 이미지를 잘 설명하는 문장을 만드는 것을 말합니다. 아래 예시는 이 논문에서 사용한 데이터셋 Flickr30k의 일부인데요. 예시를 보시면 이미지 아래에 이미지를 설명하는 description이 있는 것을 확인할 수 있습니다. Show and Tell 논문에서는 이를 NIC (Neural Image Caption) 모델을 이용하여 만들어보고자 합니다.

서론에서는 이미지를 설명하는 문장을 자동으로 만들어 내는 것(Image description)이 굉장히 어려운 task라고 설명합니다. image classification과 object detection보다 어려운 task라고 하는데, description을 만들기 위해서는 object를 인지해야할 뿐만 아니라 object와의 관계를 파악하고 이를 자연어로 표현해야 하기 때문입니다.
그런데 Show and Tell 논문에서는 이를 복잡하지 않은 방법으로 해결합니다. 논문의 저자는 NLP분야에서의 기계 번역에서 영감을 받았습니다.
1.2 Seq2Seq
Show and Tell 논문은 2015년에 나왔기 때문에 당시의 기계 번역에서 SOTA였던 Seq2Seq 구조의 일부를 사용하였습니다. Seq2Seq 모델을 간략히 설명하며 기계 번역이 어떻게 진행되는지 설명하고자 합니다.
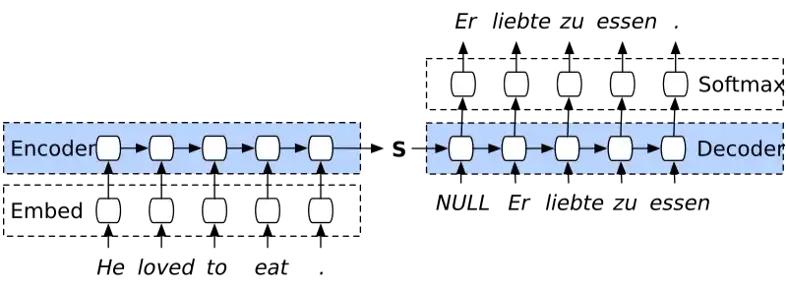
Seq2Seq 모델은 인코더-디코더 형태를 가지고 있습니다. 인코더에서 각 단어들을 학습하여 hidden state라는 벡터를 추출합니다. 이 hidden state를 다음 layer로 전달하여 학습하면 마지막 layer에서 추출한 hidden state는 입력된 모든 단어의 정보를 담고 있게 됩니다. 이를 context 벡터라고 말합니다. 디코더에서는 context 벡터를 이용하여 문장을 생성합니다. (예시 그림에서는 단어가 나오는 것을 확인할 수 있는데, 문장은 단어들로 만들어졌기 때문에 단어를 여러개 만드는 것은 문장을 만드는 것과 동일합니다.)
Seq2Seq 모델을 이용하여 기계 번역을 하는 방법은 생각보다 간단합니다. 번역하고자 하는 문장인 S(Source sentence)와 번역 문장인 T(Target sentence)가 있다면, p(T|S)를 최대화하는 T가 나오도록 학습하여 번역 할 수 있습니다.
논문의 저자는 위의 내용을 바탕으로 CNN에서 추출한 feature를 context 벡터로 사용하여 이미지를 자연어 문장으로 “번역”하고자 했습니다. 즉, CNN을 encoder로 사용하고자 했습니다.
1.3 Contribution
이제 본격적으로 model에 대해서 설명 드리기 전에 이 논문에서의 contribution이 무엇인지 작성하였습니다.
- Image description 문제를 푸는 end-to-end 시스템을 제안함.
- vision과 language 모델의 SOTA를 조합하여 모델을 만듦.
- 기본 SOTA 보다 더 좋은 성능을 보임.
2. Model
2.1 Loss Function
위에서 언급했던 것처럼 input으로 Image가 주어졌을 때 output인 Sequence의 확률이 maximizing하도록 학습됩니다.
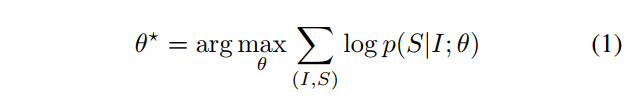
위의 설명을 수식으로 설명하면 (1)과 같습니다. θ는 네트워크의 파라미터, I는 이미지, S는 correct transcription을 말합니다. I가 주어졌을 때 예측된 S값의 log likelihood를 구합니다. 이 값을 maximize하는 파라미터 θ를 찾습니다.
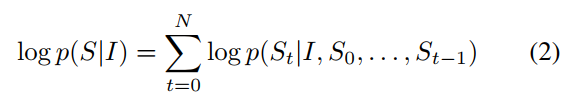
(1)의 \log{p(S|I)}는 chain-rule을 이용하여 (2)와 같이 표현할 수 있습니다. 문장은 여러 단어로 구성되기 때문에 chain-rule과 log의 특성인 곱을 합으로 표현하는 것을 이용하여 (2)와 같이 만들 수 있습니다. 위에서 Seq2Seq에서 설명 드린 p(T|S)와 비교했을 때 입력을 이미지로 바꾼 것이 차이점 입니다.
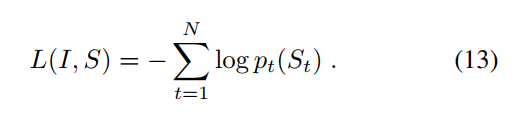
loss function은 (13)과 같습니다. correct word의 negative log likelihood의 합으로 loss를 구할 수 있습니다.
2.2 Model Architecture
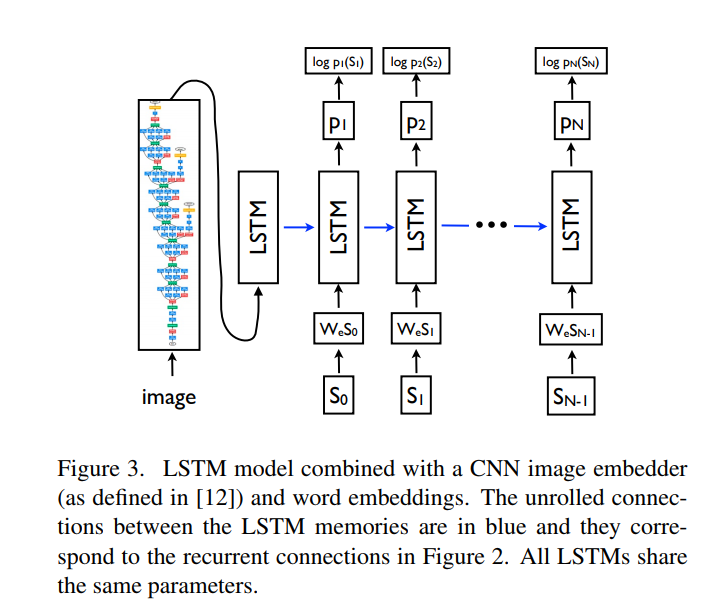
모델의 구조는 Figure3와 같습니다. 이미지를 이용하여 context 벡터를 뽑아내면 LSTM에 넣어 단어를 생성합니다. 매번 생성된 단어와 이전까지에 대한 정보를 포함하는 hidden state을 입력으로 받아 다음 출력물을 만들어 냅니다. 문장의 끝을 나타내는 end word가 나올 때까지 단어들을 뽑아내면 이 단어들이 이미지를 설명하는 description이 됩니다.
CNN 인코더 (GoogleNet)
이 논문에서는 당시 SOTA였던 GoogleNet을 인코더로 사용했습니다. ImageNet으로 사전학습된 모델을 사용하였고, 마지막에 FC layer를 추가하여 워드 임베딩과 같은 차원으로 맞추었습니다. 마지막 layer를 통과하여 최종으로 추출한 feature를 context 벡터로 사용하였습니다.
RNN 디코더 (Seq2Seq)
위에서 말씀 드린 것처럼 Seq2Seq의 디코더 부분을 그대로 사용하였습니다. Seq2Seq 모델은 RNN의 long-term dependency 문제를 개선하기 위해 LSTM(Long Short-Term Memory)을 사용하였습니다. long-term dependency는 RNN 구조를 가졌다면 필연적으로 발생할 수 밖에 없는 문제인데, 고정된 size의 hidden state는 입력으로 들어온 단어의 정보를 가지고 있습니다. 그런데 긴 문장이 들어온다면 hidden state는 고정된 길이를 가지기 때문에 자연스레 앞에서 들어온 단어의 정보가 손실될 수 있습니다. 이를 해결하고자 LSTM이 등장하였습니다. LSTM의 구조는 아래와 같습니다.
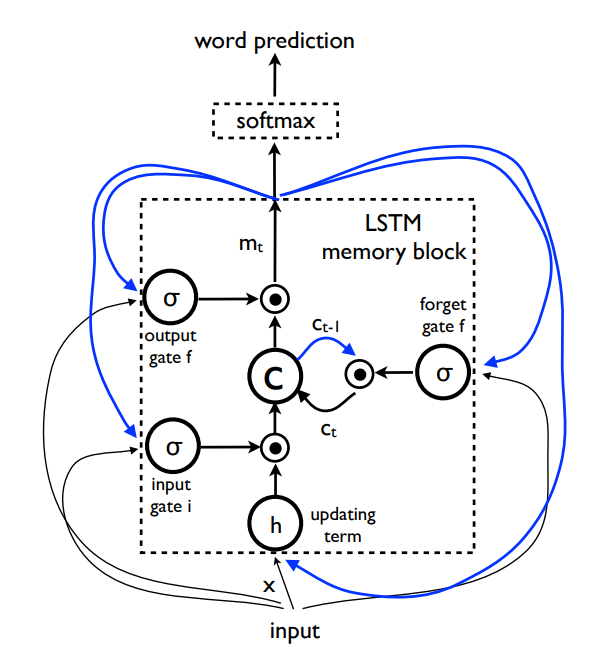
Figure 2를 통해 LSTM 구조를 확인할 수 있습니다. 처음 이 figure를 봤을 때 흔히 보던 LSTM이 아니여서 이 논문에서는 LSTM을 번형시켜서 사용했나 했는데, 단순히 그림만 이렇게 새로 그린 것이고 구조는 동일하였습니다.
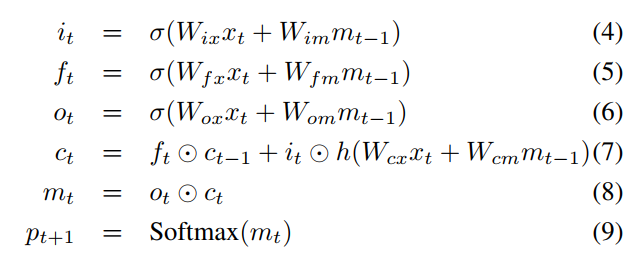
LSTM은 RNN과는 다르게 장기 기억(cell state)과 단기 기억(Hidden state; memory)라는 2가지 상태 정보를 저장하고 처리합니다. 장기 기억과 단기 기억을 3가지 gate를 이용하여 long-term dependency 문제를 완화하였습니다. 앞으로 3가지 gate인 forget gate f, input gate i, output gate o가 무엇인지 설명하고자 합니다.
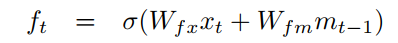
f_t는 어떠한 정보를 잊게 만들지를 결정합니다. 새로운 단어(x_t가 입력으로 들어오면서 앞전에 들어온 정보 중에 필요하지 않은게 있을 수 있습니다. forget gate를 통해서 오래된 정보 중에서 필요 없는 정보는 잊을 수 있도록 합니다.
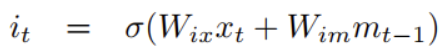
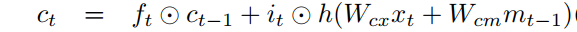
i_t는 새로운 정보를 반영하는 역할을 합니다. (7)을 보시면 h(W_{cx}x_t + W_{cm}m_{t-1})을 확인할 수 있는데요. 보통은 h(W_{cx}x_t + W_{cm}m_{t-1})을 \tilde{C_t}로 표현하여 i_t와 함께 불립니다. 장기 기억(cell state) C_t는 f_t와 i_t를 이용하여 업데이트 합니다.
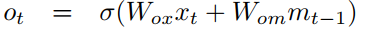
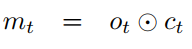
이렇게 장기 기억(cell state)을 구했으면 o_t는 장기 기억과 현재 데이터를 이용하여 단기 기억(Hidden State, 여기서는 m_t)를 갱신합니다.
Figure 3의 파란 선은 이전의 값이 다시 들어가는 recurrent connection을 의미합니다.
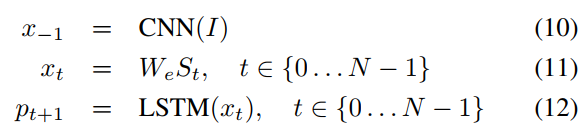
I는 이미지, S = {S_0, S_1\dots,S_N}는 이미지를 설명하는 문장, W_e는 워드 임베딩, S_t는 단어 사전의 크기와 동일한 차원인 원핫 벡터일 때 앞에서 설명드린 내용을 (10), (11), (12) 식으로 정리할 수 있습니다.
이미지(I)가 CNN에 입력되어 x_{-1}을 출력합니다. 단어 임베딩과 원핫 벡터를 곱해(W_eS_t) S_t의 단어 표현(x_t)를 만듭니다. LSTM에 이를 넣어 다음에 올 단어의 확률(p_{t+1})을 출력합니다. 이때 과적합을 방지하기 위해서 이미지는 t=-1인 시점에서 한 번만 입력됩니다.
2.3 Inference
이미지가 주어졌을 때 문장을 생성하는 방법으로 Sampling과 BeamSearch를 고려했다고 합니다.
Sampling
샘플링은 p_1 확률에 따라 첫 단어를 샘플링하고, 이 단어를 이용하여 p_{2}를 얻습니다. 즉. predict -> sample -> predict -> sample -> …를 문장의 끝을 나타내는 spectial token을 샘플링하거나 최대 길이에 도달할 때까지 반복합니다.
BeamSearch
BearmSearch에서는 매번 하나의 출력값이 아닌 Beam 개수(k) 만큼 출력값을 내놓도록 하여 다양성을 주고 마지막에 가장 좋은 Sequence를 선정하여 description을 만들어 냅니다.
사실 이 부분이 설명이 잘 안나와 있어서 이해가 잘 가지 않았는데요. 그래서 설명이 잘 나와있는 글을 발견하여 일부를 참고하였습니다. (참고)
- 첫번째 Decoding 단계에서 상위 k개의 후보를 고려합니다. (Softmax 결과 기준 확률 높은 k개)
- k개의 첫 단어 각각에 대해 K개의 두번째 단어를 생성한다.
- 생성된 첫번째, 두번째 단어를 조합하여(확률 곱셈) 상위 k개의 조합을 선택합니다.
- 상위 k개의 조합에서 k개의 세번째 단어를 선택하고 3번과 4번 과정을 반복합니다.
- 시퀀스가 종료된 후 전체 점수가 가장 높은 시퀀스를 선택합니다.
논문에서는 beam 사이즈를 20으로 설정하였다고 합니다.
3. Experiments
3.1 Evaluation Metrics
논문에서는 NIC를 통해 생성한 description을 평가하기 위해 사람이 평가하는 방법 외에는 100% 성능을 평가할 metric가 부족하다고 말합니다. 이 때문에 논문에서는 여러 평가 metric를 이용하여 성능을 보였습니다.(BLEU, METEOR, CIDEr, recall@k을 사용함.) 주로 NLP에서 사용하는 평가 metric이기 때문에 이해를 돕기 위해 각 metric이 어떤 성능 지표인지 간단히 설명하고자 합니다.
BLEU (Bilingual Evaluation Understudy)
BLEU란 n-gram을 통해 순서쌍들이 얼마나 겹치는지에 대한 측정을 통해 생성한 문장과 GT가 얼마나 유사한지를 나타냅니다. n-gram이 1이라면 단어 한 개씩을 비교하고, n-gram이 3이라면 3개의 단어의 집합을 비교합니다. 그런데 이렇게 비교하게 될 경우, 1-gram이라면 the, is 같은 중복된 단어가 많이 나오는 경우 높은 점수를 얻을 수 있다는 문제가 있습니다. 이를 보정하기 위해서 Cliping과 문장 길이에 대한 과적합을 보정하는 Brevity Penalty를 주었다고 합니다. (자세한 설명은 여기 참고)
BLEU 수식은 아래와 같습니다.
BLEU=min(1,\frac{output length(예측 문장)}{reference length(실제 문장)})(\Pi^{4}_{i=1}precisioni_i)^{\frac{1}{4}}사실 BLEU는 많은 문제점이 있는데, 단어의 순서쌍만 고려하기 때문에 문장 구조를 고려하지 않습니다. 또한 단어의 의미도 고려하지 않는다는 문제점이 있습니다.
METEOR (Metric for Evaluation of Translation with Explicit Ordering)
METEOR는 BLEU의 단점을 보완한 metric이라고 합니다. METEOR는 단어의 의미와 순서를 고려하여 평가합니다. 정렬성을 고려한다고 하는데, 단어 그 자체를 보는 BLEU와는 다르게 임베딩 벡터나 사전과 같은 유사성 도구를 사용하여 단어의 정렬성을 계산합니다. 이후 계산한 정렬도를 가지고 F-score를 계산합니다. 그런데 계산하는 과정을 살펴보면 여전히 겹치는 단어가 몇 개인지 계산하기 때문에 사람이 평가하는 것을 대체할 수는 없습니다. (자세한 내용은 여기 참고)
CIDEr (Consensus-based Image Description Evaluation)
CIDEr metric는 가장 설명이 없어서 이 성능지표가 무엇을 측정한 것이지 알기 힘들었습니다. 자세히 알고 싶으신 분은 CIDEr: Consensus-based Image Description Evaluation 논문을 참고해주시기 바랍니다. 간략하게 설명드리자면 CIDDEr는 각 n-gram에 대해서 TF-IDF (Term Frequency Inverse Document Frequency)를 이용하여 계산하였다고 합니다. (TF-IDF에 대해서 자세히 알고 싶다면 여기 참고)
각 n-gram인 w_k에 대해서 TF-IDF weighting g_k(s_{ij})를 계산합니다. (식 (1) 참고)
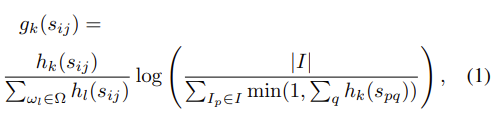
이후에는 모델이 생성한 문장(candidate sentence)과 이미지를 설명하는 문장(reference sentence)간의 코사인 유사도의 평균을 구합니다. (식 (2) 참고)
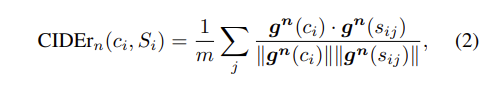
최종 CIDEr 값은 아래와 같이 구합니다.
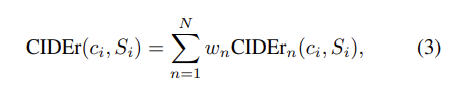
이렇게 BLEU, METEOR, CIDEr에 대해서 살펴봤는데, 모두 n-gram 방식을 사용하는 것을 알 수 있었습니다.
3.2 Datasets
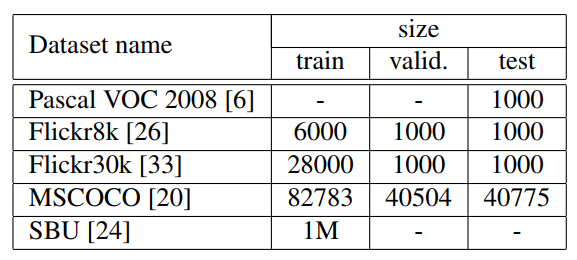
Show and Tell 논문에서는 위와 같은 데이터셋을 사용하였습니다.
3.3 Results
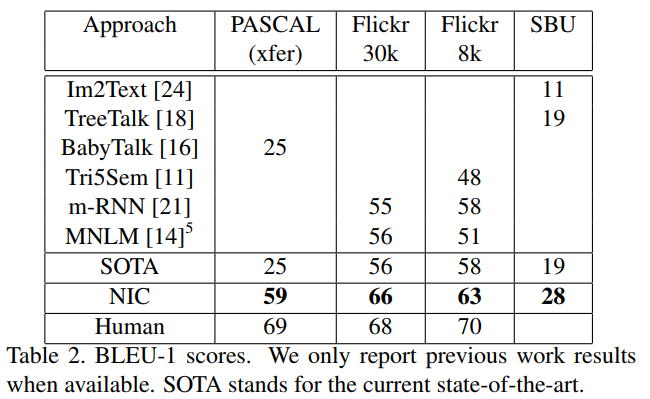
Table2를 통해 NIC가 당시 SOTA 보다 더 좋은 성능을 낸다는 것을 확인할 수 있습니다. Flicker 30k에서는 사람과 2점밖에 차이가 나지 않는데 무척 대단하다고 생각합니다.
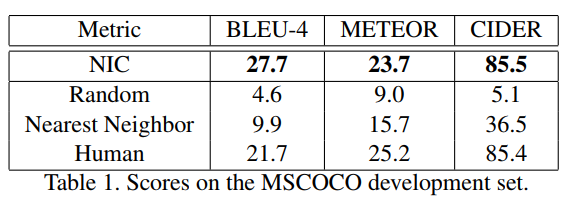
Table1을 보면 무려 NIC가 Human을 능가하는 점수를 받았다는 확인할 수 있습니다. 엄청난 성능인데요. 그런데 정말 Human 보다 높은 퀄리티의 description을 만들어 냈을까요? 논문에서는 정확한 성능을 측정하기 위해서 사람을 이용해서 NIC를 포함한 다양한 ML 모델에서 생성된 Caption을 평가하도록 했습니다.
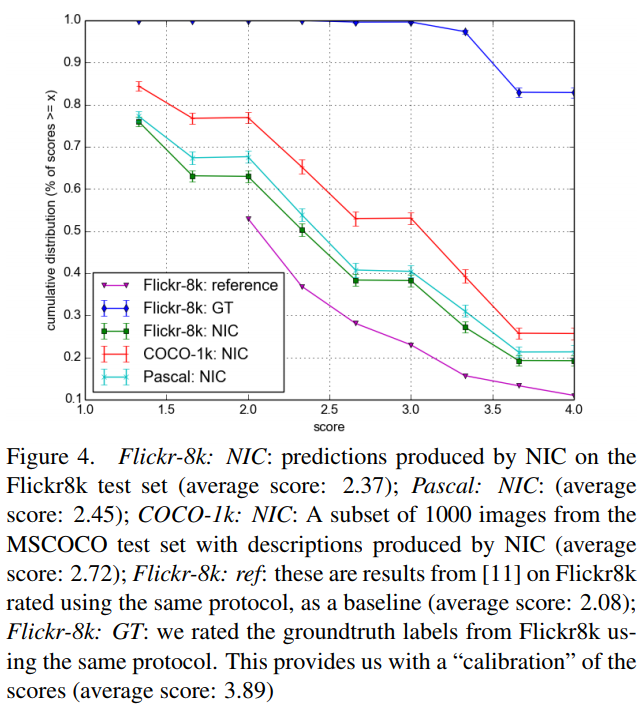
Figure 4에서는 사람이 평가하여 측정한 점수를 시각화 한 것을 확인할 수 있습니다. x축은 socre, y축은 socres > x인 누적 분포를 의미합니다. 점수는 아래의 기준을 통해 부여하였다고 합니다.
1점 : Unrelated to the image
2점 : Somewhat related to the image
3점 : Describes with minor errors
4점 : Describes without errors
Figure 4를 보시면 NIC가 다른 모델(reference)보다는 점수가 높지만 GT보다는 낮은 것을 알 수 있습니다. 그런데 앞서 언급한 Table 1에서 BLEU의 점수를 보면 NIC가 Human보다 높은 것을 확인할 수 있습니다. 이는 BLEU가 완벽한 metrix이 아님을 말합니다. 논문에서는 이러한 부분을 통해서 metric 연구에 대한 필요성을 언급하였습니다.

Figure 5에서는 사람이 평가한 것의 각 점수마다의 예제를 확인할 수 있습니다. 여기서 주목할 점은 2행 1열 이미지 입니다. frisbee(원반)이 이미지에서 굉장히 작은 부분을 차지하는데도 불구하고 NIC는 이를 가지고 caption을 만들었다는 것을 확인할 수 있습니다.
이렇게 Show and Tell 논문 리뷰를 마쳤습니다. 이 논문의 가장 큰 contribution은 이미지를 “번역”한다는 아이디어인 것 같습니다. 실제로 논문을 리뷰하면서 모델 구조가 인코더를 CNN 모델로 대체했다는 것 외에는 기존의 Seq2Seq와 다르지 않았고, 이런 간단한 아이디어임에도 불구하고 높은 성능을 얻었다는 것이 놀라웠습니다.
또한, 저는 최근에 수업 과제로 google에서 발표한 Towards a Human-like Open-Domain Chatbot이라는 NLP 논문을 리뷰했는데요. 2020년 논문이지만 2015년 논문인 Show and Tell에서 언급한 정확한 평가 metrix의 부재를 여전히 문제점으로 삼고 있습니다. 그만큼 sentence generation 분야에서 정확한 평가 metric을 찾는 것이 어려운 일이라 생각이 듭니다.
이상 리뷰 마치겠습니다.
감사합니다.
좋은 리뷰 감사합니다.
해당 논문이 기존의 {이미지를 이해 -> obejct 관계를 이해 -> 문장으로 설명}이라는 과정으로 생각되었던 이미지 캡셔닝 task에 {이미지를 문장으로 번역}이라는 개념을 가져와 단순하게 만들었다고 이해하였습니다.
Seq2seq에 대한 설명에서 p(T|S)가 최대가 되도록 한다고 하셨는데, 확률이 최대가 된다는 것이 어떤 의미인지 설명해주실 수 있나요??
또한, 해당 task의 평가는 사람이 진행한 것이라 하셨는데, 평가는 한 이미지에 대하여 여러 사람이 평가를 하는지도 궁금합니다!!
안녕하세요. 댓글 감사합니다.
1) 이는 기계 번역을 다시 간단히 설명드리며 질문에 답변해드리겠습니다. 번역이라는 것은 한 언어(source language; x)에서 다른 언어(target language; y)로 변환되는 과정을 말합니다. 이거를 확률로 해석할 수 있는데, “x가 주어졌을 때 y의 확률”로 말할 수 있습니다. seq2seq에서는 이 확률을 최대화하도록 하여 학습합니다.
2) 네 맞습니다. 2명의 사람이 한 이미지에 대해서 점수를 매겨 평가하였습니다. 두 사람의 점수가 다른 경우 평균을 취했다고 합니다.
안녕하세요 좋은 리뷰 감사합니다
seq2seq 언어 모델에서
“I love you”를
“나는 너를 사랑해”로 변역하고자 입력, 출력을 맵핑했을 때 어순이 다르더라도
I -> 나는
love -> 너를
you -> 사랑해
로 출력되도록 학습하는지 궁금합니다.
문장 전체에 대한 feature를 받게 되어 어순의 차이가 크게 영향을 미치지 않는것인가요?
안녕하세요. 댓글 감사합니다.
seq2seq 이전의 방법론으로 통계적 언어 모델과 Neural Network Language Model(NNLM)이 있는데 이때는 어순을 고려하지 못했다고 합니다. 이때는 정말로 이 단어가 나온 뒤에 어떤 단어가 나오면 될까에 대한 활률만 고려하기 때문입니다. 또한 고정된 길이만 가진다거나 여전히 문맥을 이해하지 못한다는 등의 문제가 있습니다.
그리하여 seq2seq가 나오게 된 것인데 한국어와 영어의 경우 어순에 따라 차이가 있기 때문에 단어, 단어로만 보고 번역하게 되면 잘 번역할 수 없습니다. 그리하여 문장의 전체(context vector)를 보고나서 생성하는 구조가 필요했고 seq2seq가 등장하게 되었습니다.
문장 전체에 대한 정보를 담고 있는 context vector를 통해 어순을 어떻게 처리할까에 대한 문제를 해결하였다고 생각하시면 될 것 같습니다.
굉장히 예전 논문이네요 리뷰 잘 읽었습니다.
CNN back-bone에 따른 ablation study는 없나요?
RNN 같은 경우는 vanishing gradient 문제가 발생하는 것으로 알고 있는데 LSTM에서 이를 어떻게 해결했는지 후에 세미나 혹은 리뷰에 보충해주시면 더욱 좋을 것 같습니다.
안녕하세요. 댓글 감사합니다.
1) 저도 이 부분이 좀 의아한 부분이었습니다. 인코더로 어떤 모델을 가져가는지에 따라서 성능 차이가 많이 날 것 같은데 ablation study가 따로 없더라구요. 제 생각에는 CNN 인코더로 SOTA 모델을 가져다 사용했기 때문에 SOTA 보다 성능이 낮은 다른 모델들을 사용해서 유의미한 성능이 나올 것 같지 않아 실험하지 않은 것 같습니다. 또한 contribution이 cv에서 SOTA인 모델과 nlp에서 SOTA인 모델을 합쳐서 사용했다는 것이기 때문에 그것을 강조하기 위해서 실험하지 않은 것 같습니다.
2) LSTM이 3개의 gate를 이용함으로써 vanishing gradient 문제를 해결했다고는 들었는데 정확히 수식적으로 확인하지는 못한 것 같습니다… 리뷰에 보충하여 작성하도록 하겠습니다.
안녕하세요 좋은 리뷰 감사합니다.
이미지가 과적합 방지를 위해 -1 시점에서 한 번만 들어간다고 설명해주셨는데, 왠지 생각해보니 여러 번 들어오는게 더욱 이상한 듯 하다는 생각도 듭니다. 혹시 이전 연구에서 입력 횟수에 따른 과적합 관련 실험이 있었던 건가요?
그리고 figure4에서 방식에 따른 설명에 ‘protocol’이라는 용어가 사용되는데, 무엇을 의미하는지 궁금합니다.
안녕하세요. 댓글 감사합니다.
1) 이 부분에 대해서는 왜 과적합 방지를 위해서 한번만 입력으로 넣은 것인지에 대해서 자세한 설명이 없어 넘어갔는데요. 그래서 related work 부분을 보았지만 딱히 언급은 없었지만, 아마 이전 연구들에서 비슷한 실험이 있어 이렇게 말한 것은 아닌가 추측합니다.
2) protocol이라는 용어는 사람이 점수를 매기는 방식(본문에서 언급한 1점에서 4점으로 점수 매기는 방식)을 의미합니다.
안녕하세요 좋은 리뷰 감사합니다.
설명해 주신 여러 평가 메트릭 중 BLEU는 단어의 집합에서 유사한 단어가 등장할 수록 score가 높아지고, 집합에 포함된 단어의 수를 n-gram으로 나타내는 것으로 설명해 주셨는데, 그렇다면 [표2]는 n-gram이 1인 결과값이고 [표1]의 BLEU-4는 n-gram이 4인 결과인가요? 그렇다면 두 평가 방식을 다르게 사용한 이유가 있을까요?
안녕하세요. 댓글 감사합니다.
1) 네 맞습니다. BLEU-1는 n-gram이 1 일 때, BLEU-4는 n-gram이 4일 때를 의미합니다.
2) n-gram은 보통 1에서 4까지를 보는데요. 1-gram일 경우 한 단어에 대해서 매칭이 얼마나 되었는지만 보기 때문에 문맥 혹은 단어의 순서를 평가하지는 못합니다. 4-gram일 경우 4개씩 매칭되는지를 보기 때문에 하나의 단어만 보는 1-gram과는 달리 단어의 순서가 얼만큼 맞는지를 평가할 수 있습니다. 이때문에 두 평가방식으로 점수를 매겨 비교한 것으로 생각됩니다.
안녕하세요 주연님 좋은 리뷰 감사합니다. 제가 이미지 캡셔닝에 대해 잘 모르고 있었는데 이 리뷰를 통해서 어느 정도 감을 잡은 것 같습니다.
LSTM은 순환 신경망의 한 종류이고 주로 시퀀스 데이터를 처리하고 long-term dependency 문제를 해결하는데 사용되는 모델이라고 정리를 하였습니다. 그리고 Forget Gate에 대한 이해가 확실치 않은데 제가 이해한 바로는 현재의 입력 x(t)에 가중치 행렬을 곱한값과 단기 기억 m(t)에 가중치 행렬을 곱한 값에 시그모이드를 씌워 0부터 1까지의 값을 가지게 하고 값이 1에 가까울수록 이전 정보를 많이 유지하고, 0에 가까울수록 많은 정보를 잊게 하는 방식으로 동작하는게 맞을까요??