
안녕하세요. 세 번째 X-Review 글입니다. 지난 번 X-Review에서 CBAM 논문을 리뷰 하며 SENet도 함께 소개했기 때문에 SENet과 관련된 내용은 이전 리뷰에서 확인해주시면 감사하겠습니다. 물론, 필요 시 다시 한 번 짚고 넘어가겠습니다.
0 Abstract
이전의 SENet은 어떤 문제점이 있었을까요? 다시 한번 SENet의 구조를 살펴보자면, SENet은 Channel-Attention으로 채널 별 Attention을 통해 모델의 성능을 올리는 데에는 효과를 봤지만, Global Average Pooling을 통해 채널 축으로 Flatten(Squeeze)하므로 위치 정보(Poisitional Information)를 고려하지 못하게 됩니다. 사실 이 점은 CBAM의 등장 배경과 동일한데, Coordinate Attention 기법은 또 어떠한 장점을 들고 등장할까요?

먼저 Channel-Attention과의 차이를 보겠습니다. Channel-Attention(SENet)이 2D Global Pooling을 통해 하나의 Feature를 만드는 방식을 사용한다면, Coordinate-Attention은 1D Feature를 Encoding하여 두 Spatial direction으로 Feature를 합치는 방식을 사용합니다. 해당 방식은 뒤에서 살펴볼 터이니, 주장하는 장점을 보겠습니다. 저자는 Coordinate-Attention을 통해 long-range dependencies를 고려하고 two-direction spatial으로 위치 정보를 보존하며 Attention을 적용할 수 있다고 주장합니다. two-direction spatial으로의 Attention이란 수직 성분과 수평 성분으로의 Attention 적용을 의미하는데, 이 부분이 CBAM과의 차이점이라고 볼 수 있겠네요. 물론 뒤에서 다시 살펴볼 예정입니다. 논문의 제목처럼 해당 모델은 MobileNet에 특히 강점이 있는데, 그 이유는 단순함과 유연함으로 Computational 측면에서 장점을 갖는다고 합니다. 그럼 다음 장을 보겠습니다.
1 Introduction
“Attention은 모델에게 어느 것(what)과 어느 부분(where)에 집중할 지를 말해주는 알고리즘이다.”는 이제 알고 있을 것 입니다. 아직 엄청난 성능 향상을 보이지는 못하는 것 같아도 꽤 다양한 방면에서 사용되며 구조의 단순함으로 인해 널리 사용되고 있지만 mobileNet 등의 경량화 네트워크에서는 Computational overhead 문제로 인하여 사용하기 쉽지 않다는 문제점이 있습니다. 이러한 Computational capacity를 생각해 봤을 때, SENet은 적합하지 않습니다. 또한 Abstract에서 말했듯이 Channel attention만 진행하는 문제점도 지적됩니다. 위치 정보를 잃어버린다면 long-range dependencies 또한 무시되기 때문입니다. CBAM은 이를 극복하고자 Spatial-attention을 적용하지만, 이 때 Convolution을 통하므로 지역적인 정보만 고려된다는 문제점을 지적합니다. CNN을 통한다면 고정된 크기의 커널을 사용하므로 long-range dependencies를 학습하지 못하기 때문입니다.
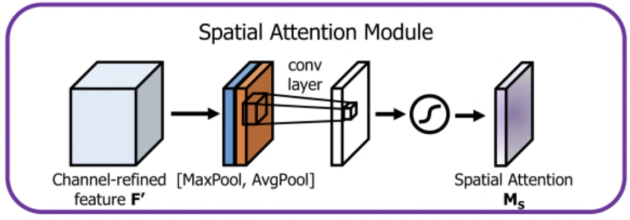
따라서 Coordinate-Attention은 2D global pooling이 아닌 1D로 Feature를 분해하여 인코딩하는 과정으로 Channel-attention을 먼저 진행합니다. Channel-attention을 진행 시 위치 정보를 임베딩 합니다. 아, 이렇게만 들어서는 잘 모르겠습니다. 수식을 보고 이해하는 것이 맞을 것 같습니다. 그래도 논문의 흐름을 따라 읽어보겠습니다. 결국 1D로 분해한다는 것이 (H,1)과 (1,W), 위치와 넓이 축으로 분해하여 수직 성분과 수평 성분에 대해 Attention을 적용하는데, 이렇게 해준다면 direction-specific information, 즉 방향에 대한 정보와 long-range dependencies를 모두 학습할 수 있습니다. 이러한 Attention map으로 원 Feature map과 연산한다면 ROI에 대해 강조할 수 있겠죠? Channel 뿐만 아니라 direction 정보도 얻을 수 있으니, SENet에 비해 효과적일 수 있습니다. 또한 해당 Attention 방법은 굉장히 light-weight, 즉 경량화 되어 있어 MobileNet에 적합하다고 설명하는데, 한번 실험 파트에서 들여다 봐야겠네요. 성능이 이만큼 올랐다는 이야기는 뒤에서 살펴보고.. Related work는 결국 MobileNet과 Attention 이야기이니 마지막에 부록 차 MobileNet에 대한 설명만 잠깐 추가해보겠습니다. 얼마나 Computation 성능이 좋으면, Related Work까지 총 네 번 정도 등장하네요. 방법론으로 들어가겠습니다.
3 Coordinate Attention
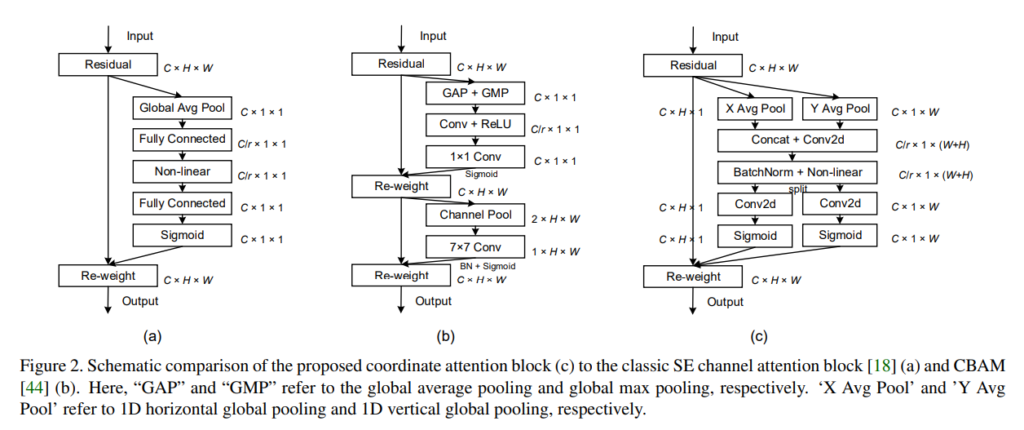
결국 Attention이란 내가 어느 부분과 연관성 있는지 알고자 하는 작업입니다. 입력 X에 대해 Attention map Y는 동일한 사이즈로 나오죠. 그래야만 원 Feature인 X에 곱하여 강조할 부분을 강조하고, 강조하지 않을 부분을 약하게 할 수 있기 때문입니다. 자.. Revisit Squeeze-and_excitation Attention의 목차가 보입니다. 물론 이전 CBAM Review에서 자세히 살펴봤지만, 해당 Attention 알고리즘을 토대로 만들었으니 수식을 잠시 짚고 넘어가겠습니다. SENet에서는 global average pooling(GAP)를 사용하여 Feature를 채널 축으로 합칩니다. GAP 연산으로 영상 전역의 정보를 합치는 효과를 불러올 수 있겠죠. 그렇다면 이 과정을 수식으로 살펴보겠습니다.
z_c = \frac{1}{H \times W} , z_c 는 c번째 채널에 대해 Squeeze 연산을 하는 모습입니다. 전체 H, W에 대해 합하여 H \times W 로 나누는 작업이 GAP이니, 하나의 채널에 대해 GAP를 연산한 것을 이제 전체 채널에 대해 모두 연산하여 합하면 되겠죠. 이를 다음의 수식으로 표현합니다. \widehat{X} = X \cdot \sigma ( \widehat{z} ) , \widehat{z} = T_2(ReLU(T_1(z))) , T_1, T_2 는 FC Layer를 의미하며 이러한 비선형 결합을 통해 Sigmoid, 즉 확률 값을 뱉어내어 Attention score를 뽑아내고 있습니다. 자, 이 논문에서 이 과정을 왜 소개했을까요? 사실 이 논문에서 얘기하는 Coordinate Attention은 z_c 를 뽑아내는 과정만 다를 뿐 입니다. H에 대해서 한 번, W에 대해서 한 번 연산해준다면 원하는 의미대로 이제 1 \times 1 \times C 가 아닌 H \times 1 \times C 와 1 \times W \times C 로 변환될 수 있기 때문입니다. 저도 이 과정에서 사실 조금 의아한 부분이 있었는데요. Global pooling은 아니지만, 하나의 차원을 1로 만들면 그 나름의 불 이득이 있으리라 생각했기 때문입니다. 하지만 이 과정이 모두 long-range dependencies를 위함이라고 하니, 뒤에 Grad-CAM 시각화 자료에서는 분명 보여졌으면 좋겠습니다. 그렇다면 말로 풀어낸 이 과정을 수식으로 다시 써내려보겠습니다.
z_c^h (h) = \frac{1}{W} \sum_{0 \le i < W} x_c(h, i) ,
z_c^w (w) = \frac{1}{H} \sum_{0 \le j < H} x_c(j, w)
네 , SENet과 유사한 모습을 볼 수 있습니다. 하지만 이제 우리는 H, W에 대해 각각의 연산을 통해 두 방향의 Spatial한 (H, 1) , (1, W) 를 얻을 수 있게 되었습니다. 저자는 이를 horizontal coordinate와 vertical coordinate라고 표현합니다. 즉 하나의 Feature map이 있다고 할 때 한번은 수직 방향에 대해 Attention을, 한 번은 수평 방향에 대해 Attention을 적용하는 모습입니다. 저자는 결과적으로 이러한 horiziontal, vertical coordinate는 direction-aware feature map을 생산한다고 합니다. 수직 방향, 수평 방향에 대해 Attention을 적용하니, 해당 Feature는 direction-aware, 즉 방향에 대해 더욱 잘 알 수 있다!는 주장은 합리적으로 들립니다. 또한 이러한 방식으로 long-range dependencies를 고려할 수 있다고 하는데, 아마 두 coordinate 사이 선형 결합을 통해 이루어지겠죠? 그렇다면 SENet에서 이 과정을 연산하는 다음의 식을 보겠습니다.
f = \delta (F_1 ([z^h, z^w]))
z^h, z^w 를 Spatial dimension으로 Concat한 다음 ([ , ]를 Concat으로 지정합니다) 비선형 활성화 함수를 취해줍니다. 아, SeNet도 그렇고 CBAM도 그렇고 Coordinate Attention에서도 마찬가지로, r 이라는 reduction ratio 파라미터를 두어 사이즈를 조절하는데, 이 점은 Attention 연산을 전체에 대하여 수행하는 그 전체의 Computational 측면의 이득을 얻기 위함입니다. 이제 SENet에서의 Feature의 형태는 어떻게 되었을까요? 다음과 같습니다. H와, W로 나뉘어져 있던 것을 합하고 Reduction ratio인 r로 나누어 줬다는 의미입니다. f \in \mathbb{R}^{C/r \times (H + W)}. 그렇다면 Coordinate Attention은 어떻게 될까요? H와 W로 나눴으니, 다음으로 표현할 수 있습니다.
f^h \in \mathbb{R}^{C/r \times H} , f^w \in \mathbb{R}^{C/r \times W}
하지만 이렇게 Feature를 둔다면 원 입력 Feature인 X와 채널 수가 같지 않으니, 1×1 Convolution 연산으로 channel 수를 조정해줍니다. 이 Convolution을 F 라 할 때 Attention score인 g 를 뽑는 수식을 보자면 …
g^h = \sigma(F_h(f^h)), g^w = \sigma(F_w(f^w))
!!! 드디어 끝이 났네요. 이제는 원 Feature와 곱해주기만 하면 됩니다! 처음 언급했던 것처럼 원본 Feature X에 대해 Attention score를 곱한 Y의 출력은 이제 다음의 수식으로 마무리 짓겠습니다.
y_c(i,j) = x_c(i,j) \times h_c^h(i) \times g_c^w(j)
Reduction ratio인 r을 많이 늘리며 Channel을 조정하여 Computational 측면에서 신경 썻다는 점은 추후 Ablation study에서 보기로 하고서, 사실 CBAM과는 조금 차이 있지만 SENet을 수학적으로 변형하며 표현한 과정이네요. 재미있는 점이 아래에서 다시 살펴보겠지만, 미리 살펴보자면 X Attention이나 Y Attention, 즉 하나의 축으로만 Attention 연산을 한 것은 이전 SENet 대비 성능 향상이 없다고 합니다. 어떻게 보면 이 Ablation Study에서 long-range dependencies를 말하고자 한 것 같습니다.
4 Experiments
Ablation study 먼저 살펴보겠습니다. 직전에서 언급한 X Attention, Y Attention과 Coord. Attention을 보겠습니다.
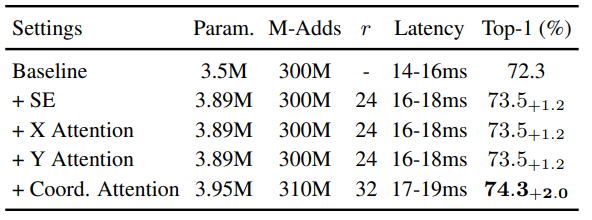
Baseline은 MobileNetV2 model이며, Coord. Attention을 적용 시 SENet 대비 0.8%의 성능 향상을 보입니다. 대신 Reduction ratio를 조금 높이 설정한 모습이네요. 다음은 SENet과 CBAM과의 비교입니다.
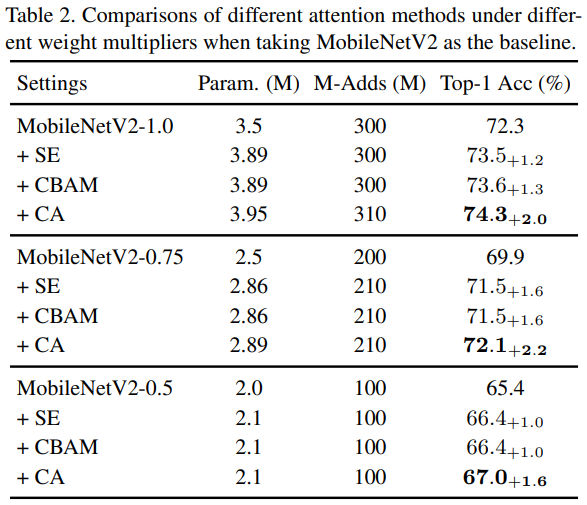
확실히 성능 향상을 보이는 것 같습니다. MobileNet에서는 SENet과 CBAM의 차이가 없네요.. Parameter 수는 달라지지 않았고, M-Adds 또한 달라지지 않았는데 성능이 0.6% 향상했네요. MobileNext에서의 비교도 있지만, 이는 넘어가고 Reduction ratio에 관한 Ablation study를 보겠습니다.
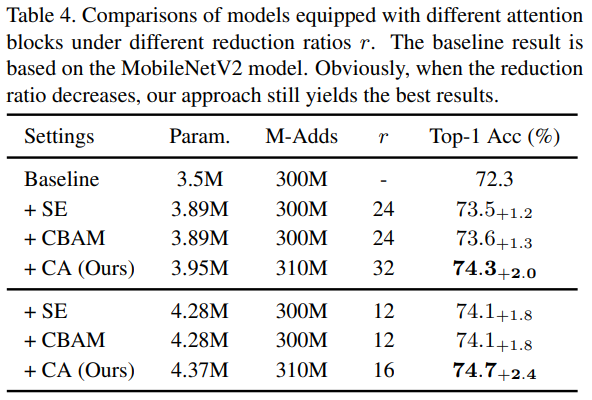
Reduction ratio를 32로 설정했을 시 높은 성능을 보였습니다. Reduction ratio를 낮출 시 더 성능 향상은 있지만 그만큼 파라미터 수가 증가한 모습이 보이네요. 이제 중요한 Grad-CAM입니다. Attention에서 Visuallization의 척도이기 때문에, long-range dependencies가 잘 보였으면 좋겠네요.
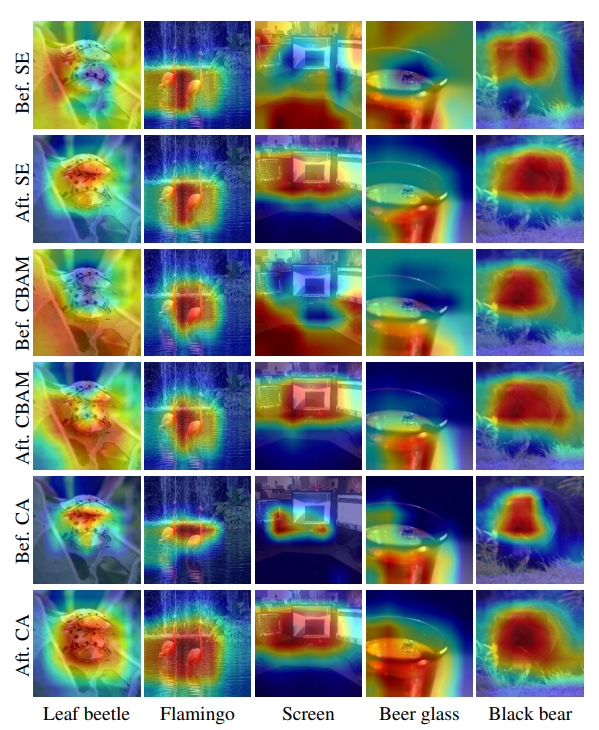
Bef.와 Aft.는 Attention 적용 전과 이후인데, 아무래도 다른 방법론에 비해 조금 더 넓은 범위로 Attention이 적용된 모습이 보이는데 과연 이 부분이 좋은지 안 좋은지는.. long-range dependencies와 연관 짓기에는 조금 한계점이 있지 않나 생각이 드네요. 다른 사진에 대해 보여줬으면 하는 아쉬움이 있지만 성능적으로는 확실히 좋아보입니다. 해당 Attention 알고리즘은 Object detection과 Segmentation에서도 사용되며, 이번에는 Object detection에서의 성능을 살펴보겠습니다.
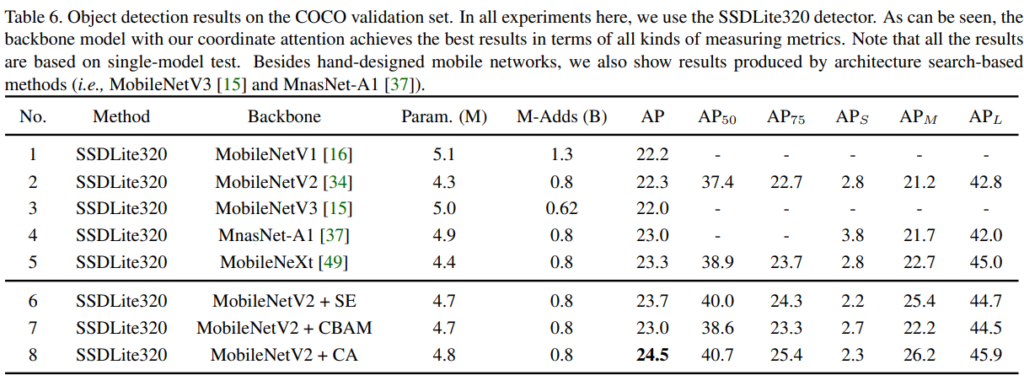
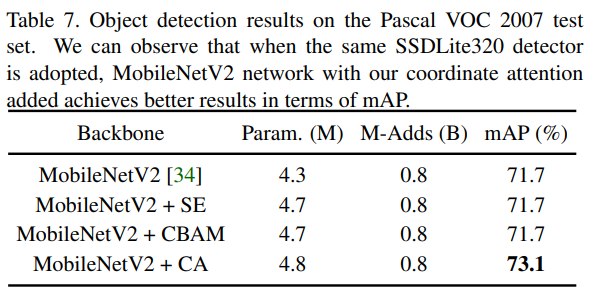
특히 Pascal VOC 2007에서 mAP가 타 Attention 방법론 대비 꽤나 많이 향상한 모습이 보입니다. 저도 이 부분에 집중했었습니다. 이번에 대해 결론은 딱히 없지만.. 아쉬운 점은 그렇다면 ResNet에서도 한번 성능을 실험해보고 FLOPs나 Object detction에서의 FPS 정도를 리포팅 했더라면 MobileNet에 적합한 Attention이다!하는 주장의 설득력이 더 충분하지 않았을까 하는 생각이 드네요. 이상 리뷰를 마치겠습니다.
안녕하세요. 리뷰 잘 읽었습니다.
질문이 몇 가지 있는데, 가장 먼저 왜 해당 논문의 저자는 자신들이 제안하는 attention 기법이 mobilenet에 적합한 attention이라고 주장을 하는 것인가요? 그냥 어떠한 CNN backbone에서도 다 적용 가능하고 성능에 이점이 있을 것 같은데, 왜 mobilenet에 초점을 두고 설명 및 실험을 진행하였는지 이해가 가지 않네요.
작성해주신 리뷰 내용 중 인트로 부분에서 “Attention은 ~~~ mobileNet 등의 경량화 네트워크에서는 Computational overhead 문제로 인하여 사용하기 쉽지 않다는 문제점이 있습니다. 이러한 Computational capacity를 생각해 봤을 때, SENet은 적합하지 않습니다.” 라고 작성해주셨습니다. 근데 지금 논문에서 제안하는 CA가 SE보다 더 많은 파라미터 및 latency를 잡아먹는 것 같은데, SE가 computational capacity 관점에서 부적합하다면 CA는 더더욱 부적합한 것 아닌가요? 위에 SE가 mobileNet 등 경량화 네트워크에서 부적합하다고 말씀하신 부분은 본인의 생각이신가요 아니면 저자가 논문에서 저런 논조로 얘기를 한 것인가요? 만약 본인의 생각이시라면 왜 그렇게 생각하신지 답변해주시면 좋겠습니다.
두 번째 질문은 1~4번 테이블에서의 표기 방식이 조금 헷갈리네요. Baseline이 제일 위에 있고 그 다음에 + SENet, 그 밑에 행은 + CBAM 뭐 이런 식으로 “+” 표기가 되어 있는데, 각각의 행들은 Baseline “+ ~~”로 개별적으로 봐야하는 것인가요? 아니면 바로 위의 행에 합쳐서 봐야하는 것인가요?(가령 테이블2에서 4번째 행 Ours는 Baseline + SE + CBAM + Ours 처럼 말이죠.)
안녕하세요. 좋은 질문 감사합니다.
질문을 읽어보고서 논문의 어조를 다시 살펴보니, 제 설명의 어투가 잘못되었던 것을 잡아 다시 설명하고 해당 부분을 수정하겠습니다.
먼저 인트로 부분에서 질문 주신 “Attention은 mobileNet 등에서 사용하기 쉽지 않다는 문제점이 있다”는 부분은 옳으나, Computational over-head 즉, 연산량의 문제로 인하여 VGG, ResNet, ResNext와 달리 비교적 한정된 모델 사이즈인 mobileNet에서 사용이 용이하지 않습니다. 다양한 Attention이 VGG, ResNet 등에서 일반적으로 사용되나 mobileNet 등의 한정된 사이즈의 네트워크에서는 잘 동작하지 않는다는 표현이 맞겠네요. SENet이 적합하지 않다는 어조는 없었으며, 오히려 SENet을 모델링하여 사용하고 있고 다시 표현하자면, SENet이 mobileNet에 적합한 Attention의 시초이지만, 해당 방식에는 문제점이 있다.는 표현이 더 옳은 것 같습니다. 지적 감사합니다.
그렇다면 해당 답변이 두 번째와 첫 번째 일부에 해당하는 답변으로 볼 수 있겠네요. 첫 번째 질문에 대하여 추가적으로는 여타 다른 CNN의 backbone에서 리포팅 한 논문들을 읽어보고서 Param, FLOPs 등에 대해 리포팅 된 결과에 대해 말씀드릴 수 있을 것 같습니다. 다만 핵심은 분명 다른 Attention 방법론이 MobileNet에 사용하기에는 Param 수 등이 훨씬 많아 적용하기에는 무리가 있다고 주장합니다.
마지막 질문에 대한 답변으로는 Baseline이 mobileNet에서 mobileNet + SE / mobileNet + CBAM / mobileNet+CA로 보는 것이 맞습니다. 말씀하신 것과 같이 개별적으로 보는 것이 맞습니다.
저도 논문을 읽고 작성하던 도중 의아했지만 직역하며 읽었을 때 그대로 작성한 느낌이 들어 질문을 토대로 다시 읽어보니 제 표현법이 어색했음을 알 수 있었네요.. 좋은 질문 감사합니다
본 방법론이 mobilenet에서만 실험을 수행한 이유가 비교군들도 mobilenet에서만 실험을 수행해서 혹시 그렇게 한건가요? 왜 mobilenet에 적합한지가 명확하지가 않네요. 추가적으로 베이스라인 실험을 보면 H와 W 방향으로 각각 Attention을 수행해줄때는 SE 대비 성능 향상이 없고, X와 Y 성능이 똑같은데요. 똑같을 수가 없을 것 같은데, 혹시 왜 이런지에 대한 설명이 있나요?
네 안녕하세요. 좋은 질문 감사합니다.
먼저 첫 번째 질문에 답변드리자면, 실제로 CBAM paper를 보면, ResNet50과 ResNext 등에 대하여 리포팅된 모습을 볼 수 있습니다. 논문의 취지는 mobileNet에서는 여타 다른 Attention 관련 방법론들이 Computational 측면에서 문제점이 존재하여 Param.등을 살펴볼 때 SENet, CBAM 등을 적용할 수 있는데, 해당 방법론들이 갖는 문제점, 특히 언급했듯이 long-range dependencies 관점에서 문제점이 있으니 해당 방법에 대해서만 리포팅하겠다!고 해석할 수 있겠습니다. 조금 복잡할 수 있지만 단순히 보자면 mobileNet과 같은 네트워크에서 사용할 수 있는 방법론은 여태 2가지 정도로 볼 수 있고 이를 개선한 Coord. Attention을 사용하겠다는 말인데, 그렇다면 저도 의문점으로 가졌던 것과 같이 다른 방법론들이 mobileNet에서 어느 정도의 Computational overhead를 갖는지 알 수 있다면 좋았을텐데라는 아쉬움은 남는 것 같습니다.
두 번째 질문에 대한 답변으로는 그러게요.. X Attention 즉 X Avg Pool을 하여 CxHx1 shape의 Attention과 Y Attention이 동일한 성능이 나오는 것도 웃겼는데, 심지어 SENet과 완전 동일한 성능을 모든 Param 등이 갖다는 측면은 물론 실험에서 나온 것이긴 하지만 큰 설득력이 없는 것으로 보여집니다. 해당 실험에서 말하고자하는 분명히 “자 봐 한 방향으로의 Attention만 하면 성능이 그대로인데 두 방향 모두 적용했을 때 올랐지? 왜 그럴 것 같애? 아 역시 두 방향 모두 해줘야 전 방향으로의 Attention을 보고 long-range dependencies를 볼 수 있기 때문이지?”라고 말하는 것 같습니다. 현재는 MobileNet V2를 베이스라인으로 두었으며 Reduction ratio가 다르게 세팅되어 있는 것은 Latency 미 param. M-Adds 등에서 굉장히 비슷한 상황을 만들었을 때의 Top-1 score를 보기 위함인데, 논문에서도 X-Attention과 SENet의 성능이 동일한 이유에 대해서는 언급을 안하고 있어 아쉬운 것 같습니다. 아마 그렇게 보자면 X Attention 혹은 Y Attention 한 방향으로만 하는 것을 Channel Attention에 더하여 하나도 장점이 없다고 해석할 수도 있겠습니다. 좋은 질문 감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
ablation study 부분이 헷갈린데, + SE, + X Attention 이렇게 되어있는 거는 baseline + SE, baseline + X attention으로 이해할 수 있을까요? (baseline + SE + X attention이 아니라)
또한, Baseline + Coord, Attention에서 Attention은 x attention, y attention을 모두 적용한 것으로 이해하면 되는 걸까요?
감사합니다
네 안녕하세요. 좋은 질문 감사합니다. 정확히 논문에서 나와있지는 않지만 본문에 있는 그림을 토대로 해석한다면 X Avg Pool 이후 Conv2d를 거치고 BatchNorm + Non-linear(오피셜 코드를 보면 ReLU6를 사용했습니다.) 이후 다시 Conv2d (Reduction ratio를 통해 Param 수를 조절하고자 Conv2d를 두 번 통과합니다.)를 통과한 다음 Sigmoid만 통과하는 방식으로, baseline + SE + X Attention이 아닌 baseline + X Attention으로 해석하는 것이 맞습니다.
두 번째 질문에 대한 답변으로는 Coord Attention은 X Attention과 Y Attention을 모두 적용한 것이 맞습니다. 모델 그림을 다시 살펴보면 X Attention (Width Avg Pool -> (C x H x 1))과 Y Attention (Height Avg Pool -> (Height Avg Pool -> (C x 1 x W))를 둘 다 사용한 (C) Ours 방법이 Coordinate Attention입니다.
안녕하세요 좋은 리뷰 감사합니다.
ablation study에서 baseline에 se, x attention, y attention을 각각 적용한 결과가 동일하게 나온 점이 흥미로웠습니다. 한 방향으로 진행된 attetion은 그 방향에 상관없이 효과가 동일하다는 것을 보여주는 걸까요?
안녕하세요. 좋은 질문 감사합니다.
다들 질문을 보면 첫 Ablation Study에 관심이 많으신데, 저도 다시 살펴보더라도.. 정확히 하고자 하는 말은 X Attention과 Y Attention을 동시에 사용한 Coord. Attention 방법론이 long-range dependencies를 고려하여 성능 향상을 보일 수 있었다고 말은 하지만, 그에 관련한 고찰은 논문에 실제로 담겨있지는 않습니다. 저도 읽으면서 정확히 성능이 같은 부분에서는 의아했지만 현재로는 그 이유에 대해서는 정확히 나와있지는 않습니다. 따라서 저자의 본 의도는 방향에 상관없이 동일한 효과를 갖는 Attention이라는 해석 보다는, 두 방향 모두를 고려한 Ours 방법이, long-range dependencies를 학습한다고 보는 것이 더 옳을 것 같습니다.