안녕하세요 오늘은 video copy localization인데, copy detection 논문을 들고왔습니다. 들어가기 전에 컨셉 중에서 일부가 저희 CVPR 논문과 유사해보이는 부분이 있어서 딱 눈에 보여서 읽게되었네요. 참고로 VCSL이라는 데이터셋이 작년 CVPR에 붙었는데, 올해 AAAI에 이 논문이 붙어서 비교해보니 VCSL 1저자가 이 논문 1저자네요. 데이터셋 활용겸 해서 논문 낸 것 같습니다.
Introduction
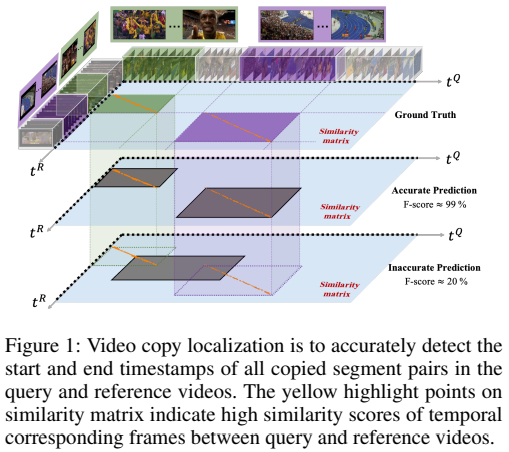
먼저 여기서 다루는 Video Copy Localization은 [그림 1] A 비디오와 B 비디오 사이에 일치하는 구간(세그먼트)을 찾아내는 것이 목표인 Task입니다. 원래는 VCDB 라는 데이터셋을 사용하거나, 다른 데이터셋이 몇가지 있기는 했는데요. 오래되거나 양이 작아서 크게 활발하게 연구가 수행되지는 않았던 것 같습니다. 그러던 와중에 대용량의 VCSL 데이터셋이 작년에 등장했고, 그 데이터셋을 활용해서 나온 후속 연구로 보면 될 것 같습니다.
이 논문에서 제안하는 TransVCL은 기본적으로 temporal한 정보를 반영할 수 있는 Transformer에 Similarity pattern을 찾아내는 detector가 붙어있다고 생각하면 됩니다. (A비디오와 B비디오 간의 유사도 matrix에서 패턴을 분석해서 일치 구간을 찾아내는 detector)
여기서 약간 특이한 점이 추가됩니다. 결국은 이 과정이 프레임과 프레임의 관계에 의존하기 때문에 global한 video-level representation이 손실된다고 합니다. 그래서 transformer 학습 과정에서 token을 하나 추가하여 video-level representation을 만들고, 이 token을 이용하여 비디오에서 해당 프레임이 video-level representation과 관련있는지를 확인하는 이진분류를 수행해서 이 작업을 보조한다고 합니다. (이렇게 global한 관점에서 비디오를 활용해서 특정 프레임을 분류하는게 어떻게 보면 컨셉이 좀 비슷해 보여서 읽게 되었는데… 그냥 Transformer의 Class Token이라서 딱히 뭐 없네요.)
TransVCL Details
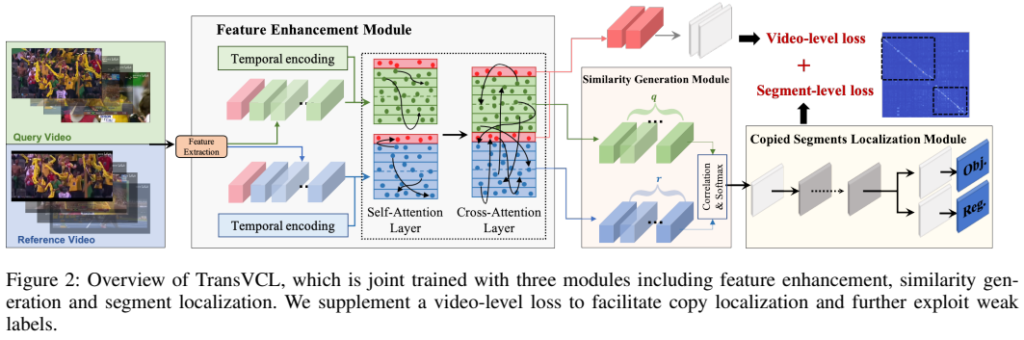
모델 구조는 [그림 2]에서 확인할 수 있는데요. 3개의 Module을 가지고 있습니다. Feature Enhancement Moudule과 Similarity Generation Module 그리고 Copied Segment Localization Module인데요. 앞의 모듈부터 차근차근 알아봅시다.
Feature Enhancement with Attention
이름에 Trans가 붙은 것처럼 Transformer 기반의 백본을 사용합니다. Query video로 부터 F^Q = \{f^Q_m\}^q_{m=1}의 frame-level feature를 추출하고, Reference video로 부터 F^R = \{f^R_n\}^r_{n=1}의 frame-level feature를 추출합니다. 당연히 m과 n은 해당 비디오들의 길이고, 그냥 프레임 단위로 feature를 뽑는다고 보시면 됩니다.
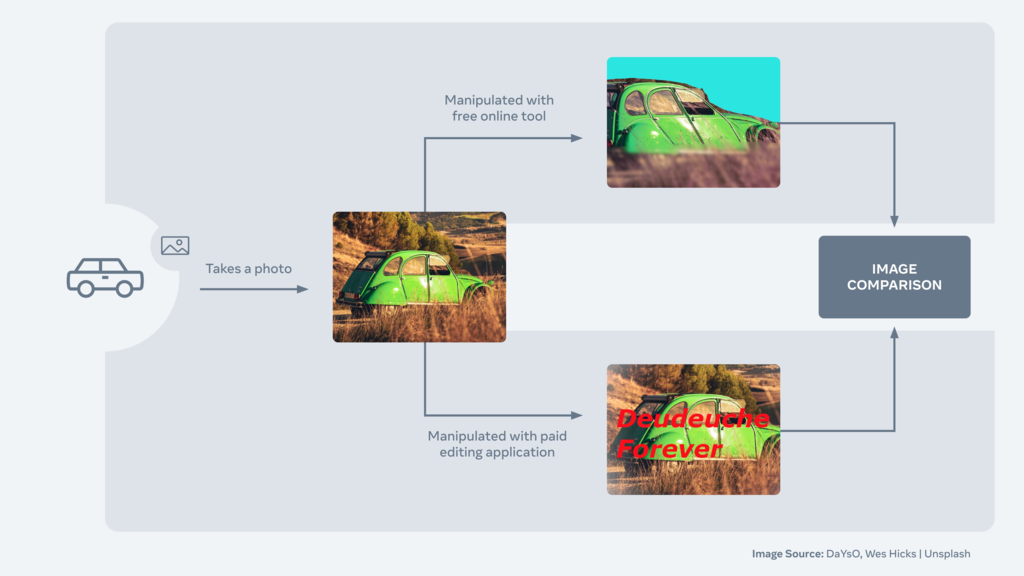
논문에 이 백본은 그냥 transformer면 된다고 되어있는데, 정확하게는 설명이 안되어있습니다. 코드에서는 YOLOv3에서 사용하는 PAFPN을 가져왔는데, 여기 백본은 CSPDarknet이긴 합니다. 비디오에서 이런류 백본을 쓰는것도 신기한데… 학습은 또 Facebook AI Image Similarity Challenge에서 위의 그림같이 동일한 이미지를 찾는 챌린지를 열었는데, 여기에서 제공하는 feature로 학습을 했다고 합니다. Matching 쪽에서는 이게 SOTA frame-level feature라서 가져왔다고 하는데, 이쪽 분야 논문을 안읽어본것도 아닌데 이렇게 가져오는건 처음보네요.
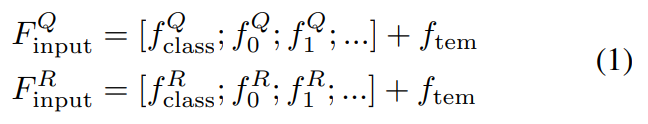
다시 본론으로 들어와서, temporal 정보가 중요한 localization task에서 이렇게 frame-level feature를 사용하면 temporal한 정보를 전혀 가지고 있지 않습니다. 따라서 이 초기 frame-level feature와 temporal encoding을 더해줘서 temporal 정보를 반영할 수 있도록 합니다. 이 과정이 [수식 1]의 과정입니다.
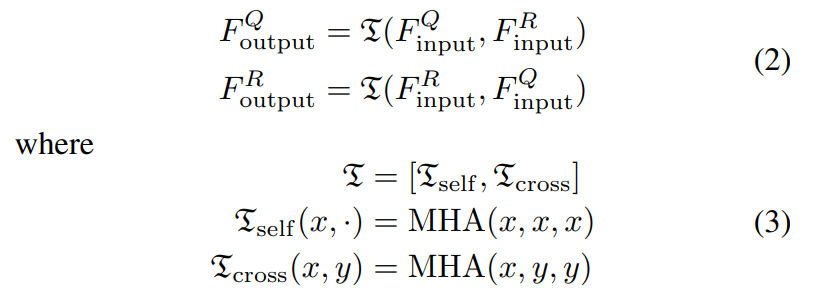
Self-attention과 Cross-attention은 [수식 2]와 [수식 3]을 통해 확인할 수 있는데, 일반적인 내용이라 넘어가도록 하겠습니다. Self에서는 같은 비디오 내의 프레임으로 사용하고, Cross에서는 key와 value는 서로 다른 비디오에서 가져온다고 보면 될 것 같습니다.
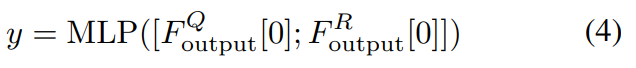
그리고 [수식 1]을 보면, Class token이 있는데요. 이 토큰을 global video feature로 활용합니다. 그래서 뭔가 추가적인 모듈을 통해서 global video feature를 활용하는건 아니고요. [수식 4]와 같이 Query 비디오와 Reference 비디오의 Class token을 concat하여 MLP에 Linear layer 하나가 붙은 분류기에서 binary classification 하는 형태로 이 부분을 학습합니다. 본 논문에서 다루는 Task는 Query랑 Reference 사이에서 유사간 구간을 찾아야 하기 때문에 이런 형태가 도움이 되는 것 같습니다.
Similarity Matrix Generation
기존의 frame-to-frame similarity matrix를 계산할 때는 최적화 과정이 없었다고 주장하며, dual-softmax operator를 적용했다고 합니다. (사실 이 부분은 공감이 조금 안되는게, 프레임과 프레임 끼리의 유사도를 구한 다음 refinement 하는 논문들을 몇개 봤는데요. 여기서 말하는 과정과 그 논문들의 차이가 없는 것 같은데… 아무튼 그렇다고 하네요.) 이 dual-softmax operator는 되게 단순하게 작동합니다.
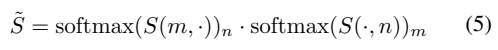
S_{mn}=\frac 1τ·\langle \hat f^Q_m,\hat f^R_n \rangle과 같이 similarity matrix를 정의할 수 있다 해봅시다. f는 frame-level feature이고, τ는 temperature인데요. 정리하면 frame-to-frame similarity matrix를 저렇게 표현합니다. 거기에 [수식 5]와 같이 softmax를 m축과 n축으로 각각 수행해줍니다. 결론적으로 Refinement를 수행해주는데, 그걸 모델을 통해서 하는것이 아니라 softmax로 대체했다고 보면 될 것 같습니다.
Copied Segments Localization
이제 Query 비디오와 Reference 비디오 사이에서 일치하는 구간을 찾아봅시다. 이 과정은 Similarity matrix를 얼마나 잘 만들었는가와 관련이 있습니다. 이 matrix는 일치하는지 일치하지 않는지를 표현하는 2차원 배열입니다.
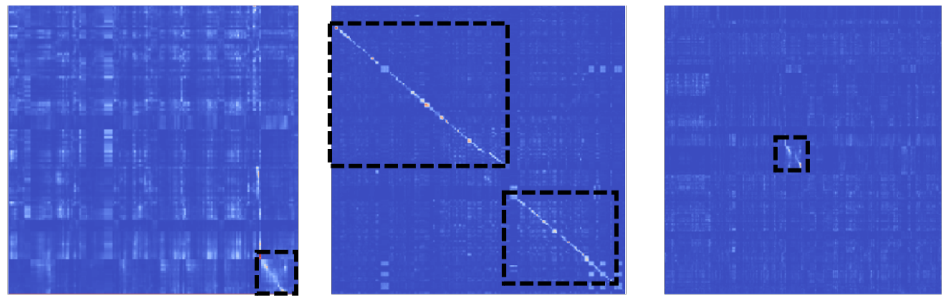
그럼 위의 그림과 같이 잘 보면 선이 생기게 되는데요. 이걸 object detector로 찾습니다. 본 논문에서는 YoloX의 detection head를 사용했다고 합니다. 사실 이렇게 하는게 맞나 싶기도 한데, 주파수 관점에서 접근하는 방법론들은 속도가 느려서 이런 방법론을 채용하는 것 같습니다.
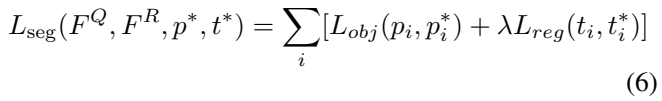
그래서 [수식 6]과 같은 Loss를 가지게 됩니다. p는 예측값, t는 gt값인데요. 별이 붙는 경우에는 binary label로 0/1의 값이고, 아닌 경우에는 좌표값 (top-left and bottom-right coordinates)이 들어옵니다.
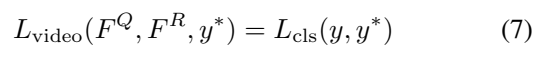
그리고 [수식 7]번을 통해서, 앞서 설명했던 global video feature를 통해 video-level copied prediction을 수행하는 Loss가 하나 더 있습니다. 자세히 살펴보면 Loss 자체는 Yolo의 Loss랑 같습니다. 비교해보면 L_{obj}는 Confidence Loss로 이름만 바꾸면 똑같은 것을 볼 수 있습니다. 그래서 자세한 설명은 넘어가도록 하겠습니다.
Extension to Flexible Supervision
모델이 video-level과 segment-level에서의 localization 둘 다 가능하게 되어있기 때문에, semi-supervised나 weakly-supervised로의 확장이 가능하다고 합니다. 이 부분은 대용량 데이터셋도 만들었겠다 싶어서 추가한 부분인 것 같네요.
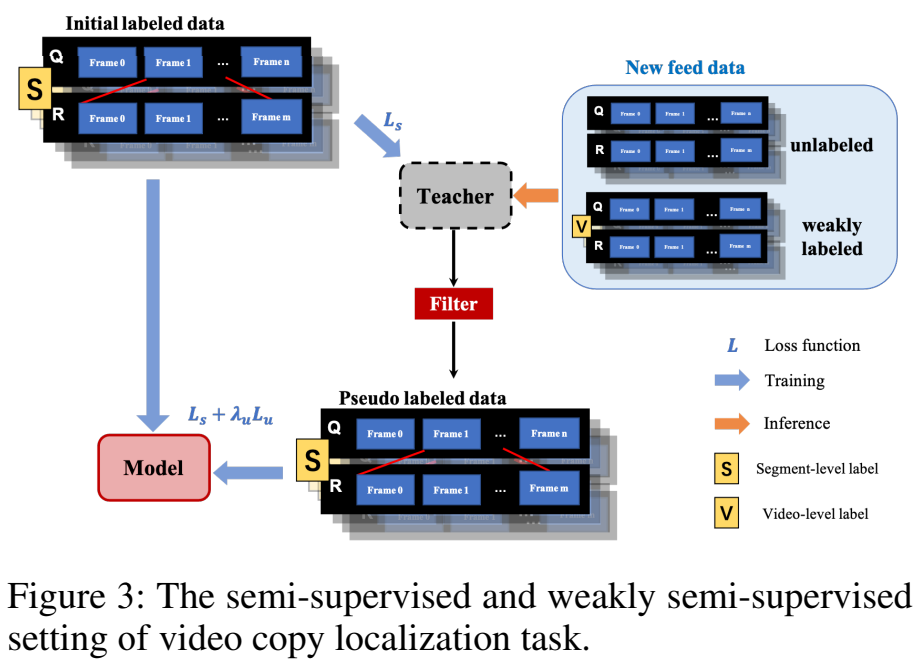
확장은 [그림 3]과 같이 수행됩니다. semi-supervised나 weakly-supervised를 위해 특별하게 추가되는 과정은 딱히 없어서 그 부분은 넘어가고, Loss만 바뀌는데요.
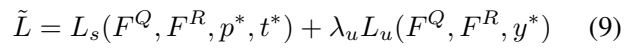
기존의 Segment Loss와 Video Loss만 사용하는데, 이제 Segment Loss에서 사용하는 별이 붙은 값들이 모두 pseudo label이 되고, y^*는 weakly supervised 상황에서의 video-level copied label이 됩니다.
Experiments
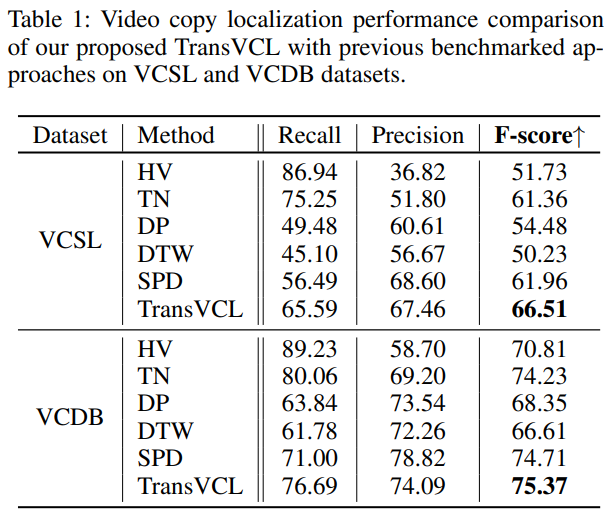
기존의 방법론과 비교를 좀 해보면 SPD가 좀 최근에 나온 방법이고, 학습이 필요한 방법론이고 나머지는 다 예전에 나온 방법론이고 학습이 필요 없는 방법론으로 보시면 됩니다. 좋은 성능을 보이는 건 맞지만 비교군이 살짝 애매하네요.
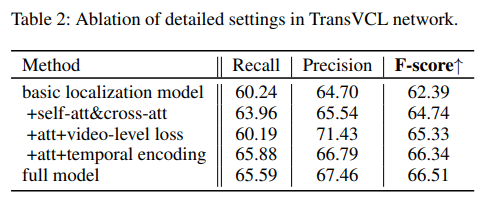
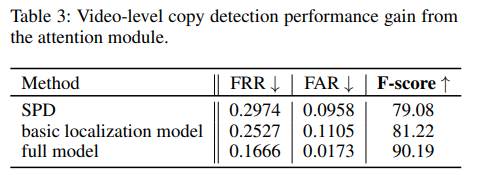
Ablation으로는 두가지가 있는데, 요것도 이제 잘 보시면 [표 2]는 그냥 Transfomer의 모듈 제거한 실험과 Yolo의 Loss를 뺀 실험입니다. 그리고 [표 3]로 다른 detector를 적용했는데 SPD 자체도 detector에 대한 자세한 설명이 없어서 아마 Yolo같이 다른 object detector를 쓰지 않았나 싶습니다.
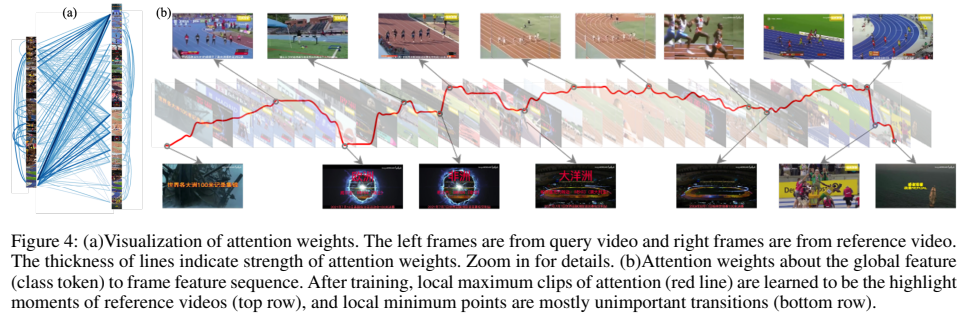
정량적인 그림을 확인해보면 주제와 관련 없는 프레임에 대한 attention weight가 낮은 것을 볼 수 있는데요. 이건 이제 Class token을 global video feature로 활용하는 방법이 잘 작동했음을 보입니다. 다만, 이게 잘 작동하는 이유를 좀 생각을 해보면 VCSL에서는 주제가 VCDB에 비해 많아지기는 했지만 120여개로 한정된 주제만 존재하기 때문에 학습이 가능한 것으로 생각합니다.
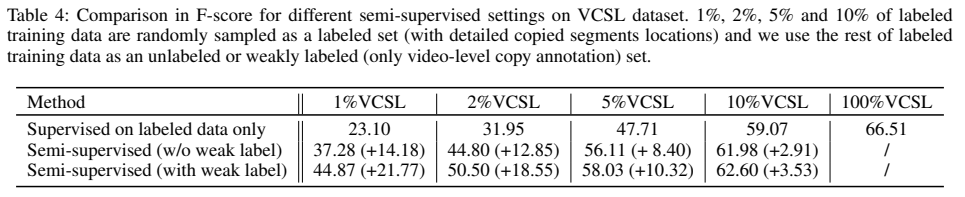
semi-supervised로의 확장 성능도 확인을 해보면, 10%에서는 지도학습 기반의 성능 대비 만족할만한 성능을 보여주고 있습니다.
Conclusion
아무리 생각해도 AAAI에 붙기에는 novelty가 너무 떨어지는 것 같습니다. 모델 자체는 논문에 설명은 없지만 코드를 열어보면 Yolo의 코드를 활용한 것이 보이고, Loss에서도 Class token을 global video-level feature로 활용한다는 점 빼고는 특별한 내용이 없었습니다. 성능이 높은 것도, 작년에 나온 데이터셋이라 아직 활용이 되지 않았고, VCDB로 평가에서 성능이 높은 이유도 비교군이 너무 예전 방법론들 밖에 없어서 그렇지 않았나 싶고요. 대단히 아쉬운 논문이었습니다.
리뷰 잘 읽었습니다.
질문이 한 가지 있는데, 수식 4번에서 각 비디오의 class token을 concat하여 binary classification을 수행한다고 하셨습니다. 여기서 이 binary classification을 한 결과가 global video feature라는 것인가요? 아니면 binary classification 과정을 통해서 학습한 class token들이 global video feature라는 것인가요?
그리고 이 binary classification은 무엇을 분류하는 목적으로 학습이 되는 것인가요?
“binary classification 과정을 통해서 학습한 class token들이 global video feature”이 맞습니다. 어떤 목적으로 global video feature을 학습하는지는 해당 task에 대한 이해가 필요하긴 한데… 단순하게 설명하면 정량적 그림을 같이 보면 비디오의 주제와 관련 없는 프레임이 있는 것을 볼 수 있습니다. 그리고 주제와 관련있는 프레임들이 존재하고요. 이 global video feature는 전체 주제를 대표할 수 있는 feature로 학습되기를 기대해서 주제와 관련있을 경우 attention weight를 높이고, 아니면 낮추는 방향으로 학습합니다.
리뷰 잘 읽었습니다.
1. temporal encoding이 positional encoding인가요?
2. global video feature를 생성할 때 binary classififcation을 진행한다고 했는데 뭐를 구분하는 task 인가요? global video feature를 생성하는 부분에 대한 detail을 조금 더 설명 부탁드립니다.
네 이 논문에서 temporal encoding이 positional encoding입니다. 논문을 읽어보면 주제 값과 관련된 텍스트(축구면 축구를 맞췄으면 0 아니면 1)를 활용하는 것 같은데, 코드 열어보면 해당 프레임이 주제와 관련된 프레임인지를 각각 예측하는 것으로 보입니다.
안녕하세요 좋은 리뷰 감사합니다.
Copy Localization task는 시각적으로 어느 정도 유사한 장면들이 GT로 구성되나요? 중간에 facebook challenge 그림처럼 저 정도의 변화도 copy localization task에서는 잡아내는 것인지 궁금합니다.
그리고 만들어낸 similarity map에 YoloX 모델의 detection으로 최종 proposal을 만드는 것으로 이해했는데, detection 성능에 따라 생길 수 있는 문제는 없는건가요?
여기서 detection을 수행하려는 대상 자체가 따지고보면 검은색 이미지에 흰색 대각선을 찾는것과 동일해서 detector의 성능이 그리 크게 영향을 받을것이라고 생각하지는 않습니다. Video copy localization이라고는 하지만 결국은 copy detection이라서 VCDB와 CC_WEB에서 동일한 비디오로 간주하는 정도면 같은 장면이라고 생각하면 편할 것 같습니다.