이번에 리뷰할 논문은 물체 검출 방법론 입니다. 트랜스포머 기반의 물체검출 중 DETR 계열의 방법론 중 처음으로 COCO 리더보드의 SOTA를 달성한 논문입니다. 현 시점에서는 해당 논문에서 제안한 스킬을 이용하여 추가적인 성능 개선을 보인 방법론들이 SOTA를 이루고 있습니다.
Intro
물체 검출은 컴퓨터 비전 분야에서도 기초 학문에 속하며, 많은 연구들이 이뤄져 왔습니다. 여러 연구 중에서 컨볼루션을 이용한 연구들(e.g. HTC++, DyHead etc.)이 COCO 리더보드에서도 항시 SOTA를 가져가며 훌륭한 연구 결과들을 보여줬습니다. 하지만 기존 컨볼루션 기반의 물체 검출 알고리즘은 hand-designed 요소들(e.g. NMS, default-boxes)이 여전히 남아 있어 하이퍼 파라미터 튜닝에 따라 성능 개선의 여지가 남아 있다는 문제가 있습니다.
컨볼루션 기반의 검출기 이외에도 트랜스포머 기반의 검출기인 DETR은 직접적으로 anchor set을 예측하며, attention을 이용하여 중복되는 anchor들을 줄이는 방식을 이용하기 때문에 hand-designed 요소들 없이 예측이 가능합니다. 하지만 이러한 장점에도 불구하고 DETR은 느린 속도와 decoder에 사용되는 query들의 의미가 불명확하다는 단점을 가지고 있습니다. 그렇기에 deformable attention을 적용한 Deformable DETR, positional encoding과 content(decoder의 query) information을 learnable하도록 구성한 DAB-DETR, 불확실한 bi-partite matching을 해소하기 위해 제안한 denoising (DN)을 적용한 DN-DETR이 제안되었습니다.
다양한 DETR 계열의 연구들이 진행됨에도 불구하고 물체 검출 분야의 SOTA(COCO 기준)은 컨볼루션 기반의 검출기가 선점하고 있었습니다. 이러한 이유에 대해 저자는 2가지 이유를 꼽았습니다. (1) 전통적인 검출기(컨볼루션 기반)은 많은 연구들이 진행되었으며, 높은 최적화가 진햄됨. (2) DETR 계열의 확장성은 연구가 미흡하다. 쉽게 풀자면 대용량 데이터를 이용한 학습과 거대한 백본을 이용한 연구들에 대한 리포팅이 현저히 부족함. 저자는 위 2가지 이유를 고려하여 새로운 기법을 제안하고자 합니다.
구체적으로는 앞서 소개한 DN-DETR, DAB-DETR, Deformable DETR을 기반으로 새로운 DETR 계열의 검출기를 제안합니다. 기존 DETR이 가지는 backbone, a multi-layer Transformer encoder, a multi-layer Transformer decoder와 multiple prediction heads로 구성됩니다. 추가로 3가지 새로운 기법을 제안합니다.
Method
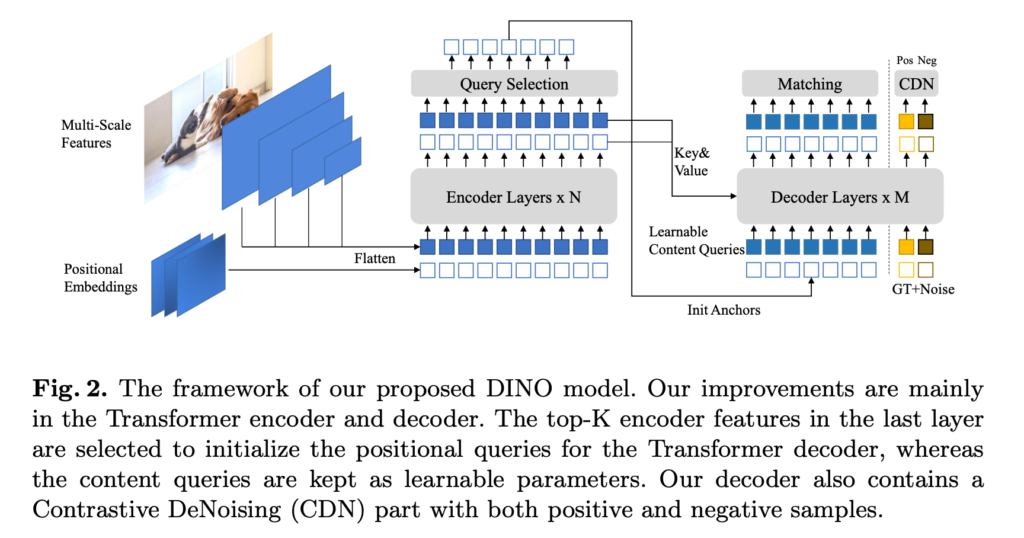
Contrastive De-Noinsing training (CDN)

해당 기법은 DN-DETR의 denoising training method를 기반으로 합니다. 기존 방법은 불안정한 bipartite matching이 원인인 느린 수렴 속도를 가진 DETR 계열의 모델들의 학습을 보다 안정적이게 만들어줍니다. 보다 구체적으로 이야기하자면 GT에 GT를 포한한 한도내에서 노이즈가 추가된 노이즈 GT를 생성하고 해당 값을 원본 GT 값으로 복원하는 추가적인 block을 구축합니다.
기존 방식은 수렴 속도와 학습 안정성을 높이기에 훌륭한 방법이지만 물체가 존재하지 않는 ‘no object’ 케이스에서는 약한 결과를 보여주었습니다. 그렇기에 저자는 ‘no object’ 에서도 예측할 수 있도록 useless anchors를 추가합니다. Fig 3의 오른쪽 그림과 같이 람다 크기에 따라 GT를 포함한 positive query, GT 외의 영역인 negative query로 구성됩니다. 여기서 negative query를 결정하는 람다2는 hard-negative sample에 가깝도록 최대한 작은 크기로 구성됩니다. 최종적으로 CDN은 GT 박스의 수의 2배 만큼 생성되며, 각각의 값들은 l1 loss와 GIoU loss로 구성되어진 box regression을 위한 reconstruction losses와 분류를 위한 focal loss로 구성됩니다.

저자는 해당 기법이 왜 잘 작동하는지에 대하 분석 내용을 함께 리포팅하였습니다. 저자가 언급하길 기존의 DETR 계열의 방법론들이 중복된 예측들을 set-based loss와 self-attention으로 줄일 수 있지만 Fig 8의 왼쪽 그림의 하얀 화살표와 같이 한계가 존재한다고 합니다. CDN은 유사한 박스에 대해 GT로 denosing을 수행하기 때문에 약간의 차이를 구분하는 능력이 커지기에 중복 이슈를 보다 잘해결한다고 합니다. 다음으로 원하지 않는 앵커를 예측하는 케이스에서는 CDN이 ‘no object’를 찾는 능력을 길러 구분하는 능력을 높여준다고 합니다.
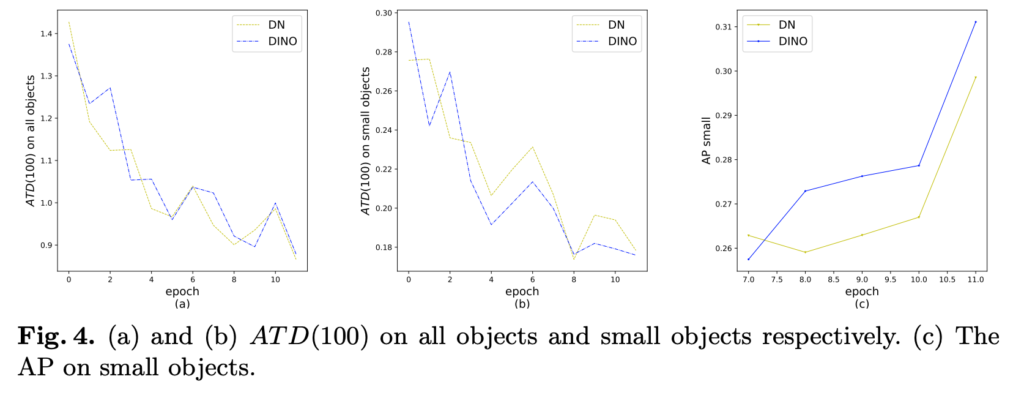
또한 저자는 DN 대비 CDN의 효율성을 보이기 위해 Fig 4의 실험을 진행하였습니다. 여기서 ATD는 Average Top-k Distance로 예측한 타겟과 GT 간의 차이를 측정한 메트릭입니다. 분석한 결과, all objects에서는 DN과 CDN 모두 좋은 결과를 보여줍니다. 하지만 작은 물체에 대해서는 CDN이 더욱 좋은 결과(Fig 4-(b))를 보여주고 있습니다. AP로 비교했을 땐, CDN이 +1.3AP라는 개선된 성능을 보여주고 있습니다.
Mixed Query Selection
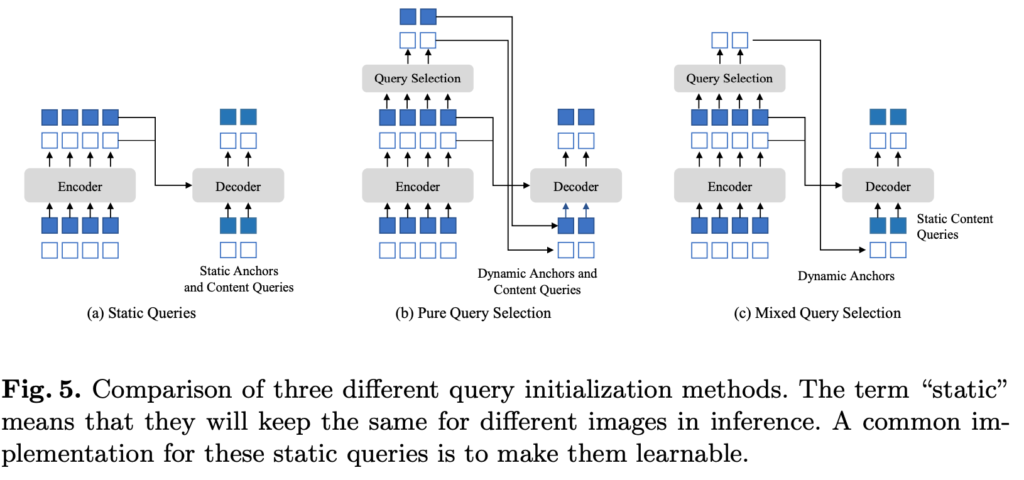
DETR과 DN-DETR에서는 Fig 5-(a)와 같이 개별적인 영상에 대해 정적인 embeding을 이용하여 decoder의 positional query와 0으로 초기화된 content query를 이용하였습니다. 즉,(+ 개별적인 영상에 대한 박스 예측값에 대한 초기값을 고정으로 사용했다고 보시면 됩니다.)그에 반해 Deformable DETR에서는 Fig 5-(b)와 같이 positional query와 content query 모두 학습 가능하도록 구성함으로써 개별 영상마다 동적인 초기화를 진행합니다. 동적인 초기화는 수렴 속도와 예측 성능을 향상시키는 효과를 야기했습니다. 저자는 해당 방법에 영감을 얻어 새로운 방법을 제안인 Fig 5-(c)인 Mixed Query Selection을 제안합니다.
Mixed Query Selection은 positional query만 동적으로 초기화 시키고 content query에 대해서는 정적인 초기화 기법을 이용합니다. 이러한 이유에 대해 저자가 주장하길, 이것들은 디코더에서 애매해모하고 잘못된 매칭을 야기시킨다고 주장합니다.
Look Forward Twice
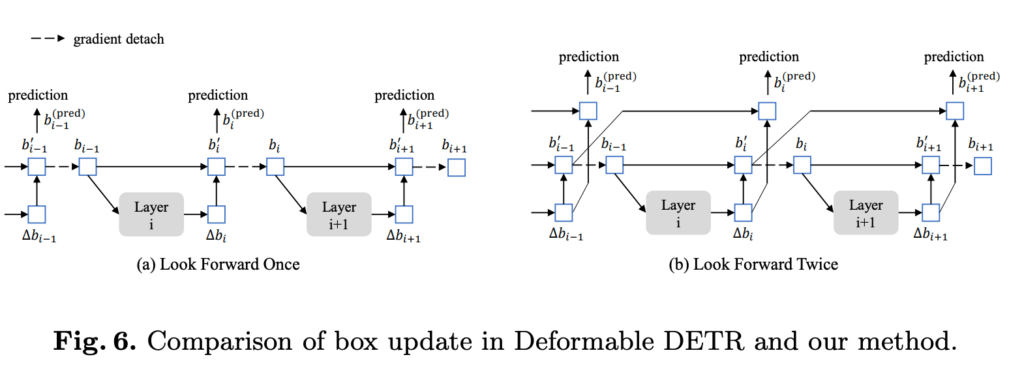
Deformable DETR에서는 이전 레이어의 정보를 활용하여 현재 레이어의 정보 강화시키는 방법(Fig 6-a)을 제안하였습니다. 해당 방법을 사용하면서 안정적인 학습을 진행하기 위해서 이전 정보에 대한 역전파를 끊는 방법을 제안하였습니다. 하지만 저자는 반대로 Fig 6-b와 같이 최종 업데이트에서 이전 레이어의 정보를 넘겨주고 이후 레이어의 역전파를 전달 받는 방식을 이용합니다. 즉, 기존 방식에서는 이전 정보를 토대로 업데이트를 진행하고 추가적으로 한번 더 업데이트를 진행합니다.
+ 이에 대한 저자의 고찰은 없지만, 제 추측으로는 LFO는 현재 레이어를 걸쳐 역전파를 수행하기 때문에 이전 레이어에 현재 레이어를 걸쳐 임베딩 공간에 대한 복잡성을 가진 상태로 학습을 진행하여 수렴이 불안정해진 것으로 보입니다. 이에 반해 LFT는 예측 값에 대해 직접적으로 전달 받기 때문에 상대적으로 복잡성이 적기 때문에 효과가 있는 것이 아닌가라고 예측합니다.
Experiment
실험에서는 COCO를 기반으로 평가를 진행합니다. 실험은 베이스 라인을 위한 ImageNet-1K로 학습한 ResNet-50을 bakcbone으로 두고 COCO로만 학습한 detector와 성능 개선을 위한 ImageNet-22k로 사전학습한 SwinL을 bakcbone으로 두고 Object365으로 사전 학습한 detector로 COCO를 fine-tuning한 모델로 구성됩니다.
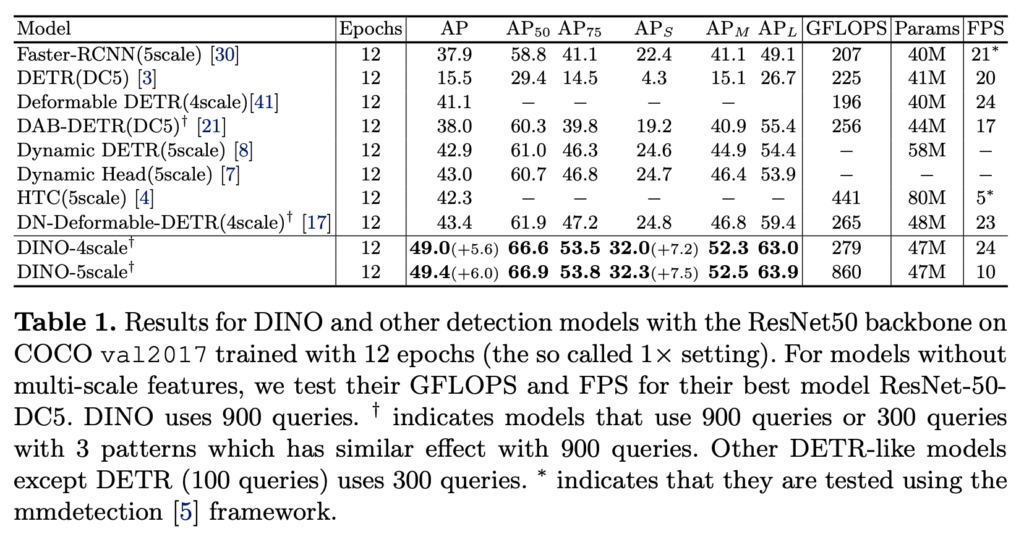
가장 먼저 Table 1은 epoch 12로 고정하여 학습한 resnet을 백본으로 둔 DINO와 이외의 SOTA 모델에 대한 결과 입니다. 같은 epoch에서 학습했을 때 가장 좋은 성능을 보여줌으로써, DETR 계열이 가진 문제점인 느린 수렴 속도를 극복한 것을 보여주고 있습니다.
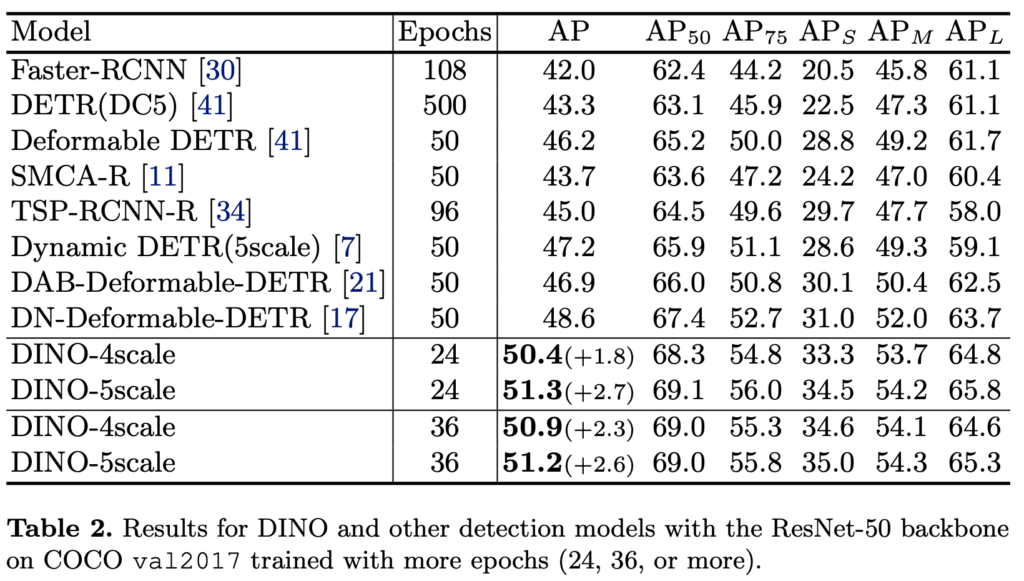
ResNet-50을 둔 백본들의 성능 비교 실험 결과입니다. 적은 에포크에도 불구하고 가장 좋은 성능을 보여주고 있습니다.
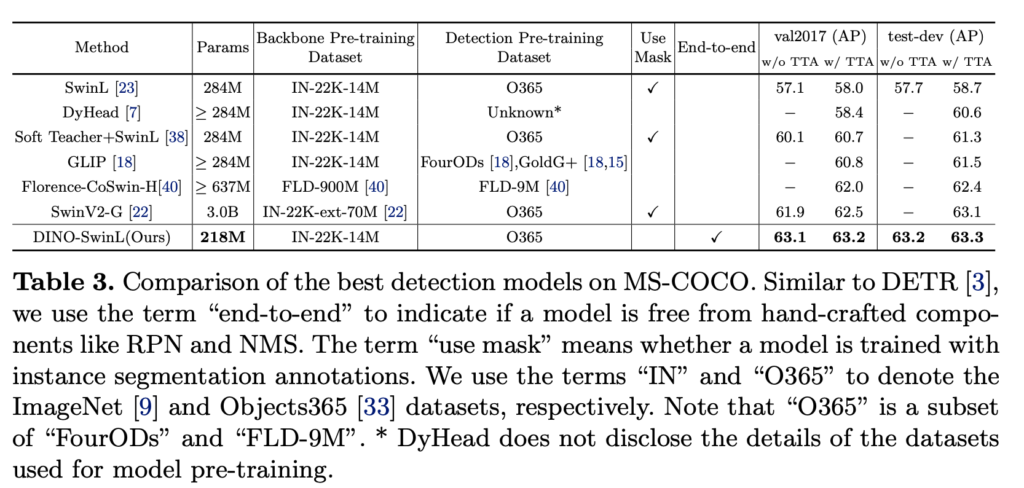
대용량의 백본과 대용량의 데이터로 사전학습을 진행한 기존의 검출기와 비교한 결과이며, 해당 모델 대비 가장 좋은 성능을 보여줍니다.
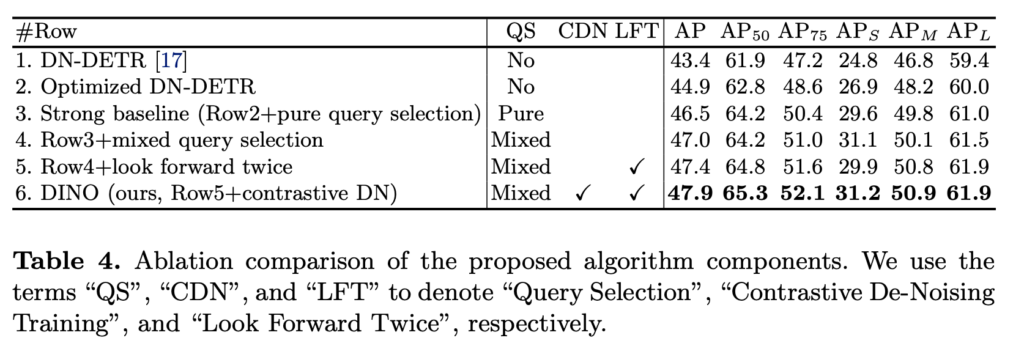
마지막으로 albation study 입니다. 모듈을 추가하면서 순차적으로 성능이 증가하는 결과를 보여주고 있습니다.
해당 논문은 task의 문제를 풀기 위해 기존의 연구들을 잘 활용한 연구입니다. 좋은 것들을 잘 연결 시키는 방법도 좋은 연구로 인정 받을 수 있다는 것을 보여준 좋은 논문으로 보입니다. 또한 이후에 진행할 검출 연구에 대해 좋은 영감을 준 논문이네요.