저는 최근 Self-supervised Learning (이하 SSL)과 Active Learning(이하 AL) 을 결합한 논문에 대해 리뷰를 한 적이 있는데요, 오늘 리뷰하려는 논문 역시 SSL+AL 에 대한 연구입니다. 그런데 최근에는 그닥 크게 연구되지 않은 예전 Self-Supervised Learning 인 Pretext task를 사용했다는 점에서 저의 호기심을 자극하였습니다. 바로 리뷰 시작해보도록 하겠습니다.
PT4AL: Using Self-Supervised Pretext Tasks for Active Learning
- Paper: (ECCV 2022) Link
- Supplementary: Link
- Code: Github
- Video (by author): YouTube Link

Introduction
Active Learning 은 전체 데이터를 라벨링하는 대신, 모델에 효과적인 결과를 가져오는 subset 데이터셋을 선별하는 방법을 연구하는 태스크입니다. 전체 집합 중 하위 데이터셋을 선별하는 방법은 크게 Distribution 기반과 Uncertainty 기반으로 나뉘는데요. 전체 데이터를 대표하는 하위 집합을 선별하여 라벨링의 중복성을 줄이는 방식이 Distribution (혹은 Diversity 기반이라고 하기도 함) 기반 연구입니다. 그리고 모델이 어려워하는 데이터를 선별하여 모델의 성능을 올리는 방식이 Uncertainty 기반 연구입니다.
(더욱 친절하고 자세한 설명은 저의 지난번 리뷰 중 가장 처음 Background 부분을 참고해주시기 바랍니다.)
지금까지도 양 진영에서 서로 자신들의 연구가 더 뛰어나다고 주장을 하고 있는데요. 본 논문은 두 마리 토끼를 잡기 위해 Self-Supervised Learning 의 대표적인 방법인 Pretext-task 를 사용했다고 할 수 있습니다. 그와 동시에 기존 Active Learning 의 고질적인 문제인 Cold-start 문제의 해답을 제안하기도 하고, AL의 SOTA까지 달성했다고 합니다.
어떻게 Self-supervised Learning 과 Active Learning 을 결합하였길래 Distribution과 Uncertainty 두 마리 토끼를 잡았는지 알아보도록 하겠습니다.
Using Pretext Tasks for Active Learning
우선 저자가 왜 하필 Pretext Task를 Active Learning 을 위해 사용하게 되었는지 그 동기에 대하여 알아야 합니다. 그러기 위해서는 Self-supervised learning(SSL) 에 대한 지식을 알아야합니다. (SSL에 대해 아시는 부분은 바로 패스 하셔도 됩니다)
Self-supervised learning은 기존에 매핑되어 있는 Label을 사용하지 않고, 데이터를 자체적으로 변형하여 만든 라벨을 사용하여 모델을 학습시키는 방법입니다. 대표적으로 하나의 이미지를 0도, 90도, 180도, 270도 회전시켜 모델의 입력으로 넣어주고 모델이 그 회전한 값을 예측하도록 모델을 학습시키는 방법이 있습니다. (< 참고로, 이 방법론을 본 논문에서도 사용하였습니다) 이렇게 기존에 있는 라벨을 사용하지 않고 자체적으로 데이터를 변형시켜 모델을 학습하는 이 과정을 (1) Pretext task라고 합니다. 이제 그 다음으로 (2) Downstream task로서 원하고자 하는 태스크에 앞서 학습한 모델을 활용합니다. 영상 분할, 객체 검출 등등 그 어떤 태스크도 가능합니다. 예를 들어 downstream task가 영상 분류라면 마지막 레이어에 FC Layer를 추가하여 Fine-tunning 하는 것도 Downstream task라고 합니다. 결국 제가 생각하기에 Self-supervised learning 은 훌륭한 모델 초기화 방법이라고 생각합니다. 이 방식을 사용하여 Downstream에 적용했더니 기존 supervised 기반의 연구보다 더 뛰어난 성능을 보이기도 하여서, SSL이 아주 인기를 끌었다고 할 수 있습니다.
(더 자세한 내용은 저의 과거 리뷰인 SimCLR: A Simple Framework for Contrastive Learning of Visual Representations 중 Self-Supervised Learning이란 무엇인가? 부분을 참고해주세요 ~ )
저자는 Pretext task가 Downstream에 효과적이었다는 것은, 곧 그 둘 사이의 높은 상관관계가 있다고 해석할 수 있다고 접근하였습니다. 그리고 이는 곧 저자로 하여금 pretext loss가 downstream task loss와 연관이 높다는 가설을 세우게 되는 동기가 됩니다.
Pretext task loss is correlated with the main task loss.
여기서 main task 는 downstream task를 의미합니다. 만일 downstream task가 영상 분류라면 classification loss가 될테고, 영상 분할이면 segmentation loss가 됩니다.
그래서 저자는 pretext task가 main task와 연관이 있다면, pretext가 어려워하는 이미지 역시 main task 에서도 어려워 할 것이라고 생각하여 해당 가설을 세웠습니다. 그리고 세 가지 데이터를 통해 그 연관성을 확인하였습니다. 아래 그림 2가 바로 pretext loss와 main task loss의 연관성을 나타낸 그래프입니다. x축이 main task인 classification loss를, y축은 pretext loss를 정규화하여 동일한 평가 데이터에 대하여 그래프로 나타낸 것입니다. 그 결과 왼쪽에서부터 CIFAR-10: 상관계수 \rho = 0.79, Caltech: 상관계수 \rho = 0.78, ImageNet: 상관계수 \rho = 0.88로 두 loss는 높은 상관관계에 있다는 것을 검증하였습니다. (게다가 세 가지 데이터셋이 개수, 크기, 클래스 수가 달라 다양하다는 것을 통해 충분히 설득력이 있다고 주장)
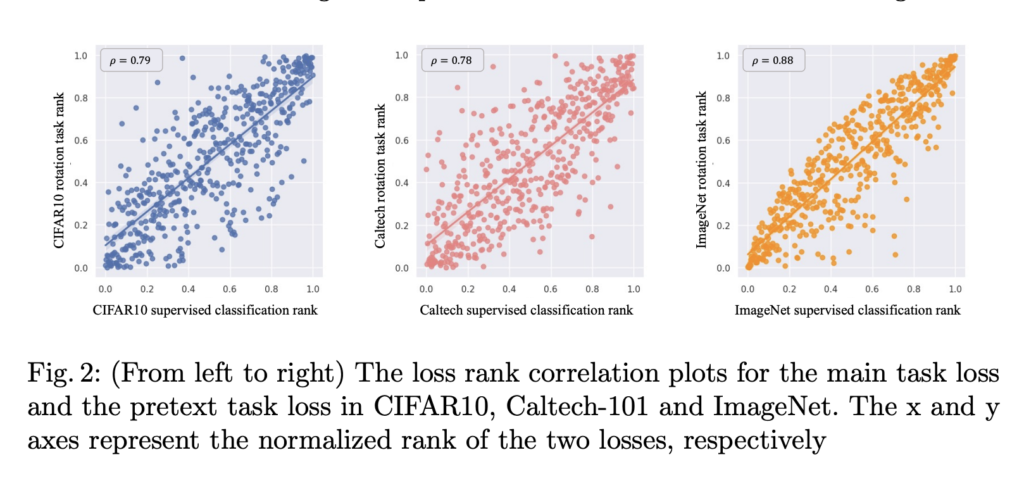
이렇게 Pretext task가 main task 와 연관이 있다는 것을 입증한 이유는 다름 아닌 저자가 제안하는 프레임워크의 첫번째 단계의 당위성을 증명하기 위함이라고 생각합니다. 이 부분은 바로 다음 섹션인 Method 파트에서 설명드리겠습니다.
Method
아래 그림 1은 저자가 제안하는 PT4AL (Pretext task for Active Learning)의 프레임워크를 나타냅니다. PT4AL은 (1) pretext task learning for batch split (2) in-batch sampling 두 가지의 요소로 구성됩니다.
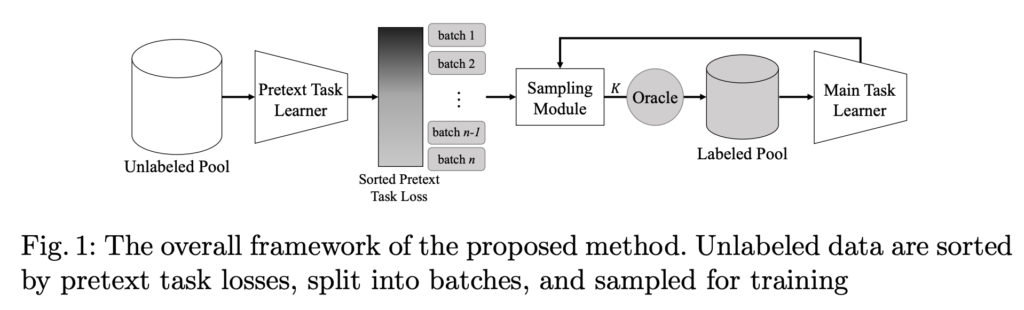
[1] Pretext Task Learning for Batch Split
첫번째 단계인 (1) pretext task learning for batch split은 Pretext task 로 전체 Unlabeled Data로 모델을 학습한 뒤, 전체 데이터를 i개의 batch로 나누는 단계입니다. 여기서 batch는 Active learning 의 각 cycle에서 데이터를 선별할 subset 입니다. 예를 들어, 1번째 AL 사이클은 batch_1에서 K개의 데이터를 선별하고, 2번째 AL 사이클에서는 batch_2에서 K개의 데이터를 선별합니다. pretext task로는 rotation pretext task를 사용하였습니다. (사실 저자가 제안하는 PT4AL에서는 Rotation prediction 말고도 Pretext task라면 제한 없이 어떤 것이든 사용할 수 있으나, 가장 대중적으로 사용되는 Rotation 을 이해를 돕기 위해 설명하였습니다.) 제가 앞선 예시로 든 0도, 90도, 180도, 그리고 270도 회전한 각도 맞추는 방법론이죠. 간단하게 pretext task의 loss는 아래와 같이 표현할 수 있습니다.
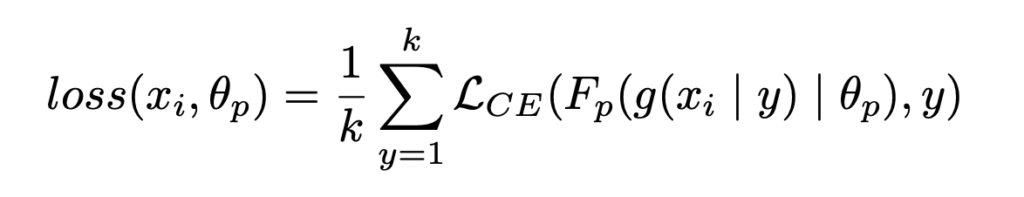
◀︎ Rotation Prediction Loss
L_{CE}는 당연히 Cross Entropy Loss를 의미하고, g( | y)는 pretext task에서 사용한 모델의 회전 각도에 대한 식을 의미합니다. 그리고 여기서 k는 0/90/180/270 각도 개수니까 4겠죠. 마지막으로 F_p는 Pretext task의 확률 분포를 나타냅니다.
이렇게 Pretext task 로 Unlabeled Dataset에 대해 학습을 진행합니다. 학습이 끝나면 이제 모든 Unlabeled Dataset인 X_U에 대하여 Pretext task의 Loss인 loss_{X_U}를 구한 뒤, 이 loss를 기준으로 모든 데이터에 대해 내림차순으로 정렬합니다. 그리고 정렬한 데이터에 대하여 Active Learning 의 cycle 횟수만큼 분할합니다. 예를 들어 Active learning을 총 10번 반복하고 싶다면 전체 데이터를 10개의 batch로 분할합니다. 그럼 첫번째 batch는 가장 큰 pretext loss를 가지는 데이터로 구성되고 마지막 10번째 batch는 가장 작은 pretext loss를 가지는 데이터로 구성되겠죠.
왜 이렇게 데이터를 배치 단위로 분할했을까요? (이제 여기서 저자는 pretext task와 main task는 서로 연관이 있다는 것을 주장하기 위해 가설을 세우고 이를 경험적으로 증명까지 했던 것을 기억하셔야 합니다.) 저자가 증명한 가설에 따르면 pretext task loss가 높으면 active learning 모델 역시 어려워할 데이터로 구성될 것입니다. 그 반대 역시 마찬가지겠지요. pretext task loss를 기준으로 데이터를 배치 단위로 AL 싸이클에서 선별할 데이터 풀을 미리 나눈 이유는: 저자의 Active learning 은 Uncertainty 기반의 방법인데, cycle이 반복되면서 Uncertainty 데이터에만 치중하여 선별하지 않기 위한 대비책이라고 할 수 있습니다.
데이터를 구분하지 않고 계속 Unlabeled Pool 전체 데이터에서 불확실성 기반으로 데이터를 선별할 경우, 선별된 데이터는 전체 표현력은 없고 결정경계에만 집중하여 포진될 것입니다. main task가 쉬워하는 데이터는 이미 그 클래스의 대표성을 나타내는 샘플이라고 할 수 있어, 후반의 싸이클에서 Distribution을 고려하여 데이터를 선별할 수 있는 효과를 가져옵니다.
따라서 1단계를 통해 Uncertainty 기반의 AL이더라도, 사전에 Pretext-task로 학습한 모델로 데이터를 분할함으로써 전체 데이터를 대표하는 샘플을 선별할 수 있도록 방법론을 제안하였습니다.
[2] In-batch Sampling
이제 Batch 내에서 Active Learning 을 수행하는 방법입니다. 그런데 PT4AL은 제가 지난번 리뷰했던 방법론과는 다르게 Pretext task의 가중치를 AL에서 사용하지 않고 단순히 batch 분할용도로만 사용하더군요. 그리고 Active Learning 에서 데이터를 선별하는 방식은 Least Confidence (LC)를 사용하였습니다. (LC에 대한 설명은 아래 이미지인 지난 리뷰로 대체하겠습니다)
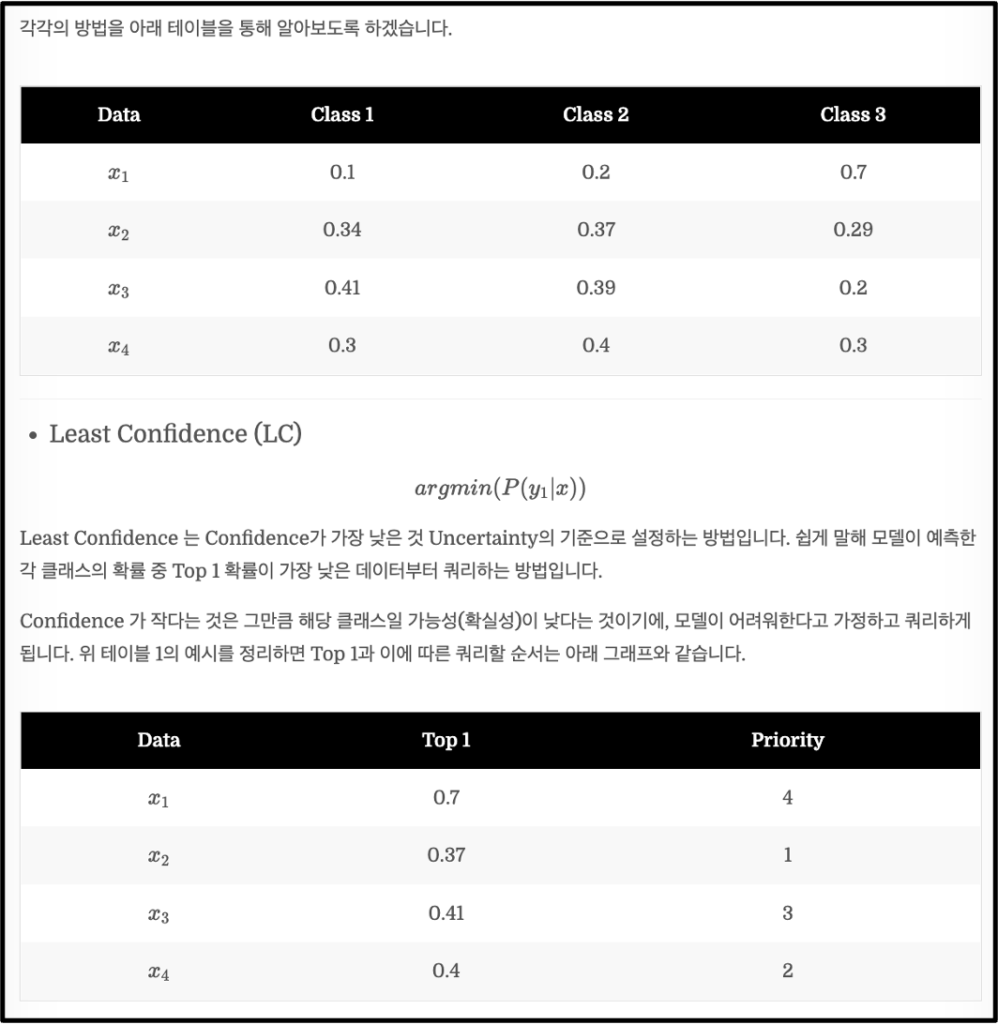
LC를 나타내는 데이터를 선별할 데이터 샘플러 \phi 수식 역시 간단합니다. 여기서 주의할 건, 바로 직전 Active Learning 에서 사용한 모델 F^{i-1}_m을 사용하여 데이터를 선별합니다.
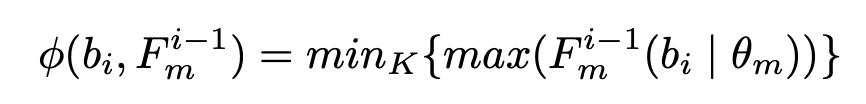
직전 모델이 없는 첫번째 사이클의 경우 loss가 비슷하다는 것은 시각적으로 유사할 경우가 높다는 경험적 관찰을 기반으로 idx가 5의 배수인 것으로 uniform하게 데이터 샘플을 선별하였습니다.
이제 이 PT4AL의 알고리즘을 정리하면 아래와 같습니다. 생각보다 굉장히 간단하죠?

Experiment
저자는 총 3가지 실험 결과를 보였습니다. 가장 대표적인 classification, 그리고 segmentation을 추가로 성능을 비교하여 확장 가능성에 대해 확인하였습니다. 또한 AL이 취약한 class-imbalance 상황에 대해서도 리포팅합니다.
Image Classification
CIFAR-10, Caltech-101, ImageNet-67에 대한 결과를 아래 그림 3에서 확인할 수 있습니다. 여기서 주의깊게 본 부분은 ImageNet이 아닌 ImageNet-67을 사용했다는 점인데요. ImageNet-67은 수월한 실험과 유사한 이미지로부터 오는 노이즈를 피하기 위해 WordNet 을 기반으로 67개로 클래스를 줄인 데이터셋을 의미합니다. (저희도 ImageNet으로 바로 적용하기 전에, 해당 데이터셋을 사용하면 좋지 않을까 하는 인사이트를 얻을 수 있었네요)
아래 테이블 중 빨간색이 바로 저자가 제안하는 PT4AL입니다. CIFAR에서는 최고 성능인 10 cycle을 돌렸을 때 95.13%를 달성하고, 모든 Cycle에서 가장 뛰어난 성능으 보임을 확인하였습니다. 특히, 가장 처음 cycle에서 55.85%로 랜덤하게 초기 Labeled data를 선별하는 기존 연구의 46.02%q보다 압도적으로 좋은 성능을 보일 수 있었습니다. 이를 통해 저자가 제안하는 Pretext-task 기반의 초기 라벨 데이터 선별 방법이 좋은 방법임을 알 수 있었습니다.
또한 정성적 결과도 확인하였는데요. 아래 그림 4 (a) 랜덤은 균일하고 데이터 전체에 걸쳐 균일하게 데이터를 추출하였지만, 결정 경계를 중심으로 추출하지 않아 큰 성능 향상을 가져오지 않았습니다. (b) Learning Loss는 결정경계에 너무 치중한 나머지 클래스를 대표하는 데이터에는 집중할 수 없었습니다. 마지막으로 (c) PT4AL은 결정 경계 뿐만 아니라 중간 부분의 데이터도 선별할 수 있음을 정성적으로 확인할 수 있었습니다.

Semantic Segmentation & Image Classification on an Imbalanced Dataset
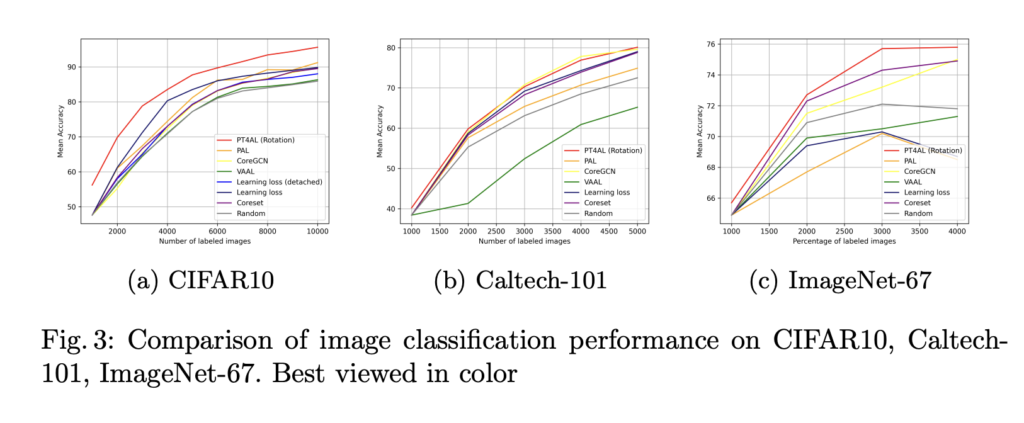
아래 좌측 테이블은 Cityscapes에 대한 Semantic Segmentation 성능을 나타내며, 오른쪽은 Imbalanced 데이터셋에 대한 성능을 나타냅니다. Semantic Segmentation을 위해서는 DeepLab을 백본으로 사용하였고 그 결과 역시 제안하는모델이 제법 큰 차이로 기존 연구들을 앞지르는 결과를 보였습니다.
또한 다음과 같은 CIFAR 분포에서 성능을 확인하였는데요: airplane-500, automobile-1,000, bird-1,500, cat-2,000, deer-2,500, dog-3,000, frog-3,500, horse-4,000, ship-4,500 and truck-5,000. 아래 그래프를 통해 Distribution 기반의 방법론이 이런 불균형에 Uncertainty에 비해 상대적으로 부정적인 영향을 덜 받는 것을 확인할 수 있었을 뿐더러, 제안하는 방법론은 그 두마리 토끼를 잡을 수 있었음을 다시 한번 알려주었다고 합니다.
Cold Start Problem in Active Learning
마지막으로 전체 데이터 중 랜덤한 라벨 데이터를 골라 학습을 시작하여 성능이 랜덤보다 저하되기도 하는 AL의 고질적인 문제인 Cold start 문제를 다뤘는데요. 저자는 제안하는 PT4AL이 이 Cold start를 해결하는 방법론임을 주장하였습니다. 이를 위해 첫번째 사이클에 대하여 여러번 실험을 돌려본 결과를 아래 테이블에서 확인하였습니다. 그 결과 PT4AL을 사용한 결과가 표준편차도 Random에 비해 훨씬 작으면서 평균 정확도 역시 8% 가량이나 높은 것으로 훨씬 안정적인 초기 선택 방법임을 알 수 있었습니다.

Conclusion
저자는 PT4AL을 제안하여 pretext task를 AL에 적용하여 Uncertainty, Distribution을 극복한 방법론을 제안하였습니다. 그와 동시에 Cold start 문제를 해결할 수 있는 대안으로서 역할을 함을 확인하였습니다.
간단한 아이디어도 SSL과 AL을 동시에 사용한 방법론인데, 두 방법론이 완전히 독립적으로 존재한다는 것이 조금 아쉬웠습니다. 그리고 Ablation study에 LC 말고 다른 Sampler 를 적용했을 때 성능이 궁금해지기도 하네요. 이상 리뷰 마치겠습니다.
좋은 리뷰 감사합니다.
AL과 SSL에 대해 세세하게 설명해주셔서 이해가 잘 됩니다.
한가지 궁금한 것이 있습니다.
pretext loss가 높은것 부터 학습하여 초반에는 Uncertainty 기반으로, 후반으로 갈수록 대표성을 나타내는 샘플을 학습하는 Distribution에 집중하는 것이라 하셨는데, 거꾸로 초반에 Distribution에 집중하고 후반에 Uncertianty 기반으로 학습하는 실험이 있는 지 궁금합니다. 사람으로 치면 심화문제를 먼저 학습하는 것 보다 개념문제를 익히고 심화를 해야하지 않을까 하는 생각이 들어서, 내림차순이 아닌 오름차순으로 정렬하여 사용할 경우 어떤 결과가 나올 지 궁금합니다.
좋은 댓글 감사합니다.
저도 읽으면서 그 부분이 궁금해지더군요. 아니나다를까 저자 역시 같은 고민을 하였는지 실험 결과를 리포팅하였는데요. 논문에 따르면 내림차순을 하는 것이 더 좋은 성능을 보여 해당 방법을 채택하였다고 합니다.
안녕하세요 좋은리뷰 감사합니다.
혹시 어떤 pretext task 든 간에 상관없이 적용할 수 있다고 하셨는데 그럼 다른 pretext task 를 적용한 실험도 있는지 궁금합니다.
좋은 질문 감사합니다.
Ablation study에 해당 실험을 다뤘는데, 제가 빠뜨렸네요!
우선 저자는 pretext task로서 (1) rotation prediction (2) colorization (3) solving jigsaw puzzles (4) SimSiam 을 적용하여 결과를 분석하였습니다. Classification에서 rotation 이 가장 좋은 성능을, Segmentation 에서는 colorization이 좋은 성능을 보였다고 합니다.