이번에 소개할 논문은 CVPR2021에 게제된 SagNet이라는 방법론입니다. 해당 논문의 분야는 Domain Adaptation 분야로 간략하게 컨셉을 요약하면 Style에 강인한 네트워크를 학습시켜서 domain shift로 인해 발생하는 성능 드랍을 개선시켜 보겠다는 논문입니다.
Intro
CNN 모델은 좋은 성능을 보여주지만, 한번도 보지 못한 데이터 셋에 대해서 평가를 할 때는 그 성능이 제법 크게 하락합니다. 하지만 인간은 한번도 보지 못한 영상일지라도 의미론적인 부분이 유사한 것을 잘 캐치할 수 있죠. 한 예시로 어린 아이에게 고양이가 그려진 그림을 보여주고 실제 고양이 사진을 보여주면 이 아이는 비록 그림으로 고양이를 보고 배웠더라도 실제 사진에서 역시 고양이임을 충분히 인지할 수 있습니다. 하지만 CNN은 사람만큼 강인하게 동작하지 못하죠.
이에 대한 원인으로 여러가지가 있겠지만, 특정 진영에서는 CNN의 inductive bias가 사람의 시각 인지 체계랑 다르게 동작하기 때문이라고 주장합니다. 즉 사람은 물체를 인식할 때 그 대상의 shape을 보는 등 content에 더 집중하지만, CNN은 texture와 같이 style에 더 강하게 집중한다는 것이죠.
이러한 원인이 domain shift가 발생했을 경우 성능이 감소한다고 판단하였으며 저자는 CNN 모델이 최대한 style이 아닌 content에 더 집중할 수 있도록 하는 새로운 방법론을 제안하고자 합니다. 즉 CNN가 Style-biased learning이 아닌 Content-biased learning을 할 수 있도록 하기 위해 새로운 학습 방법을 제안하는 것이 이 논문의 핵심 contribution 입니다.
Method
먼저 해당 논문의 overall framework은 다음과 같습니다.
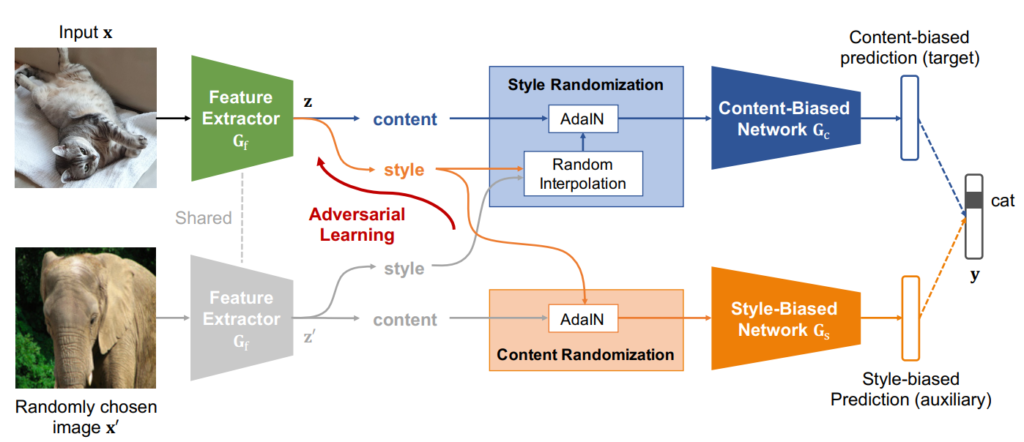
보시면 크게 3가지의 네트워크로 구성되어 있으며, 이는 각각 Feature extractor, Content-Biased Network, Style-Biased Network입니다. 편의를 위해 각각을 FE, CBN, SBN으로 줄여서 부르도록 하겠습니다.
그럼 CBN의 경우 어떠한 스타일을 randomizing함으로써 영상 컨텐츠를 더 명확하게 하는 방향으로 학습하며 반대로 SBN의 경우 컨텐츠를 randomizing함으로써 style에 편향되도록 학습을 수행하게 됩니다. 다만 SBN의 경우에는 결국 Adversarial Learning을 통해 해당 논문의 최종 목표인 FE가 style-biase 되지 않도록 학습이 되는 것이죠.
Content-Biased Learning
그럼 조금 더 자세하게 얘기를 나눠보도록 하겠습니다. Content-Biased Learning에서는 네트워크가 컨텐츠에 편향되도록 학습하기 위해 Style Randomization Module 즉 SR Module이라는 것을 활용합니다.
이 SR 모듈은 학습 단계 동안 각 클래스 카테고리에 상관없이 서로 다른 영상들 사이에 특징 분포를 보간함으로써 스타일을 랜덤하게 변화시킵니다. 결과적으로, CBN은 스타일이 매번 변경이 되기 때문에 올바른 예측을 수행하기 위해서 컨텐츠에 더 편향된 방식으로 학습을 진행하게 됩니다.
자 그러면 위에 내용을 수식과 함께 풀어서 얘기해보죠. 학습 과정에서 제공된 입력 영상을 x 그리고 랜덤하게 선택된 또 다른 입력 영상을 x' 라고 합시다. 그러면 이제 Feature Extractor G_{f}를 통해 각각의 입력 영상들은 feature map z, z' 으로 나타낼 수 있습니다. 이제 해당 feature map들에 대하여 아래 수식과 같이 채널 축만이 존재하는 (즉, spatial dimension에 대하여) 평균과 표준편차를 계산하게 됩니다.
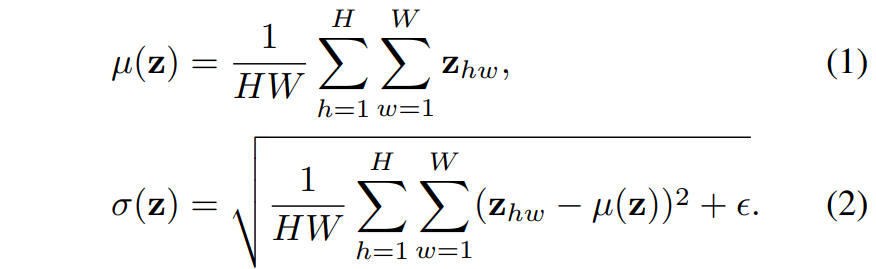
해당 평균과 표준편차 값들은 해당 영상의 Style을 나타내는 정보라고 이해하시면 됩니다.(왜 평균과 표준편차가 영상의 스타일을 나타내는지에 대해서는 Adaptive Instance Normalization에 대한 논문 및 리뷰를 살펴보시면 좋을 듯 합니다.)
아무튼 이렇게 스타일에 대한 정보를 추출했으면 아래 수식과 같이 Style 보간 및 Adaptive Instance Normalization 과정을 순차적으로 수행해줍니다.
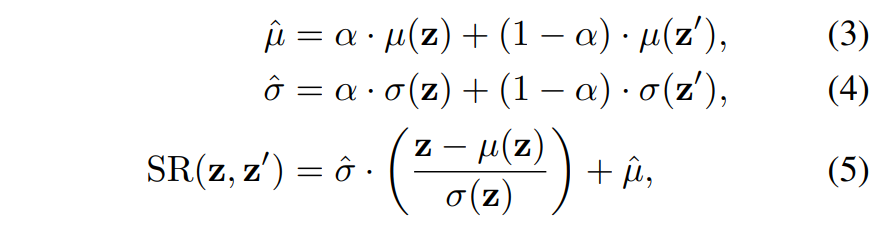
즉 스타일을 랜덤화하기 위해서스타일을 나타내는 평균과 표준편차를 각각 z와 z’에 대하여 알파만큼의 값 비율로 섞어서 새로운 평균과 표준편차를 생성한 후 새롭게 생성된 평균과 표준편차로 AdaIn을 수행해주는 모습입니다.
이렇게 SR 모듈까지 잘 처리되었다면 다음은 CBN을 잘 학습시키는 과정만이 존재합니다. 즉 SR 모듈을 통해 Style이 변경된 feature를 CBN의 입력으로 활용하여 Classification을 수행하는 것이지요.
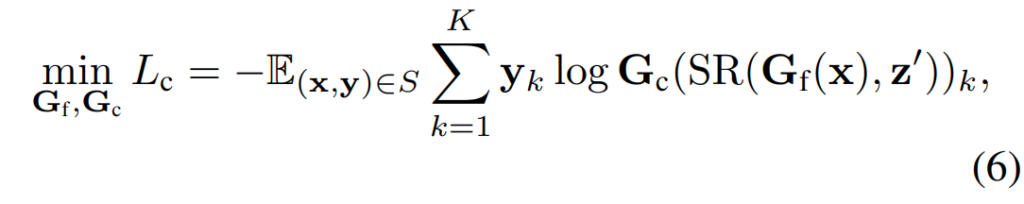
여기서 S는 학습 데이터 셋, k는 클래스의 개수, y는 one-hot label을 의미합니다. 결과적으로 CBN은 매번 style이 변경되는 feature map을 통해 classification task를 수행함으로써 style보다는 content에 더 편향된 방향으로 모델을 학습하게 됩니다.
Adversarial Style-Biased Learning
다음은 SBN에 대한 내용입니다. 저자는 FE가 추출한 feature map 역시 style에 대한 정보를 최대한 배제하도록 하고자 하였습니다. 즉 SBN과 adversarial loss를 통해 style 편향된 표현을 feature extractor가 학습하지 못하게 하는 것이죠.
위에서 CBN이 학습을 위해 SR 모듈을 활용한 것과 반대로 SBN은 Content Randomization, 즉 CR 모듈을 활용합니다. 이 CR 모듈은 style을 유지시키고, 컨텐츠를 변경하는 것이 핵심이며, 그림1에서 볼 수 있듯이, 단순히 Adaptive Instance Normalization을 적용하는 것 뿐입니다.
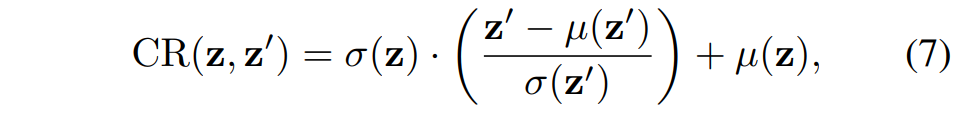
보시면 원래의 입력 영상 x의 feautre map z의 스타일을 무작위로 선택된 x’의 feature map z’의 content map에 적용한 것을 확인할 수 있습니다. 이렇게 z의 style이 녹아든 feature map은 SBN의 입력으로 들어가 분류 문제를 푸는 방식으로 학습이 될 것이며 이때 SBN은 매번 컨텐츠는 변경되지만 Style이 일정하기 때문에 Style을 기준으로 분류를 학습하도록 하는 style-bias 방식으로 학습이 진행됩니다.
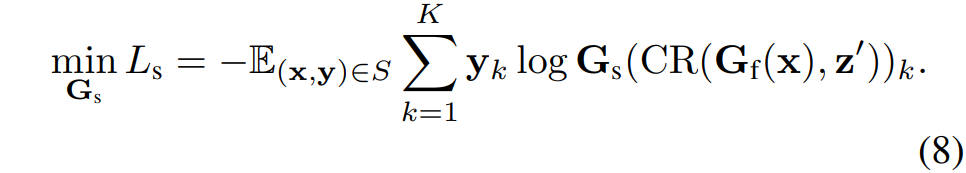
결과적으로 위에서도 한번 얘기했다시피, feature extractor가 style에 편향되지 않도록 학습을 수행하기 위하여 FE가 SBN을 속이도록 학습이 진행되어야만 합니다. 이는 아래 수식과 같이 style-biased prediction과 uniform distribution 사이에 Cross Entropy loss를 계산하는 것을 통하여 adversarial loss를 정의할 수 있다고 합니다.
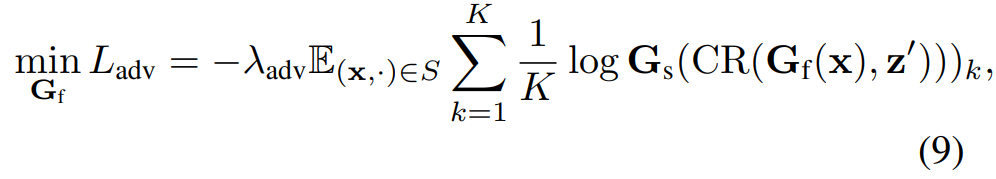
사실 위에 수식 9번은 한번에 이해하기가 어렵네요. 저자는 style-biased prediction과 uniform distribution 사이에 CE loss 계산이 결국 Style-biased prediction의 CE loss를 maximizing하는 것과 동일하다고 하는데, 왜 그런 것인지에 대해서 아직은 잘 모르겠습니다. 다만 의도는 결국 feature extractor가 추출한 feature map에서의 style이 영상의 style을 잘 표현하지 못하기에, SBN의 CE loss 값 역시 커지도록 하는 방향으로 학습하기를 원한다는 것 같네요.
Experiments
논문에서는 Domain Generalization, Unsupervised Domain Adaptation, Semi-Supervised Domain Adaptation 등 다양한 분야에 대하여 실험을 진행하였습니다. 해당 리뷰에서는 SagNet의 효과에 대한 실험과 DG 분야에 대한 결과만을 리포팅하고 리뷰 마무리 짓도록 하겠습니다.
저자는 먼저 SagNet이 성공적으로 CNN의 inductive bias와 domain discrepancy에 대하여 효과를 보이는 지를 실험하기 위해 16-class-ImageNet과 texture-shape cue conflict stimuli 데이터 셋으로 실험을 진행합니다.
texture-shape cue conflict stimuli 데이터 셋은 아래 그림과 같이 생겼는데, 쉽게 말하면 영상 위에 적힌 단어는 영상의 content를, 영상 아래에 단어는 영상의 style을 의미하는 영상이다 라고 이해하시면 될 것 같습니다.

먼저 아래 그림-(a) 결과를 살펴보시면, 베이스라인인 Resnet-18은 texture에 대한 정확도가 55%에 달하는 반면 Shape에 대한 정확도는 20%정도를 보여주고 있습니다. 이는 기존의 CNN은 shape보다는 texture를 중점적으로 보고 있었다는 것을 의미하게 됩니다.
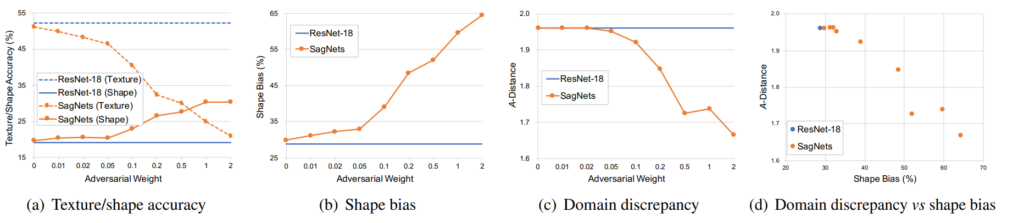
반면에 SagNet의 경우 Adversarial loss의 weight을 점차 높임에 따라서 texture에 대한 정확도는 점차 떨어지는 반면 shape이 무엇인지를 예측하는 정확도는 점차 증가하는 것을 확인하실 수 있습니다. 이는 저자가 의도한 대로 SBN 모델의 adversarial loss 방식이 feature extractor가 style보다는 content에 더 편향되도록 학습을 진행시킨다는 것을 증명합니다.
이러한 경향성은 (b) 그래프에서 역시 adversarial weight을 점차 키움에 따라서 sagnet의 shape bias가 점차 커지는 것을 확인하실 수 있습니다. 참고로 shape bias는 texture 또는 shape에 대해 정답을 맞춘 결과 중에서 shape을 맞춘 결과의 비율을 나타낸 것이라고 합니다.
또한 그림3-(c)의 경우에는 SagNet이 얼마나 Domain Gap을 잘 줄였는지에 대한 실험을 보이고 있습니다. 16-class-ImageNet과 cue conflict stimuli dataset은 서로 상이한 데이터 셋이지만 class 카테고리는 동일한 데이터 입니다. 따라서 이 두 도메인에 대한 영상들에 대해 feature map을 뽑은 후 거리를 계산하는 방식으로 domain discrepancy를 얼만큼 줄였는지를 계산합니다.
domain discrepancy를 계산하는 방식으로는 A-distance 라는 계산 방식을 활용하였는데 이는 2(1- epsilon)으로 이 epsilon은 서로 다른 두 도메인의 예제들을 구분하도록 훈련한 SVM classifier의 generalization error를 의미합니다.
결과적으로 기존의 baseline인 resnet18과 달리 SagNet으로 학습시킨 resnet18은 A-distance가 점차 감소하는 것을 통해 domain의 차이를 줄이는 역할을 수행하고 있다고 주장합니다.
Domain Generalization
다음은 Domain Generalization 쪽 실험 결과입니다. DG 분야는 쉽게 말해서 학습 때 단일 또는 다중 source domain으로 학습한 다음 평가 때는 한번도 보지 못한 target domain에서 진행합니다. 실험에 사용한 데이터 셋은 PACS와 Office-Home이라는 데이터 셋으로 각각 4개의 도메인에 대하여 7개와 65개의 카테고리를 예측할 수 있는 데이터 셋 입니다.
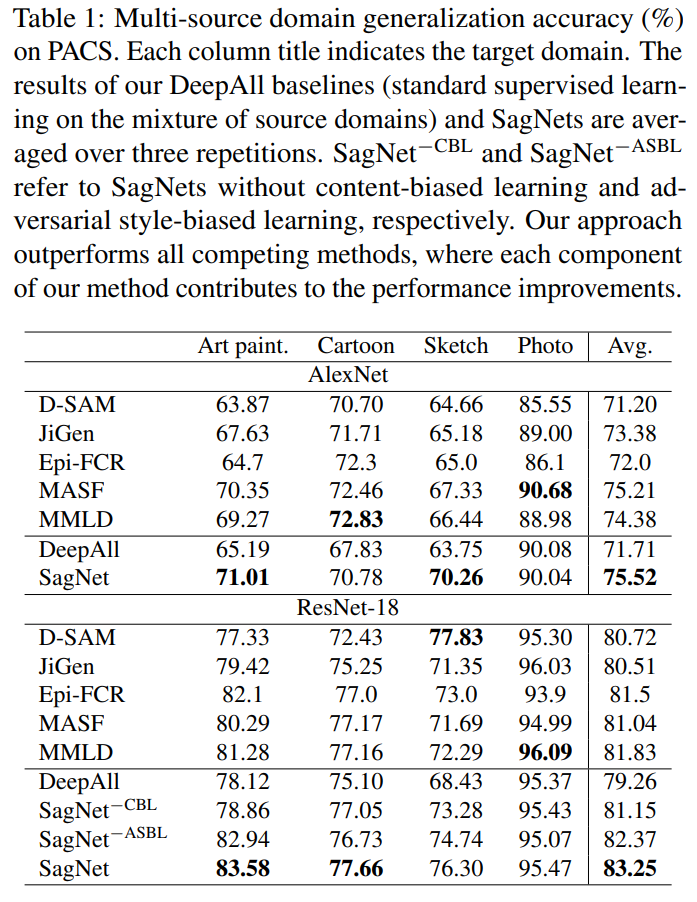
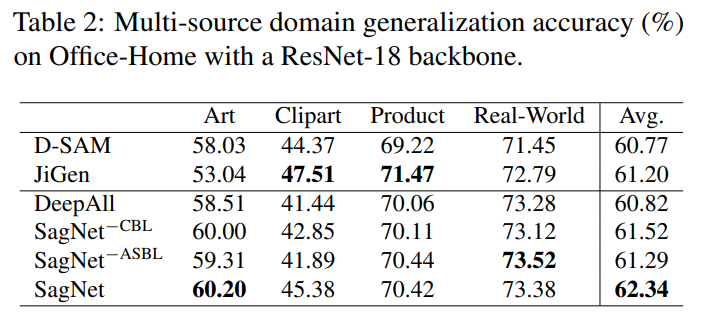
제안하는 SagNet은 PACS에서 4개의 도메인 중 평균적으로 가장 좋은 성능을 달성하게 됩니다.
결론
해당 방법론은 컨셉이 매우 직관적이어서 논문을 이해하는데는 크게 어려움이 없었던 것 같습니다.
논문의 컨셉 자체는 설명해주신 것 처럼 간단해서 이해가 쉬운 편인 것 같은데요. [그림 2]에서 아무리 생각해도 Content와 Style을 의미하는 단어가 잘 매칭이 되지 않네요. texture-shape cue conflict stimuli 데이터셋이 의도적으로 Style과 Content를 변형시킨 데이터셋이고 이를 통해서 Content 부분의 정확도와 Style 부분의 정확도를 평가하기 위함인건가요? [그림 3]의 실험은 이 데이터셋만으로 평가한 결과인지도 궁금합니다.
texture-shape cue conflict stimuli 데이터 셋은 style transfer 기법들을 활용해 영상의 content와 style을다르게 설정한 영상을 의미합니다.
예를 들면, 영상의 상단에 cat, 하단에 elephant가 적혀있으면 이는 고양이의 컨텐츠 영상에 코끼리 영상에서 가져온 style을 입힌 것으로 보시면 됩니다.
저도 해당 데이터 셋을 처음 접해봐서 자세히는 모르지만, 해당 데이터 셋은 영상의 content와 style label이 각각 들어있기에, 모델이 해당 영상을 보고 content label을 예측하는지 혹은 style label을 예측하는지 등을 통해 모델이 어느쪽으로 bias 됐는지를 판단하는 것 같습니다.
그리고 그림3의 실험은 texture-shape cue ~~ dataset과 추가로 16-class-ImageNet으로 실험을 진행하였습니다.
리뷰 잘 봤습니다.
문제 정의가 정말 참신하고 새롭다고 생각이 드네요.
뭔가 CNN의 근본(?) 을 정확하게 이해하고 있지 못해서 드리는 질문일 수도 있는데요, 이때까지 제가 접한 논문들은 제 기억에 의하면 도메인이 서로 다른 image가 input으로 들어 올 경우 feature를 뽑아내는 encoder가 서로 다른 parameter를 가집니다. 그런데 본 논문에서는 shared 하는 구조를 가지는데, domain이 서로 다르면 각각의 feature를 뽑아내는 parameter가 서로 달라야 한다고 생각이 드는데.. 이 부분에 대해서 답변 가능 하신가요??
감사합니다.
그건 무엇을 의도하느냐에 따라서 달라질 것 같습니다.
만약 각 도메인에 specific한 성질을 추출하고 싶다면, 권석준 연구원이 말한대로 각각 독립적인 인코더를 활용을 해야하겠지요. 반대로 두 도메인에서 모두 잘 동작하는 인코더를 학습하고 싶다면 weight shared encoder를 활용할 수도 있겠구요.
해당 논문에서는 결국 도메인에 강건한 특징은 texture와 같은 style이 아닌, shape과 같은 content 요소들이라고 생각하였기에 어떠한 도메인의 영상이 들어온다 하더라도 content에 편향되도록 학습을 시키기 위해 하나의 네트워크로 구현된 것입니다.