
Cross-modality fusion transformer
안녕하세요. 두 번째 X-Review 글입니다. 이번 논문은 IPIU 2023을 준비하며 읽은 논문으로, 이전 세미나를 준비하며 Attention is all you need와 An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale 를 읽어 NLP와 Vision에서 Transformer에 대한 개념을 다잡았는데, 이번에는 Multispectral object detection에서 Transformer의 Self-Attention을 적용한 논문을 읽게 되었습니다. 사실 해당 논문의 방법론이 현재 작성하는 IPIU의 토대가 되는 논문입니다.
0. Abstract
본 논문의 Abstract에서 먼저 짚고 넘어갈 내용이 있어 꺼내게 되었습니다. 지금은 당연한 말이지만 저자는 Object detection에서 Multispectral 이미지를 사용하는 것의 장점을 말하며, 두 브랜치로 이어지는 다른 Modality를 충분히 활용하고자 cross-modality fusion transformer (이하 CFT) 를 제안합니다. 그렇다면 저자는 왜 Transformer 기반의 방법론을 제안할까요? 이 부분이 Abstract에서 짚고 넘어가고자 하는 핵심 내용입니다. 먼저 CNN과 Transformer 의 long-range dependencies 를 알아야겠네요. 이 부분은 어쩌면 NLP의 내용을 토대로 이해하는 것이 좋을 것 같습니다. 아래의 그림을 보겠습니다.
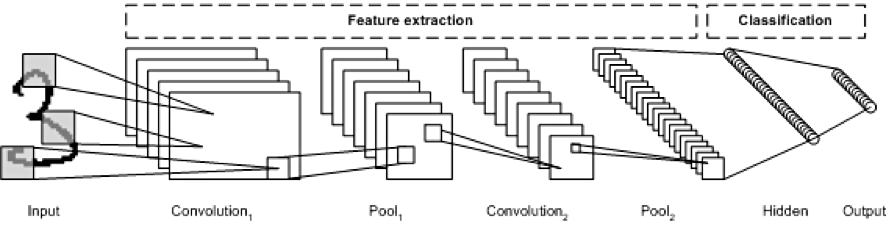
너무나도 유명한 그림입니다. CNN은 Feature extraction 단계에서 고정된 사이즈의 커널을 사용합니다. 그림의 첫 번째 Convolution을 통과했을 때를 보겠습니다. 고정된 크기의 커널을 사용하기에 현재 Receptive field는 한정적입니다. Feature map의 한 부분에서 입력 이미지의 전체를 보지 못하고 부분 부분만 보게 됩니다. 당연히 CNN의 기본적인 원리이며 Receptive field를 넓게 하고자 Convolution 층을 쌓아 가며 이미지 전체의 정보를 고려할 수 있게 합니다. 이를 위해 층을 꽤나 깊게 쌓아야 하고, 처음 단계의 Convolution에서는 3의 윗 부분과 아랫 부분, 즉 영상 내 거리가 먼 곳의 정보와 연관성을 고려하기에는 힘듭니다. SSD 모델의 전체를 설명할 필요는 없으리라 생각하며 구조만 들고 와서 다시 한번 보겠습니다.

CNN 기반의 SSD에서 Conv4_3에서는 영상 전체를 볼 수 있을 만큼 Receptive field가 넓을까요? 그렇지 않습니다. 정확히 계산은 해봐야겠지만, Conv10 ~ 정도는 되어야 영상 전체의 정보를 보고 거리가 먼 곳의 정보를 통합할 수 있겠네요. 이러한 문제를 장거리 의존성, long-range dependencies 문제라고 합니다. Transformer는 long-ragne dependency 문제를 극복할 수 있습니다! 이 이유에 대해서는 이미지를 패치 별로 나누어 토큰화 한 다음 Self -attention을 적용하여 영상 전체의 연관성을 볼 수 있기 때문입니다. 따라서 해당 논문에서는 Multispectral 이미지에서 Transformer 기반의 알고리즘을 제안하였고, 이 부분이 논문의 가장 큰 Contribution이라고 할 수 있습니다. 물론 이에 관련된 연구가 없었던 것은 아니지만, Multispectral object detection 연구에서 이러한 시도는 이루어지지 않았다고 하네요.
1. Introduction
아마 RCV 여러분들이라면 Multispectral 영상을 활용하는 것이 단일 영상 대비 환경에 강인하다는 등의 이점이 있다는 것을 아실텐데요, 저자도 역시 같은 말을 합니다. 특히 비, 안개, 겹쳐진 상황, 빛이 적은 상황, 낮은 해상도에서 RGB 영상 만을 사용하는 것의 단점을 말하며 시작합니다. 하지만 위에서 언급했듯이, CNN 기반의 Detection 방법의 단점을 언급합니다. 이전에 mutlispectral dataset으로 FLIR, LLVIP, VEDAI 등으로 실험했다고 하는데, 이 점은 뒤에서 다시 짚고 넘어가겠습니다. CNN의 단점을 언급하며 결국 어떻게 다른 모달리티를 사용하는 것의 이점과 표현력을 충분히 통합할 것인지에 대해 고민합니다. 그러기 위해서는 cross-modality fusion mechanism이 어떻게 고안될 것인지 고민하고 있습니다. 이전의 multi-modal mechanism은 모두 CNN 기반으로, CNN은 global receptive field를 가질 수 없는 long-ragne dependencies의 문제로 인해 지역적인 정보만 통합하여 사용할 수 있습니다. 따라서 long-range dependencies를 학습하고자 Transformer에서 self-attention이 소개되었고, 이를 multi-modal에서 가져와서 사용한 연구가 바로 본 논문에서 제안하는 CFT 모델 입니다. self-attention에서는 왜 long-range dependencies를 학습할 수 있는지는 위에서 언급했으니 지금은 넘어가겠습니다. multispectral object detection에서의 transformer를 적용시킨 사례는 처음이라고 하네요..
2. Related work
Fusion에 대해 설명합니다. 모델에서 결국 fusion 개념이 들어가니, fusion에 대해 저자는 고찰하고 있습니다. 이를 두 레벨인 Macro level과 Micro level로 분리지어 어떤 퓨전을 적용할 것인지를 찾습니다. 먼저 Macro level에서는 fusion하는 위치에 대해 마합니다. Early fusion, late fusion등을 언급하다… 네, 알고 있듯이 Halfway fusion의 성능이 제일 좋다고 하네요. Micro level에서는 fusion 하는 방식에 대해 말합니다. 두 modality에서 나온 feature map을 fusion 시 element-wise-addition을 할 수도, average/maximum, wise cross product를 할 수도 있습니다. 또한 다른 방법들도 있지만, 저자는 transformer 방식의 퓨전이 multi-modal의 모달 내와 모달 간의 정보를 모두 고려할 수 있는 방식이기 때문에 최근 인기가 있다고 설명합니다.
3. Methodology
모델의 백본 네트워크로는 YOLO v5를 채택했으며 이는 multispectral object detection이 가능하며 당시 좋은 성능을 보이고 있기 때문이라고 합니다. 퓨전 시 GFD-SSD의 퓨전 방식과 같이 CFT라는 게이트를 통과한 다음 다시 원래의 modal로 돌아가는 방식을 사용하는데, 아래에서 다시 살펴보겠습니다. 아래는 모델의 구조입니다.
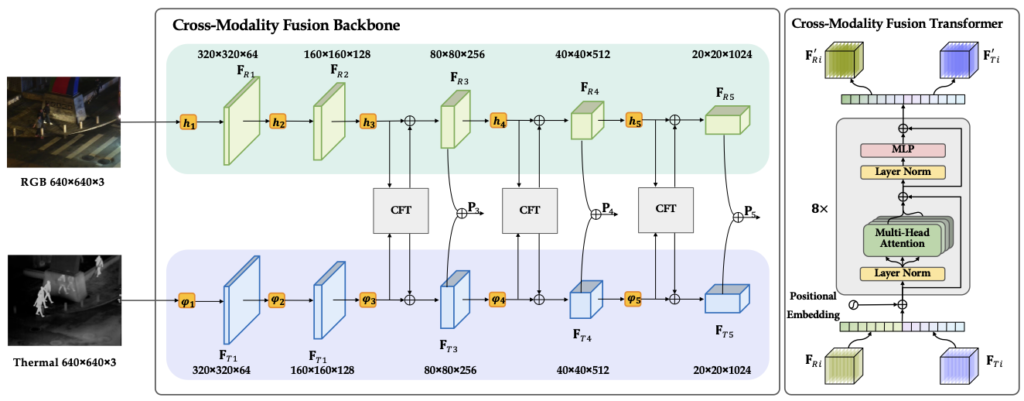
결국 모델의 CFT 게이트에서 일어나는 일만 확인하면 됩니다. H \times C \times W 의 RGB Feature map과 Thermal Feature map을 flatten하여 HW \times C 로 만든 다음 채널 축으로 합칩니다. 그렇다면 2HW \times C 차원이 될 것이고, 이를 특정 차원으로 임베딩 한 다음 Positional encoding을 거칩니다. embedding과 positional encoding은 transformer에서 등장하는 개념으로, 특정 차원으로 표현력을 압축하고 위치 정보를 살리기 위한 장치라고 보시면 됩니다. 이후는 이제… Transformer에 나오는 Multi-Head Self Attention을 거칩니다. 이후 다시 원래의 정보를 더해주고 MLP를 거치는 과정을 8번 거치는데, 정확히 원 논문의 방법을 그대로 사용합니다. 코드도 공개되어 있으니, 참고해보시면 될듯합니다. 정말 신기한건,, 해당 부분을 코드 공개 시 직접 구현하거나 self-attention을 구현하여 사용했을 법도 한데, torch의 multihead attention을 그대로 사용했습니다..ㅎㅎ. 아래의 수식들은 결국 Transformer 블록을 설명하는 수식과 동일한데, 살펴만 보겠습니다.

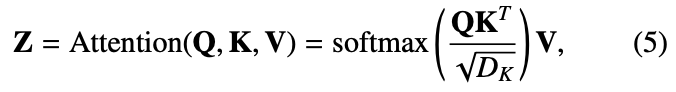
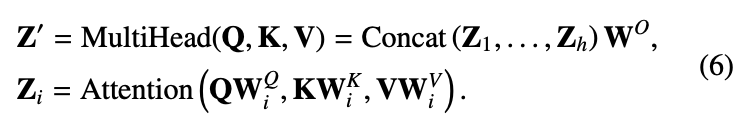
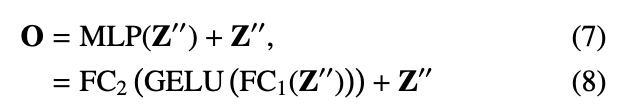
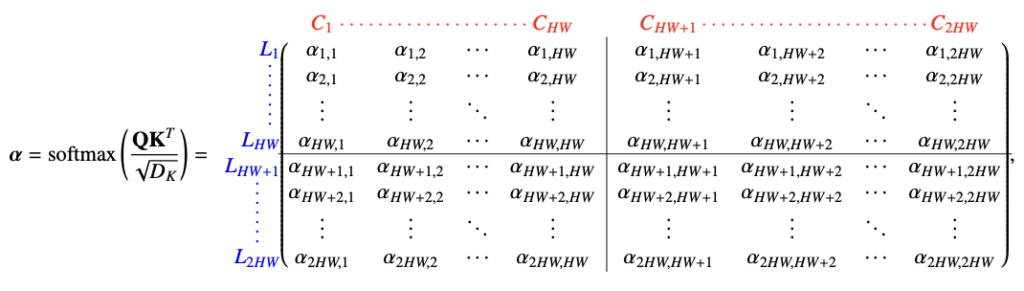
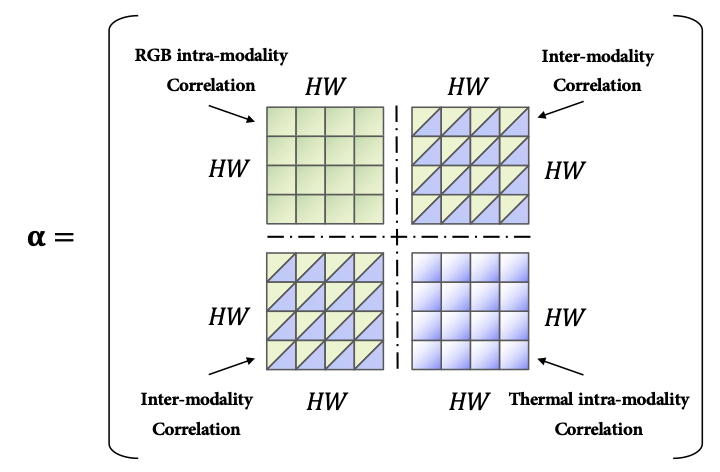
네.. 수식 모두 Transformer 기본 수식과 다를께 없습니다. 코드를 보니 GELU 말고 SiLU로도 activation function을 바꿔가며 실험을 해본 모양인데, 성능 개선은 없었는 것 같습니다. 실험 단계에서는 결국 임베딩으로 들어가는 shape이 위에서 설명했듯이 2HW 이기 때문에 쿼리와 키를 곱할 때는 4(HW)^2 이 됩니다. 따라서 이는 메모리 상 문제가 될 수 있어, 저자는 입력 이미지 사이즈를 다운샘플링 하여 사용했습니다. 이러한 디테일 외에도 GAP을 사용하여 Feature map의 사이즈를 조절하는 등, Transformer 블록을 8번이나 반복하다보니 computation complexity나 memory limit 으로 인해 그러한 방법을 채택했다고 합니다. 결국 Transformer self-attention은 이미지 내 long-range dependencies을 고려할 수 있고, 이미지를 패치로 쪼개어 모든 패치 간의 연관성을 살펴보다 보니 영상 내 정보를 모두 통합할 수 있습니다. 이러한 self-attention의 입력으로 두 모달리티의 feature map을 채널 축으로 합친 fused feature map을 넣었으니… 모달 간 그리고 모달 내 연관성을 살펴볼 수 있다는 컨셉입니다. 비록 퓨전된 feature map을 넣었으니 그 한계점이 보이긴 하지만,, 성능 향상을 이루었다고 하네요. 이를 Intra-modality correlation (모달 내 연관성), Inter-modality correlation (모달 간 연관성)을 표현한 다음의 그림을 보면 알 수 있습니다.
4. Experiment
위에서 언급했듯이 FLIR, LLVIP, VEDAI dataset을 활용하여 실험합니다. FLIR은 multispectral object detection에 유명한 데이터셋으로, 원본 데이터셋이 RGB-Thermal 간 align이 맞지 않아 이를 수정한 버전으로 실험했다고 하네요. LLVIP는 pedestrian dataset으로, 낮은 빛에서 촬영한 데이터셋입니다. VEDAI 은.. vehicle detection을 위해 고안된 데이터셋입니다. YOLO v5를 백본으로 사용하고 있으므로 Loss function 또한 YOLO의 Loss와 동일합니다. 아래 수식으로 보고 넘어만 가겠습니다. 논문 읽으며 느낀 점인데,, YOLO의 Loss를 그대로 들고 오는 개념이지만 YOLO에서만큼 자세히 설명해주네요. 심지어 4.3.의 Evaluation Metrics보면 mAP와 AP의 수식까지 모두 적어주는데, 참 친절한 논문이네요. 지향하고 IPIU 작성 시 참고해야겠습니다.
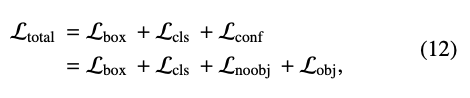
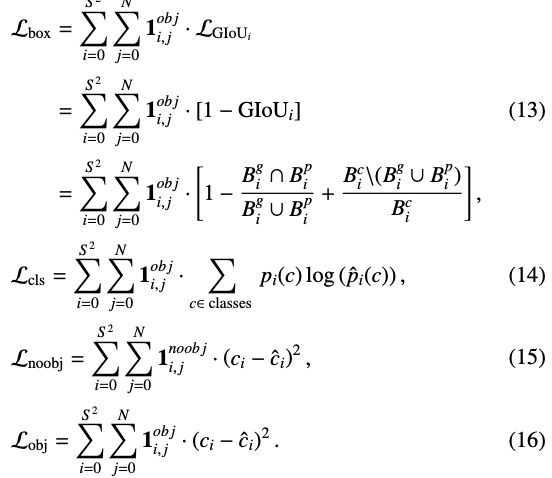
마지막으로 각 실험에 대한 성능 표입니다.
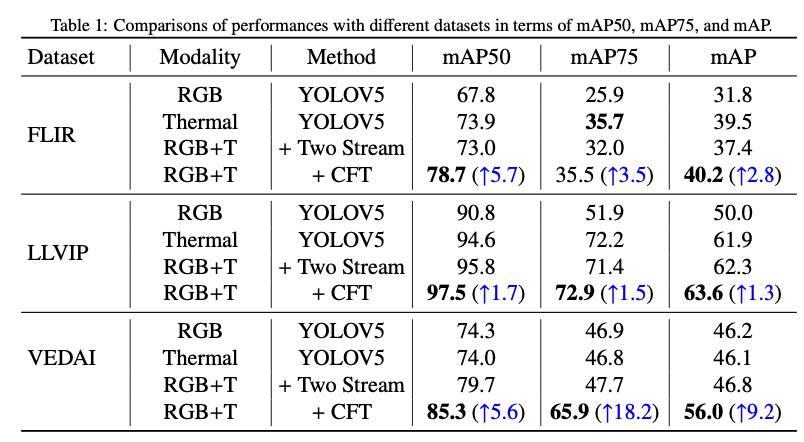
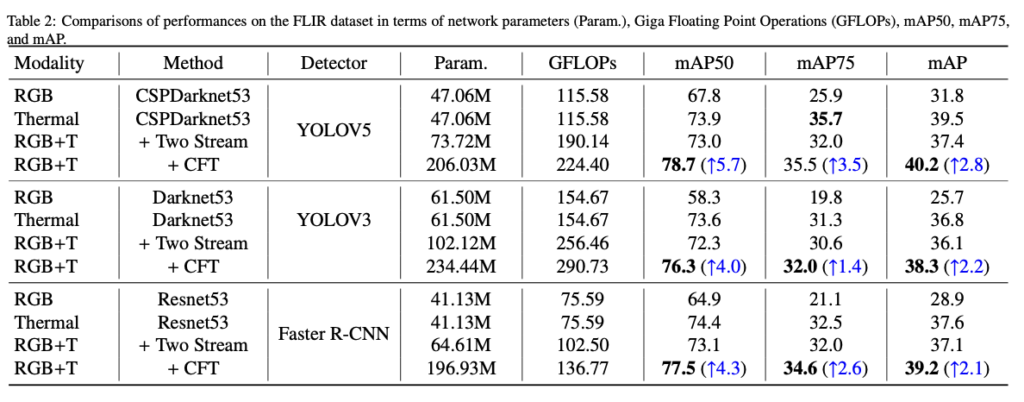
Two stream은 Multispectral image를 사용했을 때의 방식이며 CFT를 적용 시 YOLO v5에서 최대 97.5의 mAP를 보였습니다. 1.7에서 5.7까지, dataset에 따라 성능 증가 폭이 굉장히 큰 모습을 볼 수 있습니다. 심지어 VEDAI dataset에서는 mAP@75에서 18.2%의 향상을 보였네요.. 다음으로 Backbone을 변경하며 실험해 본 실험에서의 결과도 있습니다. YOLO가 아닌 F-RCNN에서 실험해봤으며, 이를 통해 CFT 모듈이 2-stage에서도 좋은 방법이라고 합니다. 하지만 역시! 시각화 자료로 살펴보겠습니다.



첫 번째 열은 RGB, 두번째 열은 Thermal을 뜻하며 첫 번째 행은 GT, 두번 째 행은 단순 Fusion을 Baseline으로, 세 번째 행은 CFT 모듈을 뜻합니다. 결국 위의 세 dataset에서의 CFT가 FP와 FN에서 좋은 성능을 보인다고 말하고 싶어합니다.
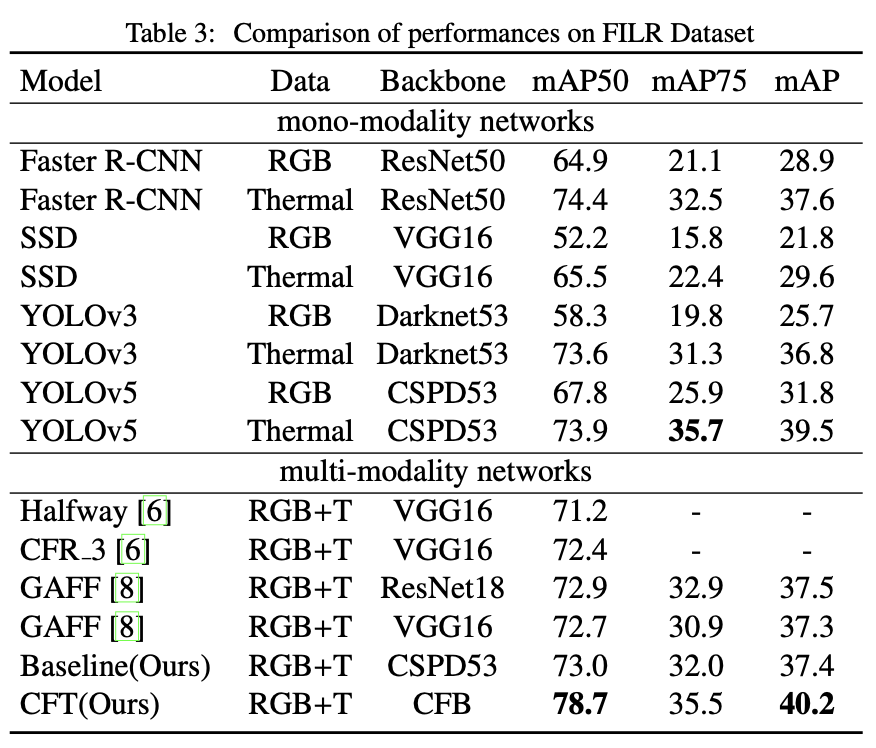
VGG16 Haflway와의 성능 비교가 있길래, 들고 왔습니다. CFT를 장착하니 무려.. 7.5%가 올랐네요? 물론 얘네들이 FPS는 언급안하는데, 사실 Transformer 블록을 8번이나 반복하기 때문에 해당 방법론은 Real-time method라고 보기는 어려울 것 같습니다. 아마 그래서 일부러 mAP 성능만 말하는 것 같습니다. 5. Conclusion에서는 CFT 모델이 Global contextual information을 통합하고 그러므로 multi modality를 사용하는 것의 이점을 극대화할 수 있다고 말합니다. 또한, CNN 기반이 아닌 Transformer 기반으로 long-range dependencies를 학습할 수 있어 기존 문제점을 개선했다고 언급합니다.
CFT의 Fusion 방식을 조금 바꾸어 현재 IPIU에 적용하고 있는데 (형준님의 아이디어 덕분에..) 실제로 꽤나 높은 성능 향상을 보여, Vision Transformer 기반 모델에 조금 더 관심이 생기게 된 논문 같습니다. 이상으로 리뷰를 마치겠습니다! 많은 질문 부탁드립니다.
좋은 리뷰 감사합니다.
Multisperctral Object Detection이긴 하지만 KAIST 데이터셋으로 실험한 결과를 리포팅하지 않은 것은 조금 의아하네요. 혹시 상인님은 무엇때문에 해당 논문이 KAIST에 대해 리포팅하지 않았다고 생각하시나요?
그리고 리뷰 중 3. Methodology 에서 “비록 퓨전된 feature map을 넣었으니 그 한계점이 보이긴 하지만,, 성능 향상을 이루었다고 하네요. ” 에서 한계란 무엇이라고 생각하시나요?
안녕하세요. 좋은 질문 감사합니다.
먼저, KAIST 데이터셋을 사용하지 않은 이유에 대해 따로 리포팅 되어 있지 않았지만, FLLR ADAS dataset이 multispectral object detection dataset이기에, KAIST 데이터셋을 대체하여 사용된 것으로 보입니다. 조금 흥미로운 점이, Yolo v5는 KAIST dataset과 FLIR로 실험한 부분이 모두 리포팅 되어 있는데, 따로 실험하지 않은 부분이 혹시..?하는 마음이 있지만 Datasets 부분을 읽어보면, 정확히는 FLIR dataset이 아닌 원본 dataset이 image pair 사이의 align이 맞춰져 있지 않은 부분이 많아 이를 제외한 버전을 사용했다고 하며 썰을 푸는데… 이런 썰을 더 풀고자 하지 않았을까 하는 생각이 듭니다. 다만 재밌는 점은 그렇다면 본 논문에서 well-aligned한 image pairs를 만들었느냐?하면 또 그런 점은 아닙니다. “Multispectral fusion for object detection with cyclic fuse-and-refine blocks”의 논문에서 이미 새로 정제한 dataset을 가져 오는데, 본 논문에서 이 논문을 언급하며 CFT 게이트를 해당 논문과 다른 하나의 논문에서 아이디어를 얻어왔다!라고 했는데, 그 논문의 실험 결과를 baseline으로 잡고자 하지 않았을까 하는 생각도 듭니다만, 사실 그렇지도 않구요… 마지막 의심이 드는 부분으로, 정제된 FLIR의 dataset 수가 5,142 pair로 상대적으로 적은 축에 속하는데, KAIST dataset으로 실험 시 Transformer 방식을 사용하여 실험 시 너무 오랜 시간이 걸리지 않았을까 하는 생각이 듭니다. 실제로 SSD에서 CFT를 사용하여 학습해보는데,, 정말 오랜 시간과 많은 메모리를 잡아 먹더라구요..ㅎㅎ
두 번째 질문에 대한 답변으로는, 저의 생각으로는 CFT 게이트에 채널 축으로 합친 Feature map을 넣는데, 이에 대해 RGB-Thermal pair 사이의 correlation을 본다라고 되어있지만, 그렇다면 하나의 모달리티에서 self-attention을 한 다음 다시 퓨전하여 self-attention을 진행하는 것이 본 논문의 원 의도에 더 적합하지 않았을까?하는 점이 제 생각이여서 한계점이라고 말했습니다! 다소 주관적이지만, 현 방법으로는 두 모달리티 사이의 연관성을 본다라고 생각할 수도 있지만 그렇다면 self-attention 방식이 아닌 cross-attention 방식이 더 적합했을 것 같았고, 실제로 추후 cross-attention 방식을 사용한 논문이 리포팅 되어 있기 때문입니다ㅎㅎ
리뷰 잘 봤습니다.
3번 method 설명 부분에서 쿼리와 키를 곱하면 4(HW)^ 2 이 되기 때문에 연산량이 너무 많아서 downsampling 을 한다고 하셨는데, 그냥 dimension을 유지 한 채로 transformer block을 8번이 아닌 4번정도 반복하면 안되나요??
그리고 ‘비록 퓨전된 feature map을 넣었으니 그 한계점이 보이긴 하지만’ 이라고 언급 한 부분에서 한계점이란 무엇을 말하는 것인가요??
감사합니다
안녕하세요. 좋은 질문 감사합니다.
먼저 첫 번째 질문에 대해 논문의 내용을 다시 리포팅하여 고찰하자면 하나의 모달리티에서 나온 Feature map을 Flatten하면 HWxC, 두 Feature map을 Concatenate하니 2HWxC이며 따라서 Query와 Key를 곱한, Intermediate matrix의 dimension이 (4HW)^2입니다. 그렇다면 640×640의 input image에 대해 Network를 통한 중간의 Feature map에서 CFT 연산을 하고자한다면 그 때의 Feature map은 160×160 사이즈, 따라서 QK의 연산량은 2.4G를 넘고, “unacceptable”하다고 표현되어 있네요! 이 때 만약 transformer block을 8번이 아닌 4번을 거친다면, 그만큼 표현력은 적어집니다. 원 Transformer 논문인, “Attention is all you need”에서 8번 반복하는 이유가 그만큼 다양한 weight으로 초기화하여 표현력을 늘리고자 하는 본 의도를 살리고자 한 것 같습니다. 실제로는 저도 연산량 및 연산속도로 인해 Transformer block을 두 번만 반복하는 형식으로 코드를 돌리고 있는데도 오랜 시간이 걸리는 것을 감안했는데, 본 논문에서는 그렇게 해서 표현력을 잃어버릴빠에야, downsampling한 뒤 upsampling 해주는 형식이 더 좋지 않을까라는 고찰이 있는 것 같습니다! 그리구 두 번째 질문에 대해서는, 위의 주영님 댓글에 답글을 달았으니 참고하시면 좋을 듯 합니다!
리뷰 잘읽었습니다.
상인님도 논문을 읽으시면서 왜 KAIST에서는 성능 비교를 하지 않았을까? 란 생각과 다른 멀티스펙트럴 검출기와 성능 비교를 수행하지 않았음에 의문을 가졌을 거라고 생각합니다. 왜 그랬을까란 부분에 대해 나중에 같이 이야기를 나눠보았으면 좋겠습니다.
간단한 질문 하나 드리고 가겠습니다.
해당 방법론에서 box regression loss로 GIoU를 사용했습니다. GIoU란 무엇인가요?
안녕하세요. 먼저 좋은 질문 감사합니다!
KAIST 데이터셋에 대해 성능 비교를 하지 않은 점이, 논문을 읽을 때 의아하긴 했지만 FLIR dataset을 사용했으니 본인들은 괜찮다는 식으로 넘어간 것 같은데, 다시끔 질문을 보고서 생각해보니 정말 의아하네요. 아마 Transformer Block을 8번 반복하는 방법으로 인해 실시간 탐지가 불가능한 수준의 FPS가 나왔을 것으로 예상하는데, Detection 논문에서 FPS를 쏙 뺀 것을 보니 확실히 의심스럽습니다.
아! 두번째 질문을 보고 Loss 부분에서 GIoU에 대해 말씀해주셔서 Yolo를 다시 보니 Yolo에서는 GIoU가 아닌 IoU Loss를 사용했더라구요? 이 부분에서 제가 착각이 있었던 것 같아 다시 GIoU에 대해 찾아본 바로 설명드리겠습니다. 먼저 해당 논문에서 GIoU에 대해 언급한 부분을 보자면, IoU가 box regression loss에서 흔히 사용되지만 본 논문에서 비교적 GIoU Loss가 더 좋은 성능을 보였다고 되어있습니다. 그렇다면 GIoU Loss란 무엇일까요? GIoU Loss는 IoU 이후 등장한 Loss로, IoU Loss는 만약 bounding box 간 overlap이 없을 시 동작하지 않는 문제가 있습니다. 아주 쉽게 한국어로 표현하자면 교집합 / 합집합인데, overlap이 없다면 교집합이 0이기 때문입니다! GIoU Loss는 이 점을 어떻게 극복하고자 했을까요? GIoU Loss는 Prediction과 GT를 모두 포함하여 커버칠 수 있는 가장 작은 단위의 박스 C를 이용합니다. 따라서 만약 Prediction과 GT 사이 교집합이 없더라도 Loss를 줄일 수 있게 됩니다. 특히 학습 초반에 만약 overlap이 없다면?의 문제점이 있어 GIoU를 사용하는데, 단순히 설명하다보니 다시 드는 생각으로, Yolo v5에서도 multigrid search를 위해 다양한 feature map에서 추출하는데 정말 overlap이 없는 박스가 생성될까?하는 의문점이 다시 드네요. 다시 GIoU에 대해 살펴보자면 GIoU의 핵심은 non-overlap인 경우 Gradient가 소실될 수 있는데 해당 문제점을 개선할 수 있는 점입니다!
안녕하세요 이상인 연구원님, 좋은 리뷰 감사합니다.
Transformer에 관한 내용을 찾아보다 우연히 해당 리뷰를 읽게 되었습니다. 아직 관련 지식이 얕아 Multispectral feature fusion을 제외한 부분은 이해하기 쉽지 않네요.
제가 리뷰를 읽고 이해한 바로는 다음과 같습니다.
1. CNN model에서는 층이 깊어져야 receptive field가 넓어져 거리가 먼 곳의 정보를 통합할 수 있는 한계가 있습니다. 이를 long-range dependency 문제라고 합니다.
2. Transformer는 이미지를 패치 별로 나누어 토큰화 한 다음 Self-attention을 적용하여 영상 전체의 연관성을 볼 수 있기 대문에 long-range dependency 문제를 극복할 수 있습니다.
3. 본 논문의 Contribution은 Multispectral image에 Transformer 기반의 알고리즘을 적용한 것에 있습니다. Multispectral object detection 연구에서 이러한 시도는 최초였습니다.
4. Backbone으로 YOLO v5를 사용하고 있고, Loss function도 YOLO의 Loss를 그대로 사용합니다. transformer부분도 일체의 수정 없이 기본 transformer의 수식을 그대로 사용합니다. YOLO가 아닌 F-RCNN에서도 실험이 진행되었으며, CFT모듈이 2-stage에서도 좋은 방법인것을 확인할 수 있었습니다.
읽다보니 몇 가지 궁금한 부분이 있어 질문 드립니다.
1. 해당 모델은 기존의 multispectral feature fusion 모델의 feature fusion 부분을 transformer로 대체한 것으로 보입니다. CFT를 거친 fused feature image를 다시 각각 RGB와 thermal image의 featuremap과 합치는 것인가요?
2. 위 논문에서 Loss는 YOLO의 것을 그대로 사용하고, transformer부분은 기본 수식을 변형하지 않고 그대로 사용한 것으로 이해했습니다. 모델이 바뀐만큼 바뀐 task에 맞게 수식을 수정하면 더 좋은 결과를 얻을 수 있지 않을까 하는 궁금증이 듭니다. 이와 같이 기존의 것을 세부적으로 수정(tuning?)하지 않고 단순 mixing하는 논문이 많은가요?
네 안녕하세요. 우선 리뷰 읽어주셔서 감사합니다.
1. long-range dependency 문제는 이해하신 바가 맞으나, 조금 더 설명해보자면 Receptive field 관점 이외에도 CNN 자체적으로 가질 수 밖에 없는 한계라고 보심이 맞습니다. 결국 long-range dependency란 영상 내에서 멀리 떨어진, 예를 들어 (300, 300)이미지에서 (0,0) 지점과 (300, 300) 지점이 어느 정도 연관성이 있느냐를 따지기 위해서는 CNN에서는 300 x 300 커널을 사용해야만 할텐데, 그렇지는 않죠. CNN은 결국 개념 자체가 이미지의 Locality한 부분을 보고서 이미지를 이해하고자 하기 위함이며, 그렇기에 동반될 수 밖에 없는 문제점이기도 합니다. long-range dependency를 해결하는 방법 중 하나로 Transformer 기반의 ViT, 혹은 DETR과 같은 방법론들이 존재합니다. Transformer 기반이라 함이 결국 NLP의 Transformer를 가져오고, Text 내 sequence 간의 어떠한 연관성을 알고자 하는 아이디어에서 등장한 개념이니, 이를 정확히 이해하기 위해서는 NLP에서의 Long-range dependency를 검색해보시면 이해가 더욱 쉬울 것 같습니다. 혹은 Seq2Seq, LSTM 과 같은 방법론을 검색해봐도 쉽겠네요. https://childult-programmer.tistory.com/55 제가 아주 예전에 작성한 글이긴 하지만.. LSTM 레이어라는 부분을 보시면 그래도.. 이해가 되지 않을까 기대합니다.
2. 1과 더불어, Transformer의 개념의 Self-attention이 결국 long-range dependency를 해결할 수 있지 않았나 생각합니다. 옳게 이해한 것으로 보입니다.
3. 본 논문의 Main contribution은 intra-modality correlation과 inter-modality correlatioin을 고려하고자, Fusion Feature map에 ViT를 적용한 것 입니다. 재연님의 이해가 전반적으로 맞습니다. 제가 아는 선에서 최초는 맞지만.. Detection이라는 분야가 아니라면 GMFlow라는 논문도 비슷한 Contribution을 가져간 것으로 알고 있습니다.
4. 네. 그렇기에 사실 Transformer에 대한 설명을 추가했더라면 리뷰가 꽤나 길어졌을 것 같네요.
1. 정확히는, Fusion한 Feature map에 대해 Transformer를 통과합니다. Feature fusion 과정 자체를 Transformer로 대체한 것은 아닙니다. RGB, Thermal 이미지를 각각 임베딩하여 1D로 눌러쓴 이후, 둘을 그대로 Concat하여 2배 길이의 1D Feature를 만들고서 그대로 CFT 모듈에 통과시켜버립니다. CFT를 통과한 이후 다시 더해주는 것은 맞습니다.
2. 음.. 해당 부분에서 바뀐 Task라는 의미를 정확히 이해하지 못했습니다. Yolo 또한 Detection을 위한 하나의 Detector이며, Transformer 방식을 사용한 것은 어떻게 보면 각 모달리티 Feature map을 Enhancement 하는 효과를 불러옵니다. 다음 문장의 단순 Mixing 하는 논문이 많냐는 것은.. 이러한 과정은 어떻게 보면 실험적으로 이뤄진다고 볼 수 있습니다. A와 B를 합쳤을 때, Loss만 봤을 떄 A를 사용하는 것이 좋은지, B를 사용하는 것이 좋은지, 또는 새로운 C를 만들어내는 것이 좋은지는 어떻게보면 실험적으로 알 수 있는 부분이라는 생각이듭니다. 물론 실험에서 기존 논문 혹은 지식을 토대로 어느 정도의 가정을 할 수 는 있지만, 다양한 실험으로 Ablation study를 낸다면 더 좋은 논문이 되지 않을까하는 아쉬움도 남긴 합니다.
질문 2번째의 첫 번째 문장에 대해 다시 설명해주신다면, 이해한 다음 다시 댓글 달도록 하겠습니다. 감사합니다.