안녕하세요. 오늘은 지난 리뷰[WACV-2023] Motion Aware Self-Supervision for Generic Event Boundary Detection의 AS 시간입니다. 지난 리뷰에서 잘 다뤄지지 않았던 부분이 그래서 어떻게 Flow 없이 motion 정보를 활용하는 것에 대한 내용이었는데요. 해당 논문에서 원리를 설명하지는 않아서 이 논문을 읽게 되었습니다.
Introduction
비디오에서 가장 뚜렷한 특징이 뭐가 있을까요? 주로 Motion이 답변으로 제시되는데요. 그래서 비디오를 활용할 때, (특히 action 관련 task)에서는 주로 optical flow를 많이 활용합니다. 문제는 이 optical flow를 계산하기 위해서는 시간도 많이 들고, 기존 모델 말고 다른 모델이 필요하다는 문제점이 항상 제시되어 왔습니다. 이러한 문제점들을 해결하기 위해서 spatio-temporal convolution을 통해서 움직임을 잘 게산해보려는 노력들이 있었는데, 잘 안되었다고 하네요.
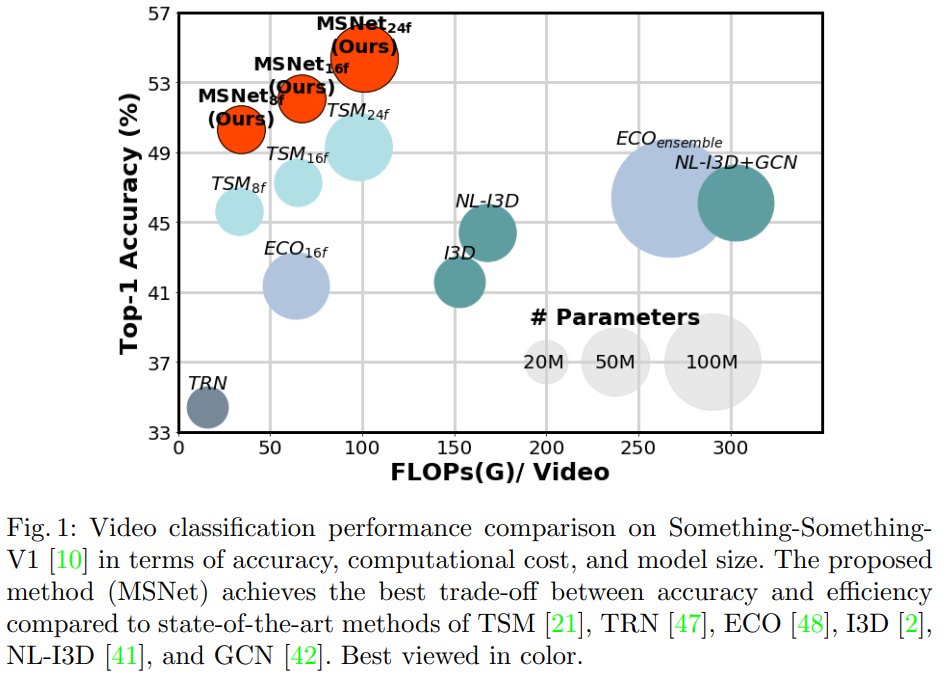
그래서 본 논문에서는 motion estimation이 가능한 E2E 학습 모듈, MotionSqueeze Module(이하 MS 모듈)을 통해서 이 문제를 해결했다고 합니다. 그림 1이 그 성능을 보여주는데요. MSNet은 우리가 알고있는 Resnet 백본에 여기서 제안하는 모듈을 붙인 네트워크인데요. 기존의 flow를 사용하는 모델보다 더 빠른 속도에 더 높은 정확도를 보여주는 것을 확인할 수 있습니다.
Proposed approach
그럼 본격적으로 본 모듈에 대해서 알아봅시다. 일단 기본적으로 비디오에서 움직임을 계산하기 위해서는 앞/뒤 프레임이 필요합니다. 그래서 모델이 T개의 프레임을 가진 비디오를 입력으로 받습니다. 단, MS 모듈이 단일 프레임을 입력으로 받지는 않는다는 점을 기억하고 넘어갑시다.
MotionSqueeze Module
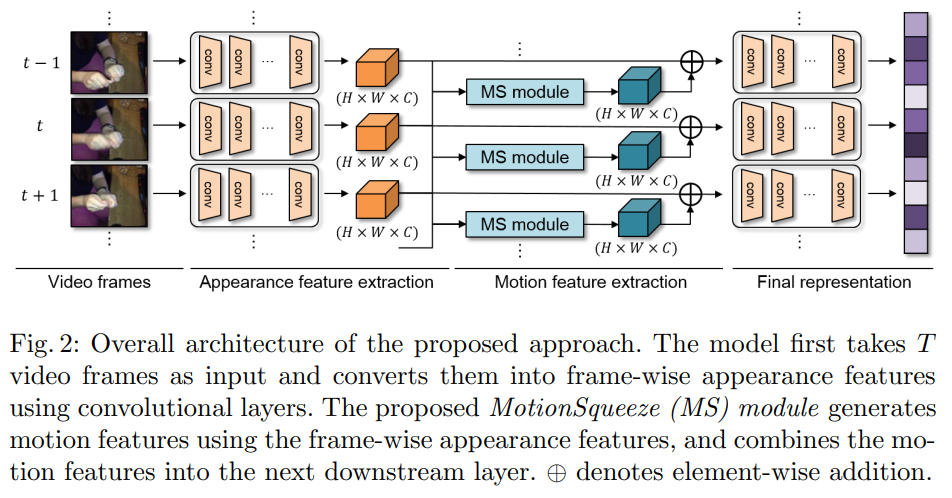
MS module은 motion feature extractor로 정의할 수 있습니다. 그림 2를 보면 대략적인 구조를 확인할 수 있는데요. 기존의 백본의 중간에 이렇게 끼워넣는다 정도로 생각하면 될 것 같습니다. 그럼 이 끼워 넣는 것에서 어떻게 motion 정보를 추출하는가… 그건 3단계(Correlation computation / Displacement estimation / Feature transformation)로 나눠집니다.
Correlation computation
Feature에 대한 notation을 잠깐 짚고 넘어갑시다. t번째 feature를 F^{(t)}라고 할때, 이 단계에서는 F^{(t)}와 F^{(t+1)}를 입력으로 correlation을 계산합니다. 이때 feature의 shape가 H*W*C인데, 여기서 C끼리의 차이를 계산하고, feature에서 C의 위치를 F_x라고 부릅니다.
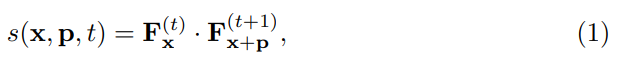
P는 displacement라고 할때 그럼 (1)번 수식을 이해하는데 필요한 notation을 다 알게 되었습니다. 즉, t번째 feature의 특정 위치와 t+1번째 feature의 특정 구역(p의 크기만큼 따져보면 구역이 됩니다)의 행렬곱을 통해서 correlation을 계산하는 것을 알 수 있습니다. 이렇게 설명하면 되게 복잡하게 느껴지실텐데요. 단순하게 보면 p만큼의 크기를 가지는 1×1 convolution 연산이라고도 보면 좋을 것 같습니다. (참고로 p는 15로 설정해서 쓴다고 합니다.)
Displacement estimation
다음 단계는 motion 정보의 변위를 측정하는 단계입니다. 미분 가능하지 않은 방법으로 이 방법을 수행해보면 단순하게 \argmax_p s(x,p,t)와 같이 계산하는 영역에서 correlation이 최대값인 x의 위치를 사용하는 방식이 있습니다. (이 부분은 t와 t+1에서 픽셀 매칭을 했을때 유사도가 제일 높은 픽셀이 움직인 위치라고 볼 수 있다는 부분입니다.) 하지만 학습을 하려면 가중치가 흘러야하는데 미분이 안되면 E2E로 학습시킬 수 없겠죠? 따라서 여기서는 soft-argmax라는 방법을 이용해서, 가중 평균을 사용해서 변위를 추정합니다.
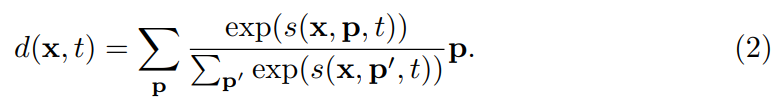
[수식 2]가 바로 이 soft-argmax라는 방법입니다. Softmax를 모르시는 연구원님은 없을 것 같아서 여기 설명은 넘어가고, 이 방법의 문제점이 또 있습니다. 특정 포인트를 고르는게 아니고, 영역에서 softmax값 만큼 가중치를 주고 계산을 하다보니 outlier에 대한 문제가 있다고 합니다.
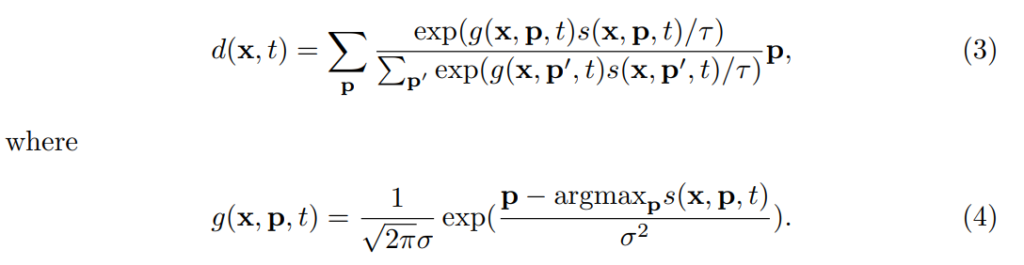
그래서 이 correlation 값에 2D Gaussian kernel를 적용해서 아웃라이어들을 마스킹 해주는 방식을 이용합니다. [수식 4]번이 가우시안 필터를 어떻게 줄지에 대한 수식이고, [수식 3]번이 가우시안 필터를 적용한 soft-argmax 수식이 됩니다. 특별한건 없는데, 수식은 1D 가우시안 필터같은데… 왜 2D인지는 모르겠습니다. 아무튼 이렇게 계산하는 값이 displacement 값이 되는데요. 여기서는 추가적인 정보를 하나 더 계산합니다.
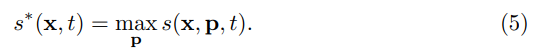
correlation의 max pooling을 적용해서 correlation의 confidence map을 계산하는데요. 이건 이제 auxiliary motion information으로 활용을 해서 displacement의 outlier를 찾거나, 모션 정보 학습하는데 추가적으로 활용을 합니다. 최종적으로 이 단계에서는 2채널의 displacement map과 1채널의 confidence map이 생성됩니다. 채널축으로 concat 해서 3채널로 다시 만들어줍니다.
Feature transformation
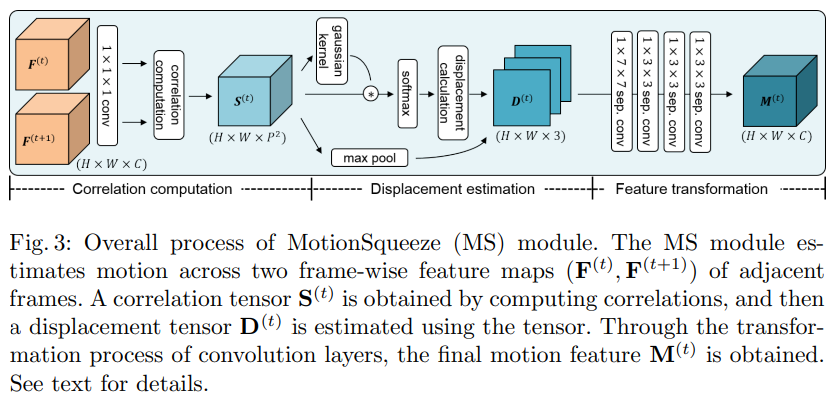
마지막 단계는 displacement tensor D^{(t)}를 motion feature M^{(t)}로 바꿔주는 과정입니다. 이 과정을 보기전에 [그림 3]의 모델 구조만 보면 설명이 다 되서, 그림을 잠깐 보면 마지막 단계에서는 D^{(t)}에 4개의 depth-wise separable convolution layer를 태우면 끝입니다. 이제 이 레이어들이 아까 계산한 변위와 confidence를 학습해서 motion feature를 뽑아준다고 보면 됩니다.
MotionSqueeze network (MSNet)
모듈에 대한 설명은 끝났고, 이 단계에서는 Resnet 백본에 이 모듈을 어떻게 끼워넣을 수 있는지에 대해 설명합니다. (Resnet에만 가능한건 아니고 모든 백본에 넣을 수 있다고 하네요.) 우선 Resnet의 Residual block마다 TSM이라는 모듈을 넣습니다. 이 TSM은 Temporal shift module로, 2D conv 연산을 수행하기 전에 feature의 channel의 일부를 temporal한 축에 따라 옮기는 형식으로 2D인데 3D conv의 효과를 얻을 수 있게하는방법론이라고 합니다.

Resnet 백본의 세번째 stage에 MS module을 끼워넣고, 계산한 motion feature를 element-wise addition 해줍니다. 이렇게 간단하게 이 모듈을 여러 백본에 붙일 수 있다고 하네요.
Experiments
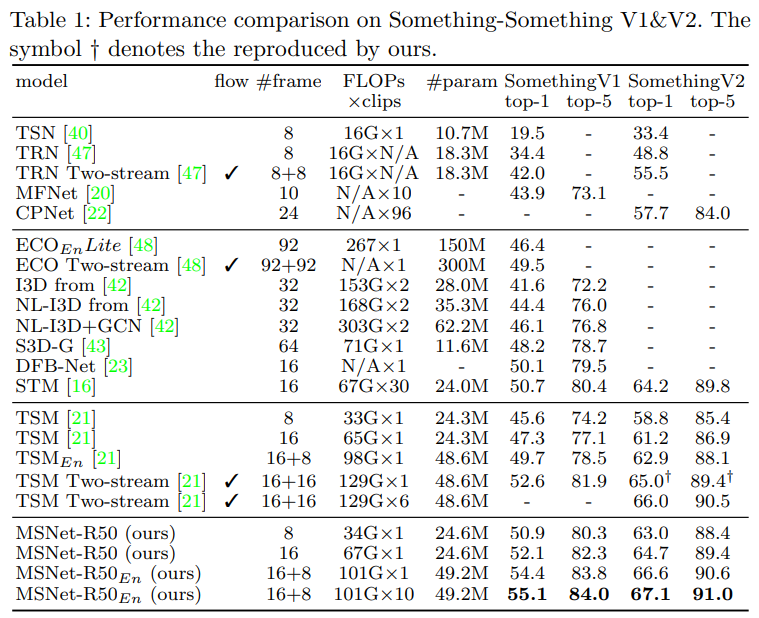
[표 1]은 기존의 SOTA 방법론과의 비교입니다. 주목해야할 부분은 FLOPS와 성능입니다. 기존의 optical flow를 활용하는 방법론이 체크표시된 방법론들인데요. 아무래도 two-stream 기반이다 보니 FLOPS가 높고 성능도 높은 것을 볼 수 있습니다. 이와 대응되는 방법론이 E_n이 붙어있는 MSNet인데요. 이건 16프레임 / 8프레임 간격으로 계산한 두 모델을 앙상블한 방법론인데요. 조금 더 빠르고, 높은 성능을 보이는 것을 볼 수 있습니다. 그리고 굳이 이렇게 앙상블 하지 않을 경우에는 훨씬 빠르고, 비슷한 성능을 보입니다.
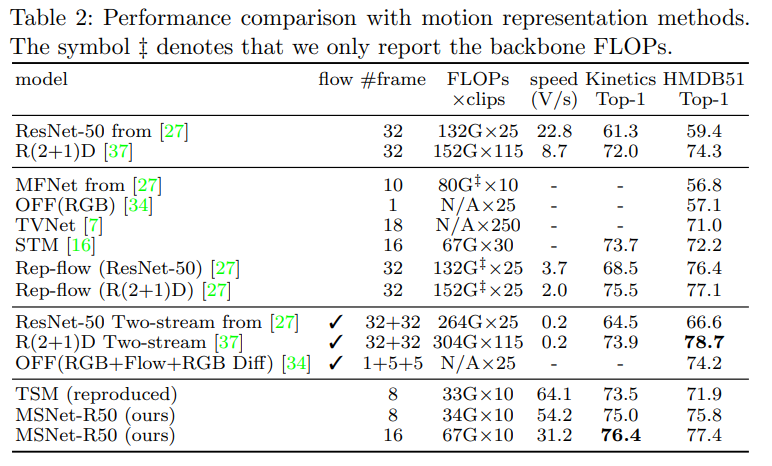
[표 2]는 motion representation을 활용한다는 방법론들과의 비교입니다. 여기서도 비슷한 경향성을 확인할 수 있는데요. MSNet이 optical flow를 활용하는 방법론들 보다 훨씬 빠르고 비슷한 성능을 가지고, Flow만 쓰거나 RGB만 쓰는 방법론에 비해서는 빠르거나, 성능이 더 높은 것을 확인할 수 있습니다. 특히 비교군으로 맨 위의 ResNet50과 R(2+1)D의 성능을 좀 비교해서 보면 논문에서 TSM과 MS module을 잘 결합하여 motion feature를 추출한 것 같습니다.

Abalation도 더 많은데, 모델 ablation은 이제 관심이 있으신 분들이 찾아보면서 보는게 좋을 것 같습니다. 리뷰에서 다뤄볼만한 부분으로는 MS module이 정말 여러 백본에 적용이 가능한가에 대한 실험으로 [그림 5]를 확인하면 되고, 다른 방법론이 아니라, 좀 더 직접적인 Two-stream과의 비교는 [표 6]을 확인하면 됩니다. Optical flow 자체가 flow를 여러개 쌓아서 사용하기 때문에, 공정한 비교를 보려면 “8+(8X1)”을 봐야한다고 하네요.
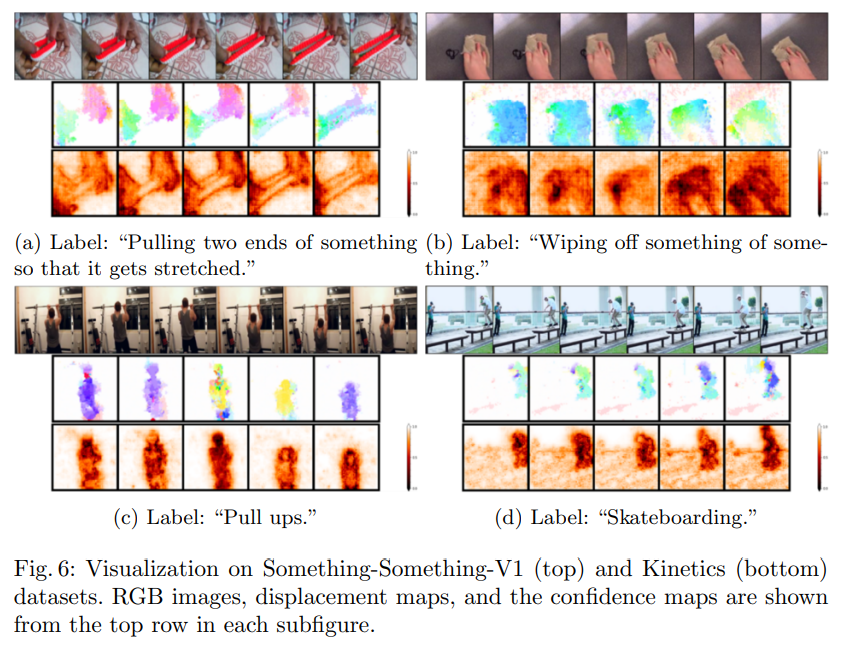
마지막으로는 displacement map과 confidence map에 대한 정량적인 결과인데요. Optical flow로 뽑은 것 같이 움직임이 있는 영역을 잘 추출한 것을 볼 수 있습니다.
리뷰 잘 읽었습니다.
한가지 궁금한 점이 correlation map에다가 soft-argmax를 취한다고 하셨는데, softmax도 아니고 soft-argmax는 뭔가요?? softmax를 취한 다음에 argmax를 연달아서 취한 것을 soft-argmax라고 명칭하는 것인가요?
아뇨 argmax를 하게되면 미분이 안되니까 argmax는 안하고. 음… softmax 값을 weight로 가지는 weight sum? 정도로 생각하면
컨셉 자체가 미분 가능해야해서 argmax를 어떻게 뺄 수 있을까의 문제라서 argmax를 하는 것은 아니고요. 쉽게 생각하면 그냥 softmax 값을 weight로 가지는 sum pooling이라고 보면 될 것 같습니다.
안녕하세요 좋은 리뷰 감사합니다.
리뷰에서 언급해주신 displacement의 outlier는 어떤 상황에 발생할 수 있는건가요?
그리고 confidence map이 displacement의 outlier를 찾거나, 모션 정보 학습하는데 추가적으로 활용된다고 해주셨는데, outlier를 찾아내는 별도의 과정이 있는게 아니라 뒤 conv layer를 통과하며 얻을 수 있는 효과를 말씀하신 건가요?
우선 Displacement의 outlier 같은 경우에는 변화량을 계산하기 위해서는 어디서 어디까지 움직였는지를 알아야 계산을 하겠죠? Action이 좀 격하거나 배경이 밋밋하다고 생각하면 정해진 범위 내에 대응점이 없을 수도 있는데, 이 경우에 outlier가 발생할 수 있을 것 같습니다.
뒤의 질문은 그게 맞습니다. 따로 추가적인 연산을 해준다기 보다는, 서로 다른 정보를 채널축으로 합쳐 conv layer에 던져서 모델이 학습하기를 기대하는 방향입니다.