안녕하세요. 이번 주차 X-Review는 ‘Temporal Sentence Grounding in Videos’ task (이하 TSGV)에 대한 전반적인 서베이 내용으로 준비했습니다. 내년부터 ETRI 과제가 text와 video를 함께 사용하는 방향으로 확장될 수 있기에 해당 task에 대해 미리 대비하고자 서베이를 수행하였습니다.
서베이 내용은 아래 서베이 논문들을 참고하여 작성했습니다.
- [ArXiv 2022] Temporal Sentence Grounding in Videos: A Survey and Future Directions
- [ACM CS 2021] A survey on temporal sentence grounding in videos
우선 TSGV task에 대해 소개드리고, 본격적으로 최근 연구 동향은 어떤지 살펴보겠습니다.
지난 연구실 세미나 때 임근택 연구원님께서 소개해주시어 간략하게나마 아실 것으로 생각됩니다.
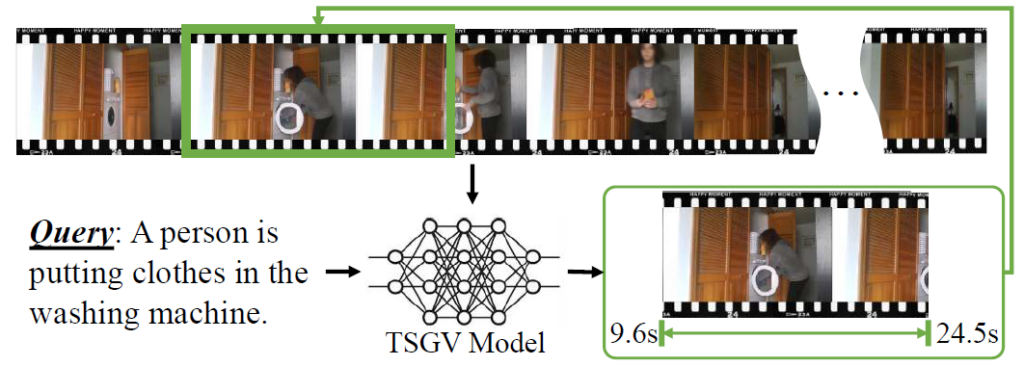
TSGV task는 그림만 보셔도 쉽게 이해하실 수 있습니다. 위 그림과 같이 text query와 video를 함께 입력으로 받습니다. 이후 잘 설계된 TSGV 모델을 거쳐 결국 비디오에서 text query의 의미론적 행동이 실제로 발생하는 구간을 찾아내는 것입니다.
위 그림에서는 주어진 text query의 내용이 ‘사람이 세탁기에 옷을 넣는다’로 ‘사람’과 ‘세탁기’, ‘넣는다’를 잘 임베딩 하여 비디오에서 찾으면 되겠다, 싶지만 실제 데이터셋에는 이렇게 간단한 query 이외에도 ‘After retrieving a glass from the cupboard, he pours the juice into the glass.’ 또는 ‘The woman opens the refrigerator and removes a pomegranate’와 같이 비디오 전체 맥락 내의 시간적 선후관계까지 고려해야 하는 복합적인 query들도 다수 존재합니다.
따라서 TSGV는 길이가 긴 video와 복합적인 text query의 상관관계를 잘 파악하는 것이 핵심인 난이도 높은 task라고 볼 수 있습니다.
서베이 리뷰의 목차는 아래와 같습니다.
- Methods
1.1 General Pipeline of TSGV
1.2 TSGV Methods - Evaluation Metrics
- Benchmark Datasets
- Benchmark (2022 papers)
1. Methods
1.1 General Pipeline of TSGV
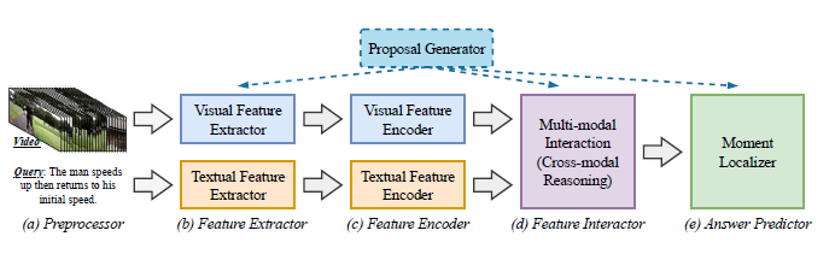
위 그림은 TSGV task 방법론들의 기본적인 파이프라인입니다. 이후 1.2절에서는 TSGV를 해결하기 위한 여러 접근법(methods)들을 소개해드릴건데, 대부분 공통적으로 위 component들은 포함하고 있다고 생각하시면 됩니다.
(a) Preprocessor 단계에서는 입력받은 video와 text에 대한 전처리가 이루어집니다. Video의 모든 프레임을 다루기엔 메모리 관점에서 비효율적이고, 또 연속되는 프레임끼리는 큰 변화가 없는 경우가 많기 때문에 실제로 사용할 프레임들을 샘플링하는 과정이 여기서 이루어집니다. Text query에 대해서는 한 문장을 단어 level에서 보며 tokenizing 하는 과정이 수행됩니다. 또는 너무 많은 단어를 가지는 문장의 경우 앞에서 몇 개만을 취하고 나머지는 버리는 작업도 해준다고 하네요.
(b) Feature Extractor 단계에서 video는 video model, text는 text model을 거쳐 feature로 변환됩니다. Video의 프레임들을 임베딩하기 위해 예전에는 VGG나 ResNet이 사용되다가, 최근에는 3D Convnet인 C3D, I3D도 많이 사용됩니다. Text에서는 GloVe나 Word2Vec부터 최근에는 Transformer 기반 모델들이 사용되고 있습니다. 서베이를 좀 하다보니, 최근에는 벤치마크 데이터셋에 따라 사용되는 backbone이 어느정도 정해져 있는 것을 확인했습니다.
(c) Feature Encoder 단계는 서로 다른 modal인 video feature와 text feature를 하나의 embedding space로 투영시키는 것이 목적입니다. TSGV task가 제안된 2017, 2018년 쯤에는 단순한 FC layer가 사용되다가 최근에는 GNN까지 사용되는 추세입니다.
(d) Feature Interactor 단계에서 본격적으로 task 수행을 위해 둘 간의 상관관계를 파악합니다. TSGV의 목적이 video에서 text query가 실제로 수행되는 구간을 찾아내는 것이므로 (d)단계를 어떤 구조로 설계하고, 어떤 loss 함수를 사용하는지에 따라 성능이 크게 좌우됩니다.
(e) Answer Predictor 단계에서는 앞서까지의 과정을 거쳐 만들어진 prediction에 점수를 매겨 최종 예측을 만들어내는 단계입니다.
1.2 TSGV Methods
1.1에서 살펴본 기본적 구조를 바탕으로, 최근까지 어떠한 방법론들이 연구되었는지 설명드리겠습니다. 같은 방법론에 속하더라도 논문마다 차이가 있기 때문에 하나하나 자세히 풀어 설명하기보단, 범주를 나누고 각각의 핵심 컨셉에 대해서만 적어보겠습니다.
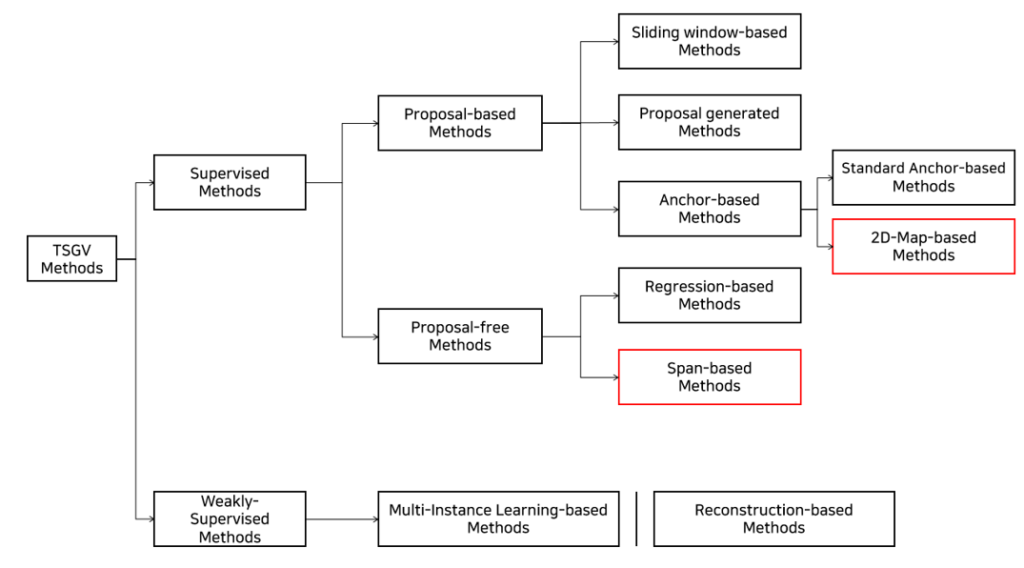
현재 학계에서 사용되는 방법론들의 관계도를 그려보았습니다.
기본적으로 Fully-supervised 방법론과 Weakly-supervised 방법론으로 나눌 수 있습니다. Fully-supervised 방법론은 입력으로 video와 text query가 들어가고, 모델이 예측한 구간을 주어진 실제 GT 구간과 비교하며 학습합니다. 이와 다르게 Weakly-supervised 방법론은 video와 text query를 입력받는 것은 같지만, 해당 text query에 대한 GT구간이 주어지지 않은 채로 학습합니다. 이번 리뷰에서는 Fully-supervised 방법론들만 살펴보겠습니다.
1.1절의 그림에 Proposal generator가 점선으로 이곳저곳에 연결되어 있는 것을 볼 수 있는데, 이는 방법론에 따라 포함되거나 포함되지 않거나, 또는 포함된다면 어느 단계에 들어갈지 다르다는 것을 의미합니다.
Proposal-based Methods
Proposal을 생성하고 이를 바탕으로 prediction을 만드는 방법론은 총 4가지로 나눌 수 있습니다.
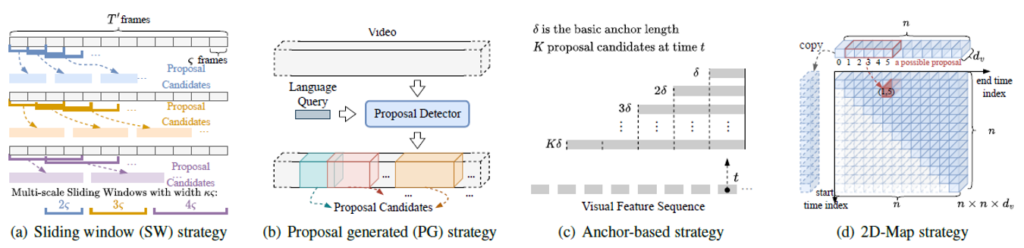
(a)는 가장 고전적인 방법으로, 다양한 크기의 window를 고정하고 비디오에서 sliding 하며 해당 window의 구간이 text와 잘맞는지 측정합니다.
(b)는 모델 내 별도의 Proposal detector 모듈을 두어 비디오에서 proposal을 여러 개 생성하고 계속 refine 하며 최종 prediction을 만들어내는 방식입니다.
(a)는 다양한 크기의 window를 만든다고 해도 결국엔 고정된 크기의 prediction만을 생성해내는 구조이고, 연산량이 크다는 단점이 있습니다. (b)는 (a)에 비해 연산량 측면에서는 좀 더 낫지만, 이후의 방법론들에 비해 proposal을 dense하게 생성해내지 못한다는 단점이 존재합니다.
이후 등장한 (c)는 video를 작은 anchor 단위로 쪼개고, 각 anchor들이 text query 구간에 포함될 확률을 계산해가며 anchor들을 합쳐가는 방식으로 proposal을 만들어냅니다.
(d)는 시작 지점과 끝 지점의 축을 하나씩 둔 2차원 map 형태를 사용합니다. 위 그림에서 map의 (1, 5)지점 원소는 text가 비디오의 1에서 시작해 5에서 끝날 확률 값을 의미합니다. 아래는 (d) 방식을 처음으로 제안한 2DTAN이라는 방법론의 모식도입니다.
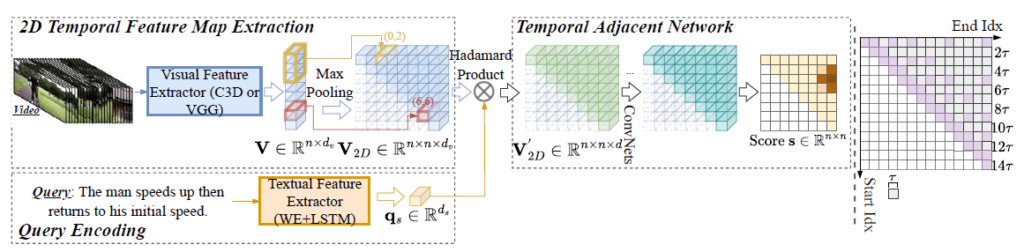
언뜻 생각하면 (a) 방식처럼 굉장히 많은 연산량을 요구하는 것 같지만, dense한 구간들을 2D map으로 표현함으로써 각 moment 간의 상관관계를 알아내 연산량을 많이 줄일 수 있다고 합니다. 이후에는 연산량을 더욱 줄이고, 2D map 속 moment들의 상관관계를 잘 모델링하는 방식들이 높은 성능을 보이고 있습니다.
Proposal-free Methods
Proposal-free 방법론 중 첫 번째는 Regression-based method 입니다. 하나의 query를 입력 받으면, 그에 대한 시작 지점과 끝 지점을 회귀 방식으로 찾아냅니다.
두 번째는 Span based 방식으로, video를 segment로 나눈 뒤 각 segment가 query 구간의 시작일 확률과 끝일 확률을 계산합니다. 이후 계산된 확률을 이용해 prediction을 만듭니다.
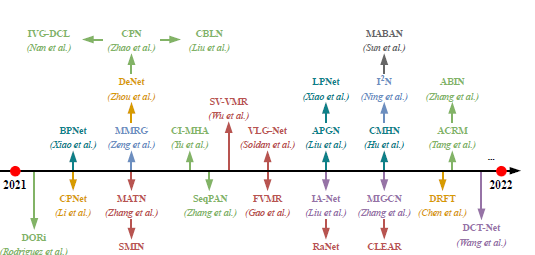
21년도의 논문들을 정리한 것입니다. 다양하지만 최근에는 그 중에서도 2D-Map 방식(빨간색)과 Span-based 방식(연두색)이 상대적으로 많이 연구되는 것으로 보입니다.
2. Evaluation Metrics
TSGV task에서 사용되는 평가지표에 대해 알아보겠습니다.
- Recall(or Rank)@n, IoU@m
- mIoU
위와 같이 2가지가 존재하며 하나씩 보겠습니다.
Recall@n, IoU@m
다들 잘 아시는 recall 개념이 사용됩니다. Recall@n, IoU@m은 모델의 예측 구간들 중 시간 축에 대한 GT와의 IoU가 가장 높은 n개를 봤을 때 그 IoU가 m 이상인 예측 구간이 하나라도 존재하면 해당 query는 positive로 보겠다는 것입니다. 모든 query에 대해 위 과정을 거쳐 모델의 성능을 측정합니다.
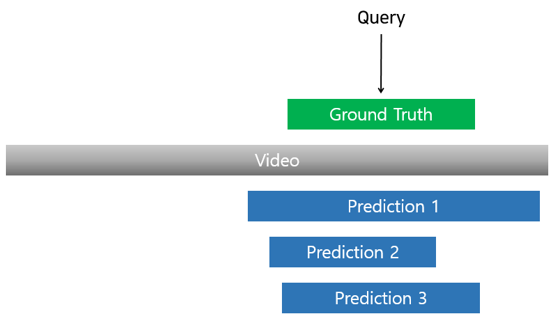
이해를 돕기 위해 그림을 가져왔는데, R@3, IoU@0.7을 기준으로 평가해보겠습니다. 주어진 video와 query에 대해 모델이 Prediction 1, 2, 3, …을 예측했고, 가장 IoU가 높은 3개의 예측 구간이 Prediction 1, 2, 3인 상황입니다. GT와 Prediction 1, 2, 3의 IoU가 각각 0.4, 0.6, 0.8이라고 가정해봅시다. 그러면 예측 구간 top-3개를 봤을 때 IoU가 0.7을 넘는 Prediction 3이 존재하니 해당 query는 positive로 계산되는 것입니다.
앞서 제가 1.2절에서 여러 방법론들을 소개해드렸는데, Proposal-based 방법론들은 여러 개의 proposal에 대해 점수를 매겨 top-n개의 예측을 만들어낼 수 있습니다. 따라서 R@5, R@3 등의 성능을 측정할 수 있지만 Proposal-free 방법론들은 한 query에 대해 하나의 예측 구간만을 만들어내므로 R@1만 측정 가능합니다. 벤치마크 데이터셋이나 논문에 따라 n은 보통 1 또는 5, m은 {0.1, 0.3, 0.5} 또는 {0.3, 0.5, 0.7} 등이 사용됩니다.
mIoU
mIoU는 평균 IoU를 의미합니다. 모델이 query에 대해 만들어 낸 예측 구간 중 가장 큰 IoU 값을 선택합니다. Query가 100개라면 100개의 IoU를 얻을 수 있고 그들의 평균을 mIoU로 나타냅니다. 최근 논문들을 살펴보니 mIoU는 잘 표기하지 않고 첫 번째로 소개드린 평가지표 R@n, IoU@m만을 측정하는 듯 합니다.
Benchmark Datasets
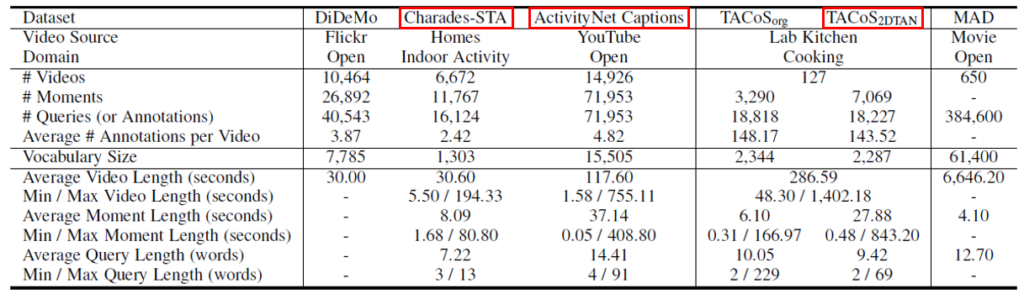
데이터셋은 크게 6개 존재합니다.
최근 21~22년도 논문을 보니 Charades-STA와 ActivityNet Captions 데이터셋이 벤치마킹에 사용되고, 논문에 따라 TACoS_{2DTAN} 데이터셋을 추가로 벤치마킹하는 경우도 있었습니다.
DiDeMo 데이터셋은 저번 세미나 때 말씀드린 바와 같이, TSGV task를 처음으로 제안한 논문에서 공개한 데이터셋입니다. 하지만 한 query에 대한 temporal annotation이 5초 단위로 되어 있고, 비디오가 공개된 것이 아닌 추출된 feature가 공개되어 있어 19년도 이후로는 잘 사용되지 않는 것을 확인했습니다.
MAD 데이터셋은 video 개수가 총 650개로 적어보이지만, 하나의 video가 평균 110분에 해당하는 영화 한 편입니다. 21년도에 공개된 데이터셋인데, 확인해보니 아직 MAD 데이터셋을 벤치마킹하는 논문은 찾아보지 못했습니다. MAD가 벤치마킹에 사용되는지는 추후 연구들을 살펴봐야할 것 같습니다.
Charades-STA 데이터셋과 ActivityNet Captions 데이터셋이 최근 벤치마킹에 사용되는데, ActivityNet Captions 데이터셋이 Charades-STA 데이터셋에 비해 전체 video 개수, 전체 moment 개수, 한 video에 존재하는 moment의 개수, 한 query 당 단어 개수 등이 훨씬 많아 TSGV task에서 사용되는 가장 큰 데이터셋에 해당합니다.
또한 video들이 어떤 도메인에 국한되어 있지 않고 반려동물, 스포츠, 요리 등 다양한 도메인을 포함하는 open-world setting이라는 점에서도 어려운 데이터셋이라고 해석 할 수 있습니다. TSGV에서는 val1을 공식적인 test 데이터셋으로 사용한다고 하네요.
4. Benchmark (2022 papers)
지금까지 TSGV의 방법론들, 평가지표, 데이터셋을 하나씩 살펴봤는데, 마지막으로 2022년에 나온 논문들의 성능은 어떠한지 보고 리뷰를 마치겠습니다.
Fully-supervised
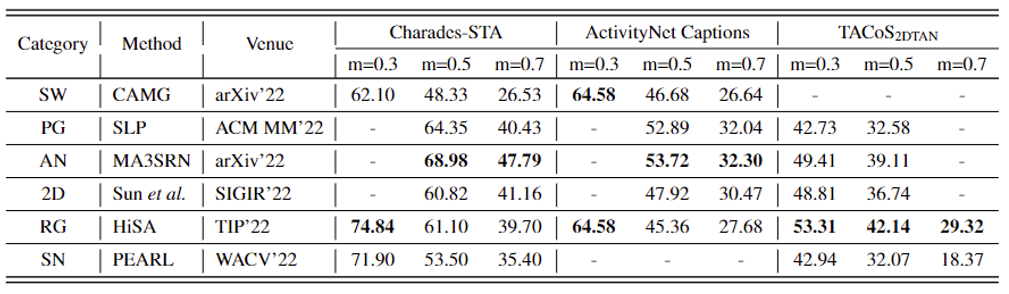
서베이 논문에 17년도부터 22년도까지 거의 모든 논문의 성능이 있었는데 2022년도(arXiv 포함) 논문의 성능만 가져와 표를 재구성하였습니다. 공교롭게도 방법론 별로 하나씩 존재하네요. 성능은 R@1, IoU@m입니다.
Anchor based 방식의 MA3SRN 또는 Regression 방식의 HiSA가 SOTA라고 볼 수 있는데, 이 마저도 데이터셋마다, 기준 IoU마다 성능 차이가 좀 커서 어떻게 분석해야 할지는 잘 모르겠습니다… 또 찾아보니 MA3SRN은 query에 대한 시간 구간 뿐만 아니라 그 구간 내 spatial 한 bounding box까지 찾아내는 Spatio-temporal TSGV를 수행하는 방법론이라고 하네요. 만약 ETRI 과제로 TSGV를 하게 된다면 위 논문들 먼저 읽어봐야 할 것 같습니다.
Weakly-supervised
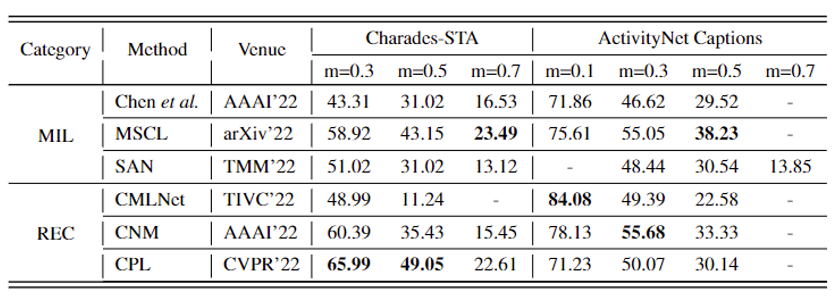
Weakly-supervised 방법론들은 앞서 설명드렸듯 query에 대한 temporal annotation 없이 학습을 수행합니다. 마찬가지로 데이터셋에 따라 성능이 일관되지는 않지만 Fully-supervised 방법론과 성능 차이가 recall 기준 많게는 10% 정도 나는 것을 볼 수 있습니다.
아직 TSGV에 대해 서베이만 수행하였는데, ETRI 과제로 위 task를 연구하게 된다면 Text embedding을 포함해 더욱 자세한 내용들을 공부할 예정입니다. TSGV는 결국 video 또는 text의 feature representation + modal 간 relation 파악이 핵심이라는 생각이 드네요.
이렇게 정리해놓고 보니 유튜브같은데서 텍스트로 검색해도 영상에서 해당 부분을 찾을 수 있다고 생각하니 해볼만한 task라는 생각이 드네요. 다만 Video retrieval에서도 속도 문제가 있어서 상용화 하는데 어려움이 있는데, 결국은 이 task도 Localization이니까… 비디오를 프레임 단위로 봐야 할 것 같아 여기서도 비슷한 문제가 당연히 있을 것 같습니다. 이런 부분에서는 어느정도로 다뤄지는지가 궁금하고, 데이터셋이 많다고는 하는데 그렇게 크지는 않아보이네요. 학습은 특정 데이터셋에서 하고 다른 데이터셋에서 평가하는지, 아니면 각 데이터셋마다 학습셋이 있는지도 궁금합니다.
1. 비디오에서 샘플링 된 프레임 중 window나 anchor 단위의 feature를 사용하기도 하고, 2D Map 방식의 경우 시작, 끝 지점 구간 단위의 feature를 만들어 사용하는 듯 합니다. 연산량을 줄이기 위해 2D Map 방식은 2D Map 상에서 인접한 단위를 모두 보는 것이 아닌 인접 32개 당 하나, 64개 당 하나 같은 방식으로 샘플링한다고 합니다.
2. 데이터셋은 Charades-STA와 ActivityNet Captions, TACoS 모두 train/test/val이 나누어져 있어 각 학습 데이터로 학습하고, val이나 test data로 성능을 측정합니다.
안녕하세요 좋은 리뷰 감사합니다.
Feature Encoder 부분에서 서로다른 크기의 feature를 하나의 공간으로 임베딩 하는것인지 궁금합니다. 혹은 모델을 두개를 사용하나요? 연구마다 다를것이라 예상되는데 어떤 구성이 가장 일반적인지 궁금하네요
최근 21년, 22년 논문을 살펴보니 extract 단계에서 같은 차원의 feature로 만들어준 후 단순한 1D Conv 나 FC Layer를 사용하는 경우도 있고, Transformer encoder를 통해 임베딩 하는 추세를 보이고 있습니다. extract 단계에서는 일반적으로 video 모델, text 모델이 각각 사용됩니다.
안녕하세요. 좋은 리뷰 감사합니다.
1) 1.Mehods의 1.1 General Pipeline of TSGV에서 (a) preprocessor 단계에 질문이 있습니다. 이 부분에서 Text query에 대해서 tokenizing하는 과정이 수행된다고 하는데, 이때 너무 많은 단어를 가지면 앞에서 몇 개만 취하고 나머지는 버리는 작업을 한다고 하였습니다. 근데 만약에 정말 중요한 부분을 설명하는 핵심 단어가 뒤에 있는 경우에는 버려지게 되는데 논문에서는 이 부분에 대해서 어떻게 나와있을까요?
2) 중간의 proposal-based methods에서 질문이 있습니다. (c)의 Anchor-based strategy 부분에서 anchor 단위로 쪼갠뒤 각 anchor들이 text query 구간에 포함될 확률을 계산해가며 anchor들을 합치는 방식으로 proposal을 만든다고 하셨는데, 그림을 보면 시간 t에 대해서 anchor 들을 합쳐가며 proposal을 만드는 거 같은데 이런 경우 시간 t에 대해서 각 합쳐진 anchor가 만들어지고, 결국에는 총 t개의 proposal이 만들어지게 되는 걸까요?
3) proposal-based methods의 (d) 부분에서 질문 있습니다. (d)가 시작 지점과 끝 지점의 축을 하나씩 둔 2차원 map을 사용한다고 하셨는데, 중간의 그림을 보면 Visual Feature Extractor를 거친 후에 나오는 2d map을 말하는 거로 이해했는데 맞을까요? 이때 Visual Feature Extractor 부분 보면 C3D 혹은 VGG를 사용한다고 하는데 2d map은 우리가 흔히 생각하는 CNN layer를 거치면 나오는 feature map을 의미하는 걸까요? 아니면 feature map에 어떠한 처리를 하여 가공한 것일까요?
또한, 시작 지점과 끝 지점의 축이라는 것이 무슨 의미인지 잘 이해가 가지 않는데ㅜ 이 말이 비디오의 시작 지점과 끝 지점을 말하는 것이라면 2d map은 비디오의 대해서 모든 정보를 가지고 있는 feature map이라고 이해해도 되는 걸까요?
감사합니다.
1. 서베이 논문이기 때문에 어떤 처리를 해주는지 논문에 따로 나와 있지는 않았습니다. 하지만 제 생각에는, 모든 문장에 속한 각 단어의 중요도를 따지는 것은 extract 또는 embedding 또는 encoding 과정에서 이루어지기 때문에, 중요한 단어가 어디 있는지와는 관계 없이 버려지고 남은 단어들만 사용하여 학습될 것으로 생각됩니다. 또한 일정 개수 이상의 단어를 버리는 과정은 포함될 수도 있고, 포함되지 않을 수도 있기 때문에 크게 문제되지 않을 것으로 생각합니다.
2. 논문마다 다르겠지만, 대표적으로는 델타 길이를 갖는 t 시점의 anchor에 대해 1델타, 2델타, …, K델타 단위로 총 K개의 proposal이 만들어지므로 전체 길이가 T인 비디오에 대해서 T*K개의 proposal이 존재할 것입니다. 이렇게 되면 기존 sliding window 방식 보다는 dense하게 proposal을 만들어낼 수 있을 것입니다. 또는 각 anchor에 대해 GNN을 적용하거나 단순히 stack 하는 방식도 있는 것 같은데, 자세한 내용은 저도 추후에 논문을 읽어봐야 할 것 같습니다.
3. 그림의 2DTAN 모델을 기준으로 설명드리면, 비디오에서 총 n개의 프레임을 샘플링한 뒤 각 프레임마다 d차원의 feature를 추출합니다. 추출한 feature를 이용해 n*n*d의 2d map을 만듭니다. 이 2d map의 각 원소는 feature인데 (0, 3) 지점에 “0번 프레임의 feature부터 3번 프레임의 feature까지 max pooling 하여 만든 d차원의 feature”가 들어가는 것입니다. 그림에서 map의 우상단에만 원소가 차는 이유는 시작-끝 축이기 때문에 (3, 0), 즉 3에서 시작해 0에서 끝나는 구간은 존재할 수 없기 때문입니다. 이렇게 만든 2d map에 conv를 태우고 sigmoid를 적용해 구간 별 최종 score를 만들어냅니다. 결론적으로 CNN layer를 거쳐 나온 feature map 자체라고 보기엔 어렵습니다.
4. 비디오의 시작과 끝이라기 보단 예측해야 하는 구간의 시작 지점과 끝 지점에 대해 가능한 모든 경우의 수를 matrix로 만들어 점수를 예측하고, 이를 바탕으로 학습하는것이 2D Map 방식이라고 보시면 될 것 같습니다.