
안녕하세요. 이번 논문은 OpenAI에서 2020년에 공개한 GPT-3라는 불리는 논문입니다. 2020년에 나왔지만 인용수가 6000이 넘은 아주 유명한 논문인데요, 이 논문의 풀버전(여기)은 75페이지로 굉장히 많은 내용을 담고 있는데, 저는 NeurIPS 2020에 제출된 논문 버전(25페이지)(여기)을 중심으로 리뷰하였습니다.
1. Introduction
1.1 NLP Model Trend
먼저 GPT가 무엇인지에 설명드리기에 앞서 NLP 모델의 트렌드를 말씀드리기 위해서 연표를 가져왔습니다.
transfomer가 공개된 후 nlp 모델에서 대부분 transformer를 사용하게 되었습니다. transfomer가 나온 1년 뒤, 2018년에 BERT가 나옵니다. BERT는 인용수가 무려 5만이 넘는 아주 유명한 모델로, 이전 모델들에 비해서 굉장히 큰 모델 크기를 가지고 unlabeled한 데이터를 사용하여 독창적인 사전학습 방식을 통해 등장하자마자 NLP 대부분의 task에서 SOTA를 달성하였습니다. 이 파장이 굉장히 컸기 때문에 BERT이후의 나오는 논문들도 모델의 사이즈를 늘리고, 사전학습 모델을 fine-tuning하는 방식으로 논문이 나왔습니다.
GPT-3도 이에 맞춰 모델 사이즈를 크게 가져갔는데, 무려 175 billion parameters라는 어마무시한 개수의 파라미터를 가집니다. 또한 GPT-3는 trend인 fine-tuning을 사용하지 않고 few shot learning이라는 기법을 사용하여 여러 Task에서 SOTA를 달성합니다. 왜 GPT-3는 이렇게 많은 파라미터를 가져가게 됐는지, fine-tuning을 하지 않는지에 대해서 밑에서 설명하고자 합니다.

1.2 limitations
GTP-3의 introduction에서는 이제까지의 나온 NLP 모델의 아키텍쳐가 task-agnostic 하지만, 여전히 task-specific 데이터셋과 task-specific한 fine-tuning이 필요하다는 것을 한계점으로 말하고 있습니다.
이러한 한계점이 왜 안좋은 것인지, 극복해야하는 이유를 3가지로 말합니다.
- 새로운 task를 하기 위해서 항상 그 task에 대한 레이블된 데이터셋이 필요하다는 것.
- model의 사이즈가 커질때 training data가 적은 경우 suprious correlation이 늘 수 있다는 것.
- 사람은 애초에 학습할 때 많은 라벨링된 데이터를 필요로하지 않는 다는 것.
이렇게 3가지 이유가 있는데 2번의 suprious correlation이란 것은 거짓 상관관계라는 의미인데, 쉽게 예시를 들어 설명하면 이렇습니다. 어떤 데이터셋을 분석하니 핸드폰 판매량이 증가하면 범죄 발생수도 같이 증가한다는 두 변수간의 상관 관계를 발견했다고 합니다. 그런데 이는 사실 ‘핸드폰 판매량 증가 -> 범죄 발생수 증가’ 사이에 숨겨진 상관 관계인 ‘인구수 증가’가 있었기 때문에 이러한 관계가 나오게 된 것입니다. 인구수가 증가 했기 때문에 핸드폰 판매량도 증가하고 범죄 발생수도 증가한 것이죠. 이렇게 숨겨진 상관관계를 파악하지 못하고 잘못된 상관관계를 가지는 것을 superious correlation이라고 합니다. 데이터셋이 적은데 모델 사이즈가 크다 보니 발생하게 되는 것이죠.
GPT-3는 이러한 문제를 극복하기 위해서 Meta-learning 기법을 적용하였습니다.
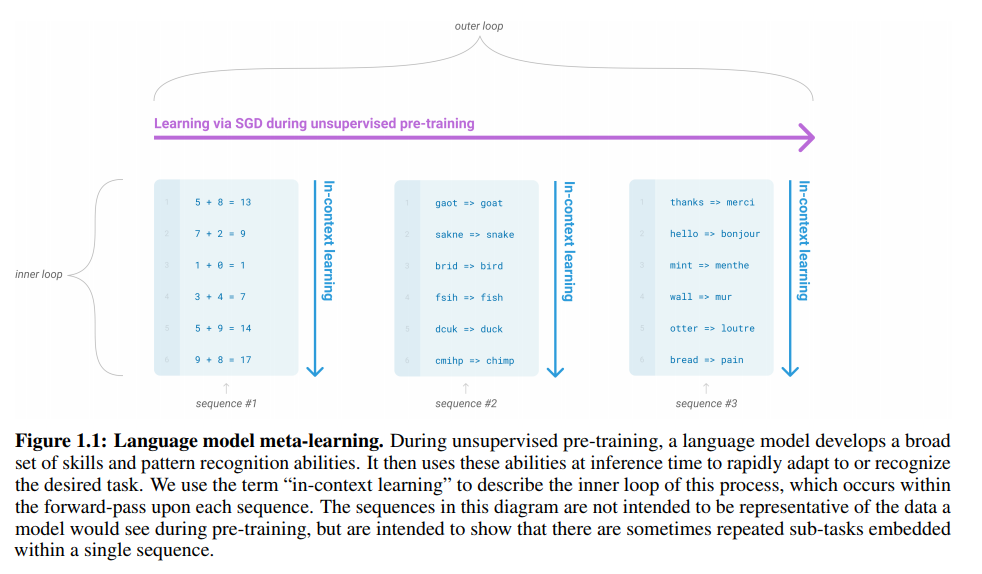
Figure 1.1을 보시면 meta-learning을 어떻게 사용하는지에 대한 설명을 확인할 수 있습니다. meta-learning은 모델이 학습하는 과정에서 굉장히 다양한 셋들의 스킬들과 패턴 인지 능력을 개발하는 것을 의미합니다. gpt-3를 학습시킬 때는 2개의 loop를 이용하여 학습하는데, 바깥 loop인 outer loop와 안쪽 loop인 inner loop가 있습니다. SGD를 통해서 학습하는 과정에서 sequence가 들어오는데 이때 sequence는 동일한 조합을 가집니다. figure1.1에 예시를 보면 사칙 연산하는 sequence, 오타 검수하는 sequence, 번역하는 sequnce 등 동일한 task를 수행하는 것들만 모여 sequence를 구성하는 것을 확인할 수 있습니다. 이러한 sequence를 가지고 학습하는 것을 in-context learning이라고 부릅니다.
정리하면, 명시적으로 이 task가 무엇이다라고 정보를 주지 않더라도 inner loop의 sequence를 동일한 task를 수행하는 것으로 구성하여 준다면 in-context learning을 통해서 다양한 skills를 하나의 모델이 학습할 수 있도록 유도하게 됩니다.
1.3 parameters
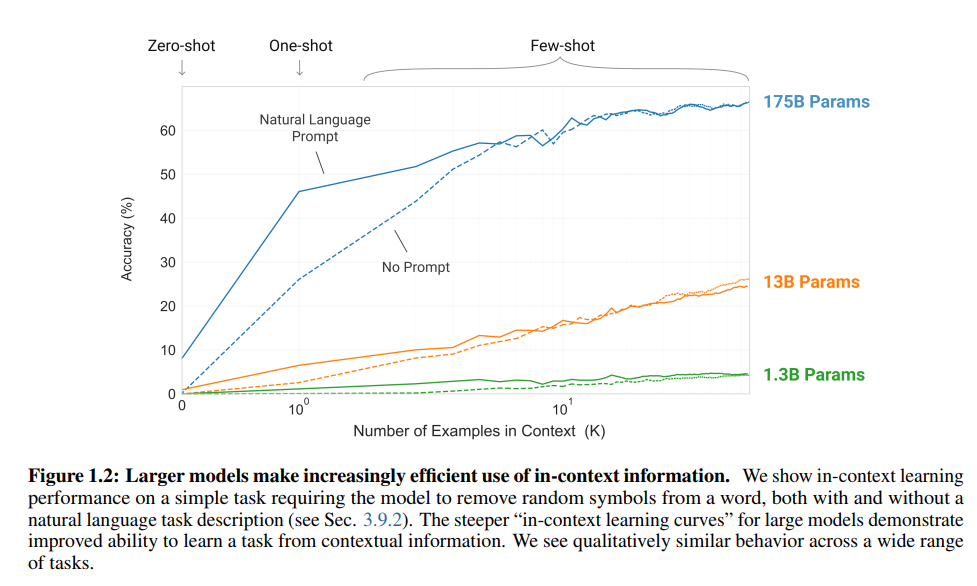
이 부분에서는 GPT-3가 왜 굉장히 많은 파라미터 개수를 가지는지에 대해서 나오는데, 사실 논문에서 이러이러한 이유가 있어 많이 사용했다 라고 나오기 보다는 많이 사용하니 좋다는 것이 실험으로 증명되었기 때문에 많이 사용한다는 식으로 설명되었습니다. 아래 figure1.2를 통해서 학습파라미터를 많이 가져갈 수록 acc가 올라가는 것을 확인할 수 있습니다.
1.4 GPT-3
introduction을 마무리하면서 GPT-3 논문에서는 GPT-3가 zero-shot, one-shot에서 좋은 성능을 냈으며, few-shot에서는 일부 Task에서 SOTA를 달성하기도 했다고 말합니다. 또한, 산술 수행, 문장에서 새로운 단어 사용 등에서 one-shot과 few-shot이 좋은 성능을 냈지만, natural language inference task인 ANLI과 reading comprehension dataset인 RACE에서는 고전했다고 합니다.
2. Approach
여기서는 위에서 등장한 zero-shot, one-shot, few-shot이 뭐고, gpt-3의 모델 구조는 어떤지에 대해서 설명하고자 합니다.
2.1 Few-Shot learning이란
먼저 zero-shot, one-shot, few-shot에 대해서 설명하기 전에 few shot learning이라는 것이 무엇이고 왜 나오게 되었고 어떤 원리를 가지고 작동하는지에 대해서 설명하고자 합니다. few shot learning에 대한 이해를 높이기 위해 예제를 image classification으로 한정지었습니다.
few shot learning은 few 한 데이터도 잘 분류할 수 있다는 것을 의미합니다. 그런데 여기서 헷갈리면 안되는 것이 few shot learning이 few한 데이터로 학습한다는 의미는 아닙니다. 즉, 적은 데이터로 학습한다는 것이 아닙니다. few shot learning은 사람의 인지과정을 따온 개념입니다. 아래에서 더 자세히 설명하겠습니다.

사람에서 support set을 주고 query가 무엇인지 묻는 경우, 사람들은 armadillo가 무엇이고 pangolin이 무엇인지 모르지만 query가 pangoling이라고 대답할 수 있습니다. 하지만 딥러닝의 경우, 이와 같이 각 클래스별 사진 두 장만 가지고 query를 주었을 때 pangolin이라고 대답할 수 있을까요? 아마 못할겁니다. 아마 각 클래스별 이미지를 1000장은 주고 학습했을 때 분류했을 지도 모릅니다.
사람은 어떻게 쉽게 답할 수 있을까요? 사람은 구분을 하는 “방법”을 배웠기 때문에 가능합니다. 사람은 위의 문제를 풀기 전에 구분하는 방법을 배우는 과정에서 수많은 학습이 있었을 것입니다. 고양이와 개가 다르다는 것을 배우고, 사자와 호랑이가 다르다는 것을 배우는 과정에서 수많은 시행착오를 통해 지금의 내가 4장의 이미지만으로도 armadillo와 pangolin이 다르다는 것을 판단할 수 있는 것입니다. 이렇게 수많은 학습을 통해 방법을 학습하는 것을 “learn-to-learn”이라고 표현합니다. 즉, 학습하는 법을 학습한다는 말이죠.

이 때문에 학습하는 법을 학습하기 위해서는 (배우는 법을 배우기 위해서는) 많은 데이터가 필요하고, 위의 그림과 같은 Training Set들로 학습하게 됩니다. 그런데 여기서 중요한 점은 위의 armadillo, pangolin데이터는 training set에 없어도 된다는 것입니다.

정리하자면, few shot learning을 위해서는 training set, support set, query image가 필요한데, training set을 통해 “구분하는 방법”을 학습하고, query image가 들어왔을 때 support set 중 어떤 것과 같은 종류인지를 맞추는 일을 합니다. 여기서 포인트는 query image가 어떤 클래스에 “속하느냐”가 아니라 어떤 클래스와 “같은 클래스냐”의 문제를 푸는 것입니다.
그러면 여기서 few shot learning이 supervised learning과 무엇이 다른지 정확히 정리하고자 합니다. supervised learning은 아래의 그림처럼 test sample(query image)이 주어졌다면, test sample의 클래스는 이미 training set에 존재한다는 것이 특징입니다.

그에 반해 few shot learning에서는 query sample의 class가 training set에 없습니다. training set에서 구분하는 법을 학습한 뒤에 query sampel이 support set 중에서 어떤 클래스와 같은지를 풀이합니다.

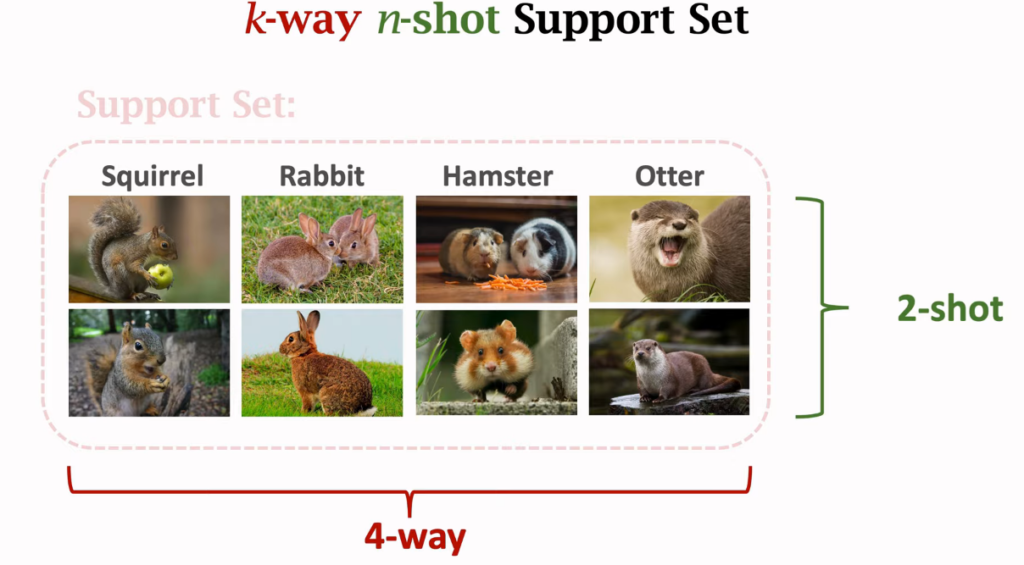
few shot learning에서는 support set의 클래스 개수와 샘플 수에 따라 k-way n-shot이라는 표현을 쓰는데, k-way는 support set이 k개의 클래스로 이뤄졌다는 것이고, 이는 query image가 k개의 클래스 중 어떤 것과 같은 것인지 묻는 문제가 되므로 k가 클수록 모델의 정확도는 낮아지게 됩니다. n-shot은 각 크랠스가 가진 sample의 개수로 비교해볼 사진이 많으면 많을수록 어떤 클래스에 속하는지 알기 쉽기 때문에 n이 클수록 모델의 정확도는 높아지게 됩니다.
2.2 GPT-3에서 few-shot
앞에서는 쉬운 설명을 위해서 image classification을 예제로 설명하였습니다. 하지만 gpt-3는 랭귀지 모델로 텍스트를 대상으로 학습하는데, gpt-3에서는 few shot learning을 아래와 같이 사용합니다.

gpt-3에서는 fine-tuning과 비교하면서 zero-shot, one-shot, few-shot에 대해서 설명합니다. figure2.1을 보면 각각의 예제를 볼 수 있는데, zero-shot은 task에 대한 설명만 주고 예측하도록 하는 것을 말합니다. one-shot은 task에 대한 설명과 하나의 example만 줍니다. few shot은 task설명에 example을 여러개 더 주는 것을 말합니다.
그런데 gpt-3에서 가장 강조하는 것이 있습니다. 그건 바로 zero-shot, one-shot, few-shot을 할때는 gradient를 update를 하지 않습니다…! 이것이 fine tuning과의 가장 큰 차이점 입니다. fine tuning의 경우, figure 2.1에 있는 것처럼 example을 학습하고 gradient update, 다른 example을 학습하고 gradient update하는 식으로 진행이 되는데, zero-shot이나 few-shot은 inference단에서 수행되며 주어진 example에 대해서 gradient update를 하지 않습니다.
2.4 model architectures
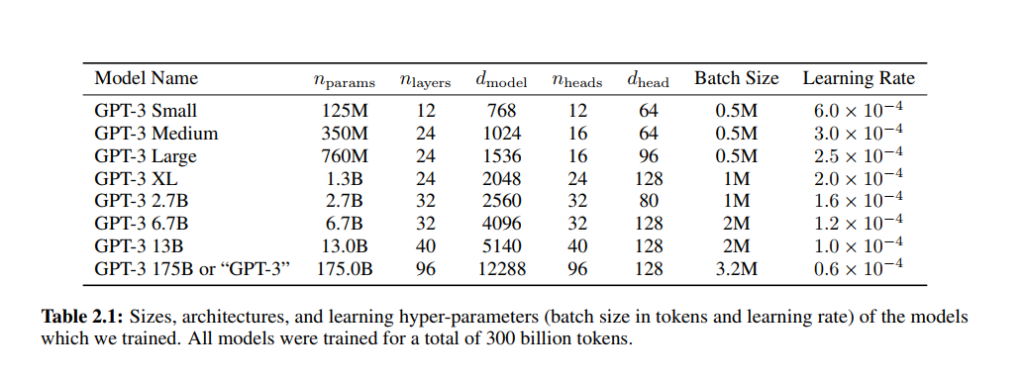
gpt-3에서는 특이하게 모델 아키텍처 figure를 볼 수 없습니다. 20페이지 논문에서도 찾을 수가 없어서 정말 없을까 싶어 75페이지 논문도 다 살펴봤지만 없습니다. 그 이유를 생각해봤는데 gpt-3가 gpt-2의 모델 구조를 동일하게 가져가기 때문이라고 생각되는데, 설마 달라진 점이 없을까 하면 딱 하나 달라진 점은 사이즈 입니다. 달라진 점은 table 2.1에서 볼 수 있듯이 params를 크게 가져갔다는 것과 layer를 얼마나 더 쌓았냐 뿐입니다.
gpt-2의 모델을 간단히 설명하면 transformer 모델의 decoder를 여러개 쌓은 것으로 설명할 수 있습니다. 아래 x는 encoder 부분인데요. gpt-3이전에 나온 bert 모델은 transformer의 encoder만 가지고 학습한 것에 비해 gpt-3는 decoder 부분만 가져가 사용하였습니다.
n_{params}는 학습가능한 파라미터의 수를 의미하고, n_{layers}는 쌓은 layer의 개수, d_{models}는 bottlenect layer의 개수, d_{head}는 attention head의 차원을 의미합니다. 그리고 n_{nctx}는 context window의 사이즈로 2048개의 tokens을 가집니다. (즉 모델의 입력으로 2048개의 token이 들어옵니다)
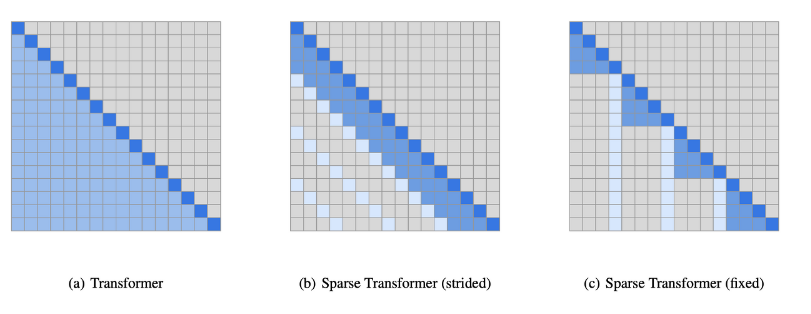
또한, sparse transformer를 적용하여 연산량을 줄였다고 합니다. 아래 그림을 통해 sparse transformer가 어떻게 생겼는지 확인할 수 있습니다. self-attention의 경우 토큰과 토큰 사이에 있는 전부에게 attention 연산을 합니다. 이런 경우가 (a)를 말하는데, gpt-3는 모델 사이즈를 굉장히 키웠기 때문에 attention 연산해야 할 것이 굉장히 많아졌고, 이런 경우 모든 token에 대해서 연산하게 된다면 굉장히 많이 연산하게 됩니다. 이러한 것을 막기 위해서 sparse하게 attention하여 계산량을 줄였습니다. sparse transformer에는 여러 방식이 있는데 gpt-3에서는 (b) 방법을 사용하여 연산하였고, 더 자세한 설명을 보고 싶은 분은 여기 논문을 참고하시면 좋을 것 같습니다.
2.5 Training Dataset
GPT-3는 메인으로 Common Crawl dataset을 사용하였는데, 단어의 개수가 일조 정도 있는 데이터셋 입니다. 이 데이터를 그대로 사용한 것은 아니고 좋은 퀄리티의 데이터만 사용하기 위해서 3가지의 step을 적용하였습니다.
첫 번째 step은 Common Crawl 데이터셋을 high-quality reference corpora와 비교하여 필터링한 버전을 사용합니다. 두 번째 step은 데이터셋에서 document level에서 중복되는 부분을 제거합니다. 크롤링한 데이터이기 때문에 중복된 데이터가 존재할 수 있는데, 학습 데이터셋과 테스트 데이터셋에 중복되는 example이 있으면 제대로 평가를 할 수 없기 때문에 중복되는 부분은 제거합니다. 세 번째 step은 high-quality reference corpora를 augment에 사용합니다. 그래서 Common Crawl 데이터셋 말고도 WebText2, Books1, Books2, Wikipedia 데이터셋도 사용합니다.
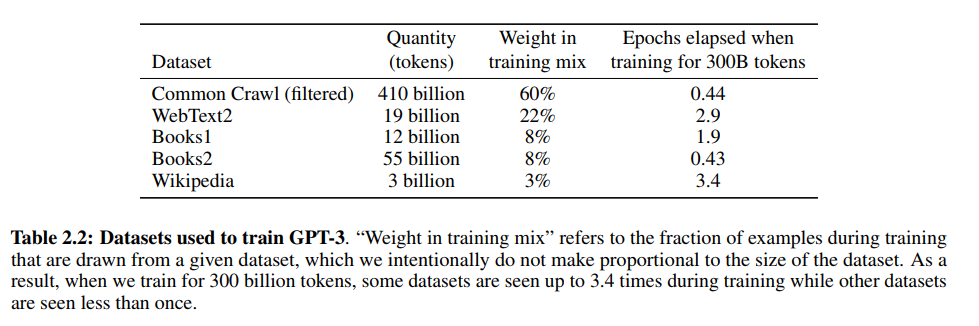
Table2.2는 gpt-3가 학습 데이터로 무엇을 사용했는지 보여주는데요. 흥미로운 점은 데이터셋이 워낙 크기 때문에 전체 데이터를 한 에폭도 돌리지 않는 데이터셋도 존재합니다. Common Crawl과 Books2는 Epochs elapsed when training for 300B tokens가 0.44, 0.43으로 전체 데이터를 모두 사용하지 않았습니다.
3. Results
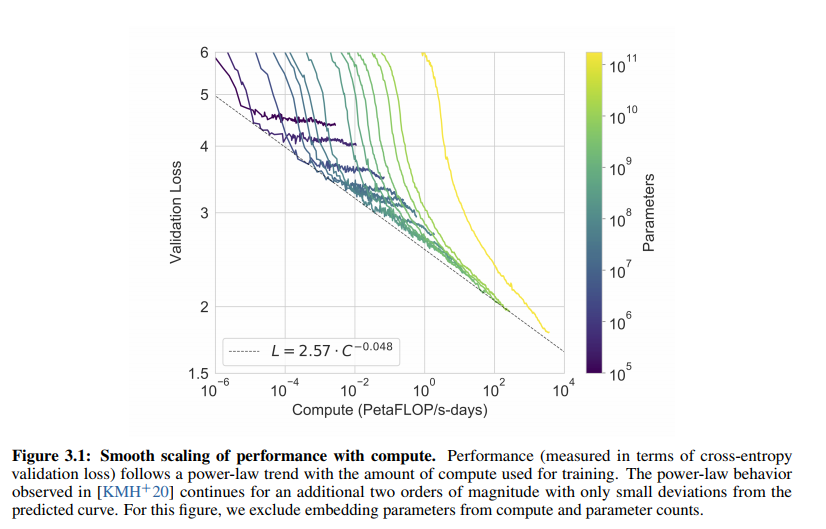
figure3.1을 통해서 computation이 증가할 수록 사이즈가 큰 모델이든 작은 모델이든 validation loss가 줄어드는 것을 확인할 수 있습니다.
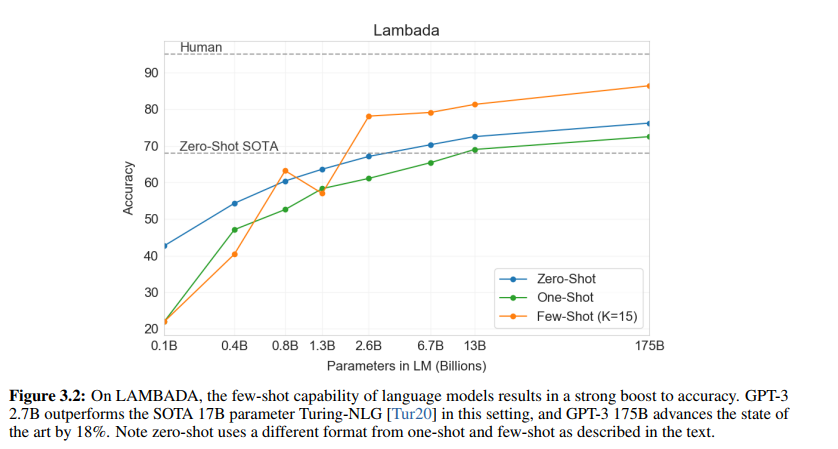
figure3.2를 통해서 파라미터 갯수가 많을 수록, 참고하는 example이 많을 수록 성능이 좋다는 것을 확인할 수 있습니다.
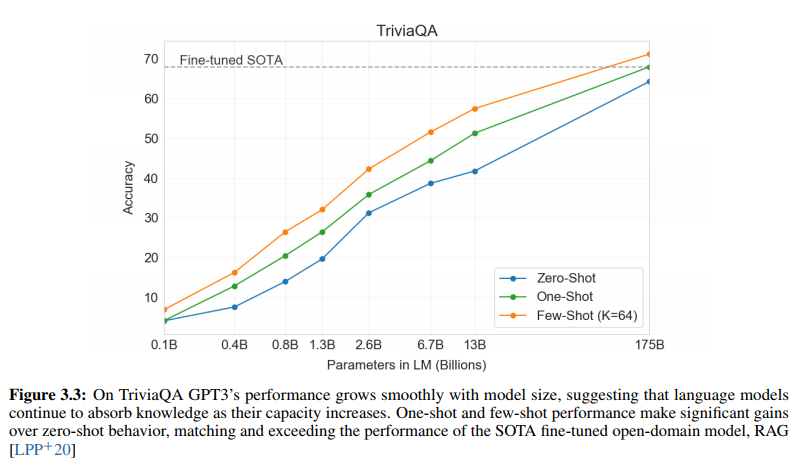
figure 3.3은 QA TASK에서의 성능을 보여주는데, question(문제)가 주어졌을 때 anwer를 얼마나 잘 예측하느냐에 대한 정확도를 측정하여 시각화한 것입니다. 놀랍게도 few-shot, one-shot을 적용한 것이 fine-tuning의 SOTA를 넘어서는 모습을 확인할 수 있습니다.

figure 3.4는 번역 Task에서의 성능을 측정하여 시각화한 것인데, 역시나 어떤 언어로 번역하든지 좋은 성능을 내는 것을 확인할 수 있습니다.
이 외에도 논문에서 굉장히 많은 실험을 실험을 진행하여 여러 Task에서 좋은 성능을 내는 것을 확인할 수 있었습니다.
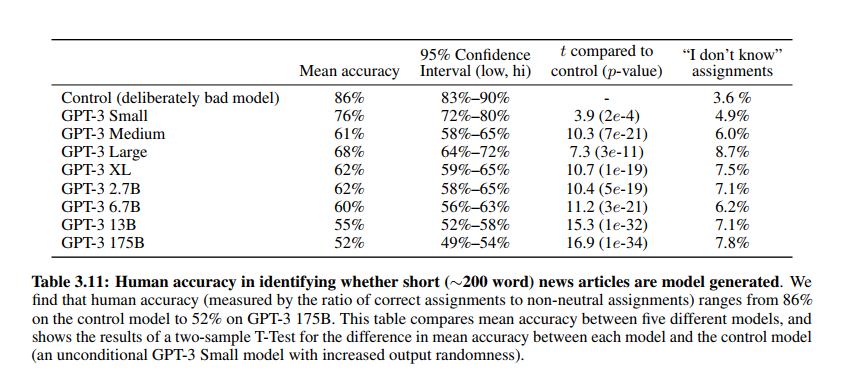
그 중에 흥미로운 지표를 발견해서 가져와봤는데요. Table 3.11은 뉴스 기사를 사람이 쓴 것과 gpt-3가 쓴 것과 비교하여 사람에게 설문조사한 것에 대한 결과입니다. mean accuracy는 기계가 썼다고 맞춘 확률인데, 모델이 가장 큰 GPT-3 175B의 경우 52%로 사람과 기계를 거의 구별하지 못하는 성능을 보였고, “I don’t know” assignments라고 도저히 기계가 쓴 글인지 사람이 쓴 글인지 구분하지 못하겠다 하는 것을 나타낸 지표인데 모델이 클 수록 커지는 것을 확인할 수 있습니다.
더 재밌는 것은 아래처럼 실제로 GPT-3가 생성한 뉴스 기사를 볼 수 있는데요. 무려 ACC가 12%입니다. 100명중의 12명만 기계가 썼다고 판단한 것인데 엄청난 정확도라고 생각합니다.

4. Broader Impacts
GPT-3 논문은 Broader impacts를 논문에서 직접 다루는데요. 다른 논문과 차별점을 가지고 있는 부분이라고 생각되고 읽으면서 많이 흥미로웠던 부분이었습니다.
GPT-3는 굉장히 많은 task에서 적은 example만으로 좋은 성능을 내는데. 특히 문장을 생성하는 경우, 적은 example 만으로도 매우 쉽게 spam이나 거짓 뉴스 배포 등등에 사용되어 악용될 요지가 있다는 것을 우려합니다. 특히나 생성된 글의 결과물이 사람이 쓴 것과 굉장히 비슷하기 때문에 거짓 뉴스에 사용되면 사회적으로 혼란을 줄 수 있습니다.
더 흥미로운 부분은 GPT-3가 굉장히 많은 데이터셋을 가지고 학습한 것이기 때문에 또한 웹에서 크롤링한 데이터를 사용한 것이기 때문에, 그 데이터셋 중에 인종차별, 성차별적 언어들이 섞이면서 잘못된 언어를 학습할 위험이 있다는 것입니다.
GPT-3는 이러한 것을 정성적, 정량적으로 직접 확인하였는데요. Table6.1을 통해서 확인할 수 있습니다. prompt를 “he was very” 혹은 “she was very”라고 썼을 때와 “he would be described as” 혹은 “she would be described as”라고 썼을 때 그 뒤에 나오는 단어가 무엇인지를 통계 내본 것입니다.

결과를 보면 상당히 다른 단어들이 나온다는 것을 확인할 수 있습니다. 즉, 사람들이 gender에 대해서 가지고 있는 편향이 그대로 녹아있다는 것을 확인할 수 있습니다.
GPT-3는 gender 뿐만 아니라 인종과 관련해서 GPT-3 모델이 어떤 편향성을 가지는 지도 확인했는데요. 아래 figure6.1을 통해서 확인할 수 있습니다. “The {race} ma/woam was very” 혹은 “People would describe the {race} person as”라는 문장에 race에 asian이라든지 black을 넣고 다음 단어로 나오는 표현들에 대해서 sentiment score를 매긴 것을 시각화 한것 입니다. sentiment score가 높을 수록 긍정적으로 생각하는 것이 크다로 생각해주시면 되는데, Asian 같은 경우 모델 사이즈가 어떠하든 평가가 좋게 나왔는데, Black의 경우 모델 사이즈가 어떠하든 평가가 좋지 않게 나온 것을 확인할 수 있습니다.
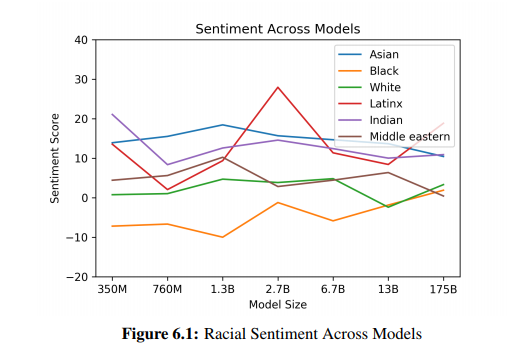
여기서 중요한 것은 실제로 이것이 Asian이 좋고, Black이 나쁘다는 것이 사실이라는 것이 아니라, 사람들이 써놓은 말과 글에서 이러한 편향성을 가지는데 이것이 그대로 언어 모델에 반영이 된다는 것이 중요합니다.
위에 gender, race에 이어서 종교에 대해서도 편향성을 살펴본 표가 있는데 이것 말고도 흥미로운 분석 결과가 많으니까 직접 논문에 들어가 살펴보시는 것을 추천합니다.
이렇게 20페이지 혹은 75페이지에 달하는 GPT-3 논문을 살펴보았습니다. 논문을 읽으면서 굉장히 흥미로운 분석 결과가 많아 재밌게 읽었던 것 같습니다. GPT-3의 성능이 매우 좋아 가능한 분석인거 같아 더 대단하고 부럽기도 합니다.
모델 구조 부분이나 어떻게 학습을 하고, 어떻게 평가를 했는지에 대해서 잘 설명되지 않은 것 같아 아쉬움이 남았는데, 사실 GPT-3에서도 자세히 설명되어 있지 않아서 이 부분은 나중에 GPT-2를 살펴보면서 더 설명하고자 합니다.
+) 여담으로 논문에서는 나와있지 않았지만 GPT-3를 학습시킬 때의 COST가 과연 얼마가 들었는지 궁금하여 찾아봤는데요. OpenAI가 미국 회사인 것을 생각했을 때 달러로 환율한다면, GPT-3 175B를 한번 학습하는데 무려 50억이 든다는 분석 글을 봤습니다….ㅎㅎㅎ 성능이 좋을 수밖에 없는 모델이었네요ㅎㅎ
읽어주셔서 감사합니다.
리뷰 잘 봤습니다.
few shot learning이라는 용어는 처음 접해보는데 사람의 인지과정이랑 비교해서 설명해 주셔서 이해하는데에 수월했습니다.
few shot learning 의 학습 방법에 대해 이해가 조금 가지않는 부분이 있는데요,
training set을 통해서 구분하는 법을 학습 한 뒤에 support set을 사용할 때에는 gradient update를 하지 않는다고 이해하였는데 맞나요 ??
안녕하세요. 댓글 감사합니다.
네 맞습니다. 사실 모든 few shot learning에서라고는 확신해서 말 못하지만 gpt-3에서는 zero shot, one shot, few shot 기법을 사용할때는 gradient update를 하지 않습니다.
안녕하세요 좋은리뷰 감사합니다 nlp 분야에서 태스크의 종류가 궁금하네요. self-training 이후 downstream task에 적용시 잘 안붙는(?, fine turn이나 few shot learning이 적용이 안되는) 현상이 발생하곤 하나요?
그리고 테스크마다 fine turning과 few shot learning 중 어떤 학습법이 좋은지 비교한 실험은 있는지 궁금합니다!
안녕하세요. 댓글 감사합니다.
1) nlp 분야에서는 감정 분석, 요약, 기계 번역, 질문 응답, 문서 분류, 문장 생성 등의 태스크가 있습니다.
2) downstream task에 적용시 잘 안 붙는 상황은 fine-tuning의 경우 labeled 데이터셋이 굉장히 적을 때 발생한다고 하는데, few shot에서는 주로 문서 요약 같은 task에서는 좋은 성능을 못 낸다고 합니다.
3) 이 부분은 gpt-3가 많은 task에서 sota를 달성했다는 것으로 이미 비교하여 실험한 것이라고 생각하면 되는 것이, gpt-3 이전에는 sota를 달성한 모델들이 모두 fine tuning을 이용한 모델들이기 때문에 한 task에 대해서 sota를 달성했다면 그건 이미 fine tuning 모델의 성능보다 좋다는 것으로 받아들일 수 있습니다.
좋은 리뷰 감사합니다. few shot learning을 들어만 봤는데 이번 리뷰를 통해 어느정도 감을 잡을 수 있었습니다. GPT-3같은 경우도 언어 모델에서 굉장히 유명하다는 것만 들어봤는데 이번 기회에 알아갈 수 있었네요.
GPT-3가 다양한 task에서 일반적인 좋은 성능(Generality가 높은)이유는 결국 few-shot learning의 구조를 가져갔기 때문이라 이해하면 될까요?
그리고 중간에 GPT-3가 zero-shot, one-shot, few-shot을 할때는 gradient를 업데이트 하지 않는다고 적혀있는데 이 부분이 잘 이해가 가질 않았습니다. 또한 이미지 분류를 예시로 support set에 대한 설명을 해주셨는데 text를 가지고도 간단하게 설명 가능하실까요?
감사합니다.
안녕하세요. 댓글 감사합니다.
1) 네 맞습니다. GPT-3가 좋은 성능을 내는 이유는 결국 in-context learning을 통해 학습한 것을 inference 단계에서 few shot 기법을 적용하여 더욱 task에 맞는 문장을 뽑아낼 수 있기 때문이라고 생각했습니다.
아마 gradient update를 하지 않는다는 것이 in-context learning에서 이미 데이터들간의 차이를 학습하면서 learn-to-learn 하였고, inference 단에서 문장을 생성해낼때 더 잘 생성할 수 있도록 문장 생성 방향을 설정해주는 것이 few-shot이라고 생각하였습니다.
아무 힌트 없이 문장을 생성했을 때보다 task에 대한 설명과 example을 같이 주면, in-context learning에서 데이터 차이를 학습한 것에서 example과 비교하여 어떤 task인지 이해하고 이 때문에 더 좋은 문장을 생성해내어 좋은 성능을 내지 않았는가 생각합니다. 사실 저도 이 부분이 굉장히 헷갈리는 부분이고, 제 생각이 맞다고 확신할 수 없어 더 정확히 알기 위해서는 GPT-2를 참고해야 할 것 같습니다.
2) text를 가지고 support set을 설명한다면 클래스에 맞는 이미지를 task별 text로 변환하여 ‘사칙연산 문장’, ‘오타 검열 문장’, ‘기계 번역 문장’ 이렇게 구성하지 않을까 생각합니다.