
오랜만에 Active learning 방법론에 대해 제안한 논문입니다. 최근 제가 리뷰했던 논문들은 대개 self-learning 과 합치는 등 AL을 메인으로 제안하는 방법론은 아니었는데요. 바로 리뷰 시작해보도록 하겠습니다.
[ICCV 2021] Influence Selection for Active Learning
Background
Active Learning 이란 라벨링의 비용을 줄이는 것을 목표로 제안된 연구입니다. Unlabeled 데이터셋 중에서 라벨링을 했을 때 더 효과적인 샘플이 무엇인지를 해내는 것인데요. 여기서 효과적이다 라는 기준에 따라서 많은 연구들이 진행되고 있습니다.그 연구의 갈래들 중 현재 가장 활발하게 연구되는 방향은 Diversity 기반과 Uncertainty 기반 연구가 있습니다.
Diversity 기반은 선별하고자 하는 데이터가 다양성을 나타낼 수록 효과적이라고 판단하는데요. Unlabeled 데이터셋을 대표할 수 있는 샘플들을 고르는 연구입니다. 동일한 비용으로 라벨링을 할 때, 클래스 간 중복을 줄이고자 연구가 되고 있습니다.
Uncertainty는 불확실성을 의미하는데요. 모델이 예측하는 확신도가 낮을수록, 쉽게 말해 모델이 어려워할수록 효과적이라고 판단합니다. Uncertainty가 높다는 것은 어떤 클래스에 속할 지 명확하게 판단할 수 없는 그런 샘플을 의미한다고 이해하시면 될 것 같습니다. 보통 결정 경계 근처에 있는 샘플들이 이런 경향을 보이고 성능 저하의 요인이라고 보는 연구들도 있습니다.
Introduction
저자는 Learning Loss 혹은 Coreset 과 같은 Task-Specific 하지 않은 Active learning 방법론이 필요하다고 주장합니다. 즉, Classification, Object Detection 등 다양하게 적용이 가능해야한다고 주장합니다.
Learning Loss는 데이터를 선별하는 모델 아래에 Loss를 예측하는 모델을 추가하여, Loss가 높을 수록 Uncertainty가 높다고 선별하는 방법론입니다. Loss를 기준으로 데이터를 선별하기 때문에 Loss가 있는 어떤 방법론이든 상관없이 적용할 수 있습니다. 그렇기 때문에 task-specific하지 않다고 할 수 있습니다.
저자는 일반적인 알고리즘을 추가로 제안하기 위해 influence 를 사용하였습니다. Influence Selection for Active Learning(ISAL) 이라는 방법론을 제안하였는데요. influence measurement 를 사용하여 데이터 선택 여부를 결정하는 방법론입니다. 자세한 내용은 바로 다음 챕터에서 설명드리겠습니다.
Method
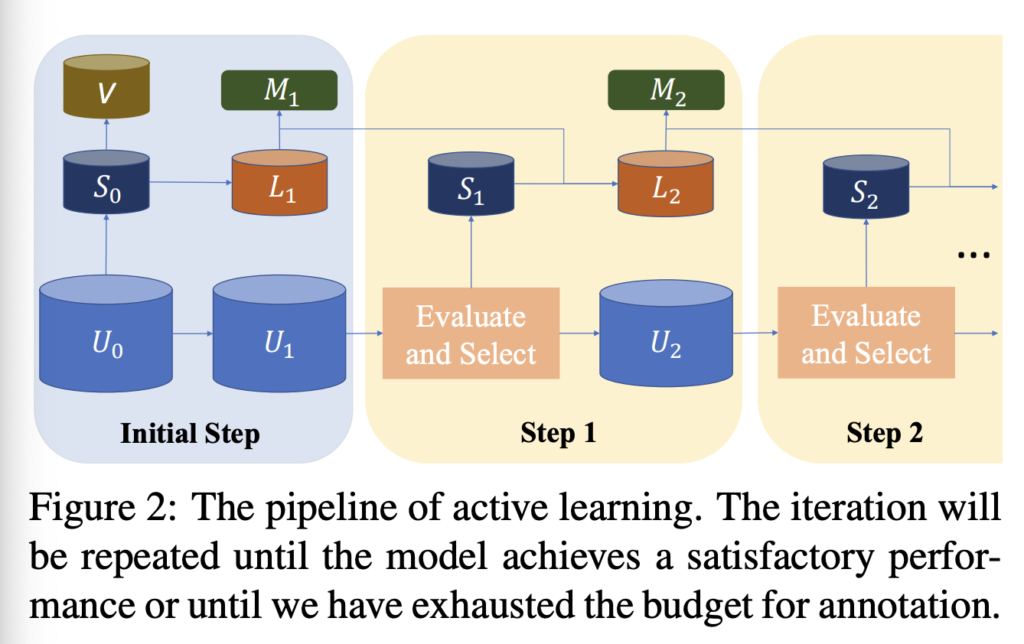
AL의 파이프라인은 상단 그림 2와 같습니다. 우선 데이터를 선별하는 모델을 초기 소량의 Labeled dataset L_0으로 학습 시킵니다. 보통 전체 데이터셋의 10% 미만으로 랜덤하게 선택되는 경우가 많습니다. 그 다음으로 Unlabeled dataset의 샘플들을 학습한 모델의 입력으로 넣어 유용한지 여부를 평가합니다. 이제 그 척도를 바탕으로 가장 효과적인 데이터를 B개만큼 추가합니다. (B는 AL에서 Budget을 의미하며, 라벨링할 수 있는 비용 혹은 예산을 의미합니다) B개의 Unlabeled에 대해 라벨링을 한 다음 L_0에 추가하여 L_1을 만들고 다시 모델을 재 학습시킵니다. 이 과정을 지정된 횟수만큼 반복하는 것이 AL의 파이프라인입니다.
The Influence of an Untrained Sample
저자는 선별할 데이터를 선택하는(각 샘플의 유용성을 판단하는)척도로 Influence를 사용하였습니다. 그런데 특이한 건, 보통 라벨링을 추가한 다음 모델을 재학습시키는데, 저자는 모델을 재학습시키는 것은 시간이 너무 오래걸린다고 지적하였습니다. 따라서 influence function에서 영감을 받아, 언라벨 샘플 z' 의 영향을 Loss 함수에 추가하여 파라미터 변경의 근사치를 구할 수 있었다고 합니다. 그 새로운 파라미터를 다음과 같이 정의할 수 있습니다.![]() 또한 이 모든 것을 반영한 Influence I는 식 (1)과 같습니다.
또한 이 모든 것을 반영한 Influence I는 식 (1)과 같습니다.
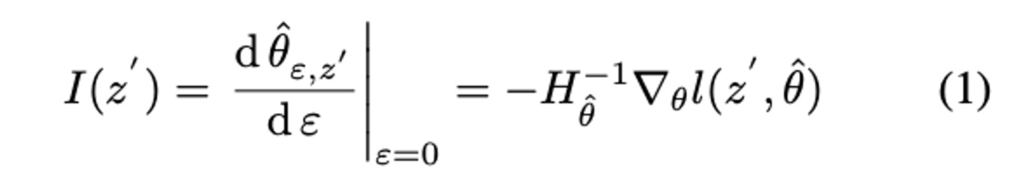
그러나 이 모델의 파라미터 변경은 언라벨 샘플 z'로 인한 모델 성능 변경에는 직접 반영할 수 없습니다. 따라서 Unlabeled 데이터셋인 U_0으로부터 랜덤하게 선택한 뒤 레이블을 추가하였습니다. 이렇게 추가한 Subset을 R이라고 하였으며, 이 R에 대한 Loss 변화에 의해 평가되는 모델의 성능을 고려하기 위해 체인 룰을 적용한 식 (2)를 사용하였습니다.
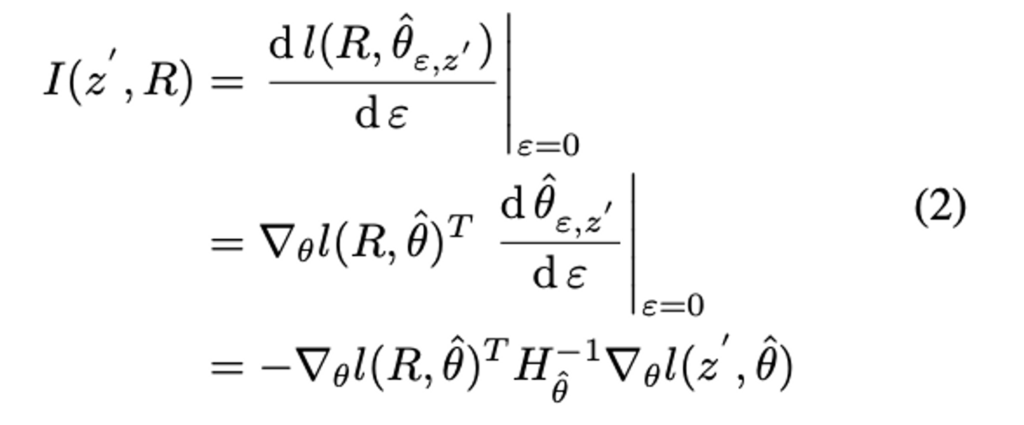
Untrained Unlabeled sample Influence Calculation
이제 Unlabeled 데이터셋의 샘플 z' ∈ U_i에 대해 평가해야합니다. 이를 위해 저자는 Untrained Unlabeled sample Influence Calculation(UUIC)를 제안하였습니다.
우선 저자는 image classification에서의 expected gradient에 집중하였는데요. expected gradient의 가장 직관적인 설계는 Loss를 계산하기 위한 GT로서 posterior probability의 상위 K 클래스를 사용하는 것입니다. 따라서 저자는 Loss를 모델로 backward하고, 클래스 라벨과 관련된 그라디언트를 얻었습니다. 그런 다음 클래스 라벨label_i의 posterior probability 인 pred_i를 backward된 그라디언트를 평균하는 가중치로 사용합니다. expected gradient 인 G_{z'}는 수식 (3)과 같이 정의됩니다.
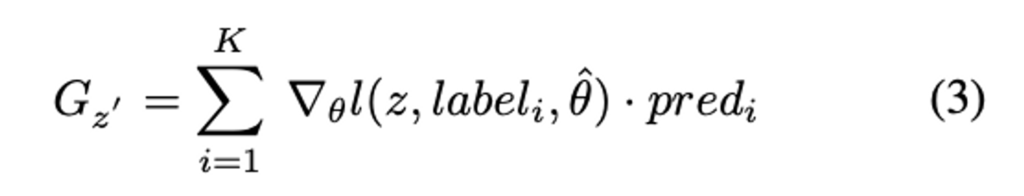
이제 (3)을 고려하여 (2)를 재정의하여 얻은 Influence 수식은 (4)와 같습니다.
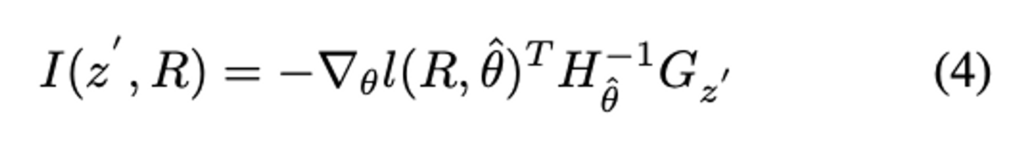
저자가 제안하는 ISAL의 알고리즘은 아래 수도코드를 통해 정리할 수 있습니다.


Experiment
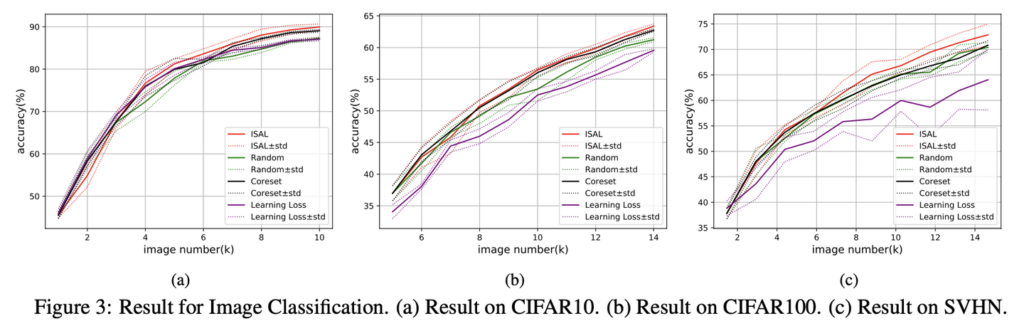
CIFAR10, CIFAR100 그리고 SVHN 에 대한 성능 입니다.
모두 2%의 데이터를 초기 라벨 데이터셋으로 사용하였습니다. 또한 250개의 이미지를 샘플링하였으며, 아래 실험 테이블은 Coreset과 Learning Loss와 비교한 겨로가입니다.
그 결과 CIFAR-10의 경우, Coreset에 비해 12% 효과적이었으며, Random과 비교했을 때, 23% 효과적임을 확인하였습니다. CIFAR-100은 2.9%, 9.3% 의 ㄷ뛰어난 성능 그리고 SVHN도 마찬가지로 12%, 14% 의 우수한 성능을 보였습니다.
Object Detection
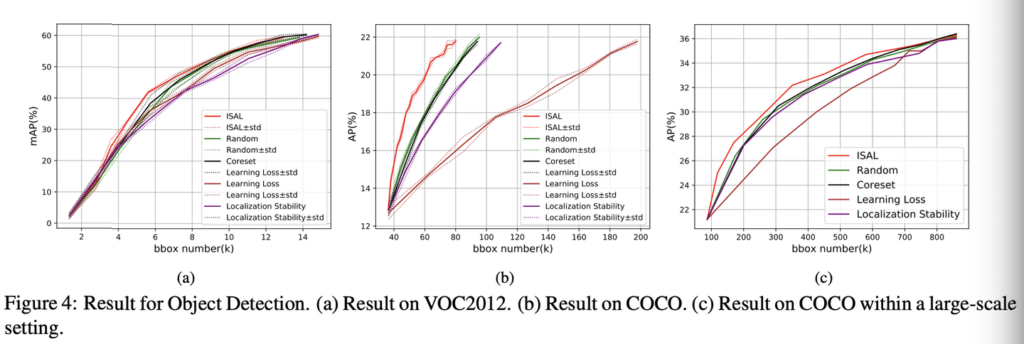
VOC2012, COCO 에 대한 결과입니다. 이 결과 역시 ISAL이 다른 방법론들에 비해 Object Detection 태스크에 적용했을 때 우수한 결과를 보였음을 확인하였습니다.
아래가 정성적 결과입니다. 이를 통해 제안하는 방법론이 타 방법론에 비해 bbox 크기가 더 object에 적합하고, 중복 비율도 더 낮은 결과를 보였습니다.


Conclusion
Influence measure 방식을 적용한 task-agnostic and model-agnostic 한 Active LEarning 을 제안하였습니다. 그 결과 SOTA 성능을 달성하였으며, object detection 에서도 뛰어난 성능을 보이며 AL의 확장 가능성을 확인한 논문입니다.
안녕하세요. 리뷰를 읽는 도중 궁금한게 있어 질문 남깁니다.
리뷰에서 Influence에 대한 언급이 많이 있는데 여기서 influence의 정의가 정확히 무엇인가요? 수식1이 influence를 의미하는 것인가요?
또한 인트로에서는 Learning loss? 라는 기법을 통해 loss가 있는 어떠한 테스크에도 모두 Active Learning이 적용 가능하다는 식으로 내용이 작성된 것 같은데, 갑자기 저자는 왜 influence라는 것을 통해 데이터를 선택하는 것인가요? learning loss로 선택한다는 것이 아니었나요? 아니면 influence라는 것이 learning loss 방식 중 하나라고 보면 되는 것인가요?
좋은 질문 감사합니다.
Influence 함수란 데이터를 극소량으로 업데이트할 때 모델 파라미터가 어떻게 변하는지를 측정하여 학습 샘플의 중요성을 평가하는 것으로 해당 논문에서는 수식 (1)을 influence로 사용하였습니다.
그리고 두번째 Learning Loss는 Uncertainty 기반의 Active Learning 방법론인데, Learning Loss에 Influence를 고려하여 데이터를 선별하는 방식으로 보면 될 것 같습니다