
현재 미래국방 과제에서 Semantic Segmentation task를 진행하고 있습니다.
성능을 개선시켜야 하는데 dataset의 규모가 매우 작아서 한계가 있다고 판단하여
semi-supervised 논문을 찾아서 읽어보았습니다.
그럼 리뷰 시작하겠습니다.
1. Introduction
본 논문은 labeled data말고도 추가적인 unlabeled data를 함께 활용하는
semi-supervised semantic segmentation 방법론을 다루고 있는 논문입니다.
semantic segmentation은 이미지가 주어졌을 때 pixel별로 어떤 class에 속하는지를 분류하는 문제입니다.
해당 task에서 training data를 구성하기 위해서는 아래와 같이 pixel-level로의 labeling 과정이 필요합니다.

하지만 수천장의 이미지를 pixel level로 직접 labeling을 하는것은 시간과 비용적으로 매우 expensive 합니다.
이 때문에 semantic segmentation task 에서의 semi-supervised 방식 적용이 중요한 문제로 대두되고 있습니다.
semi-supervised 방식을 사용하여, labeled data 뿐만 아니라 추가적인 unlabeled data도 함께 사용할 수 있어서 dataset의 양을 많이 증폭시킬 수 있습니다.
Semantic Segmentation 에서 semi-supervised를 적용한 이전 방법론들의 방식으로는 크게 2가지가 있습니다.
첫번째는 Consistency regularization 입니다.
이는 input의 다양한 변화 (perturbation) 에도 일관성 있는 예측을 수행하고자 연구되었습니다.
이미지에 어떠한 변환을 주어도 최종적으로 유사한 예측값을 출력해야 한다는 가정 하에 unlabeled image를 사용하는 것입니다.
두번째는 Self-training 입니다.
이는 labeled image로 network를 학습시킨 뒤에, unlabeled image가 예측한 결과를 pseudo label 삼아서 training 하는 방식입니다.
2. Method
본 논문에서는 새로우면서도 간단한, network perturbation을 통한 consistency regularization 방식을 소개합니다.
이름은 cross pseudo supervision 이라고 칭합니다. 줄여서 CPS 라고 표기합니다.
사실 모델 그림은 method에서 설명 하려고 했지만, 이해를 돕기 위해 미리 그림을 첨부하겠습니다.
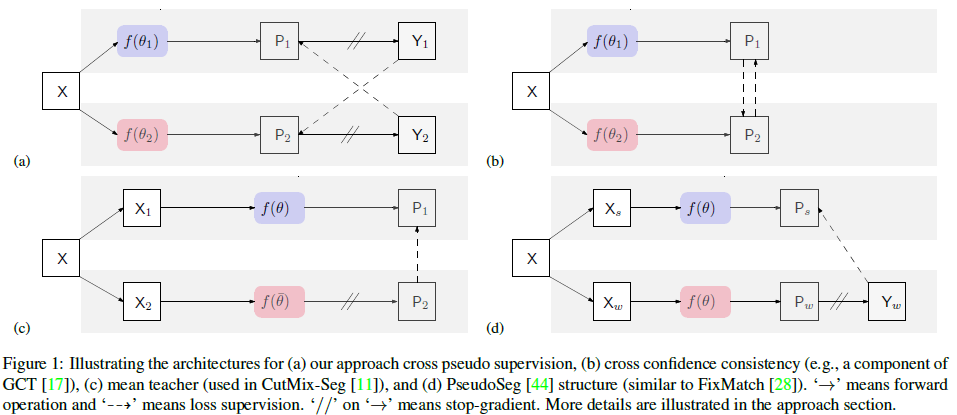
본 논문이 제안하는 방식은 Fig.1 의 (a) 에 해당합니다.
X라는 input이 2개의 segmentation network로 각각 들어가게 되는데,
이 2개의 networks는 동일한 구조를 가졌지만, initialize는 다르게 진행합니다.
해당 모델의 경우 input으로 들어간 이미지는 두개의 네트워크 f(\theta_1), f(\theta_2) 를 거쳐서 각각 P_1, P_2 를 예측합니다. 이는 softmax를 통과한 segmentation confidence map 으로 예측하고자 하는 class의 수 (ex. 차,사람,개,,,) 만큼의 채널을 가진 확률맵 입니다.
그리고 P_1, P_2 로 부터 one-hot encoding을 수행해서 특정 class로 매핑한 결과가 pseudo segmentation map 이라고 불리는 Y_1, Y_2 입니다.
그런데 여기서, semi-supervised 에는 labeled 와 unlabeled data 가 모두 사용된다고 하였습니다.
labeled image 같은 경우 위의 과정을 통해 예측된 P_1, P_2 와, GT인 Y^*_1, Y^*_2 사이에서 픽셀별로 cross-entropy loss가 아래 식을 통해서 계산됩니다.
참고로 loss 식에서는 CxHxW의 shape을 가지는 P_1 을 p_{1i} 와 같이 채널축 vector로 표현하였습니다.
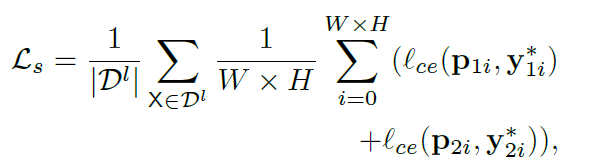
위 식에서 D^l 은 labeled data의 집합을 의미하고, 해당 loss를 supervision loss인 L_s로 명칭하였습니다.
그럼 unlabeled image의 경우엔 어떤 loss가 적용될까요?
이 경우에 본 논문의 핵심인 cross pseudo supervision이 적용됩니다.
모델 구조는 동일하고, 다르게 초기화된 network인 f(\theta_1), f(\theta_2) 에 각각 unlabeled image 가 들어가게 되고, 최종적으로 pseudo segmentation map인 Y_1, Y_2 가 예측되게 됩니다.
한 쪽에서 예측된 pseudo segmentation map를 사용해 반대쪽 segmentation network를 supervision 합니다.
다른쪽 모델의 pseudo label이 된다고 생각하시면 됩니다. 모델 그림을 보시면 점선 화살표를 보실 수 있는데, 해당 화살표가 서로 cross 되어서 표기된 것이 보이실겁니다. loss 계산은 아래와 같습니다.
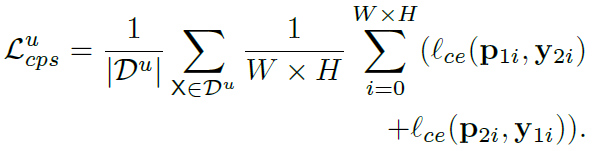
식은 쉽게 이해하실 수 있을것이라 생각됩니다.
그런데 해당 loss를 unlabeled image 뿐만 아니라 labeled image 에도 적용을 했더군요.
굳이??? 라고 생각이 들었지만, ablation study 에서 이를 다루고 있었고, 둘다 사용한 방식이 미세하게 성능이 높은것을 확인할 수 있었습니다.
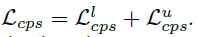
이런식으로 L_{cps} 를 구성해주고,
최종 loss 는 아래와 같습니다.
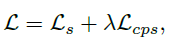
저자는 이런 cross pseudo supervision을 통해서, 동일한 input image에 대해 서로 다르게 초기화된 network에서 예측이 일관된 형태로 나오고, prediction decision boundary가 low-density regions 에 위치하도록 한다고 합니다.
사실 이 부분에서 low-density regions 에 대한 내용은 정확히 이해를 하지 못하였습니다..ㅜ
3. Experiment
본 논문에는 다양한 실험들이 많이 존재합니다.
대부분의 실험 table에서 저자는 Cutmix Augmentation 이라는 기법을 적용한 성능을 함께 리포팅합니다.
Cutmix Aug 란 classification 논문에서 제안된 augmentation 기법인데,
이를 2020년에 한 저자가 Cutmix-Seg 라는 모델을 제안하면서 segmentation task에도 해당 augmentation 기법을 적용하였습니다.
본 논문의 저자는 이 Cutmix Aug 기법을 적용해서 모델을 좀 더 강인하게 학습시켰고, 성능으로도 이를 보여주고 있습니다.

Cutmix Aug의 방식은 위와 같습니다.
box가 1개인 경우와 3개인 경우로 나눠지는데, 이미지 A와 B를 binary mask로 구분해서 겹쳐주는 방식입니다.
GT도 해당 mask에 맞춰서 겹쳐지겠지요.
또한 본 논문의 실험에서는 Ours 방법론과 비교가 진행되는 여러 방법론들이 있습니다.
해당 방법론들은 semi-supervised semantic segmentation에서 좋은 성능들을 내고 있는 방식들입니다.
해당 방법론들에 대해 간단하게 설명을 드리겠습니다.
(1) CCT(Cross-Consistency Training), GCT(Guided Collaborative Training)
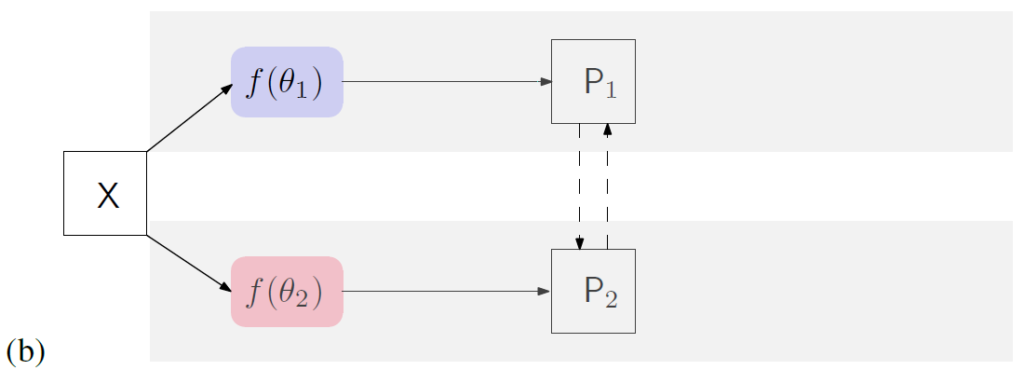
두 방식은 위 (b) 의 모델 구조를 따릅니다.
각 모델에 의해 예측된 확률(probability) 를 cross 방식으로 비교를 합니다.
해당 방식에서는 one-hot vector의 비교가 아닌, 확률값 끼리의 L2 loss로 비교합니다. 아래와 같습니다.
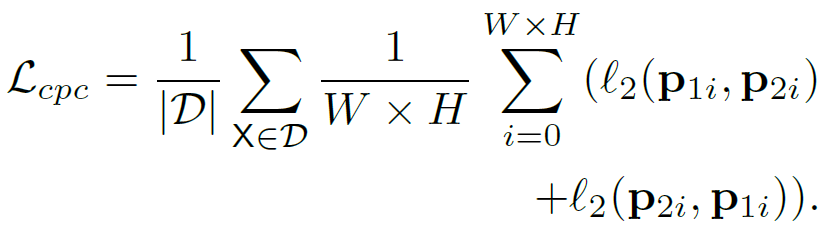
(2) MT(Mean Teacher), CutMix-Seg
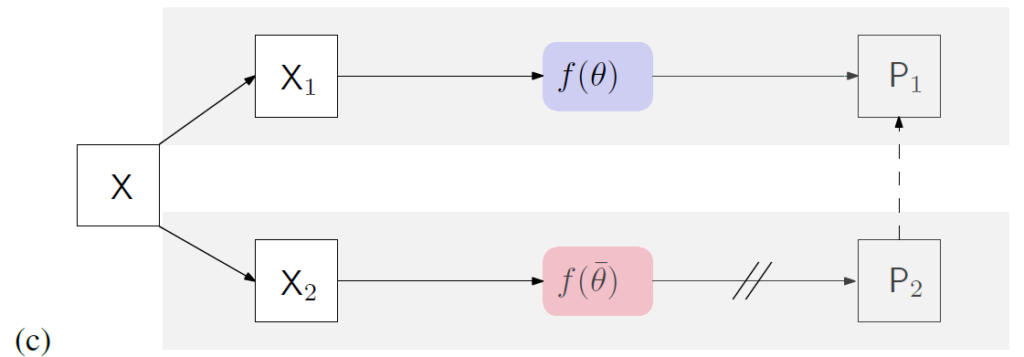
두 방식은 위 (c) 의 모델 구조를 따릅니다.
각 모델에는 서로 다른 augmentation이 적용된 image가 각각 들어가게 됩니다.
두 모델중 f(\theta) 는 student를, f(\bar{\theta}) 는 mean teacher 를 의미합니다.
두 모델은 동일한 구조를 가지고 있으며, f(\bar{\theta}) 의 화살표에 표기된 // 표시는 stop gradient 를 의미합니다.
다시말해, teacher model은 학습이 진행되지 않는다는 말이고,
student model의 \theta 는 학습을 진행하면서 파라미터\bar{\theta}의 평균을 향해 가까워집니다. 그래서 이름을 Mean Teacher라고 정한 거 같습니다.
CutMix-Seg 는 해당 방식의 augmentation 기법으로 앞서 말한 Cutmix Segmentation 을 적용 한 방식입니다.
실험의 서론이 너무 길었습니다.
아래 Table은 각각 PASCAL VOC 2012와 Cityscapes dataset 에 대한 실험 결과이고,
모델 backbone을 ResNet-50과 ResNet-101로 구분지어서 실험을 진행하였습니다.
또한 본 논문은 semi supervised의 효과적인 학습 방법만 제안했지, 뭔가 특정 모델을 제안한 것은 아닙니다.
본 논문에서는 network로 ImageNet에서 pretrained된 DeepLabv3+ 라는 모델을 사용하였습니다.
그리고 각 columns을 보시면 1/16, 1/8,, 이런식으로 분수 값이 보이실겁니다.
해당 값은 semi supervised의 효능을 알아보기 위해 기존의 전체 labeled dataset중에서 실제로 사용된 labeled의 비율을 나타낸 것입니다.
예를들어 Cityscapes 같은 경우 전체 train images는 2,975 장인데,
1/16 (662) 의 경우 662장에 대해서만 GT를 사용하고, 나머지 15/16에 대해서는 GT 사용 없이 unlabeled data인 것처럼 실험을 진행 한 것입니다.
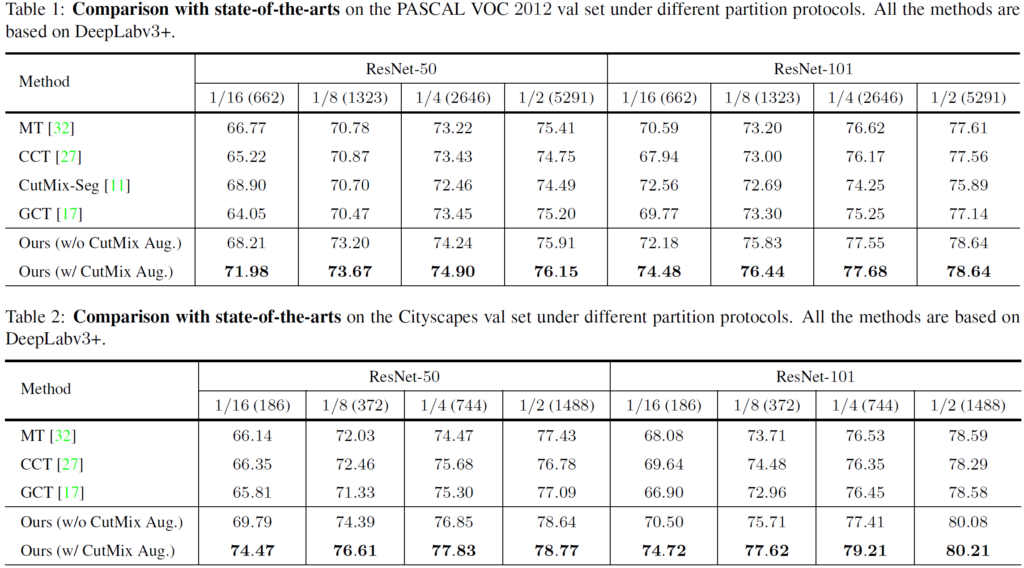
결과를 보시게 되면 모든 비율에 대해 성능이 높게 나온것을 볼 수 있습니다.
그리고 추가적으로 초점을 둬야 할 부분이 있는데, 바로 Ours 방식에 CutMix Seg의 적용 유무에 대한 성능 변화입니다.
labeled data의 비율이 적을수록 CutMix Seg 를 적용했을 때 성능의 향상폭이 더 큰 것을 확인할 수 있습니다.
이를 통해, train data가 적은 실험을 진행할 때 CutMix Seg를 적용한 semi supervised 학습방식을 통하여 성능 개선을 할 수 있을 것이라 기대할 수 있습니다.
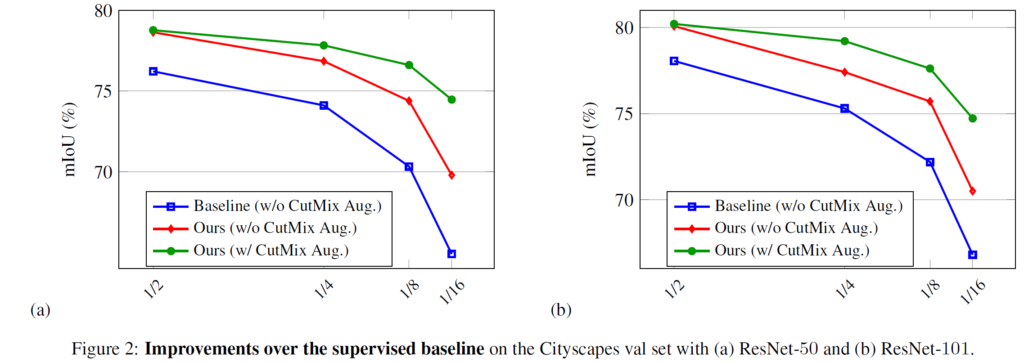
저자는 이를 그래프로도 시각화하여 보여주고 있습니다.
X축의 우측으로 가면서 labeled data의 비율이 적어질수록, CutMix Aug의 적용에 따른 성능향상의 폭이 더 커지는 것을 확인할 수 있습니다.
물론 절대적인 성능 자체는 당연히 labeled data의 비율이 큰 쪽이 좋은것도 확인 가능합니다.
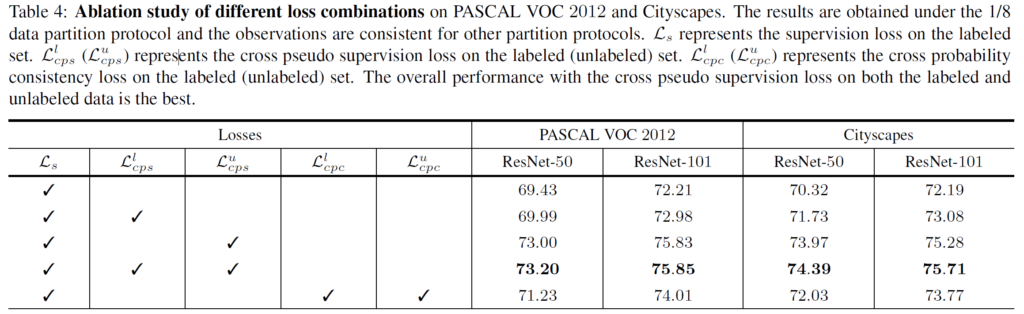
그리고 앞선 Method의 loss 설명에서,
L_{cps} 를 굳이 labeled data에 적용을 했을까 라는 의문이 들었다고 언급했었는데,
이에 대한 Ablation으로 저자는 해당 효과를 보여주고 있습니다.
물론 성능 향상에는 L^l_{cps} 보다 L^u_{cps} 이 더 효과적인 것을 볼 수 있지만,
L^l_{cps} 를 적용했을때 미세한 성능향상이 있긴 하므로 본 논문에서 loss로 함께 사용했다고 합니다.
또한 CCT(Cross-Consistency Training) 방식에서 사용하는 L_{cpc} 도 적용해봄으로써,
본 논문에서 제안한 L_{cps} 가 더 효과적이라는 것을 성능적으로도 보여주고 있습니다.

그리고 PASCAL dataset에서의 정성적인 평가입니다.
(c) columns의 경우 labeled image로만 학습한 supervised 의 결과인데,
labeled training samples의 한계로 인해 결과가 뭉개지는 것을 볼 수 있습니다.
그에 반해 (d)는 좋은 결과를 보여주고 있고,
이에 Cutmix Aug를 적용한 (e)는 오차율이 더 낮은것을 볼 수 있습니다.
본 논문에서는 기존 방식에서 간단한 변경을 하였지만 성공적인 성능 향상을 보여주었고,
기존의 CutMix Aug 방식의 적용을 통해 더 높은 향상을 보여주었습니다.
사실 모델적인 부분에서는 참신하다는 느낌을 받지는 못하였지만, 매우 다양하고 많은 실험들을 리포팅하고 있어서 해당 부분은 좋았던 논문이였습니다.
제가 읽으면서 의문이 들었던 부분들이 모두 다 Ablation에 들어 있을 정도니까요,.,ㅎㅎ
이 밖에도 제가 리포팅하지 못한 실험들이 더 많이 존재하므로, 관심있으신 분들은 간단하게 읽어 보셔도 좋을 거 같습니다.
Semi-Supervised 와 관련된 논문은 처음 접해봤는데 양질의 dataset 구축이 힘든 thermal 환경의 task들에 효과적으로 적용이 가능할 수도 있겠다는 생각이 드네요.
그럼 이것으로 리뷰 마치겠습니다. 감사합니다.
안녕하세요 좋은 리뷰 감사합니다. input의 다양한 변화 (perturbation) 에도 일관성 있는 예측을 수행하도록 학습했다고 하셨는데 perturbation 종류가 궁금합니다. 실험에서는 cutmix를 사용한 것 같은데 다른 augmentation 방법도 실험되었나요? 감사합니다
Semantic Segmentation에서 semi-supervised를 수행 한 방법론들은 모두 서로 조금씩 다른 perturbation을 수행합니다. input images를 augmentation 하는 방법이라던가, network에 각기 다른 perturbation을 수행한다던가, 혹은 feature에도 perturbation을 부여하는 경우도 있습니다.
본 논문에서 cutmix 말고 다른 augmentation을 적용한 실험은 없는거 같네요.
감사합니다.
안녕하세요 권석준 연구원님. 리뷰를 읽으면서 주말에 모델이 이상하다고 설명하던 모습이 떠오르네요. 혹시 그때 설명한 pseudo-label을 만들기 위한 베이스라인 방법론으로는 이 논문 쓰신건가요? Cityscape에 대한 정성적인 결과가 리뷰에는 없는데, 아직 그 문제를 해결 못하셨다면…. pseudo-label이 잘 만들어지는지도 확인을 좀 해보는 것이 좋을 것 같습니다. 성능상으로는 잘 나오는데, 특정 클래스에서 예측을 못하는 문제가 거기에도 있지 않을까 싶네요.
아 pseudo-label 만드는 논문은 HRNet을 기반으로 만들어 진것입니다. 해당 논문과는 관련이 없습니다!! 그리고 본 논문에서 정성적인 결과는 PASCAL VOC 밖에 존재하지 않네요,,,
그리고 주말에 간단하게나마 말씀드린 ‘특정 클래스에서 예측을 못하는 문제’ 는 pseudo-label을 사용하는 모델이 아닌 GT를 통해 supervised 로 학습 한 모델입니다. GT 를 통해 학습을 시키는데 그런 현상이 나타나니 더 미칠 지경이네요 ㅎㅎ
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다. 모델 부분에서 참심성을 받지 못다고 하셨지만 오히려 저는 간단한 방법으로 손쉽게 semantic segmentation하는 것 같아 더 좋았던 거 같습니다ㅎㅎ Cutmix Augmentation도 알 수 있어 좋았습니다. 논문의 주요 contribution이 CPS와 cutmix aug인거 같은데 cps에 cutmix aug를 적용한거랑 안한거 비교 말고 cps가 아닌 다른 방법론에 augmix 적용했을 때 cps에 cutmix aug를 적용했을 때의 성능 비교는 없었을까요?
저도 주연님의 말에 공감하는 부분도 있습니다. 물론 참신성을 받지 못했다고 하긴 했지만 제가 감히 판단할 부분이 아니라고 생각하면서도, 심플하고 컴팩트한 방법으로 성능 향상을 이루어 냈으니 오히려 좋아보이기도 하네요.
질문주신 실험은 아마 Table1 을 보시면 될 거 같습니다. 3번째 row 에 있는 CutMix-Seg 모델같은 경우 Cutmix Augmentation이 적용된 모델입니다. 해당 부분과 ours+cutmix seg 와의 비교가 아마 주연님이 질문 주신 실험인 거 같네요.
감사합니다.
비디오 분야에서도 서로 다른 RGB와 optical flow가 각각 pseudo label을 만들어내고 서로 cross supervision 하는 방법론이 있었는데, 더 이전부터 존재하던 방법론이었네요.
마지막 정성적 결과의 (c)에서 labeled data만을 사용하였기 때문에 한계가 드러났다고 하셨는데, 정량적 결과에서 labeled data 비율을 높여갈 수록 성능이 좋아지는 것과는 반대의 경향을 보이는 것 같습니다. (c)는 labeled data를 어떻게 사용한 결과인건가요?
마지막 정성적 결과에 대한 실험 세팅이 논문에 정확하게 언급되어 있지 않아서 저도 논문을 읽던 당시 고민을 좀 했던 부분인 거 같습니다.
해당 실험은 아마 ours 방법론을 통해 semi-supervised training을 진행했을 때의 효능을 보여주고자 한 실험일겁니다. 예를들어 (c)의 경우 labeled data 200장을 사용했을 때의 결과라면, (d),(e)의 경우는 labeled data 200장 + unlabeled data 500장을 사용한 뭐 이런 경우겠지요.
안녕하세요 권석준 연구원님, 좋은 리뷰 감사합니다.
사람이 라벨링하지 않는 방법론들을 찾아보다가 해당 리뷰를 읽게 되었습니다. 지금까지 라벨링이 잘 된 데이터셋만 사용하다가, 모델이 라벨링을 도와주는 semi-supervised learning을 접하니 신선했습니다. 특히 두 모델이 서로의 예측값을 GT로 사용하면서 학습하는것이 저에게 굉장히 참신하게 느껴졌습니다.
self-training 방법에서 ‘labeled image로 network를 학습시킨 뒤에, unlabeled image가 예측한 결과를 pseudo label 삼아서 training 하는 방식’ 이라고 되어있는데, unlabeled image가 예측한 결과를 pseudo label 삼아서 training하게 되면 결국 모든 예측값을 다음 GT로 사용하게 되는건가요? 그렇게 되면 사람이 원하는 정답에 대한 정보가 더 이상 모델에 제공되지 않고 잘못된 방향으로 계속 학습해 나갈 수도 있을 것 같은데, 이렇게 학습해도 유의미한 학습이 되는것인지 궁금합니다.
사실 해당 논문의 핵심이 Self-training은 아닐 뿐더러, 제가 self-training 관련 원론적인 논문을 읽어보지 못해 정확하게 대답은 못 드릴 수 있습니다.
제가 알기로 Self-training은 labeled data와 unlabeled data가 함께 있는 상황에서 동작합니다. 우선 labeled data에 대해 미리 학습을 시키고, unlabeled data에 대한 예측을 수행한 뒤 그 중 높은 정확도(신뢰도) 를 가지는 녀석 일부를 labeled data pool에 추가해서 점점 labeled data pool을 늘려 나가는 것으로 알고 있습니다.
질문하신 내용에 답변을 드리자면, 사실 semi&un -supervised 상황에서 어쩔수 없이 들 수 있는 의문점입니다. 그런데 더 많은 이미지를 활용해야 하고, label이 존재하지 않으니 어쩔수 없이 pseudo label을 설정하는 것이죠.
그리고 이미 labeled dataset에 대해 학습된 녀석을 가지고 pseudo label을 생성하는 것이기에 엉뚱한 예측을 진행하지는 않습니다. supervised에 비해 성능이 떨어지긴 하겠지만요.
더 자세한 내용은 논문이나 구글링으로 공부해보시면 좋으실 거 같습니다.