제가 이번에 리뷰 할 논문은 VIO(visual-inertial odometry)에서 두 센서의 동기화가 맞지 않을 경우 어떻게 이를 파악할지에 대해 서베이를 하다 읽게 된 논문입니다. uncertainty라는 조금 낯선 개념을 키워드로 찾게 된 논문으로, 센서의 예측값을 신뢰할 수 있는 지를 uncertainty라고 생각하고 리뷰를 읽으시면 될 것 같습니다.
1. Abstarct
여러 센서를 통합하는 것은 각 측정값에 대한 불확실성에 의존하는 것으로, 적절한 covariance(공분산을 통해 센서의 예측값들의 상관관계를 추정하는 것으로, 여기서는 불확실성과 연결하여 이해하시면 될 것 같습니다.) 추정을 통해 센서 간의 신뢰도의 균형을 유지하는 것이 중요하다고 합니다. 최근의 학습기반 방법론에서는 지도학습 방식으로, 단일 센서에 대한 불확실성을 모델링하는 연구들이 이루어졌고, 해당 논문은 비지도학습 방식으로 서로 다른 센서간의 불확실성의 균형을 맞추는 연구를 수행하였다고 합니다. 이때, IMU센서에 대하여 불확실성을 학습하는 방식을 제안하였고, 가혹한 환경을 모방한 데이터 셋을 통해 잘 작동하는지를 검증하였다고 합니다.
2. Introduction
전통적으로 SLAM은 불확실성은 고려하지 않고, 일정한 covariance를 이용하였다고 합니다. 하지만 이렇게 불확실성을 배제한 방식은 dynamic한 물체나 불연속적인 빛과 같이 변화에 취약했다고 합니다. visual odometry에 연구가 진행됨에 따라 데이터의 불확실성을 고려하는 것이 점차 중요해졌고, 이미지가 CNN을 통과해 covariance를 알아내는 연구, end-to-end로 uncertainty를 알아내는 연구 등이 이루어 졌다고 합니다. 또한, IO(Inertial-odometry)에서도 uncertainty를 이용하는 연구가 이루어졌다고 합니다.
하지만, 단일 센서에 대한 uncertainty는 그대로 멀티 센서의 상황에 적용할 수 없고, 이러한 멀티 센서의 상황에 대해서는 센서를 선택적으로 사용하는 방식으로 연구가 이루어 졌고, 저자들은 센서를 선택하는 것이 아닌, covariance를 이용하여 적절하게 균형을 잡는 방식에 대한 연구를 하였다고 합니다.
저자들은 VIO에 맞도록 uncertainty를 모델링하였다고 합니다. VO에 레이어를 추가하여 covariance를 추정하였고, VO에 대한 unsupervised loss를 제안하였다고 합니다. 또한, IO에 uncertainty를 도입하여 VO와 적절히 균형을 이루도록 하였다고 합니다.
이 논문의 cotribution을 정리하면 다음과 같다고 합니다.
- uncertainty 값의 상대적 크기가 적절히 균형을 잡는 방식을 제안하여 서로 다른 센서들이 학습된 uncertainty를 통해 적절히 융합되도록 함.
- 비지도 기반의 uncertainty 학습 방식을 제안하여 GT의 mean과 covariance가 없어도 가능하도록 함.
- 균형 잡힌 uncertainty가 강인하게 작동하는 지를 가혹한 환경에서 실험적으로 확인함.
3. Unsupervised Uncertainty Learning for Visual and Inertial Odometry
A. Unsupervised Uncertainty Learning
uncertainty는 aleatoric(임의적인)과 epistemic(지식에 관한) 두가지 타입이 존재한다고 합니다. 이에 대해 aleatoric이란 데이터 기반으로 정해지는 것, epistemic이란 사전에 알고 있는 지식을 통해 정해지는 것으로 이해하시면 될 것 같습니다. 이 논문에서는 데이터를 기반으로 하는 aleatoric 타입에 관한 uncertainty에 집중하였다고 합니다.
1. Indirect supervised uncertainty learning
- 센서의 uncertainty는 알 수 없고, GT의 평균 값만 알 수 있는 경우.
- 아래의 식(1)을 loss함수로 이용하며, ||.||^2_\Sigma는 마할라노비스 거리를 의미
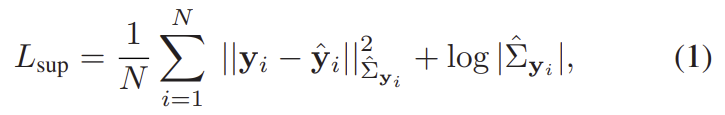
2. Fully unsupervised uncertainty learning
- 센서의 uncertainty 뿐만 아니라 GT의 평균 값도 알 수 없는 경우.
- 식(1)을 변형한 식(2)를 loss함수로 이용하며, gt였던 \mathbf{y}가 센서의 측정값인 \mathbf{z}=g(\mathbf{x})(g는 입력 데이터를 측정값으로 바꿔줌), 예측값인 \mathbf{\hat{y}}가 \mathbf{\hat{z}}=(\mathbf{x},\mathbf{\hat{y}})(h는 입력 데이터를 모델의 예측 값으로 바꿔줌)로 바뀌어 사용됨.
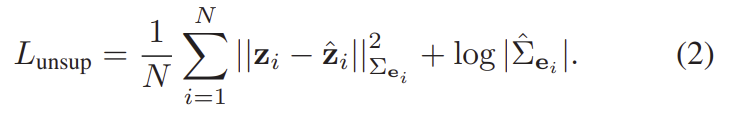
식(2)를 이용할 경우, 측정값과 예측값에 대한 항이 모두 포함되게 됩니다. (VONet의 경우측정값은 VONet을 구성하는 DepthNet과 PoseNet에 입력 데이터가 들어갔을 때 결과를, 예측값이란 VONet의 출력인 pose를 의미함.)
3. Training via covariance balanceing
- 학습 과정에 두 센서에 대한 uncertainty를 적절하게 조절하는 과정으로, 이에 대한 내용은 뒤의 4절에서 다시 자세하게 다루겠습니다.
B. Learning-based VO
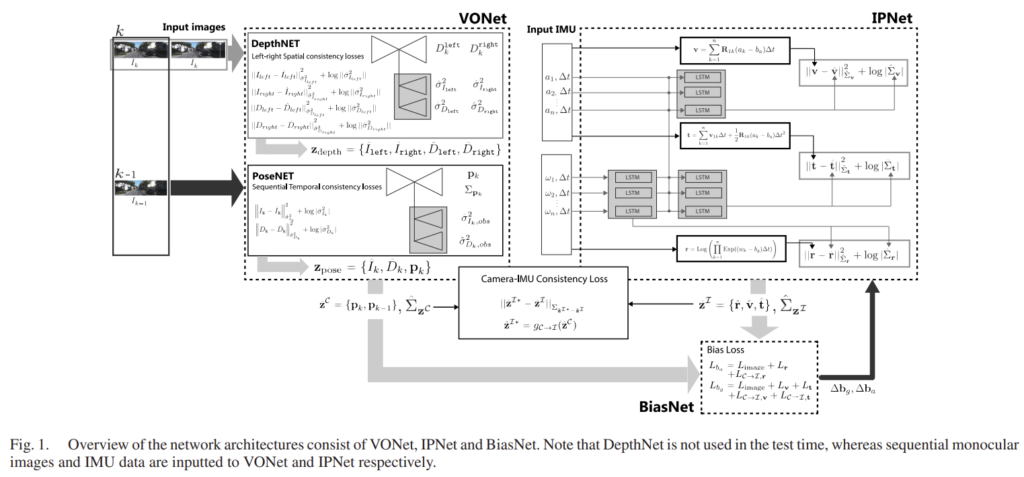
그림1의 VONet에 해당하는 내용으로, DepthNet과 PoseNet 두가지로 이루어져 있으며, 상대 pose를 학습하는 것을 목표로 합니다.
DepthNet은 stereo 이미지를 입력으로 하며, right 이미지가 source, left 이미지가 target이 됩니다. PoseNet은 연속적인 프레임의 이미지를 입력으로 하며 k-1번째 프레임이 source, k번째 프레임이 target이 됩니다.
여기서 DepthNet과 PoseNet이 위의 수식(2)의 측정값h가 되며 수식적으로 표현하면 다음과 같습니다.
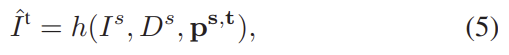
이때 그림1의 VONet 안의 회색 박스 부분이 추가된 uncertainty learning 네트워크로 VarianceNets라 하며, (i) FCLayer들로 구성된 (ii)decoder입니다. 이 네트워크는 pose 추정치의 uncertainty \Sigma_\mathbf{p}를 추정합니다.
이때 PoseNet의 loss는 L_{image}, DepthNet의 loss는 L_{depth}로, L_{image}에 대한 식인 아래의 식(6)에서 이미지I를 depth 이미지D로 바꿔준 식을 loss로 이용한다고 합니다.
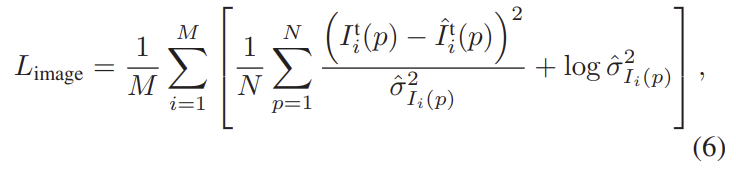
Uncertainty in VO
이처럼 loss들은 uncertainty를 포함하고 있고 학습 과정을 통해 uncertainty를 학습하게 됩니다. 아래의 그림은 이미지에 대한 uncertainty를 표시한 것으로, 빛 반사와 같이 일반적이지 않은 경우나 occlusion이 발생한 경우, 움직이는 물체가 있는 경우에 대해 높은 uncertainty를 나타내는 것을 확인할 수 있습니다.

C. Learning Based IMU Preintegration
IMU Measurement
네트워크에 입력되는 값은 각속도\mathbf{\omega}와 가속도\mathbf{a}로, IMU에 대한 측정값은 \mathbf{z}^{\mathcal{I}}= \left\{ \mathbf{r}^\top, \mathbf{v}^\top, \mathbf{t}^\top \right\}로 각각 rotation, velocity, translation을 의미하며 아래의 식을 통해 구할 수 있습니다.
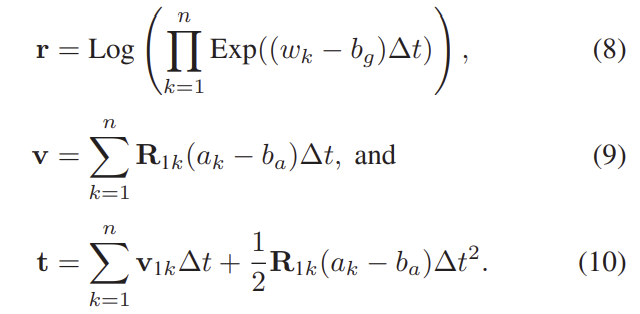
이때 rotation 벡터 \mathbf{r}_{1k}로부터 \mathbf{R}_{1k}=Exp(\mathbf{r}_{1k})가 되며, b_a, b_g는 각속도와 가속도에 대한 bias값을 의미한다고 합니다.
IPNet(IMU Preintegratin Net)을 학습하기 위해 rotation과 속도, translation에 대한 loss는 식(2)를 이용하여 loss를 구하고 학습을 진행합니다. 또한 IPNet은 LSTM을 이용하며, 네트워크의 출력은 예측값인 \mathbf{\hat{r}}, \mathbf{\hat{v}}, \mathbf{\hat{t}}와 covariance값인 \mathbf{\hat{\sum}_r}, \mathbf{\hat{\sum}_v}, \mathbf{\hat{\sum}_t} 가 됩니다.
4. Uncertainty Balancing in Sensor Fusion
balancing 단계는 크게 2단계로 이루어집니다. 우선, 센서간의 일관성을 이용하여 VONet과 IPNet으로부터 구한 uncertainty의 균형을 잡고, 그다음 BiasNet을 통해 IMU의 bias항을 예측합니다.
1) Uncertainty Balancing Via Intersensor Consistency
먼저, 상대적으로 불확실성의 균형을 맞추는 단계로 카메라에 대한 측정값은 모달리티 transfer 함수인 \mathcal{g_{C→I}(.)}를 통해 IMU의 측정값과 동일한 형태로 변환합니다.
\mathbf{z}^{\mathcal{I}*}= \left\{ \mathbf{r*}^\top, \mathbf{v*}^\top, \mathbf{t*}^\top \right\}미리 학습이 된 VONet과 IPNet는 BiasNet를 통해 VO와 IMU의 uncertainty를 균형을 잡도록 학습한다고 합니다. 이에 대한 loss는 아래의 식(13)으로 정의됩니다.
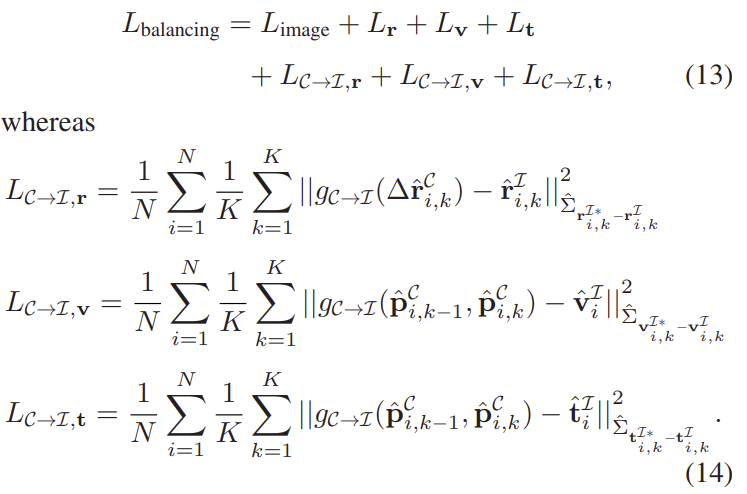
2) BiasNet Training
이 과정은 IPNet이 GT를 이용하지 않는 self-supervised 방식으로 학습이 되었기 때문에 balancing loss를 이용하여 각속도와 가속도에 bias를 주어 조정하도록 하는 과정입니다. 각 bias는 아래의 식을 통해 loss를 구하게 됩니다.
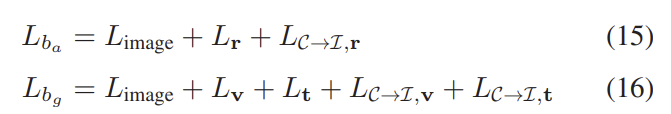
BiasNet의 입력은 (모달리티 transfer 함수를 통해 변형된 카메라에 대한 측정값) – (IMU의 측정값) 입니다.
5. Experiment
KITTI odometry 데이터 셋과 KAIST urban 데이터 셋을 이용하여 제안한 방법론을 평가하였습니다.
Qualitative Evaluation
** 그림이 작고 잘 안보일 경우 논문에서 이미지를 직접 확인해주세요!
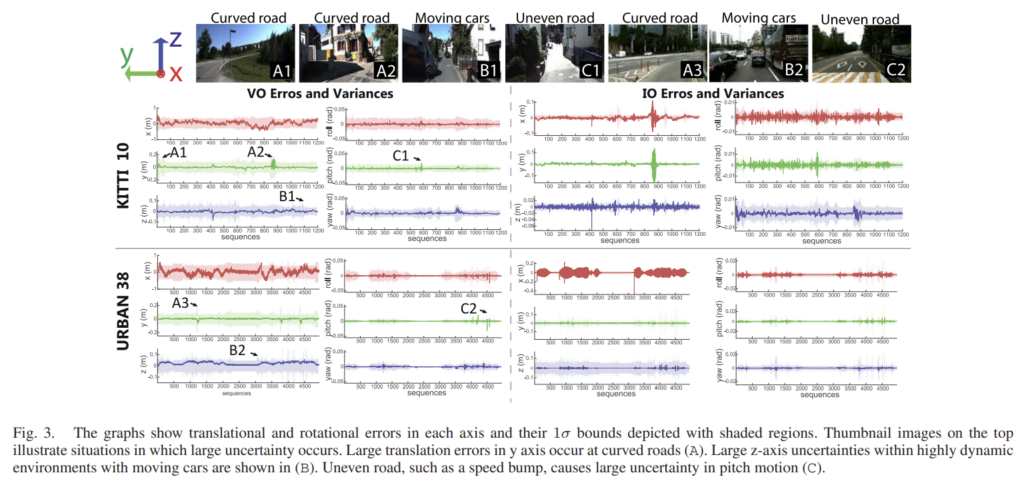
위의 그림3은 학습된 uncertainty에 대한 결과로, 진한 선이 error를 나타내고 주변색이 variance(uncertainty)를 나타내는 것으로 이해하였습니다. 그래프를 통해 오류가 클수록 대체로 큰 불확실성을 가진다는 것을 확인할 수 있다고합니다. 또한, x축에 대한 오차가 대체로 크기 때문에 불확실성도 x축에서 크게 나타났다고 합니다.
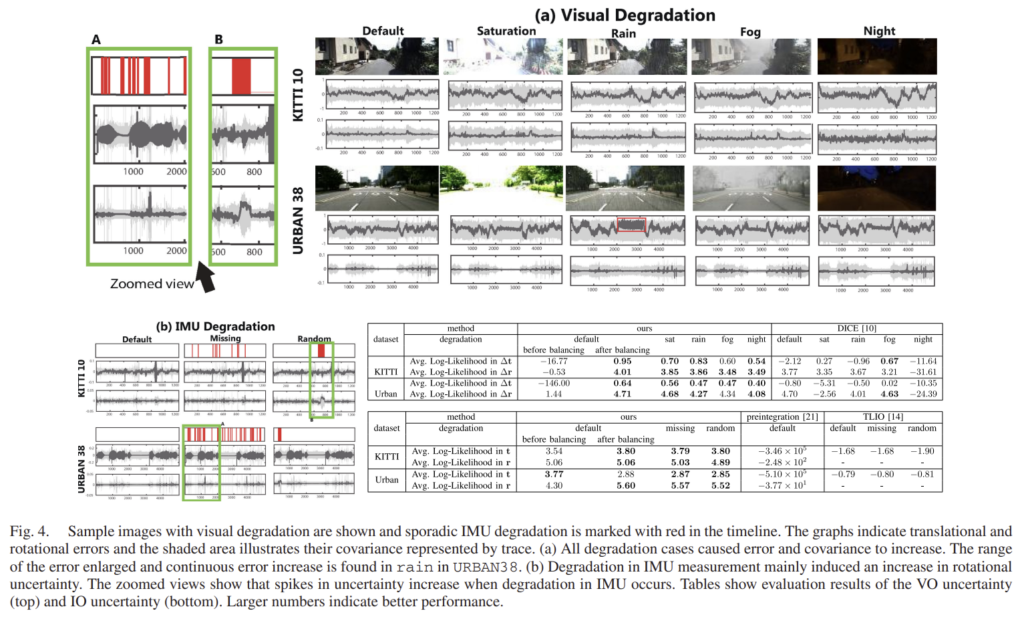
그림4는 다양한 센서 성능 저하에 대한 정성적 결과를 나타낸 것이라 합니다. (a)는 시각적 센서의 성능이 떨어진 경우로 오차가 커짐에 따라 covariance가 대체로 커졌고, 이는 불확실성이 높아졌다는 것을 의미합니다. (b)IMU 센서의 성능이 떨어진 경우로, missing은 임의로 데이터가 없는 경우이고 random은 해당 구간동안 walk noise(걸을 때 발생하는 노이즈)를 추가한 것이라 합니다. 실험 결과를 통해 uncertainty가 오류를 포착하였다고 하는데 저는 그래프를 보았을 때 잘 이해가 되지 않습니다…
Quantitative Evaluation
그림 4에 있는 표에 정량적 성능을 리포팅 하였고, Average Log-Likelihood를 이용하여 평가를 진행하였습니다. VO에 대한 비교를 위해 지도학습 방식인 DICE와 비교하였고, IP를 비교하기 위해 uncertainty를 추정하는 IO 방식인 TLIO와 비교하였다고합니다.
우선 위의 표는 VO에 대한 결과로, DICE와 비교했을 때 대체로 더 좋은 성능을 나타낸다. 특히 밤에 대한 결과는 논문의 방식이 더욱 뛰어남을 확인할 수 있다고 합니다.
IO에 대한 결과는 아래의 표로, TLIO보다 우수한 성능을 나타내며, IMU센서에 문제가 생긴 경우에도 큰 성능 하락 없이 잘 작동하는 것을 확인할 수 있다고 합니다.
또한 표에는 balancing 사용 여부에 대한 결과도 리포팅이 되어있는데, VO에서 balancing을 사용할 경우 성능 개선이 눈에 띄게 일어났다는 것을 확인할 수 있다고 합니다.
Evaluation of Odometry
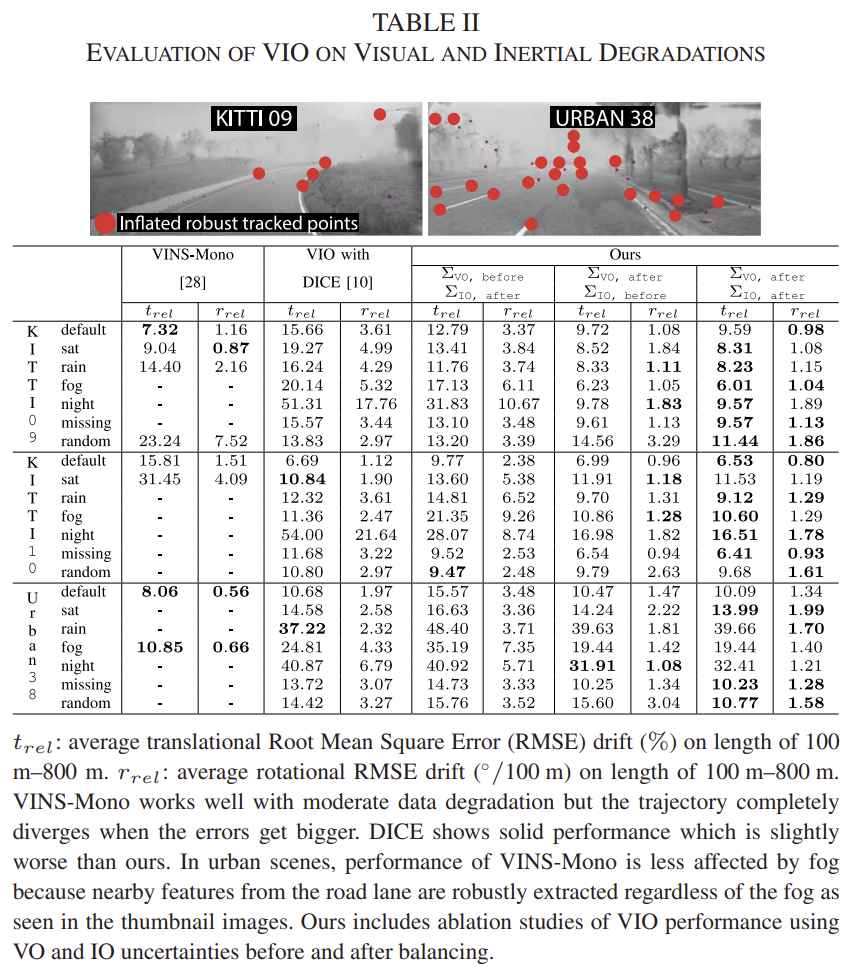
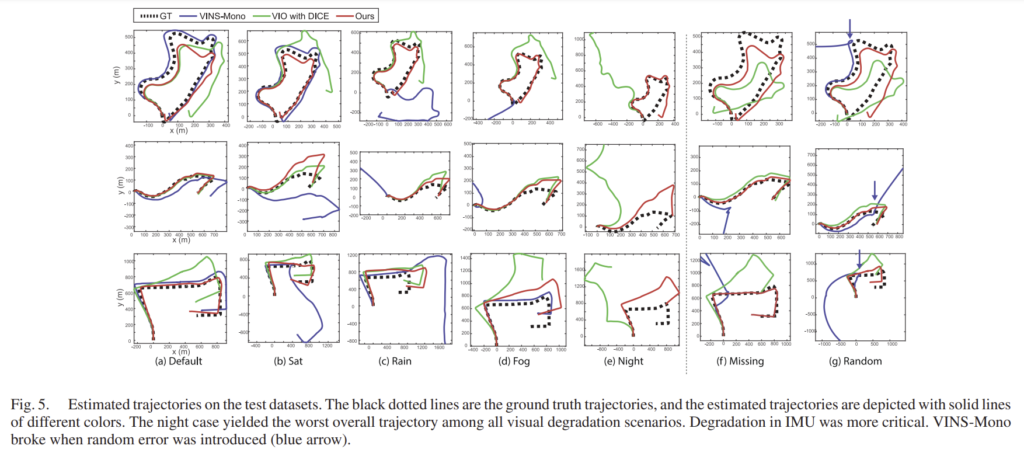
VIO에 대한 결과는 표2와 그림5에 나타나있으며 기존의 VIO 방식인 VINS-Mono와의 비교하였습니다. 전반적으로 논문의 방법론이 더욱 강인하게 작동하는 것을 확인할 수 있고, 특히 시각적 성능이 떨어지는 야간이나, IMU의 데이터가 누락되는 상황에서 기존의 방식은 발산하지만 제안된 논문의 경우는 더욱 강인하게 작동합니다.
지금까지 찾아본 방식들은 센서를 선택적으로 활용하는 방식이였는데, 이 논문은 공분산을 이용하여 불확실성을 추정한다는 컨셉을 가지고 있습니다. 수식이 많고 수학적 개념이 바로 연결이 되지 않아 이해하는 게 어려웠지만, 실험 결과(그림5)를 보았을 때, 잘 작동한다고 생각이 됩니다. 한가지 아쉬운 것은 선택적으로 센서를 사용하는 것과의 결과 비교가 없다는 것입니다. 논문을 읽으며 저자들이 센서를 선택적으로 활용하는 것이 아닌, 공분산을 이용하여 적절히 섞어 사용하는 방식을 연구한 이유가 설명되어있지 않아서 실험적으로 라도 더욱 좋음을 보였을 줄 알았는데 그러지 않아서 의아함이 남습니다.
좋은 리뷰 감사합니다.
불확실성을 다루는 VIO 방법론을 보고 싶었는데 떄마침 좋은 논문을 소개 해주셨네요.
해당 논문에서는 여러 태스크 방법론들을 보완적으로 결합하여 성능을 향상 시킨 것 같습니다.
이전 리뷰해주신 vio 논문에서는 퓨전 모듈의 노이즈를 방지하고자 어느정도 학습을 진행한 후, 학습을 진행했었습니다.
해당 방법론인 경우, 특히나 여러 태스크의 방법론이 결합되었는데요. 이 논문에서는 사전에 학습을 진행해야하는 제약 없이 한번에 학습 하는 건가요?
네,해당 논문은 depthnet과 posenet이 이미 학습이 되어있는 것을 이용한다고 합니다. 학습이 되어있는 네트워크들을 Biasnet을 이용하여 추가로 학습한다고 합니다.
안녕하세요 좋은 리뷰 감사합니다.
지금 제안하는 논문에서는 Uncertatinty를 예측하는 모듈이 하나가 더 있는 것 같은데요.
이 Uncertainty에 대해서는 결국 loss 로 정의한 것 같습니다.
active learning 에서는 uncertainty를 어떻게 정의하는지에 따라서 성능이 달라지곤 하는데,
Uncertainty로 다른 수식을 사용한 그런 논문은 없나요?
uncertainty를 구하는 수식은 여러가지가 있는 것으로 보았습니다. 이에 대해서는 추후에 다뤄보도록 하겠습니다
안녕하세요. 좋은 리뷰 감사합니다.
VIO라는 TASK를 잘 알지 못해 궁금한 부분이 있어 질문 드립니다.
전통적으로 SLAM이 불확실성을 고려하지 않고, 일정한 공분산을 이용했다고 하고, 논문 저자들도 공분산을 이용하여 적절하게 군형 을 잡는 방식에 대해서 연구를 하였다고 하는데,
보통 VIO TASK에서는 원래부터 공분산을 많이 이용하였나요? 공분산 말고도 다른 값을 이용하여 진행하는 경우는 드문가요? 제가 주로 음성 TASK를 많이 다루는데 여기서는 mfcc를 주로 사용하기 때문에 공분산도 비슷하게 주로 사용되는 값인가 생각되어 질문드립니다.
해당 논문의 related work 내용에 따르면 SLAM에서 공분산을 많이 사용하는 것으로 보입니다.
그리고 공분산이 아닌 다른 값을 이용하여 VIO를 진행하는지를 의미하시는 것 같은데 공분산을 이용하여 VIO를 진행한다라기보다는, 공분산으로 두 센서의 균형을 잡는다고 이해하시면 될 것 같습니다.