1. Introduction
Voice activity detection이란 입력 오디오를 speech segment와 non-speech segment로 분류하는 Task입니다. [그림 1]과 같이 신호에서 음성 구간이 어디인지를 찾는 것이라고 생각 하시면 됩니다.

CNN 기반 모델인 Bi-LSTM, CLDN, ResNet960, CNN-TD은 VAD 분야에서는 좋은 성능을 보였지만, 파라미터 수가 많고 학습이나 평가에 사용되는 연산 자원이 많이 소모된다는 단점이 있습니다. 이에 본 논문에서는 2D depth-wise separable convolutions과 유사한 1D time-channel separable convolution을 사용하여 파라미터 수를 획기적으로 감소시킨 MarbleNet을 제안하였습니다. MarbleNet의 크기는 파라미터 수로 볼 때 SOTA VAD 모델인 CNN-TD의 1/10 혹은 MFLOP의 1/35로, 보다 효율적인 연산이 가능합니다.
저자가 제안한 이 논문의 contribution은 다음과 같습니다.
- 1D time-channel separable convolution 기반의 end-to-end 신경망 VAD 모델인 MarbleNet 제안
- AVA 음성 데이터셋에서 sota를 달성하며, CNN-TD 모델에 비해 파라미터 수가 10배 적음
2. Model Architecture
MarbleNet B\times R \times C의 구조는 [ 그림 1 ]과 같이 전체 모델에 B개의 Residual block이 있고, 하나의 Residual block에는 R개의 sub-block이 있으며, 각 블록 내의 모든 서브 블록은 동일한 C의 출력 채널을 갖습니다. 하나의 sub-block은 1D-time-channel separable convolution, 1×1 pointwise convolutions, batch norm, ReLU, dropout으로 구성되며, 1D-time-channel separable convolution은 크기가 K인 C개의 필터로 구성되어 있습니다. 또한 모든 모델에는 4개의 하위 블록이 추가되어 있는데, Residual 앞부분에 프롤로그 레이어인 Conv1이 있고, 마지막 Softmax 앞에 3개의 에필로그 sub-block인 ‘Conv2’, ‘Conv3’, ‘Conv4’가 있습니다.
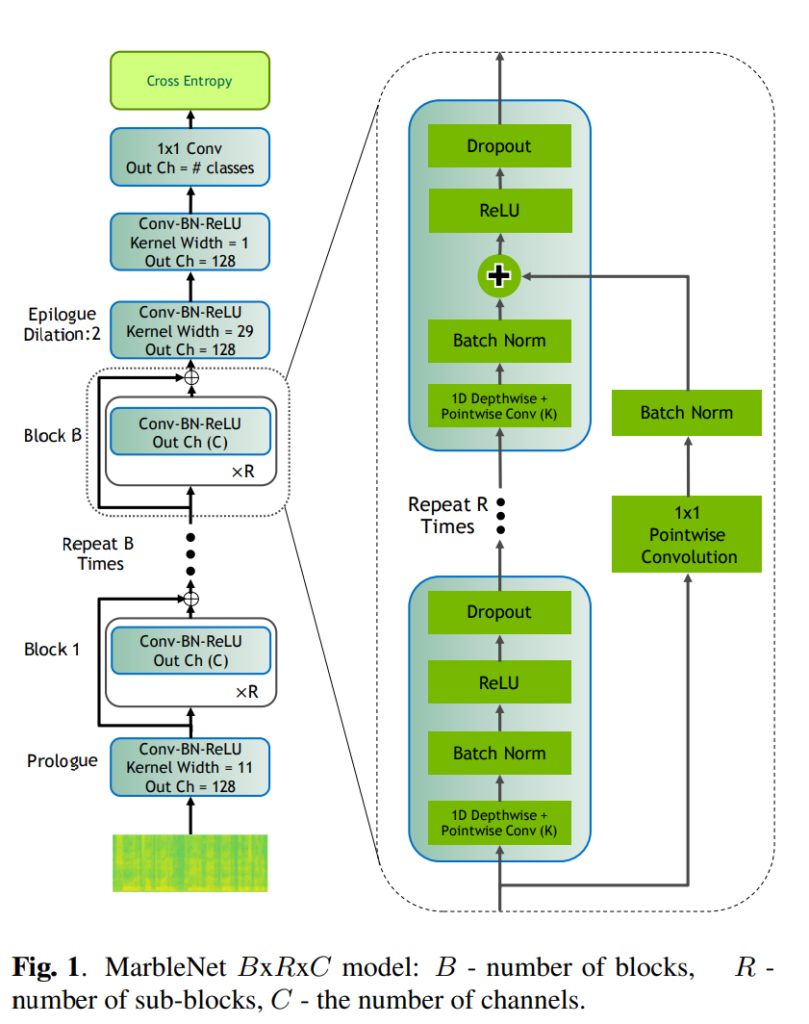
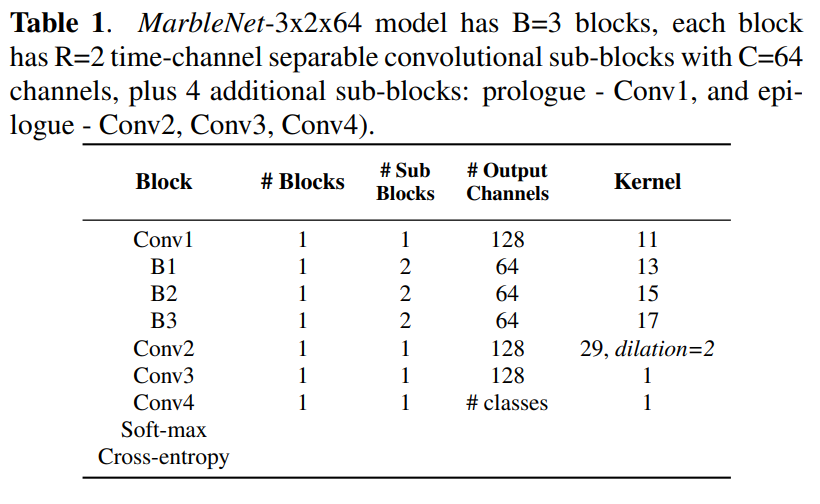
[ 표 1 ]은 MarbleNet 3\times 2 \times 64의 전체 구조를 나타냅니다.
3. Experiments
3.1 Training Data
노이즈에 강한 모델을 생성하기 위해서 학습 및 평가에는 clear speech data와 noise 데이터를 합성하여 사용했습니다. speech 데이터는 Google Speech Commands Dataset V2를 noise데이터는 freesound.org의 ‘traffic noise’, ‘inside, small room’등 35가지의 배경 소음 데이터를 사용했습니다. 합성 데이터(이하 SCF 데이터셋)는 0.63초에서 100초 사이에 분포하며, 8:1:1비율로 각각 train, test, validation으로 사용했다고 합니다.
3.2 Training Methodology
MarbleNet의 학습에는 위에 언급된 음성 + 소음 합성 데이터의 MFCC를 사용하는데 이는 크기가 64\times 64인 이미지입니다. 그런 다음 80%의 확률로 T = [-5, 5] ms 범위의 time shift, [-90, -46] dB 범위의 white noise로 augmentation을 진행하였습니다.
3.3 Evaluation Method
저자는 CNN-TD 모델을 Baseline으로 삼고 AVA 음성 데이터셋을 이용해 두 모델에 대한 평가를 진행했습니다. AVA데이터셋은 총 네 가지 클래스(non-speech, clean, noise, music)으로 구성된 데이터셋입니다.
평가 방식은 true positive rate(TPR)로, non-speech를 neative class로 두고 진행하였습니다.
3.4 Results
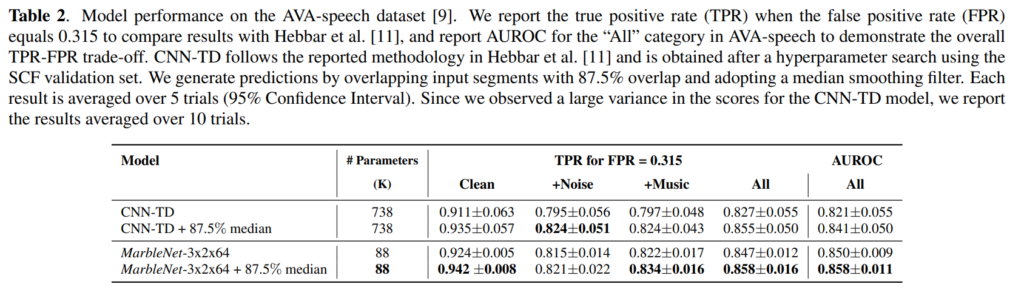
[ 표 2 ]는 AVA 음성 데이터셋에 대한 평가 결과입니다. MarbleNet은 5회, CNN-TD는 10회 반복한 결과값을 나타낸 것입니다. MarbleNet은 CNN-TD보다 더 작은 신뢰 구간을 보여줌으로써 안정적인 성능을 보이고 있습니다.
MarbleNet-3x2x64는 CNN-TD와 유사한 성능을 보이고 있지만 파라미터 수는 CNN-TD의 1/10수준입니다. 이는 MarbleNet-3x2x64가 비교적 간단한 training dataset인 SCF 데이터셋에서 훈련되더라도 추가 미세 조정 없이 더 까다로운 AVA 음성 데이터셋에 대해 여전히 우수한 성능을 얻을 수 있음을 보여줍니다.
안녕하세요.
제가 해당 테스크를 잘 몰라서 프롤로그 레이어가 무엇을 의미하는 지 모르겠습니다. 프롤로그와 에필로그라고 되어있는 것은 단순히 명칭인가요?? 혹은 특별한 기능이 있는 레이어를 지칭하는 것인가요?? 이에 대해 설명해주시면 감사하겠습니다.
또한 학습 과정에 clear와 noise데이터를 합성하여 사용하였다 하셨는데 모든 clear 데이터에 noise를 추가하여 사용한것인가요???
안녕하세요 질문 감사합니다.
1. 프롤로그와 에필로그는 단순 명칭이 맞습니다. MarbleNet의 구조는 Residual 블록과 Sub 블록으로 구성되어 있는데 블록 이외에 모델에 추가적으로 들어간 conv레이어들을 지칭하기 위한 명칭으로 이해하시면 될 것 같습니다.
2. 학습에 사용된 음성 데이터는 80%의 확률로 랜덤하게 노이즈 합성이 진행되었습니다.