Abstract
class-balance가 무너진 long-tail data문제는 deep learning 모델의 학습을 어렵게 하는 문제 중 하나이다. Active learning에서도 data imbalnce문제는 큰 학습 성능 저하를 발생시키는데, 본 논문은 이러한 문제를 발생시키지 않는 active learning framework를 제안한다.
Method
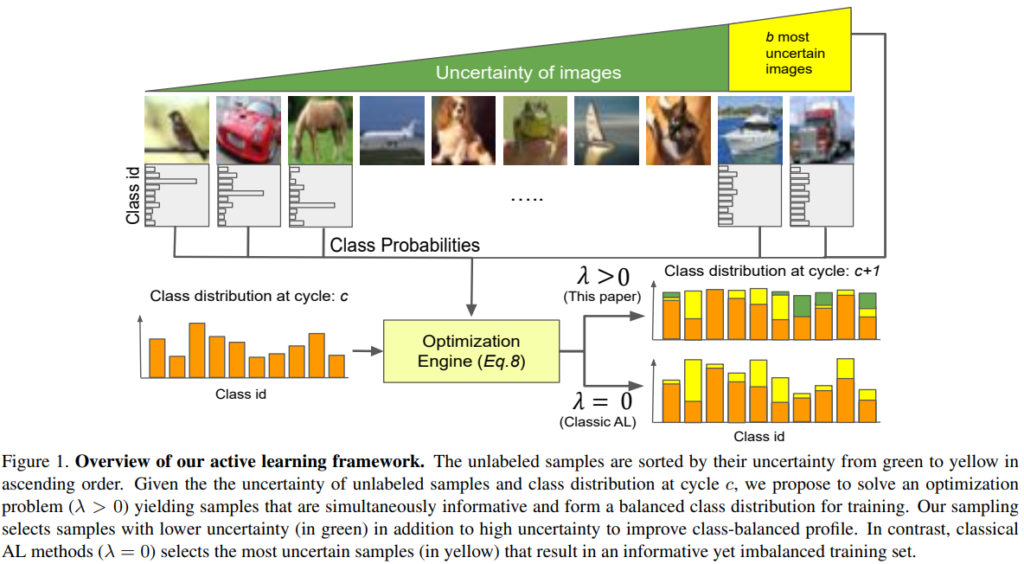
Uncertainty기반 Active Learning(이하 AL)은 모델이 학습이 불완전한 데이터를 고가치 데이터로 선별하여 데이터 가공을 요청하는 방법론으로 그림1의 우측 하단에 λ=0 상황과 같이, 상대적으로 어려운 데이터셋을 더 수집하게 되는 class-imbalance 문제가 발생할 위험이 있다. 이에 대응하기 위하여 해당 논문은 high uncertinty data 중 일부를 이용해 다음 사이클을 위한 데이터셋에서 long-tail 문제가 발생하지 않도록 보정하는 새로운 AL 프레임 워크를 제안하였다.
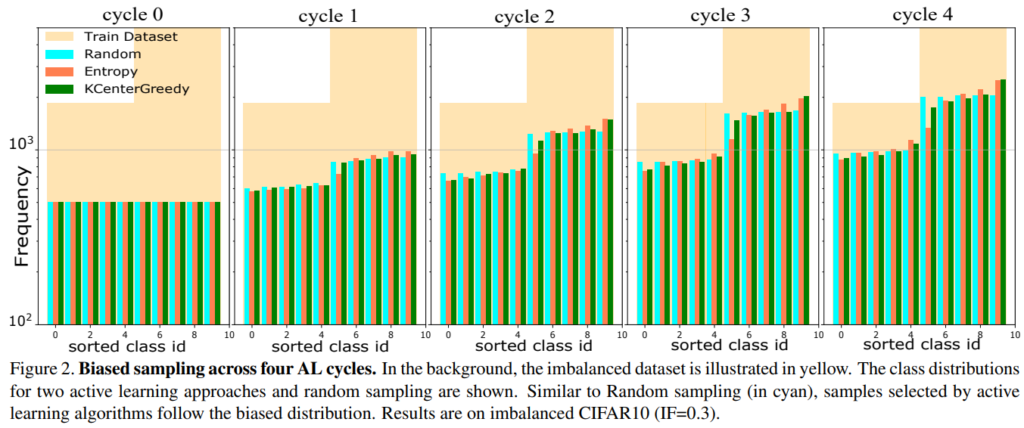
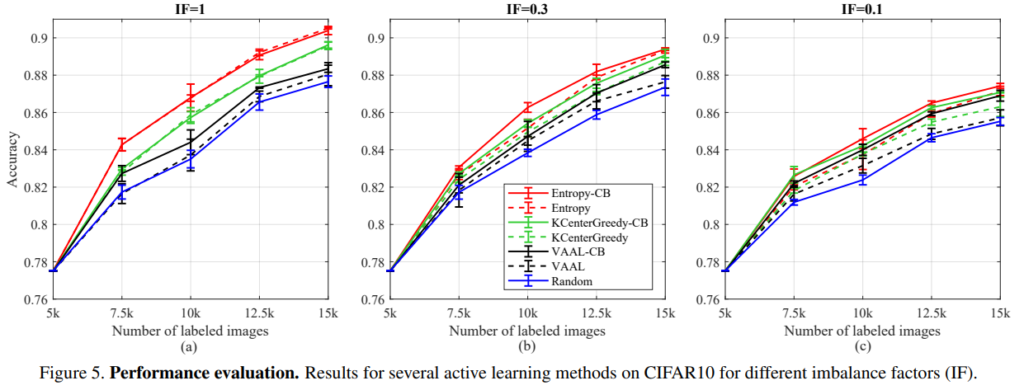
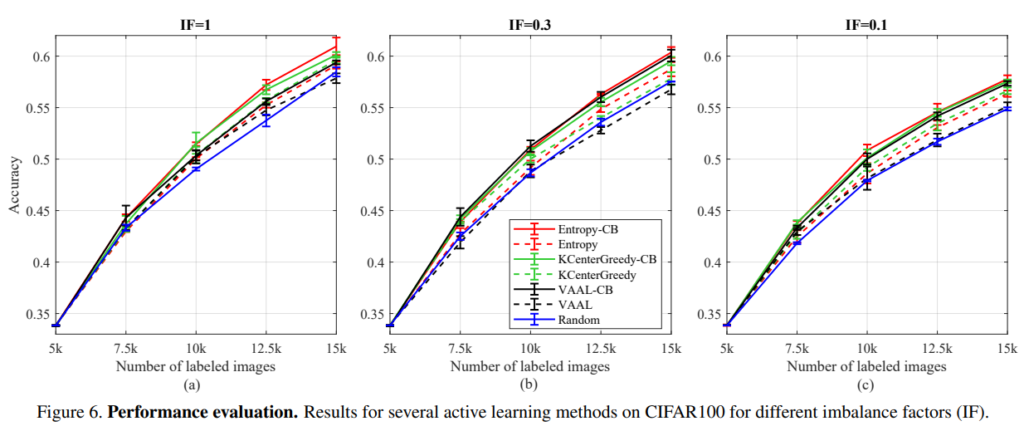
active learning 방법론에서 class imbalanced 문제에 대한 취약성은 그림2의 실험을 통해 확인할 수 있는데, 노란색 그래프와 같이 class imbalance가 있는 데이터셋에서 random, 분포기반 AL(KCenterGreedy), Uncertainty기반 AL(Entropy)으로 데이터를 선별한 결과이다. random sampling에서도 데이터의 분포를 따라 class imbalanced 문제가 발생하는 한편, AL 방법론은 class 별 난이도에 따라 해당 문제가 더 심화됨을 확인할 수 있다. 실제 데이터 가치판단을 진행해야 하는 데이터셋은 비가공 상태이므로 class imbalance 상태일 가능성이 높으며, 이러한 상황에도 random보다 확실히 좋은 sampling을 위해서는 해당 문제를 보완할 수 있는 선별법이 필요하다는 것이 본 논문의 motivation이다.
자세한 프로세스 진행과정은 다음과 같다. 기존 방법론과 같이 다음의 수식1으로 예측의 확신도를 이용해 entropy를 측정한다. 즉,개, 고양이 분류 문제에서 개일 확률이 0.3/고양이일 확률이 0.7인 데이터와 개일확률이 0.5 고양이일 확률이 0.7인 데이터가 있다면 후자의 데이터가 더 entropy가 높음으로 가치가 높다.
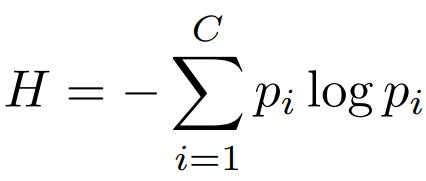
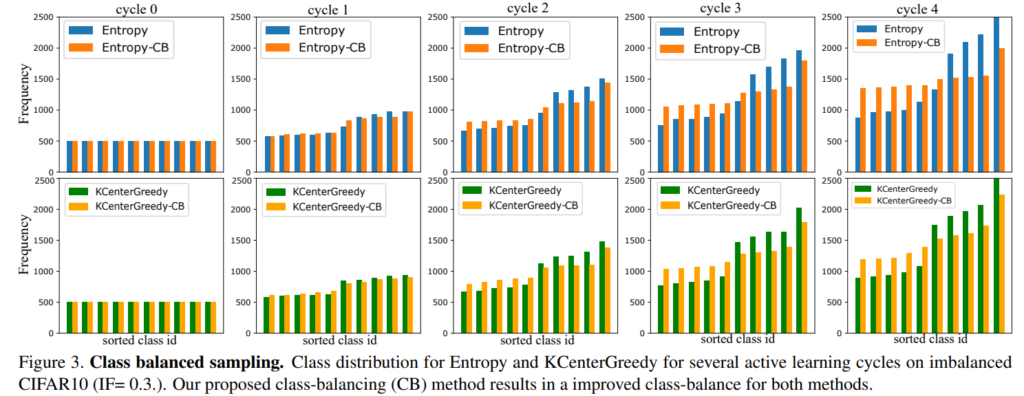
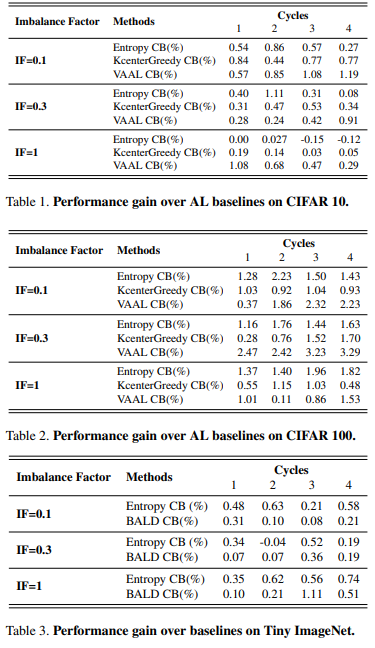
이후 미리 설정한 정규화 변수 λ에 따라 class-balancing(이하 CB)을 진행한다. CB를 통해 선별한 고가치 데이터의 결과는 그림3과 같으며 기존 방법론보다 class-imbalance 문제를 완화하였음을 알 수 있다.
실험
실험은 CIFAR10, CIFAR100, Tiny-ImageNet에서 진행하였다.
안녕하세요. 황유진 연구원님.
엔트로피가 높은 데이터를 선정해서 학습하는 active learning의 기본적인 흐름은 이해했습니다. 예시로 들어진 것도 엔트로피가 높다는 것은 이해했는데요. 제가 이해했던 active learning은 다 이런 흐름으로 데이터를 선정하는 것으로 이해하고 있었는데요. 여기서 엔트로피를 높은 것을 선정해서 가치가 높은 데이터를 선정하는 것이 class imbalance 문제와 직접적으로 어떤 관계가 있는지 잘 모르겠습니다. 혹시 추가적인 설명 가능하시다면 부탁드립니다.
감사합니다.
본 논문은 uncertainty측정 이후 가중치에 따른 class balancing 작업을 포함합니다 감사합니다
좋은 리뷰 감사합니다.
해당 방법론은 etropy를 계산하여 높은 entropy를 가지는 데이터를 고가치 데이터로 판단하여 라벨링을 진행하는 것으로 이해하였습니다. 방법론이 꽤나 단순해보이는데 CB를 제안하여 class-imbalance문제를 완화하였다는 것 말고도 다른 제안한 것이나 컨트리뷰션이 있을까요?? 또한, 기존의 연구중에 entropy를 이용하는 다른 방법론들이 존재하는지와, 존재한다면 어떠한 차별점이 있는지 궁금합니다.
AL 분야에서 데이터 선별에 따라 class imbalance 문제가 발생한다는 문제를 수면으로 끌어올린것이 해당 논문의 contribution중 하나라고 생각합니다 ㅎㅎ 감사합니다
리뷰 잘 읽었습니다.
기존의 AL 에서는 uncertainty 가 높은(?) 데이터를 선별하였다면,
본 논문에서는 uncertainty를 측정 후 high uncertainty에 대해 entropy를 측정해서 가치가 높은 데이터를 선별하는 방식인건가요??
익숙하지 않은 task라 제 이해가 맞는지 확인하고자 질문 드립니다,!!
안녕하세요 좋은 질문 감사합니다. 기본적으로는 높은 uncertainty를 갖는 데이터를 우선적으로 선별하지만, class balance를 고려하는 모듈을 추가한 방법론입니다