Abstract
전통적인 model-based 방법론이 딥러닝 기반의 방법론보다 당시에 좋은 성능을 나타냈다고 합니다. 해당 논문은 Bootstrapped Monocular VIO(BooM)이라는 방법론을 제안하여 전통적인 방법론을 통해 얻을 수 있는 기하학적 정보를 이용하여 복잡한 데이터를 이용할 수 있는 scaled 단안 VIO 방식을 제안합니다. 제안된 방법론은 end-to-end로 학습이 가능하며, 비지도 방식을 이용하여 VIO odoemtry와 depth estimation을 학습합니다.
Introduction
VIO 분야에서 전통적인 방식은 좋은 성능을 보여주었으나, 이미지로부터 불충분한 정보가 주어지거나 센서의 동기화가 맞지 않거나 dynamic한 씬에 대해서 궤도가 크게 틀어지는 문제가 있습니다. 딥러닝 기반의 방법론은 어려운 시나리오에 대해 더 강인하기는 하지만, 전통적인 방법론에 비해 성능이 떨어지는 문제가 있었습니다. 이에 본 논문에서는 scaled monocular VIO를 제안하며 딥러닝 기반의 방법론의 성능을 높이고자 전통적인 방식을 통해 얻은 결과를 이용하여 모델을 학습합니다.(이때 scaled라는 용어에 대해서는, 일반적으로 odometry가 상대적으로 움직인 값을 이용하기 때문에 크기에 대한 정보를 얻기 어려운데, 이러한 크기에 대한 정보를 포함한 VIO 방식이라고 이해하시면 될 것 같습니다.)
이 논문의 contribution을 정리하면 다음과 같습니다.
- 비지도 기반 deep monocular VIO 방식의 학습 과정에 전통적인 VIO 방식을 통합하였다.
- deep monocular VIO 방식에서 경로를 추정할 때 scale 정보도 함께 추정할 수 있다.
Approach
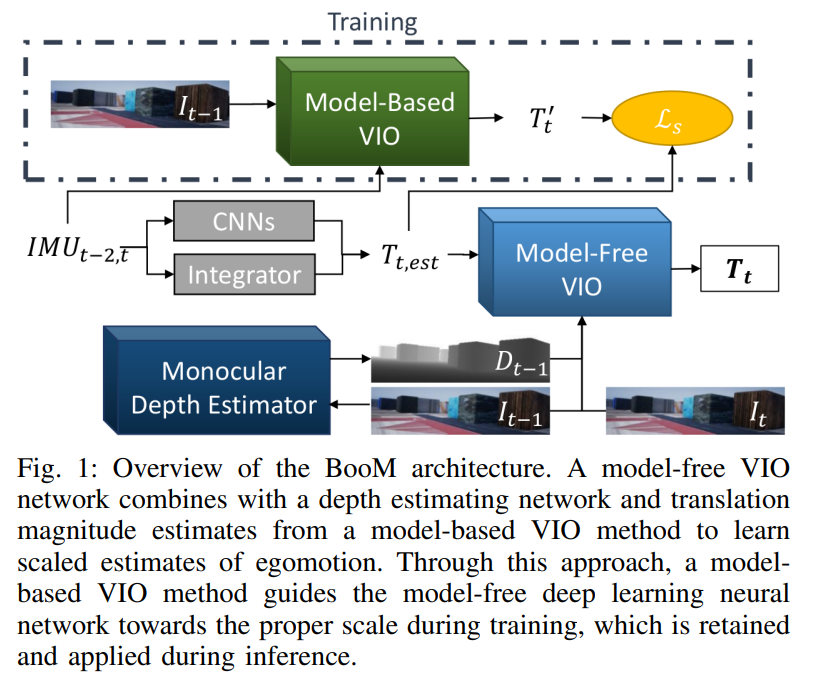
t_{j-1}와 t_j사이의 scaled egomotion을 추정하는 것이 목표입니다. 이에 RGB이미지는 (I_{j-1},I_j), IMU 데이터는 (a_{j-2,j},w_{j-1,j})의 가속독와 자이로스코프 값, 카메라의 intrinsic 파라미터K를 모델에 입력해주게 됩니다.
이때 K를 이용하여 합성뷰를 생성하므로써 카메라의 포즈 변화를 알아내게 됩니다. 합성뷰를 생성하기 위해 target 이미지와 source 이미지에 3D affine 변환을 통해 얻은 reconstructed target 이미지 간의 유클리디안 loss를 이용하여 모델이 학습이 된다고 합니다. 또한, 3D affine 변환은 depth이미지를 생성하기 위한 SFMLearner를 통해 얻을 수 있게 됩니다.
이때 IMU intrinsic과 IMU-Camera의 extrinsic 파라미터는 전통적인 VIO 모델에 들어가 scale 정보를 알 수 있도록 해줍니다.
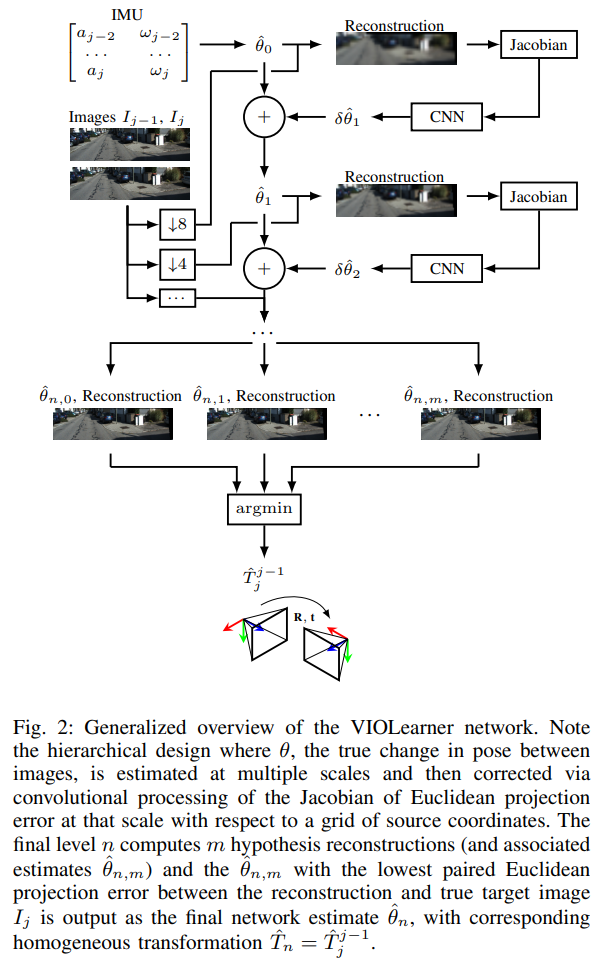
A. Initial Pose Change Estimate
j-2에서 얻은 가속도계의 측정값은 일련의 CNNs를 통해 초기 변화값을 생성하고, 자이로스코프 측정값w은 직접적으로 통합하여 방향 변화를 구합니다. 이렇게 구한 두 output을 결합하여 최종 pose 추정값 T_{t,est}(t시간에 대한 추정값. 그림에는 t라 되어있으나 수식에 대해 생각해보면 j라 이해하는 것이 적절할 것 같습니다.)을 얻게 됩니다.
B. Bootstrapping Scale
전통적인 VIO 방식은 이미지와 IMU 데이터, 카메라와 IMU 각각의 intrinsic, IMU-Camera의 extrinsic 파라미터를 이용하여 t_j에 대한 변화값을 추정합니다. 이러한 전통적 방식은 학습 과정에만 이용하며, BooM 네트워크의 depth 네트워크의 scale을 정확하게 추정하도록 학습하는 데 사용됩니다.
scale loss \mathcal{L}_s는 t_j에 대해 추정된 크기에 대한 loss로, 딥러닝 모델에서 추정한 p_{j,mf}과 전통적 방식으로부터 추정한p_{j,mb}간의차이를 이용하여 구합니다.
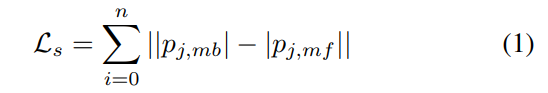
이때 저자들은 VINS-Mono[1]를 전통적 기법으로 이용하였습니다.
[1] T. Qin, P. Li, and S. Shen, “Vins-mono: A robust and versatile monocular visual-inertial state estimator,” IEEE Transactions on Robotics
Method
KITTI Driving Dataset
해당 논문은 KITTI odometry 데이터 셋을 이용하였습니다. RGB와 Depth 데이터를 이용하였습니다. (train과 test 셋을 어떻게 나누었는지에 대한 언급은 없었으나, 표에 따르면 09, 10 셋을 test에 이용하였습니다)
AirSim MAV Simulation Environment
해당 데이터 셋은 게임 개발 플랫폼인 Unreal Engine을 이용한 시뮬레이션을 통해 생성된 데이터 셋입니다. 아래의 그림5를 통해 예시를 확인할 수 있으며, 상공에서 촬영된 영상으로 구성되어있습니다. 이미지는 11.11Hz, IMU는 111.11Hz로 촬영되었고, 속도는 0~8m/s로 가정하였다고 합니다. 학습, 검증, Test 셋은 각각 10, 2, 2개의 셋으로 구성됩니다.

Simulating Harsh Environment
KITTI와 AirSim 데이터의 test 셋에 대해 augmentation을 적용하여 실제 환경에서 촬영될 수 있는 문제 상황을 가정하였다고 합니다. 이러한 과정을 통해 rain, fog, snow 환경을 모사하였다고 합니다. 또한, 실험은 VINS-Mono(전통적인 방식)의 정확도가 떨어지는 상황에 대해서 성능을 평가하였다고 합니다.(이 논문에서 보이고자 한 것이 전통적인 방식이 잘 작동하지 않는 상황에서 딥러닝 방식이 더욱 강인하다는 것이기 때문인 듯 합니다.)
Results and Discussion
어려운 상황을 모사하지 않은 경우
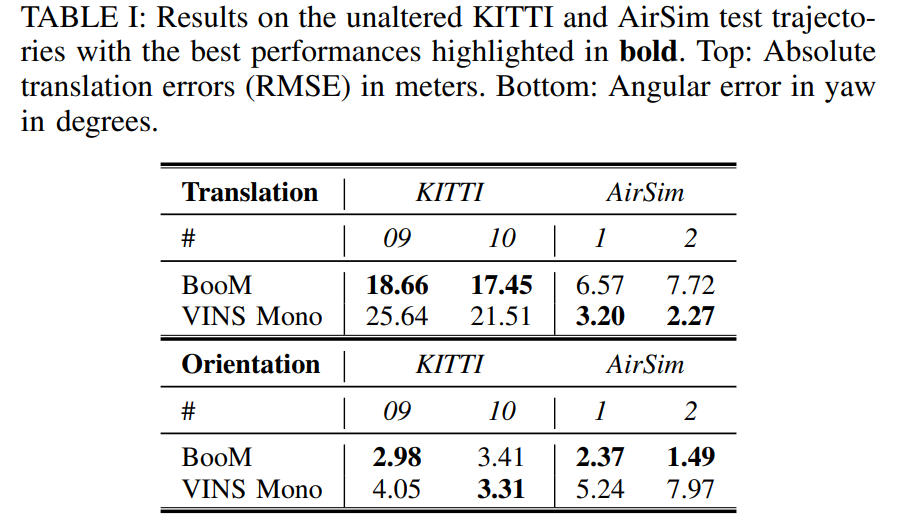
BooM은 KITTI에 대해서는 상대적으로 더욱 정확도가 높았으나, AirSim 방법론에 대해서는 Translation의 정확도는 조금 떨어지는 경향이 있습니다.
어려운 상황을 모사한 경우(KITTI)
** AirSim에 대한 결과도 리포팅 되어있으니 확인하고싶으신 분들은 논문을 참고해주세요!
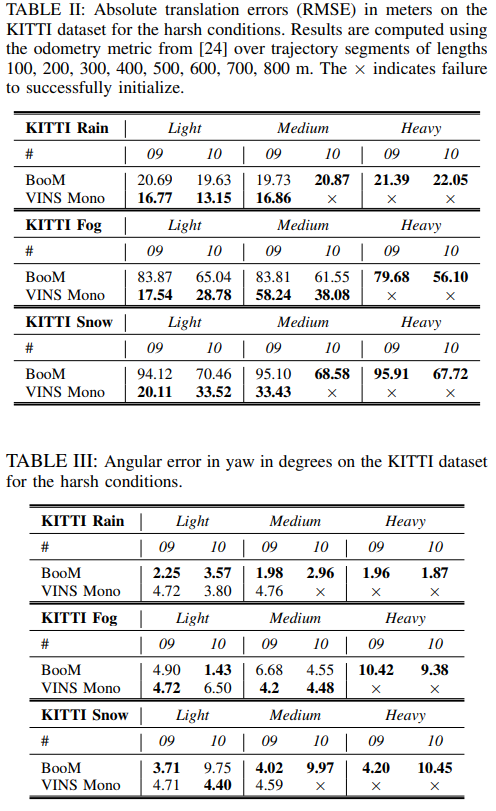
Table 2는 translation, Table3은 orientation에 대한 결과입니다. 영상에 이상상황을 모사한 정도가 강해질 수록 BooM 방식의 error가 전통적인 방식에 비해 작다는 것을 확인할 수 있습니다. 또한, 그림 7의 (b)를 통해 BooM 방식이 VINS-Mono의 예측값을 이용한다는 불완전함에도 불구하고 scale이 적절하게 추정 가능하며, 이상 상황이 강해져도 scale에 대해 강인함을 보였습니다.
안녕하세요. 좋은 리뷰 감사합니다.
궁금한 점이 있어 질문 드립니다.
‘일반적으로 odometry가 상대적인 값을 이용하기 때문에 크기에 대한 정보를 얻기 어려운데, 이러한 크기 정보를 포함한 것을 scaled’라고 설명해 주셨는데 이때 크기 정보는 어떤 크기를 의미하는지 알고 싶습니다.
또, VIO task에는 IMU의 가속도와 자이로스코프, 카메라의 rgb이미지가 함께 사용되는 것으로 알고 있는데 실험 부분을 보니 이미지는 11.11Hz, IMU는 111.11Hz로 촬영되었다고 되어 있습니다. 그렇다면 각 센서의 정보가 서로 다른 속도로 들어오게 되는데 ailgn을 어떻게 맞추는지 궁금합니다.
마지막으로는 실험 세팅에 관해 질문하고 싶은데 unreal Engine을 통해 구현한 rain, fog, snow를 어려운 상황이라는 것은 알겠는데 어느 정도를 light, medium, heavy로 정의했는지 논문에서 언급했는지도 궁금합니다.
여기서 크기 정보는 실제 세계에서의 크기 정보를 의미합니다.
또한, 두개의 이미지 프레임에 대해 10개의 IMU 데이터를 이용하는 것입니다. 이런 방식으로 align을 맞춰주게 됩니다.
마지막으로 세팅에 관해 저도 파라미터를 어떤값으로 설정하였는지 확인해보려 했으나, 정의가 되어있지 않았습니다. 다만 light,medium, heavy가 KITTI와 AirSim에서 모두 동일한 정도로 설정이 되어있다고만 언급되어있습니다.
좋은 리뷰 감사합니다.
Approach가 Method에 해당하는 거죠?
그리고 Loss에서 스케일 t를 추정을 목적으로 한다고 했는데 수식으로는 t도 보이지 않고 i도 보이지 않는 것으로 보아 추가적인 수식 설명이 있어야 할 것 같네요. 그리고 p가 포즈 정보인지 어떠한 노테이션을 가지고 있는지 설명 부탁드립니다.
근데 딥러닝 기반과 전통적 기법 간의 스케일을 구하는 이유가 뭔가요?
실험 결과도 VINS-Mono 보다 좋다고 말하기도 애매해 보이는데 말이죠…
네 논문이 Approach에 저희가 일반적으로 생각하는 Method 내용을 담고있었습니다.
i에 대한 노테이션을 제가 놓쳤던 것 같습니다. fig2에 있는 n level과 매칭이 되는 것으로, n level의 값들을 모두 더한 값으로 이해하시면 됩니다. 또한 p는 model-based, model-free 방식을 통해 구한 translation의 값을 의미합니다.
제가 이해하기로는 전통적인 기법이 센서들의 intrnsic, extrinsic 파라미터를 이용하므로써 스케일에 대한 정보를 이용할 수 있고, 이러한 스케일 정보를 depth net에 제공하여 보다 정확한 값을 얻기 위함으로 보입니다.
또한 이 논문은 일반적으로는 성능이 떨어지지만, 이상상황에서 더욱 강인함을 보인 것을 목표로 한 것으로 보입니다. 다만 논문 자체가 이상상황에 강인함을 인트로에서 더욱 어필하고, 이를 해결하기 위해 어떻게 하였는가를 중심으로 다루지 못하였다고 생각됩니다.