바로 직전에 Active Learning 과 Self-supervised learning 을 결합한 논문을 읽어보며 새로 알게된 지식이 있다면 바로 initial labeled dataset size에 대한 것입니다. 해당 논문에서는 AL의 initial labeled dataset size이 작을 경우, 오히려 random sampling 보다 성능이 좋지 못하다는 것을 주장하였습니다. 그런데 제가 직접 실험을 하면서도, 데이터셋이 일정 수준 이하로 작아지면 random sampling 보다 성능이 현저히 낮아지는 경향성을 확인했기 때문에, “그렇다면 초기 데이터셋이 작을 때를 겨냥한 AL 연구는 없나? 왜 이런 현상이 발생하는 것인가?” 라는 의문에서 시작되어 이 논문을 리뷰하게 되었습니다.
[ICML 2022] Active Learning on a Budget: Opposite Strategies Suit High and Low Budgets

Introduction
Active Learning 이란 어떤 데이터를 레이블링 하는 것이 효율적인지, 데이터를 선별하는 모델을 연구하는 것이라고 할 수 있습니다. 효율이라는 것은 1) 동일한 레이블링을 하더라도 성능이 오르는것 2) 대표성을 띠는 데이터를 레이블링 하는 것 등등이 기준이 될 수 있습니다.
기존 많은 연구들은 Uncertainty를 기반으로 연구가 되고 있는데요. 말 그대로 불확실한 데이터를 우선적으로 레이블링 하는 것입니다. 왜 불확실한 것을 하느냐? 모델이 판단하기 어렵다고 할 수 있는 불확실한 데이터는 대개 클래스를 결정짓는 결정 경계 근처에 분포되어있을 확률이 높습니다. 따라서 모델이 판단하기 어려운 데이터를 레이블링 해야 성능을 더욱 높일 수 있기 때문이니다.
이 외에도 레이블링의 중복을 피하기 위해 Diversity를 기반으로 연구가 되고 있기도 합니다. 각 클래스의 대표적인 데이터를 골라서 레이블링하는 것을 목표로 합니다.
그런데 문제는 제가 지난번 리뷰에서도 언급했듯, 이런 AL에서는 초기 라벨링 데이터셋이 적을 때에는 오히려 랜덤하게 데이터를 선별하는 것이 더 좋은 성능을 발휘했습니다. 데이터가 적다라고 한다면 보통 전체 데이터 중 1% 정도를 의미합니다. 이런 경우를 저예산 체제라 하며, 랜덤 샘플링보다 성능이 낮은 현상을 “cold start” 라고 부릅니다.
문제는 Active Learning의 목적에 있는데요. 데이터의 레이블링을 최소화하는 것을 목표로하는 AL에 라벨링 데이터가 많아야 좋은 성능을 낸다는 것은 저자의 입장에서 본질을 벗어난다고 생각한 것 같습니다. 즉, 오히려 적은 데이터셋에서 성능이 좋아야 적용이 가능하다는 것이죠.
따라서 저예산 체제에서는 기존과는 대비되는 새로운 접근법이 필요하다고 주장하며 새로운 방법론을 제안하였습니다.
Method: Low Budget Active Learning
저자는 TypiClust 라는 저예산 체제를 위해 설계된 새로운 AL 방법론을 제안하였습니다. 이는 max density (or typicality) 와 diversity를 연결하였다고 하는데요. 이에 대해 알아보겠습니다.
우선 저예산 체제에서의 몇가지 문제를 극복해야하는데요. (A) 적은 데이터로 학습된 네트워크는 과적합 되기 쉬워서 노이즈에대해 신뢰할 수 없게 만든다는 것 (B) 게다가 전형적인 샘플들은 매우 유사한 경향이 있어 다양성의 필요성이 대두된다는 점입니다. 여기서 말하는 전형성과 다양성에 대해서는 아래 그림을 통해 알 수 있을 것 같습니다. 전형적이라고 한다면 대표성이라고 생각하면 좋을 것 같습니다.

따라서 이런 문제점을 극복하기 위해, 분포가 다른 부분을 탐색하면서 typical한 데이터를 선택하는 TypiClust라는 방법론을 제안합니다. 여기서 (A)를 극복하기 위해 self-supervised 는, (B)를 극복하기위해 clustering을 사용ㅇ했다고 합니다. 제안하는 방법론은 3 단계로 구성됩니다.
Step 1: Representation learning. Unlabeled 데이터셋인 U_0로 우선 self-supervised learning 을 진행합니다. 그 다음 linear layer를 붙여서 사용한다고 합니다 (여기는 저번 리뷰했던 논문과 동일하네요)
Step 2: Clustering for diversity. 이웃 클래스까지의 거리를 측정하기 위해 (4) 식이 사용되었습니다. 가장 전형적인 샘플은 서로 가깝고, 동일한 이미지와 유사하게 됩니다. 또한 다양성을 통해 기본 데이터 분포를 더욱 잘 표현할 수 잇기 때문에 Clustering 을 사용하였습니다. 각 cycle에서 데이터를 |L_i − 1| + B 개의 cluster로 분할함으로써, 기존 샘플과 겹치지 않는 최소 B개의 cluster를 보장하게 됩니다.
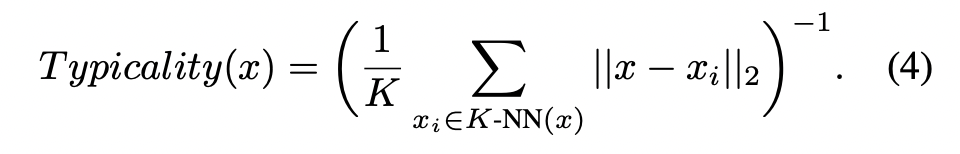
Step 3: Querying typical examples. 이제 클러스터를 통해 구한 일반적인(전형적인) B개의 클러스터들을 쿼리하는 AL 방식이 진행됩니다.
다시 말해, 해당 방식은 Self-Learning + Clustering 방식이 될 것 같습니다. 이에 대한 수도 코드를 아래 첨부하겠습니다.

Experiment
우선 해당 연구에서는 기존 AL에서 다루지 않은 imageNet을 사용하였다는 것이 제법 인상적입니다. 다만 ImageNet-100이라는 서브셋을 사용하였지만, 그래도 이미지넷을 적용하려고 시도했다는 것은 그만큼 self-learnign 을 붙힘으로써 많은 성능 향상을 가져왔다고 할 수 있지 않나 싶네요.
- Fully supervised framework
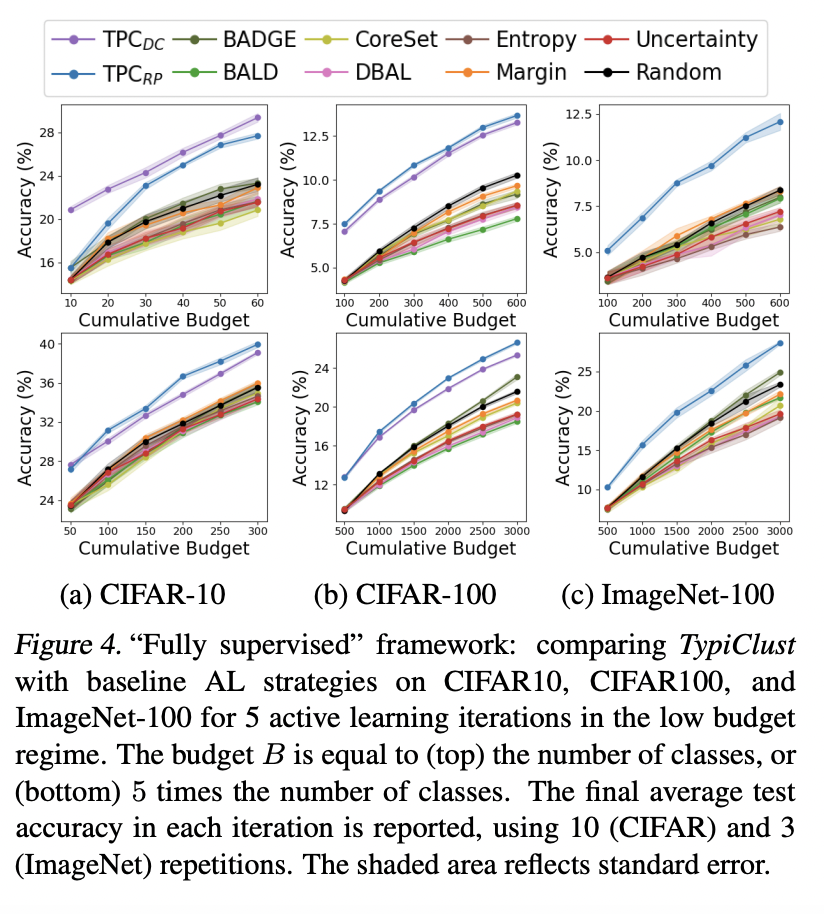
아래 그림 4에는 CIFAR-10/100 그리고 ImageNet-100에 대한 정확도를 보여줍니다. TPC가 저자가 제안하는 방법론을 의미합니다. TPC 두 방법 모두 기존의 연구를 크게 앞지르는 성능을 나타냅니다. 랜덤 샘플링과 비교해서 볼 필요가 있는데 기존 방법들은 랜덤 샘플링과 비슷하거나 심지어 성능이 떨어지는 결과를 보이는데요. 그에 비해 TPC는 높은 성능을 보입니다.
기존 연구에서는 초기 Labeled 데이터를 어떤것을 선택하는 지에 따라 성능에 많은 차이가 있고 특히 랜덤 샘플링 역시 성능이 더 좋을 수 있다 라고 말하는 경우가 많지만, 나중에 나올 Ablation study에서 초기 라벨드 데이터셋이 무엇인지는 결정적이지 않다는 것을 보여주었다고 합니다. 즉, 초기 데이터셋에 의한 체리픽이 아니다를 주장하는 것 같습니다.
Ablation Study
[1] RANDOM INITIAL POOL SELECTION
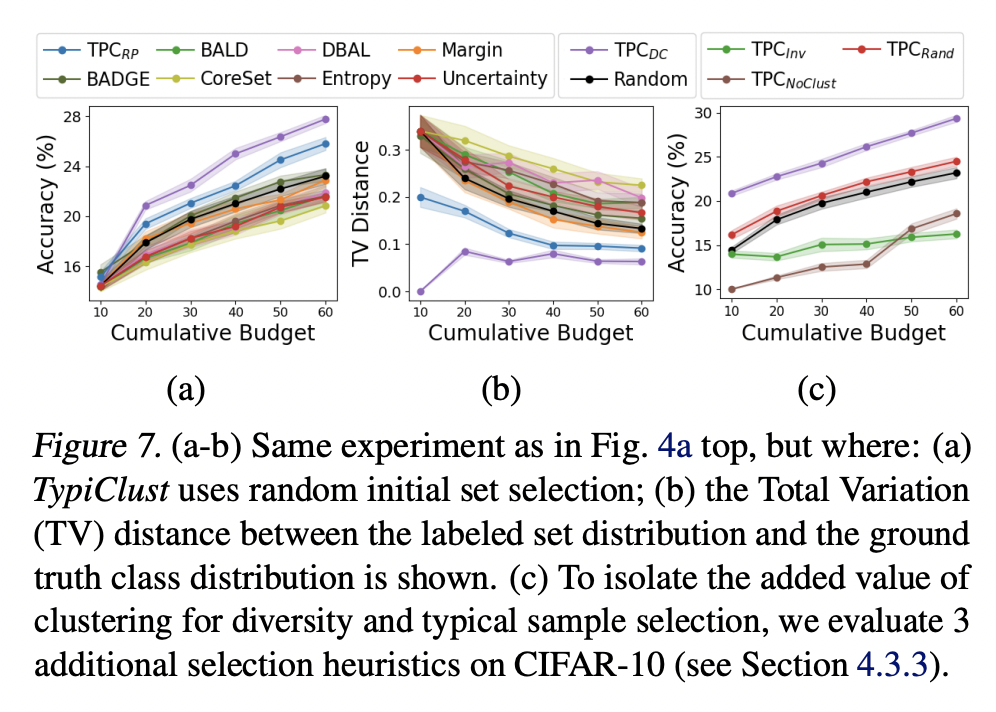
Active Learnign 은 특히 초기 라벨링 데이터셋에 성능이 민감합니다. 저자는 이 초기 샘플이 영향이 있는지를 분석하기 위해 여러번의 ablation study 를 수행하였습니다. (a)는 랜덤 선택을 (b)는 분포 사이의 총 변동 (TV) 거리,
비 랜덤 초기 샘플링이 AL과 결합할 대 일반화에 있어 이득을 가져왔음을 알 수 있었습니다.
Conclusion
고예산, 저예산에서의 AL을 위해서는 반대의 전략이 수행되어야 함을 주장하였습니다. 하지만, 아직까지 저예산이라는 기준으로 학습 데이터의 크기를 결정하는 것은 어려운 문제이기 때문에 추후 연구로 이어져야 한다고 합니다.