
CBAM: Convolutional Block Attention Module
안녕하세요. 첫 X-Review 글입니다. 해당 논문은 이번 KRoC 2023을 준비하며 읽은 논문으로, 어떤 아이디어를 토대로 실험했는지는 마지막 문단에서 왜 해당 방법론이 좋은 성능을 보이지 못했는지 고찰하며 시작하겠습니다.
참고로 해당 리뷰에는 논문 리뷰와 동시에 논문을 읽으며 처음 보는, 혹은 단어 및 개념들을 정리하는 내용을 함께 포함하여 스스로의 이해를 돕고자 하는 측면이 많으니, 논문의 내용 중 특정 용어 및 방법에 대하여 잠시 다른 방향으로 샐 수 있습니다. 따라서 논문의 방법론을 설명 시, 굵은 글자로 표현하여 시작 지점을 보이겠습니다.
1 Introduction
본 논문에서는 Convolutional Neural Network, CNN의 성능에 영향을 미치는 대표적인 중요한 세 요소로 depth, width, cardinality를 말하고 있습니다.
흔히 알고 있듯이 CNN에서 Network의 depth가 깊어지면 일반적으로 더 좋은 성능을 낼 수 있습니다. 하지만 일반적으로 depth의 증가는 Gradient vanishing 문제를 초래할 수 있는데, 이를 위해 Skip connection등의 다양한 방법을 활용하여 방지하여 Network를 깊게 쌓아 좋은 성능을 보이고 있습니다. 대표적인 예로는 LeNet, VGG, ResNet 등이 있으며 ResNet은 152층의 Layer를 쌓아 올려 성능 향상을 보였습니다.
다른 측면에서 width는 channel 수를 늘려 모델이 다양한 channel을 학습할 수 있도록 하는 것으로, GoogLeNet과 WRN에서 성능 향상을 보였습니다.
Xception과 ResNeXt는 Network의 cardinality를 통해 성능 향상을 보였는데, 이 때 cardinality는 동일한 Block을 반복 적으로 구축하여 모델링 하는 것으로, depth나 width에 비해 더 좋은 표현력을 지니고 있습니다. 아래의 ResNet과 ResNeXt의 모델 구조를 보면 금방 눈치챌 수 있을 것 입니다.
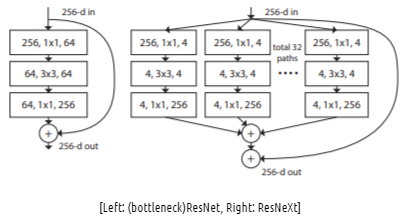
하지만 본 논문에서는 이러한 세 요소를 뒤로 한 채, Attention 이라는 측면에 집중하고 있습니다. Attention은 영상의 어떤 것에, 어떤 부분에 집중할 지 선택할 수 있도록 도와주는데, 이는 중요한 Feature들에 집중함과 동시에 필요치 않은, Outlier 등을 억압하는 효과를 동시에 내고 있습니다.
이 구문은 국문보다 원문 그대로 이해하는 것이 이해에 도움이 될 것으로 보아, 아래의 원문을 보고 다시 설명하겠습니다.
Attention not only tells where to focus, it also improves the representation of interests. Our goal is to increase representation power by using attention mechanism: focusing on important features and suppressing unnecessary ones.
CNN에서 Attention mechanism은 “What”과 “Where”의 문제로 대표되는데, 이는 곧 의미 있는 Feature를 강조하고자 어떤 것에 집중할 지, 그리고 어느 부분에 집중할 지의 문제로 해석할 수 있습니다. “What”, 어떤 것에 집중할 지는 Channel Attention, “Where”, 어느 부분에 집중할 지는 Spatial Attention으로, 이 부분에 대해서는 스스로의 이해를 토대로 한 예시를 들어 Module Block에서 자세히 설명하겠습니다.
Attention, 정말 듣기 좋은 말로 들립니다. CNN이 어떤 것과 어느 부분에 집중할 지를 잘 안다면, Classification 이외에도 Detection, Segmentation 등에 다양한 분야에 활용될 수 있을 것으로 보입니다. 논문의 저자는 Grad-CAM이라는 visualization method를 사용하여 실제로 CBAM이 network가 target에 더 집중하는 모습을 보임을 증명했는데, Grad-CAM은 특정 클래스 이미지의 Heatmap을 생성하여 실제로 CNN이 그 이미지 내 어떤 부분에 집중하여 해당 부분을 특정 클래스로 분류 에측할 수 있었는지 등을 알 수 있는 방법입니다. CAM에서는 마지막 Convolution Layer를 통과한 Feature map에 Global Average pooling을 통해 Input image의 전체 내용을 함축하는 방법으로 Heatmap을 그리고 있는데, 이 때 Global Average Pooling Layer를 반드시 사용해야 한다는 등의 이유로, Global Averge Pooling을 제외한 FC Layer를 이어 붙이는 방법인 Grad-CAM이 도입되었습니다.
아래는 Heatmap의 예시로, 위의 내용을 토대로 본다면 CBAM을 사용 시 network가 사람에 조금 더 잘 Attention하고 있는 모습을 볼 수 있습니다. Heatmap에 대해서는 익히 알고 있었지만, Attention mechanism이 그 의미는 이해를 하더라도 Black Box Model처럼 느껴졌었는데, 이제는 한층 더 신뢰성이 있게 느껴지는 것 같습니다.
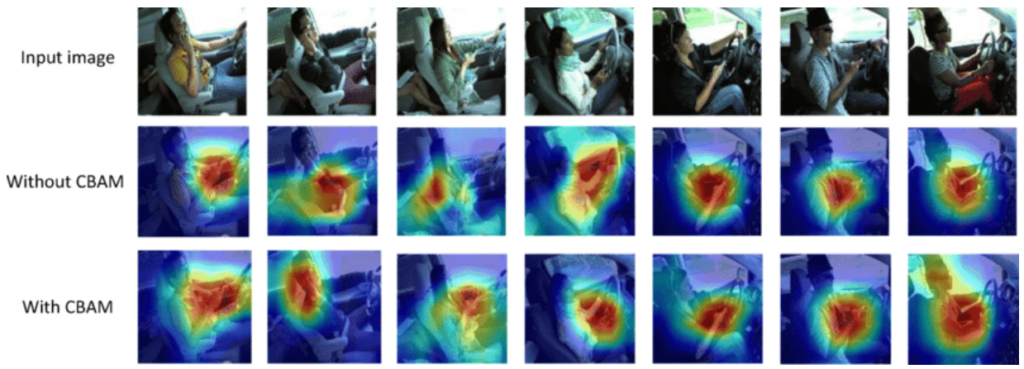
여타 다른 논문들이 그러한 이유로 쓰여졌듯, CBAM을 활용하여 정확한 Attention과 noise reduction으로 ImageNet-1K, MS COCO, VOC 2007 dataset에서 성능 향상을 보였으며 해당 모델이 굉장히 light-weight하기 때문에 computation 성능이나 parameter의 수에 대해서는 무시할 수 있을 정도라고 합니다. 아마 Detection 분야에서 FPS의 문제에서, 해당 방법론을 사용할 시 굉장히 사소한 차이를 나타내는 것으로 보입니다.
2 Related Work
Attention은 사람의 인지와 관련된 문제로, 핵심은 사람의 시각적 인지는 물체를 인지할 때 전체 장면을 한번에 해석하지 않는다는 점입니다. 사람은 힐긋 보는 찰나에, 어디에 집중할 지를 선택적으로 판단하여 물체에 대한 구조를 효과적으로 판단할 수 있습니다.
본 논문 이전, Encoder-Decoder 방식의 RAN을 제안하여 이러한 인간 지각의 Attention을 CNN에 효과적으로 적용하고자 하였으며 이러한 방식은 Feature map을 정제하여 성능을 향상하고 noise에 강한 효과를 얻을 수 있었습니다. 다만 이전과 달리 CBAM에서는 Attention을 channel과 spatial로 분리하여 Attention map을 만들고 있음을 말합니다.
또한 SENet에 비교하여 Max-pooling을 사용하고 Sptial Attention을 추가했다, 이러한 방식으로 “Where”, 즉 어디에 집중할 지를 알 수 있고 특히 detection task에서 보다 효과적이고 좋은 성능을 낸다고 하는데, 그렇다면 그들이 주장하고 자부심을 갖는 CBAM은 어떤 방법으로 구성되어 있을까요? 사실 생각보다도 더 간단합니다.
3 Convolutional Block Attention Module
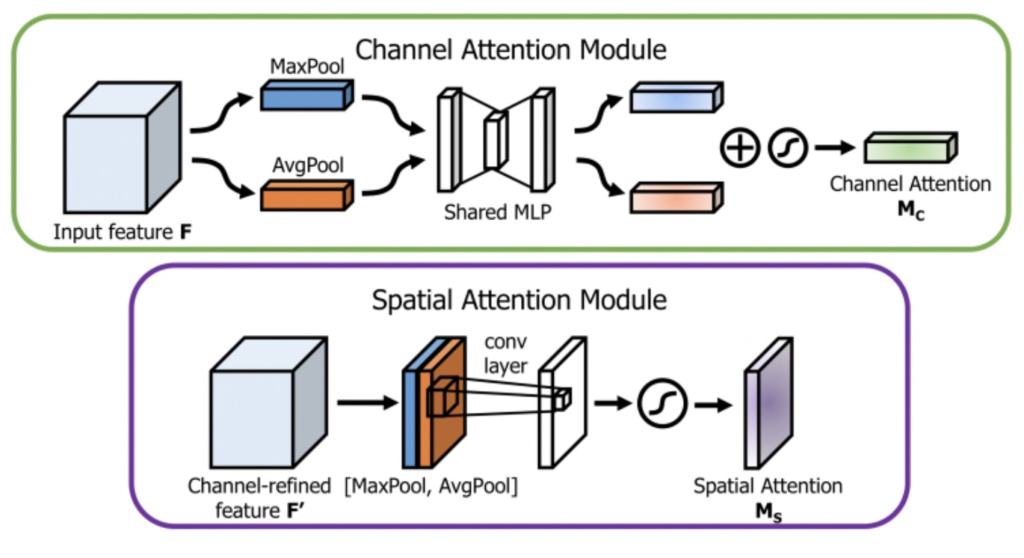
위는 CBAM의 Channel Attention과 Spatial Attention Module입니다. Channel Attention에 대해서 조금 더 자세히 설명하고 싶은데, 그렇다면 SE Net의 Channel Attention을 보는 것이 더 도움이 되겠네요.
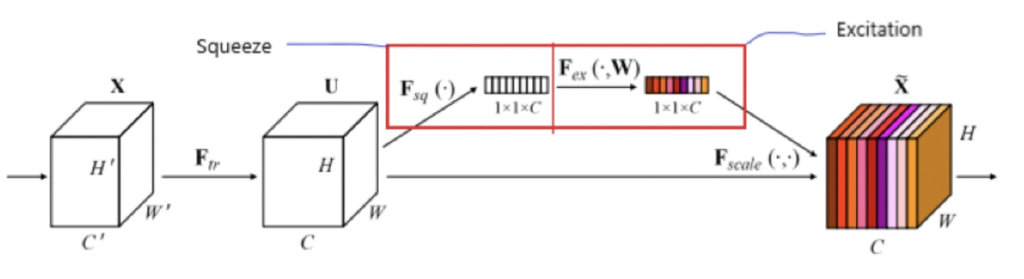
그래서 들고 온 SE Net Architecture입니다. Attention module에 들어가기 이전 Feature map F^U 를 Squeeze, 압축해주는 연산을 합니다. 이 때 Channel별로 압축하여 1 \times 1 \times C 의 F_{sq} 를 생성합니다. 이는 어떤 의미일까요?
Channel별로 학습된 F^U 이 H \times W \times 6 형태라고 예를 들어보면, channel별로 생각해봤을 때 6개의 Feature map F_1^U, F_2^U, \cdots , F_3^U 은 서로 바라보는 관점이 다르게 학습했을 것 입니다. 이러한 Feature map F_1^U \sim F_6^U 을 Global Average Pooling을 통해 1 \times 1 \times 6 으로 압축한다면, 그 압축한 정보는 해당 Feature map F^U 를 Channel 별로 압축한 정보를 담고 있다고 볼 수 있습니다.
이제 Excitation, 재조정 단계입니다. Excitation에서는 압축한 정보를 전체의 맥락으로 사용하고 싶을 것 입니다. 이 단계에서는 Bottle neck 구조로 Squeeze된 F_{sq} 에 \operatorname{ReLU} 로 Channel 간 비선형성을 넣어 Channel들의 Relationship에 초점을 두었으며, 따라서 Channel을 Reduction Ratio인 r로 수축한 다음, \frac{c}{r} 로 수축된 벡터를 다시 FC Layer를 통해 C개로 출력하여 \operatorname{Sigmoid} 를 통한 C개의 벡터 F^\prime 으로 만들어, 이 확률 벡터를 원래의 Feature map F^U 에 곱해줍니다. ( F \otimes F^\prime )
애매모호하다고 볼 수 있지만, 쉽게 생각하여 Squeeze와 Excitation의 연산으로 나온 확률 벡터 F^\prime 은 Channel들 사이의 Relationship을 충분히 고려하고 있으며, 확률 벡터로 Attention score를 사용함을 알 수 있습니다.
SE Net의 Channel Attention을 이해했다면, CBAM의 Channel Attention과 Spatial Attention은 이제 이해하기에 훨씬 수월할 것으로 보입니다. Channel을 한 명의 전문가로 생각한다면, 각각의 채널에서 나오는 정보들은 다른 전문가들로 부터 나오는 정보를 취합하는 것이 이미지를 인식하는 것에 조금 더 도움이 될 것 입니다. 예를 들어 포도를 인식한다고 할 때, 한 전문가는 포도의 둥근 모양에 집중하고, 다른 전문가는 포도의 색상에 집중한다면, 두 전문가의 의견을 취합하는 것은 포도를 인식하는 것에 훨씬 도움이 될 것 이기 때문입니다.
그렇다면 CBAM에서 Channel Attention과 Spatial Attention은 어떻게 구성되는 지에 대해 보겠습니다. W\ times H \times C의 Feature map F 를 Max-pooling과 Avg-pooling을 통해 1 \times 1 \times C , 1 \times 1 \times C 로 만든 다음 공유되는 하나의 MLP에 넣어 SENet과 동일한 Squeeze, Excitation 연산을 진행합니다. 이후 나온 둘을 더한 다음 Sigmoid를 통해 다시 1 \times 1 \times C 의 M_c 로 만들어줍니다. 이 과정이 Channel Attention이며, 다음은 Sptial Attention입니다.
Spatial Attention은 Channel Attention을 통해 나온 Feature map M_c에서 Max-pooling과 Avgerage-pooling H \times W \times \ 1 , H \times W \times 1 을 Channel로 concat하여 Convolution을 통과한 다음 Sigmoid를 통해 M_s 를 구하게 됩니다. pooling하여 나온 두 Feature map을 Convolution layer을 통과시켜 확률 벡터로 만든 다음, 이를 다시 F\prime 와 곱하면 최종적으로 Channel Attention과 Spatial Attention이 직렬로 구성된 CBAM Module이 완성됩니다. 위의 내용을 본 논문에서는 다음의 수식으로 표현합니다. 참고로 저자는 두 Attention module을 병렬로 구성해보고(BAM) 직렬로(CBAM) 구성해봤을 때, 직렬로 구성했을 때 더 좋은 성능을 보였다고 말합니다. 또한 Channel Attention을 먼저 적용하는 것이 Spatial Attention을 먼저 적용하는 것에 비해 아주 조금이지만 더 좋은 성능을 보였다고 합니다.
F^\prime = M_c(F) \otimes F
F'' = M_s(F\prime) \otimes F\prime
M_c(F) = \sigma (MLP(AvgPool(F)) + MLP(MaxPool(F)))
= \sigma (W_1(W_0(F_avg^c)) + W_1(W_0(F_max^c)))
M_s(F) = \sigma(f^{7 \times 7} (\left[AvgPool(F); MaxPool(F) \right]))
= \sigma(f^{7 \times 7} (\left[F_avg^s ; F_max^s \right))
4 Experiments
ImageNet-1K classification, MS COCO, VOC 2007 object detection에서 실험을 진행했습니다. 흥미로운 점은 ResNet 계열의 다양한 Network에서 동일 기준으로 비교하고자 PyTorch로 재구현하여 비교했다고 합니다. 아래의 표들을 살펴보며 몇몇 점들을 말씀드리겠습니다.
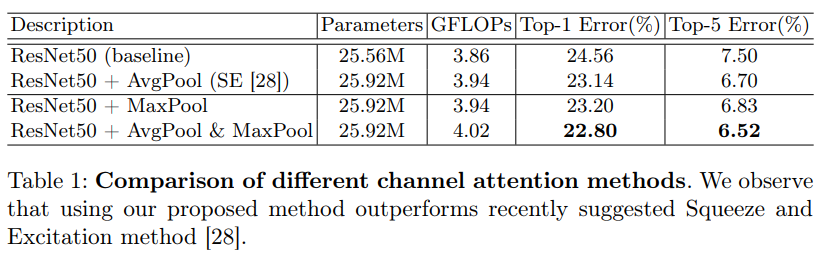
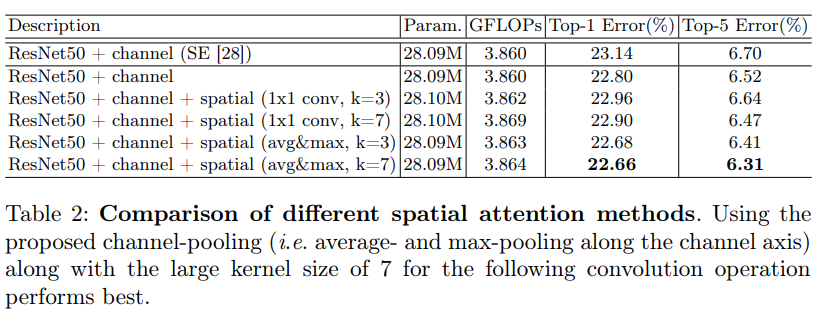
위의 Ablation studies는 Channel 별 Pooling 방법을 비교하며 실험했을 때, Avg-Pooling과 Max-Pooling을 동시에 사용하였을 때 성능이 높음을 보였으며 아래의 Spatial Attention은 1×1 convoluton layer와 Avg-pooling + Max-pooling, convolution layer의 kernel size를 3×3과 7×7로 비교하여 성능을 비교했을 때 Avg-pooling + Max-pooling + 7×7 kernel size의 성능이 가장 높음을 알 수 있습니다.
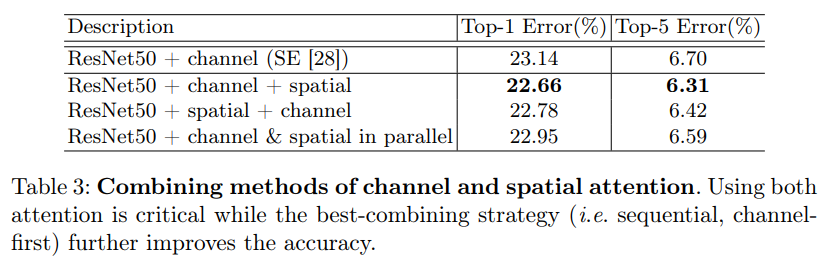
위의 두 Ablation studies를 바탕으로 Channel Attention 먼저, Spatial Attention 먼저, 두 Attention을 병렬로 구성했을 때의 Top-1, Top-5 Error를 비교했을 때, Channel Attention을 먼저 수행하는 것이 더 좋은 성능을 보임을 알 수 있습니다.
이제 ImageNet-1K에서의 Classification results입니다.
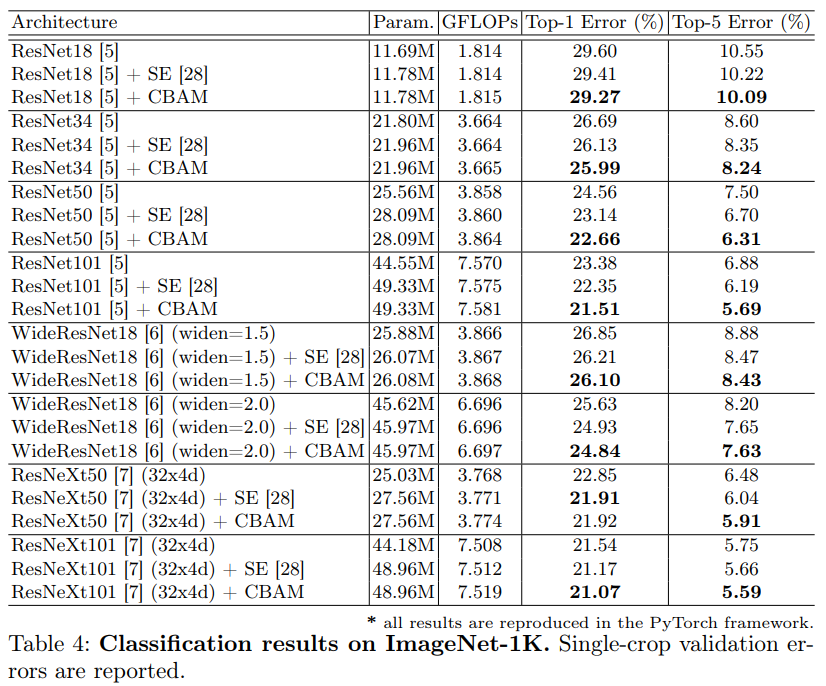
위의 Abulation studies에서 확인한 방법들을 토대로 Baseline, SENet과 비교했으며, ResNeXt50을 제외한 나머지에서는 모두 CBAM이 성능이 뛰어남을 볼 수 있습니다. 물론 그 성능 향상이 눈에 두드러지는 정도는 아니지만, 다양한 Network에서 범용적으로, 쉽게 사용할 수 있다는 점에서 그 의의가 있는 것 같습니다. 이제 처음 말했던 Grid-CAM visualization입니다.
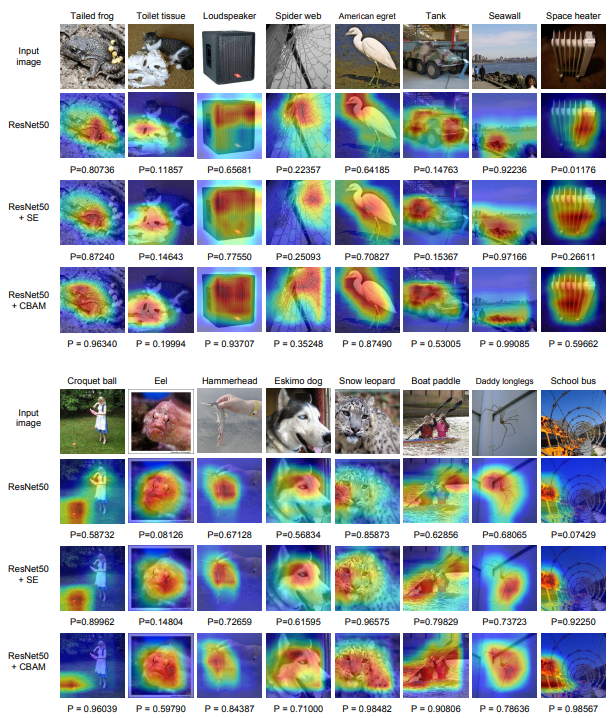
HeatMap을 살펴보면, 기존 방법보다 Attention 방법론이 조금 더 object에 강조되어 있음을 알 수 있습니다. 하지만 그 차이가 다소 크지는 않은 것으로 보아, 성능 향상이 미비했던 이유도 이해됩니다. 그렇다면 detection에서는 어떨까요?
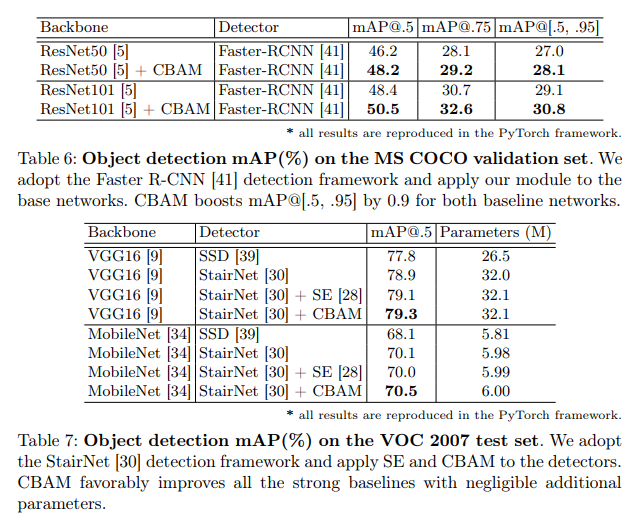
사실 VGG16의 SSD를 활용한 CBAM 방법으로 실험했더라면 좋았을 테지만, MS COCO 및 VOC 2007 dataset에서 다른 1-stage, 2-stage Baseline 방법 및 SENet과의 비교에서 좋은 성능을 보이고 있습니다.
5 conclusion
CBAM을 통해 CNN의 표현력을 높이고자 한 새로운 접근 방법인 Attention의 성능을 높이고 이를 토대로 classification 뿐만 아니라 detection 분야에서 좋은 성능을 보인 것에 의의를 두고 있습니다.
저는 해당 논문을 토대로 Kaist Pedestrian에서 Fusion 시 Attention을 통해 Fusion된 Feature map의 표현력을 Enhanced해보고자 했고, 또한 그에 더하여 밤낮에 따른 RGB, Thermal에 Attention을 따로 두어 실험해보고 있습니다. 하지만 CBAM 방법론이 실제 기대했던 것 보다 낮은 성능을 보여 그 원인을 스스로 분석했을 때, 1×1으로 Flatten하며 공간적인 정보를 잃는 것이 문제점이 되지는 않을까 생각하고 있습니다. 따라서 이 점을 보완한 Coordinate Attention을 토대로 실험했을 때, H-Fusion 대비 0.4% mAP 향상을 보였는데, 그보다도 Attention mechanism을 확실하고 쉽게 이해할 수 있는 논문이라는 점에 의의를 두고 있습니다.
좋은 리뷰 감사합니다.
리뷰를 읽다 아래 문장이 잘 이해가 되지 않아서 질문을 남깁니다.
”CAM에서는 마지막 Convolution Layer를 통과한 Feature map에 Global Average pooling을 통해 Input image의 전체 내용을 함축하는 방법으로 Heatmap을 그리고 있는데, 이 때 Global Average Pooling Layer를 반드시 사용해야 한다는 등의 이유로, Global Averge Pooling을 제외한 FC Layer를 이어 붙이는 방법인 Grad-CAM이 도입되었습니다.”
라고 하셨는데 Global Average Pooling Layer를 반드시 이용하는 것이 어떠한 문제가 있기이 Grad-CAM이 도입된것인지가 빠져있는 것 같습니다.
이에 대해 설명해주실 수 있나요??
또한, Coordinate Attention은 상인님이 디자인하신 attention 방법론인가요??
네. 좋은 코멘트 감사합니다.
1. 먼저 첫 번째 질문에 대하여 말씀드리자면, CAM은 Global Average Pooling(GAP)을 사용하는 특정 모델에만 사용할 수 있는 방법입니다. 즉 모델의 Architecture의 마지막에 GAP가 사용되어야만 한다는 점인데, 이것이 하나의 단점입니다. 저도 HeatMap을 그리는 CAM과 Grad-CAM에 대하여 처음 살펴 본 사실이라, 조금 더 자세히 찾아봤을 때 먼저 CAM이 등장하게 된 계기는 GAP가 Regularization, 즉 Outlier 들에 대처하고자 하는 용도로 제안되었지만, CNN에서 GAP를 사용 시 해당 Feature map의 Attention을 나타내는, “Generic localizable deep representation”을 구축한다고 다음의 논문 (Learning Deep Features for Discriminative Localization)에서 말합니다. GAP는 FC Layer와 비교하여 생각해봤을 때 왜 이 Pooling Layer가 Attention의 Heatmap을 그려줄 수 있는지, 위치 정보의 손실과 보존 측면에서 분석했을 때 조금 더 알기 쉬웠던 것 같습니다. 사실 질문해주신 부분에 대해서는 맨 처음 말씀드린 것 처럼 “GAP를 사용하지 않는 CNN 모델들에 보다 일반적인 방법으로 사용될 수 있다”가 정답입니다. 그렇다면 CAM과 Grad-CAM에 대한 비교 설명이 조금 더 들어가는 것이 이해에 도움이 되겠다는 생각이 드네요. CNN 모델이 K개의 Feature map을 내놓는다면, GAP를 적용하면 총 K개의 output을 얻을 수 있을 것 입니다. 이를 선형 결합한 다음 Softmax를 적용하면 class C_1에 대한 F_1, F_2, …, F_K의 중요도를 얻을 수 있으며, 이를 토대로 하나의 class activation map을 만들 수 있고, 원 입력 이미지의 사이지로 Upsampling하면 특정 클래스와 관련된 부분에 중요도가 Heat되어있을 것 입니다. 반면 GAP가 없더라도 범용적으로 CAM을 사용하고자 등장한 Grad-CAM은 CAM의 가중치를 다른 값으로 대체하는데, 이를 위해 Grad-CAM의 저자는 새로운 notation을 정의합니다. 조금 복잡하지만 결국 Target class에 대한 Activation map을 구한 다음 이에 ReLU를 적용하여 해당 클래스에 대한 영향력을 조사하여 Heatmap을 그리는 방식을 사용합니다. 조금 더 자세한 설명이 본문에 추가되었어도 좋았을텐데, 이 점 짚어주셔 감사합니다.
2. Coordinate Attention은 CVPR 2021, “Coord Attention for Efficient Mobile Network Design”이라는 이름으로, MobileNet의 Design에 적합하도록 설계된 방법론입니다. CBAM이 Channel Attention과 Spatial Attention을 수행할 때 1x1xC로 Flatten하는 것에 문제점을 제기하며 Hx1xC, 1xWxC의 가로,세로의 특성을 유지하며 진행하는 Attention 방법입니다. 해당 방법론에서 Hx1xC, 그러니 즉 세로 성분의 Attention 특성을그대로 보존하는 것이 Kaist Pd dataset에 도움이 될 것으로 판단하여 적용했습니다.
해당 설명이 미흡하거나 혹은 추가 질문 있으시다면 코멘트 달아주세요!
좋은 리뷰 감사합니다. attention 관련 개념에 아직 잘 익숙하지 않은데 꼼꼼하게 설명을 해 주셔서 이해하기에 수월했습니다.
공간적 정보에 집중하고자 하는 spatial attention과, 의미론적 정보에 집중하고자 하는 channel attention. 이렇게 두가지로 나누어 지는것이 뭔가 제가 오늘 리뷰한 HRNet과 살짝은 비슷하다는 생각이 드네요.
제가 attention 관련 논문을 많이 읽어보지 않아서 그런데, 이렇게 spatial과 channel로 나누어서 따로 진행을 하는 시도가 본 논문에서 최초인 것인가요? 아니면 다른 논문에서 차용한 방식인건가요??
그리고 추가적으로 Channel Attention 부분에서 HxWxC인 Feature map F^ U 와 1x1xC의 확률벡터(?) 를 곱해준다고 하셨는데, element wise 느낌으로다가 HxWxC인 feature map 모든 픽셀에 값을 곱해주는게 맞나요??
그리고 classification, detection 말고도 다른 분야에 사용될 가능성이 충분해 보이는데, 다른 분야에 대한 실험은 없었는지도 궁금합니다.
감사합니다
안녕하세요. 먼저 좋은 질문점으로 생각듭니다.
1. CBAM 이전 큰 가닥으로 SENet과 RCAN, FFA-Net 등이 존재했으며, 그렇다면 CBAM에서 비교 분석한 SENet과의 비교로 설명드리자면 먼저 Spatial과 Channel로 나누어 따로 진행하는 것은 CBAM이 최초이자 최초는 아닙니다. 어떻게 보면 굉장히 모순적인 말인데, CBAM 저자가 몇년 전 BAM이라는 논문에서 Spatial Attention에 대하여 언급하고 실험했습니다. 그러나 BAM에서는 Sptial과 Channel Attention이 별도로 병렬적으로 진행되는 것에 반해 CBAM은 Channel과 Spatial Attention을 직렬적으로 구성한다는 점에서 그 의의가 있습니다.
2. 이 부분에 대하여 Sigmoid를 타고난 다음 확률로 나온 벡터를 곱하는 연산이다! 하고 이해하는 것이 더 도움이 될 것이라 생각하여 넘어갔지만, 정확히 코드 상으로 구현 시에는 공유되는 MLP를 거친 AvgPool과 MaxPool output을 더하여 Sigmoid를 한 다음, Shape을 맞춰줍니다. 다음의 코드를 살펴보는 것이 더욱 도움이 되겠네요! attention = attention.unsqueeze(2).unsqueeze(3).expand_as(out); return out * attention / 그렇다면 모든 pixel이라기 보다는 일치하는 pixel 마다 곱해주는 것이 맞는 것 같은데 제 생각이 맞을까요?ㅎㅎ
3. 해당 논문에서는 다른 분야에 대한 실험은 없었지만 (아직 Attention이 CNN에 적용되고서 그 성능 향상이 그렇게 크지 않아서일까요,) Classification, Detection 말고도 다양한 분야에 적용 가능할 것으로 보입니다. 특히 어쩌면 그 개념이 NLP에서 온 점을 토대로 생각해보면 Multi-modal에서 Attention은 더 큰 성능 향상을 가져오지 않을까.. 생각해봅니다.
안녕하세요. 좋은 리뷰 감사합니다.
1. 궁금한 부분이 있는데 introduction에서 attention mechanism이 what where 문제로 대표된다면서 channel attention, spatial attention을 설명해주셨는데, 그러면 원래 대부분의 CNN에서는 channel attention 하나만 혹은 spatial attention 하나만 이렇게 하나에 대해서 attention하나요? 그래서 이 논문의 방법론 CBAM은 두개 모두 사용한 것이 contribution이 되는 걸가요?
2. channel attention 설명해주시는 부분에서 질문이 있습니다. 우선 저는 text 분야에서 attention 사용하는 부분을 주로 봐서 cnn에서 attention 적용하는 부분이 조금 이해가 잘 안되는 부분이 있어 질문합니다.
보통 attention 메커니즘이라 하면, query, key value가 있고, query key를 통해 attention score를 구하고, 이후에 softmax를 통해 attention distribution을 구한 뒤, 구한 확률값을 가지고 value를 곱해 attention value를 얻어 사용하는 것으로 이해하고 있습니다. 그러면 여기서는 각자 다른 관점으로 학습한 F_1^U와 F_2^U가 쿼리와 키가 된다면 F_1^U, F_2^U cell 하나하나가 value가 되는 걸까요? 아니면 CBAM에서는 제가 알고 있는 attention 방식이 아닌 다른 방식을 사용한 걸까요?
사실 Excitation 단계에서 “Bottle neck 구조로,,,,” 문장에서 ReLU로 Channel 간 비선형성을 넣어 Channel의 relationship에 초점을 두었다는 말이 정확히 무엇을 의미하는지 모르겠어서 더욱 attention을 어떻게 사용했다는지 이해를 못한거 같네요…ㅜ
감사합니다.
안녕하세요. 질문 감사합니다.
1. 이전의 방법론들은 주로 Channel Attention, Spatial Attention을 분리지어 사용하고 있습니다. 대표적으로 SENet의 경우 Channel Attention, FFA-Net의 경우 Image Dehazing을 위해 Spatial Attention, 즉 Task 별에 맞춰 Channel, Spatial Attemtion 중 필요한 하나에 집중했던 추세로, CBAM 이전의 BAM(동일 저자입니다)이 병렬 구조로 Attention Mechanism을 구현한 것은 ImageNet, COCO 등의 Classification, Detection 등에서 일반적인 CNN에서의 Attention 성능을 높이고자 함으로, 정확히 말하자면 이 논문의 Contribution은 Channel, Spatial Attention에 대한 다양한 실험을 바탕으로 / Channel과 Spatial Attention을 직렬적으로 구성함, Channel Attention을 Spatial Attention에 비해 앞서 구현함, 각 Attention에서 적절한 MLP 구조 및 Convolution kernel size 등의 요소를 찾아 최적의 성능을 내었다는 것에 있습니다.
2. 저도 NLP에서의 Attention에 대하여 정확히는 아는 바가 없지만, 찾아본 다음 빗대어 설명해보겠습니다. 예를 들어 현 Task가 Object Detection이라고 한다면, Query는 input Feature map, Key는 해당 object라고 볼 수 있겠네요. 그렇다면 Query를 통해 Attention을 뽑고 나서(어떠한 Attention mechanism을 사용할지는 Task에 따라, 주어진 환경에 따라 상이할 순 있겠네요), 해당 Attention map을 Attention score(Sigmoid를 태운 다음 나왔기 때문에, 확률적인 값으로 볼 수 있겠습니다.)를 구한다면, Softmax를 통해 Attention distribution을 구한다는 것이 CNN에서는 Softmax를 통해 “가장 object가 있음직한” 곳에 대한, 혹은 클래스에 대한 (전자는 Spatial, 후자는 Channel Attention에 해당할 수 있겠네요) Distribution (Attention Distribution이 결국 하나의 이미지에 대한 여러 채널 혹은 K개의 Feature map에서 Softmax를 태운 다음 나온 값들을 분포화한 것으로 이해할 수 있겠습니다. 이를 Visualization으로 확인하고자 한 Task가 본문에 나온 Grad-CAM이 되겠습니다.) 그렇다면 이러한 이해를 바탕으로 F_1^U에 대한 질문에 답해본다면, F_1^U를 Query로 볼 때 Key는 GT가 맞지 않을까요? 저도 이 점에 대해서는 확신이 찬 답변이 쉽지 않을 것 같네요ㅎㅎ.. Query와 Key를 비교하여 Query에서 Attention score를 뽑아내는 것이 맞다면, Key는 GT가 맞다는 생각입니다. 한 이미지에서 뽑아낸 하나의 Feature map(F^U)이 사람을 탐지한다고 예시를 들어보자면, F_1^U는 사람의 머리쪽 곡선에, F_2^U는 사람의 옷 색상을 담당하는 Channel이라고 생각해보겠습니다. 물론 하나의 Feature map에서 위와 같이 다른 레벨의 Feature가 뽑히지는 않겠지만, 예시로 그렇다면 F_1^U가 Query로 할 때와 F_2^U를 Query로 할 때, 두 Query에 대한 Key는 동일해야 Attention score에 신뢰성이 있다고 말할 수 있을 것 같습니다.
3. ReLU는 동차성은 성립하지만 가산성은 성립하지 않은 비선형 함수입니다. 이러한 비선형 함수를 Network에 넣는다면 네트워크는 그만큼 깊어질 수 있고 더 복잡한 특징을 연산할 수 있습니다. 사실 MLP의 깊이가 매우 얕기 때문에 ReLU로 Channel의 Relation에 초점을 두고 있다는 의미는 아주 엄밀히 따져보자면 애매하지만, 그저 이 Task에서는 ReLU의 사용보다는 공유되는 MLP를 사용하고 있어 Avg-Pool과 Max-Pool을 통과시킨 다음 결합해, 마치 Fusion처럼 1x1xC로 되어있는 두 벡터를 결합한 다음 Sigmoid를 취해준다는 점에 조금 더 포커스를 맞추는 것이 맞다는 생각이 드네요. 저도 설명하다 보니 제 설명의 방향성이 ReLU로 인해 그렇다!처럼 들려서 아쉬움이 남습니다 감사합니다.
안녕하세요, 좋은 리뷰 감사합니다.
Attention에 관심이 있어 해당 논문을 읽게 되었습니다.
작성해주신 내용 중, “W timesH×C의 Feature map F를 Max-pooling과 Avg-pooling을 통해 1×1×C 1×1×C , 1×1×C 1×1×C로 만든 다음 공유되는 하나의 MLP에 넣어 SENet과 동일한 Squeeze, Excitation 연산을 진행합니다. ” 라고 설명을 해주셨는데
그럼, 원래 SENet의 Channel attention을 수행하는 module과 CBAM에 해당하는 Channel Attention module은 같은 결과를 수행하는 것으로 이해하면 될까요?
추가적으로 Skip connection을 사용하면 Depth에 따른 Gradient Vanishing 문제를 무조건 해결할 수 있는 건지도 궁금합니다.
안녕하세요. 리뷰 읽어주셔서 감사합니다.
해당 질문에 대해서 답변하자면 나름 가볍게 답변할 수 있을 것 같네요.
우선, 네. 맞습니다. CBAM의 Channel Attention은 SENet의 Channel Attention과 동일하게 수행합니다. CBAM에서는 Channel Attention 뿐만 아니라 Spatial Attention을 직렬적으로 제안한 것이 Main contribution일 뿐, Channel Attention에 어떤 다른 변형을 가한 것은 아닙니다. 하지만 지금 시점에서 논문을 읽다보니 진정한 의미의 Channel Attention이라고 볼 수 있는지에 대해서는 의문이 드네요. 해당 1x1xC로 만든 다음 MLP에 넣는다는 의미는 채널 별로 어떠한 압축된 정보를 토대로 채널 별 연산을 진행한다는 것인데, 그러한 압축된 정보를 뽑는 과정에 대해 단순히 GAP 등을 사용하기 때문입니다. 그렇다면 학습 과정에서 채널 별 정보를 보정해주는 어떠한 연산이 있었으면 좋았을텐데 하는 아쉬움이 남네요. 물론 제 사견일 뿐입니다. 기본적으로 GAP는 하나의 채널에 대한 HxW 정보를 압축한다고 보긴 합니다.
두 번째 질문에 대해서는 Skip connection을 사용하면 Depth에 따른 Gradient Vanishing 문제를 해결할 수 있는지에 관해서인데, 무조건 해결한다고 장담은 못하겠네요. 예를 들어, 초기 Weight가 적절하지 않고 너무 낮았더라면 Skip connection을 통해 Weight을 더해주더라도 Gradient vanishing을 막는다고 보기에는.. 저는 애매합니다. 하지만 기본적으로 잘 초기화된 Weight에서 연산을 진행할 때 Skip connection을 사용한다면 Gradient vanishing 문제를 해결할 수 있습니다. 해당 내용에 대해서는 예전 신정민 연구원이 댓글 달아주신 것 중 하나의 페이지가 있어서 공유합니다. https://ganghee-lee.tistory.com/41
안녕하세요. 좋은 리뷰 감사합니다.
Channel Attention과 Spatial Attention에 대해 정확히 이해하지 못해 보충 설명이 가능할까요?
Channel Attention과 Spatial Attention이 직렬적으로 일어난다는 말과 병렬적으로 일어난다는 말은 어떻게 다른지 알려주시면 감사하겠습니다.
감사합니다.
Channel Attention은 HxWxC에서 Channel 사이의 Attention 연산이라고 생각하면 됩니다. 그렇기에 하나의 (HxWx1) x C에서 (HxWx1)을 GAP를 통해 하나로 합친 다음, 그만큼 C 채널만큼 Attention 연산을 진행하게 됩니다. 그렇다면 Spaital Attention은? (HxWxC)를 (HxWx1) x 2로 변환해주는 과정입니다. 이를 통해 Channel 축으로 Average pooling과 Max pooling을 하여 공간 간의 연산을 진행한다고 이해하시면 될 것 같습니다.
두 Attention 연산이 직렬적으로 일어난다는 것과 병렬적으로 일어난다는 것은 서로의 연관성이 얼마나 있느냐를 보는 것이라고 생각하면 됩니다. 이에 대해 저자 또한 Ablation study에서 실험을 토대로 근거를 내세운 것으로 보입니다. 감사합니다.
안녕하세요, 상인님. 좋은 논문 리뷰를 남겨주셔서 감사드립니다.
what과 where라는 두 가지 요소를 모두 고려하기 위해 CBAM을 적용한 점이 특히 인상 깊었습니다.
저는 이번 Summer URP에 참여하여 챌린지 기간 동안 SSD의 성능 개선을 목표로 CBAM을 활용해 feature map attention을 실험한 경험이 있습니다. 상인님께서 말씀하신 것과 마찬가지로, 저 또한 SSD에 CBAM을 적용하면 SE 모듈보다 MR이 낮게 나올 것으로 예상했지만, 실제 결과는 예상과 달리 CBAM의 MR이 더 높게 나오는 것을 확인하였습니다. 이에 대해 원인을 찾고자 여러 자료를 살펴보았으나 명확한 해답을 얻지는 못했습니다. 다만, 일부 논문에서는 CBAM이 조명 변화가 있는 상황에서 잡음이나 배경을 과도하게 강조하는 문제가 있다고 언급한 것을 확인했습니다.
혹시 상인님께서는 이러한 현상이 발생하는 이유에 대해 따로 조사하신 내용이 있으신지 궁금합니다. 또한, 이와 관련된 또 다른 한계점이나 해결 방안에 대해서도 의견이 있으신지 알려주시면 감사하겠습니다.
좋은 논문 리뷰 감사합니다.👍
안녕하세요. 너무 예전에 쓴 리뷰라 해당 논문이 100% 기억나진 않지만, 지금의 제 지식으로 어느 정도 설명드릴 순 있을 것 같습니다.
URP 챌린지에서 CBAM을 활용했을 때 MR이 더 높게 나온 이유는 우선 딥러닝 자체가 블랙박스이기 때문에 100% 정답은 아니겠지만, 우리가 원하는 보행자라는 객체는 실제로 이미지 내 차지하는 비율(픽셀 수)이 채 1% 가량 될 것 입니다. 사람이 많다면 그래도 한 5% 정도 되겠네요.
결국 CBAM이라는 것이 Attention, 즉 모델 입장에서 집중적으로 봐야할 부분인데, 이 집중적이란 것은 결국 사람이라는 것 보다는, 이미지 내 특징점이 될법한 부분 (아마 지금쯤 기초 교육을 받고 있을테니, 엣지 부분이나 색상이 변하는 부분 등이라고 볼 수 있겠네요)이겠습니다.
그럼 우리는 모델이 사람(보행자)에 집중할 것을 기대했으나, 그리고 기존 CBAM 논문에서 평가한 데이터셋 (일반적으로 COCO나 Pascal VOC)는 객체가 일반적으로는 이미지 내 큰 영역을 차지하며, 우리의 데이터셋과는 다소 거리가 있습니다. 이런 상황에서 모델은 오히려 픽셀이 적은 사람보다 배경 영역이나 또 다른 객체(이때 말하는 객체는 이미지에서 잘 보이는 객체, 큰 객체일 수도 있겠구요)에 집중할 가능성이 훨씬 높아집니다. 뭐 정답은 아닐 수 있지만, 그래서 그렇지 않나라고도 생각이 드네요.