안녕하세요. 오늘은 또 새로운 분야의 논문을 조금 읽었습니다. 요즘 생각이 많이 갇혀있는 것 같아서 사고의 지평선을 넓히려고 하다보니 자꾸 이렇게 찍먹을 하네요 ㅎㅎ;;
Introduction
이 논문은 few-shot classification에 대해서 다룹니다. 이 task는 소수의 학습 데이터만으로 학습을 수행하여 예측을 수행하는 것이라고 볼 수 있습니다. domain adaptation과도 비교가 조금 되는 것 같은데, few-shot classification에서는 예측해야하는 새로운 클래스가 등장한다는 점에서 가장 큰 차이를 보인다고 할 수 있습니다.
아무튼… 일반적으로는 대용량 데이터셋으로 학습한 백본 모델에 few-shot classification을 학습시킬 분류기를 따로 붙여서, 적은 양의 데이터로 얼마나 이 분포를 잘 학습시키느냐의 문제로 요약할 수 있을 것 같습니다.
여기서 그럼 또 문제가 하나 발생을 하는데요. 비슷한 문제가 여러 분야에서 등장하는 것 같긴합니다. 최근에 다크데이터 팀이 리뷰한 논문에서 알고리즘 간의 실험 세팅이 균일하지 않아 성능 차이가 발생한다는 문제점을 지적하는 논문이 있었는데요. 이 논문도 few-shot classification의 실험 세팅에 따른 성능 차이를 지적합니다.
이런 문제점들을 다 요약한 contribution을 보자면 아래와 같습니다.
- 기존 모델을 활용한 공정한 분석 과정을 통해, 모델이 깊어질수록 성능 차이가 적어지는 것을 보임
- mini-ImageNet과 CUB 데이터셋을 활용하여 높은 성능을 보이는 새로운 베이스라인들을 제시
- 도메인의 차이에 따른 성능 차이를 보여주어, 이러한 부분이 few-shot classification에서 중요함을 보임
OVERVIEW OF FEW-SHOT CLASSIFICATION ALGORITHMS
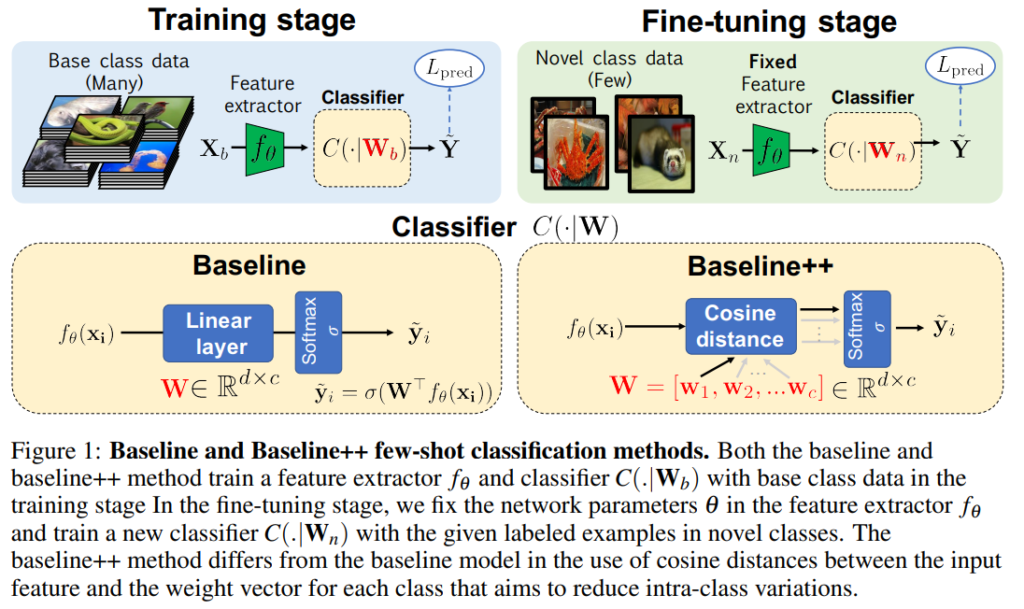
논문 내용에 베이스라인을 새로 설정하는 내용이 포함되어 있다보니 바로 베이스라인에 대한 내용으로 넘어갑니다. 일반적으로 few-shot classification에서는 위의 그림의 “Classifier”를 잘 구성하는 것이 목표입니다.
Baseline
학습은 크게 두단계(Training stage / Fine-tuning stage)로 이루어집니다. 일단 표현력을 배우긴 해야하니, 대용량 데이터셋으로 Feature Extractor(Resnet같은 백본 모델이 될 수도 있고, 그냥 CNN 레이어 몇개 연결한 구조가 될 수도 있음)을 학습합니다. 그런 다음에 목표하는 데이터셋으로 few-shot learning을 수행하는 fine-tuning stage로 나누어져 있습니다. 그래서 이 구조를 Backbone과 Learner로 나누어서 부릅니다. 논문에서 제안하는 baseline은 이러한 간단한 구조에서 Linear Layer에 softmax를 취한 간단한 분류기를 말합니다. 간단한 분류기는 다들 아실테니… 넘어가겠습니다.
Baseline++
이러한 베이스라인 말고, 확장 버전으로 Baseline++ 또한 제시하는데요. Baseline과의 차이는 cosine similarity를 사용한다는 점입니다. Cosine similarity를 사용하는 이유는 feature의 distance를 이용하는 방식인데요. 일반적으로 이런 거리 기반 분류기들로 학습을 하면 intra-class 내의 표현력이 좋아진다고 합니다.
META-LEARNING ALGORITHMS
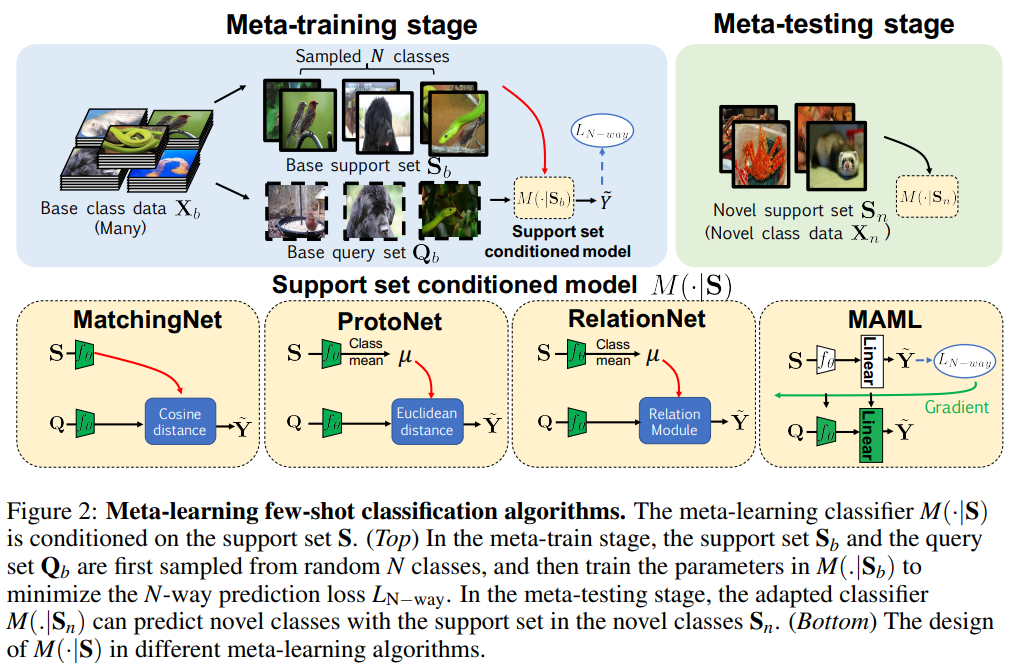
그리고 추가적으로 meta-learning이라는 개념이 등장합니다. 이건 이제 앞서 설명한 Baseline과 학습 전략이 다릅니다. 이 meta-learning에서는 Support Set과 Query Set이 등장합니다. 여기서 Query Set은 이제 예측해야하는 클래스가 담긴 데이터셋이라고 보면 되고, Support Set은 예측해야하는 클래스가 담긴 데이터셋을 학습하기 위한 이미지들이라고 보면 됩니다.
논문에서도 설명을 간단하게 넘어가서… 각각의 모델을 조금 살펴보면, MatchingNet은 Cosine similarity를 이용해서 support set과 query image와의 distance이용한 학습 방식입니다. ProtoNet은 Support Set의 이미지들의 feature의 평균을 이용한다고 보면 됩니다. RelationNet은 각 클래스의 Feature의 평균을 embedding module에 태우고, Query 이미지도 embedding Moude에 태워서 나온 각각의 Feature들을 쌍으로 concat해서 또 다른 모듈에 태워서 이미지 끼리의 관계를 배우는 네트워크입니다. 마지막으로 MAML(Model-Agnostic Meta-Learning)은 optimizer를 학습시키는 방식이라고 생각하면 될 것 같습니다.
약간 형식이 서베이 논문은 아닌데 서베이 논문같은 느낌이라 간략하게 Few-shot classification에 대해서 알아보고 넘어가는 형식이라 처음 보는 모델들이 막 등장해서 저도 딱 이정도 밖에 요약을 못하겠네요.
Experiments
데이터셋은 object recognition에서는 mini-ImageNet을, fine-grained classification에서는 CUB-200-2011을 사용했다고 합니다. cross-domain adaptation 상황도 시나리오에 있는데 이 경우에는 mini-ImageNet으로 학습하고, CUB로 넘어가서 평가했다고 합니다.
EVALUATION USING THE STANDARD SETTING
논문에서 지적했던 내용으로 알고리즘 간의 실험 세팅이 균일하지 않다는 점을 언급했었는데요. 그래서 이 논문에서는 이 세팅을 모두 다 맞춰주어 공정한 비교를 했다고 하기 위한 노력을 다룹니다.
일반적으로 few-shot classification에서 다루는 세팅으로 1-Shot / 5-Shot(클래스 마다 이미지가 몇장 있는 상태에서 학습을 하는지 마는지)을 구분하니 이 세팅을 유지했다고 합니다. 그리고 입력 크기 84×84 입력을 사용하는 4개의 Conv레이어를 사용하는 백본 하나와 Resnet 백본에서 실험을 수행했습니다.
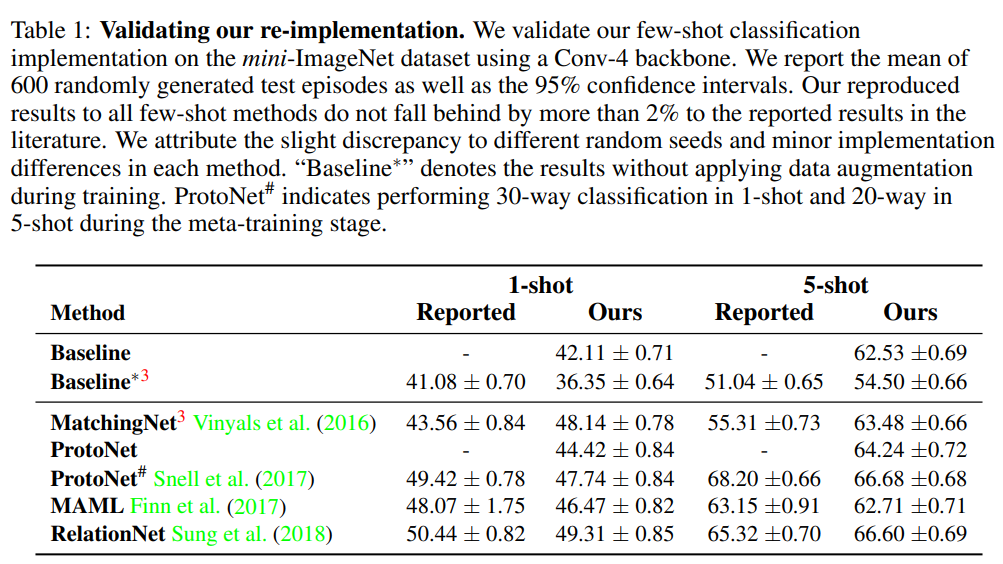
실험을 시작하기 전에 논문에서 언급한 성능을 이 논문에서 잘 구현했는지를 보기 위한 re-implementation 실험 결과입니다. 성능 차이가 좀 나는 모델들도 있기는 한데, 논문 저자들이 같은 세팅으로 맞추면서 hyper-parameter나 optimzer를 변경해서 바뀌는 성능이라서 괜찮다고 언급하고 있습니다. (Baseline 끼리의 성능 차이는 data augmentation의 적용 유무입니다.)
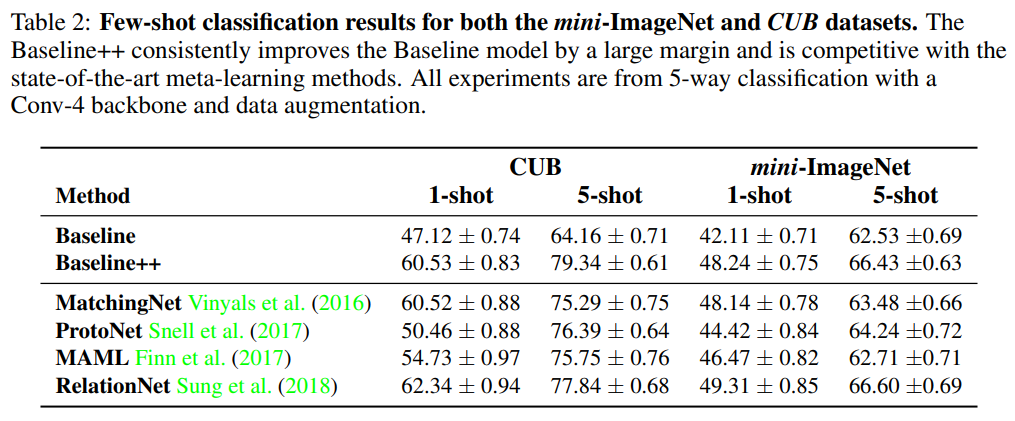
그래서 이 세팅을 바탕으로 실험 결과를 보면 [표 2]와 같습니다. Baseline 대비해서 cosine similarity를 사용하는 baseline++가 높은 성능을 보이는 것을 확인할 수 있습니다. 이러한 성능 차이를 통해서 Intra-class variation이 few-shot classification에서 중요하다는 것을 입증하고 있습니다.
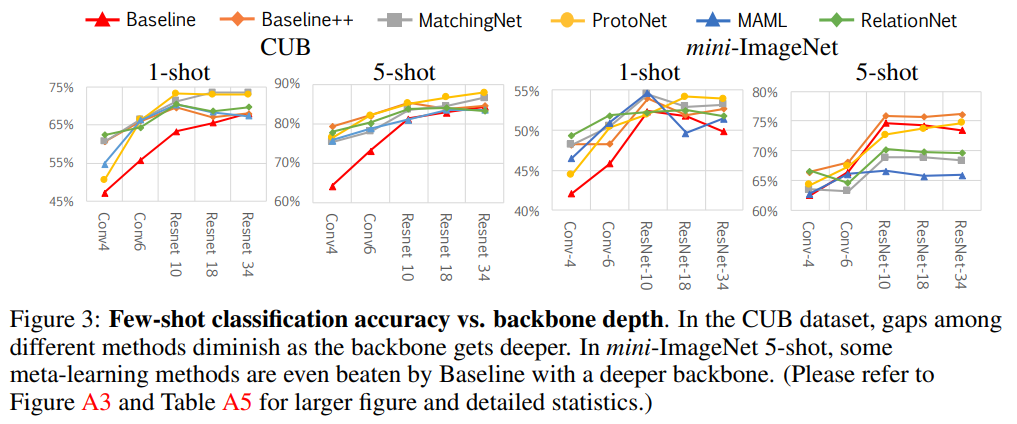
이러한 성능 차이는 사실 Conv레이어 4개를 가진 모델에서 실험을 수행한 결과입니다. 그래서 보다 복잡한 모델에서의 실험 결과를 [그림 3]을 통해서 확인할 수 있습니다. 데이터셋과 모델의 깊이에 따른 성능 차이를 확인을 해보면, CUB 데이터셋에는 모델이 깊어질 수록 방법론에 따른 성능 차이가 줄어든다는 것을 확인할 수 있습니다. 하지만 mini-ImageNet에서는 성능 차이가 벌어지는 것을 확인할 수 있습니다.
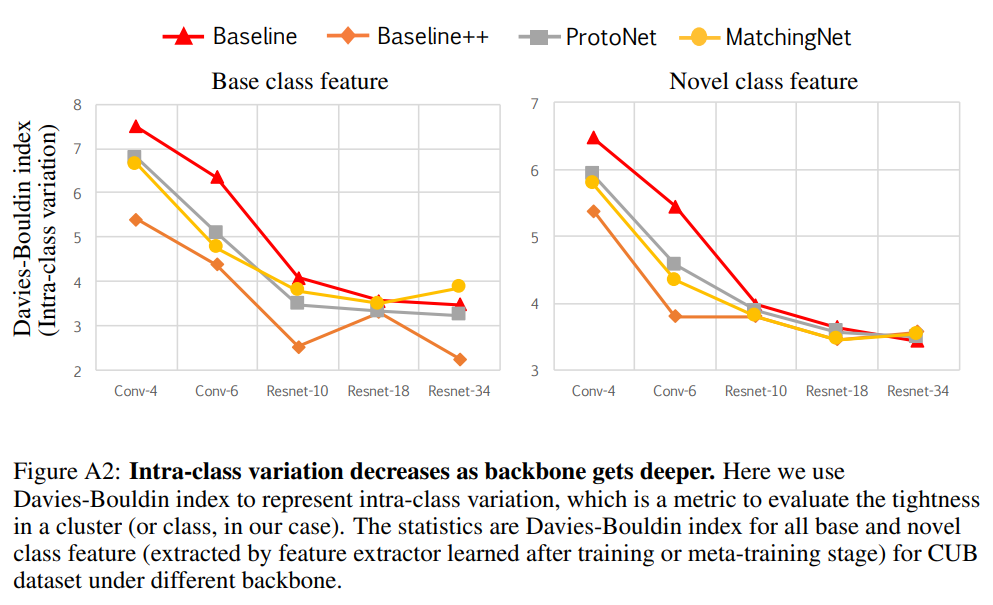
이 부분이 이제 데이터셋 끼리의 도메인 차이가 있기 때문에 이런 결과가 나온다는 것인데요. Appendix로 Davies-Bouldin index를 활용하여 백본이 깊어지면 깊어질 수록 도메인 차이가 줄어든다는 실험 결과 또한 제시했습니다.
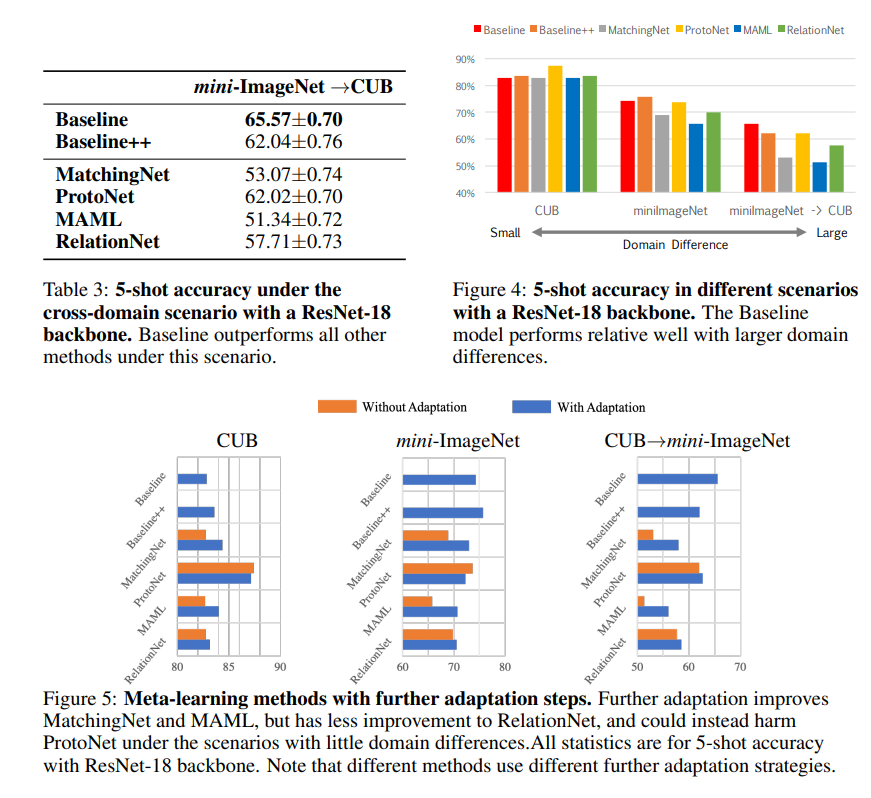
실제로 위 그림들의 실험 결과가 이제 도메인 차이를 정량적으로 확인할 수 있는 실험 결과들입니다. 도메인이 바뀜에 따른 성능에서 기존 방법론들 보다 베이스라인으로 제시한 방법론들의 성능이 높은 것을 확인할 수 있으며, Meta-learning의 방법론들이 성능이 좋지 않은 이유는 Support Set으로 학습하는 도메인과 다르기 때문이라고 보고 있습니다.
Conclusion
처음 보는 분석과 모델들이 많이 등장하기는 하지만, 중점적인 내용이 fair-comparison 관련된 비교 실험이면서 서베이 논문 같은 느낌이라 few-shot classification이라는 task에 대해서 알아보기는 쉬운 내용인 것 같습니다. 다만 제가 원하던 내용은 아니라… 다음에는 zero-shot 관련 논문을 좀 읽어보려고 합니다.
리뷰 잘 읽었습니다.
사실 리뷰만 읽었을 때는 해당 논문에서 풀고자 하는 문제가 정확히 무엇이고, 그래서 이를 어떻게 해결했는지 전혀 감이 잡히지를 않네요.
결국 해당 논문에서는 기존의 연구들이 모두 다른 실험 세팅을 진행한 점을 지적하면서 동일한 세팅에서 공평한 평가를 진행해야 한다가 큰 문제 정의인가요? 그럼 동일한 세팅으로 학습을 진행해서 결과를 리포팅한 것이 과연 광진님께서는 이 논문이 ICLR에 붙을 정도로의 큰 기여를 했다고 생각을 하시나요?
제가 생각했을 땐 기존의 연구들이 주장했던 내용은 사실 실험 세팅들이 각기 달라서 발생한 잘못된 주장들이었으며 공정한 세팅으로 다시 평가해보니 기존과 달리 새로운 경향성 및 사실이 입증되어 올바른 연구 방향성을 제시하지 않은 이상 저는 해당 논문의 기여에 대해서 잘 모르겠습니다.
또한 기존의 실험 세팅이 달랐다면 무엇이 달랐으며 본인들이 어떤 식으로 통일했는지가 있을 것 같은데 리뷰에서는 관련 내용이 없어보이네요. 논문에서 구체적인 언급이 없었나요? 아니면 리뷰에서 생략하신 건가요?
마지막으로 CUB와 달리 Mini ImageNet에서는 네트워크가 무거워져도 각 방법론들의 성능 차이가 한 지점으로 수렴하지 않는다고 하셨는데 왜 그런지에 대한 분석 내용은 없나요? 논문에서 해당 실험을 통해 무엇을 말하고 싶은지 잘 모르겠습니다. Few-show classification과 네트워크의 깊이 사이에 관계를 보이고자 했던 실험 같은데 CUB와 Mini ImageNet의 경향성이 같은게 아닌 상이한 상황에서 저자는 무엇을 주장하고자 한 것인가요?
실험적으로 증명한 사실들이 이 task에 도움이 될 정도라서 붙었다고 생각은 하는데, 제가 이 task 논문이 처음이라 알아보려고 읽은건데 내용이 실험을 알아야 이해를 하는 내용이라 좀 애매하긴 했네요. (제목도 살펴본다길래… 읽은건데…) 실험에서 제시하는 베이스라인도 이 논문에서 제안하는 베이스라인이 아닙니다. 레퍼런스 논문들이 다 있는 상태고요. 이런 관점에서 보면 기여도가 좀 부족한 것 같습니다.
하지만 어떤 관점에서는 실험 세팅이 서로 다른 상황에서 비교하던 상황을 한번에 정리하고, 이 task에서는 intra variation을 중요하다는 실험 증명과 당시에 유행하고 성능도 좋던 meta-learning이 사실은 domain 변화에 잘 대응하지 못한다는 등의 증명이 기여로 인정이 된 것 같긴 한데… 그 정도 까지일지는 저도 의문이네요.
실험 세팅과 관련되서는 제가 패스한 부분으로 남아있는건 옵티마이저와 하이퍼파라미터, 그리고 augmentation 적용 유무 정도만 차이가 납니다. 이정도는 특별할게 없어서 생략했습니다.
마지막으로 데이터셋의 차이에 따른 실험은 저도 모르겠는 부분입니다. 이게 모델의 깊이에 따라 따라 성능 차이가 나는 것을 보여주면서 두 데이터셋을 가지고 비교를 했는데요. 결론은 도메인이 달라서 그렇다는 결론으로 나오는데, 저도 정민님과 같은 생각을 가지고 있습니다. 추론하기로는 fine-grained classification에서 도메인 변화에 따른 성능 차이와 함께 뭔가 보여주려고 했던 것 같은데, 저도 이해가 좀 가지 않는 부분이네요.
좋은 리뷰 감사합니다.
table1에서 저자들의 re-implementation 성능이 기존 논문의 성능과 좀 다른 것이, 세팅을 맞추기 위해 저자들이 하이퍼파라미터나 optimizer를 수정했기 때문이라고 해주셨습니다.
이게 모든 방법론들끼리 같은 하이퍼 파라미터나 optimizer를 쓰도록 통일되었다는 뜻인가요?
Augmentation까지 추가해서 그런 하이퍼 파라미터들과 모델을 모두 동일하게 맞췄다고 합니다.
좋은 리뷰 감사합니다.
Baseline++와 Baseline의 차이점에 대해 cosine similarity를 사용여부로 소개해주셨는데 어떠한 방식으로 사용되는지 추가 설명을 부탁드리겠습니다.
MatchingNet의 경우 Cosine similarity를 이용해서 support set과 query image와의 distance를 학습한다고 하신것 같은데, 이와 같은 방식인가요? 그렇다면 기존 baseline의 경우는 어떠한 방식으로 학습되나요?
Baseline의 Linear Layer를 대체했다고 생각하면 됩니다. MatchingNet 이랑 cosine similarity를 이용해서 학습하는건 똑같은데, support set을 사용하면 아예 다른 방법론이라 같은 방식은 아니고, 우리가 Retrieval task류에서 학습할 때 contrastive learning에서 distance 기반으로 학습을 하듯이 여기서는 분류를 학습하는데 distance 기반으로 학습한다고 생각하면 됩니다.