안녕하세요, 이번 주에 제가 준비한 논문은 2021년도 CVPR에 게재된 ‘Uncertainty Guided Collaborative Training for Weakly Supervised Temporal Action Detection'(이하 UGCT) 입니다.

제가 계속해서 리뷰해왔던 task인 비디오 분야의 Weakly supervised Temporal Action Localization(WTAL)을 수행하는 방법론입니다. 해당 논문에서는 다른 모델의 학습 과정에 붙여 사용할 수 있는 모듈을 제안하였습니다.
TAL은 비디오 내 존재하는 action 구간의 시작, 끝 지점 정보와 그 구간이 어떤 action인지를 아는 채로 학습합니다. 반면 WTAL은 action 구간의 시작과 끝 지점에 대한 정보가 주어지지 않고, 비디오에 특정 클래스의 action이 존재한다는 정보만을 가지고 학습합니다.
바로 논문을 살펴보겠습니다.
1. Introduction
Introduction에서는 다른 논문들과 큰 차이 없이 task에 대한 간단한 소개와, Weakly-supervised 방식의 장점에 대해 이야기합니다. 이후 기존 방법론들의 접근 방식에 대해 설명합니다.
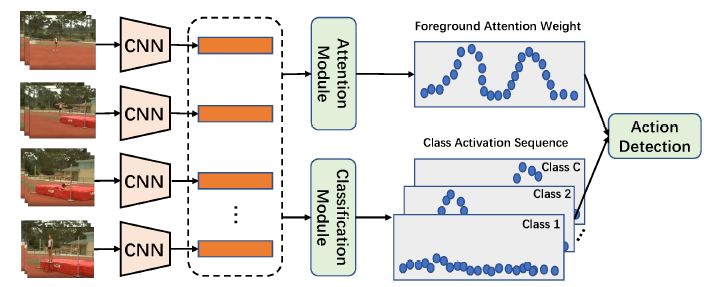
여러 접근법 중 위 그림과 같이 비디오의 각 segment가 특정 클래스에 관계 없이 Action에 해당할 확률인 ‘Foreground Attention Weight’와 각 segment가 특정 클래스에 속할 확률을 매트릭스 형태로 나타내는 ‘Class Activation Sequence'(CAS)를 추출하여 task를 수행하는 방식이 활발히 연구되고 있었고, 가장 좋은 성능을 보였습니다.
WTAL은 비디오 내에서 action 구간에 대한 localization과 그 구간의 action 클래스를 예측하는 classification이 동시에 수행됩니다. 이 때 구간이 어느정도 잘 만들어졌다면 그 구간에 대한 action 클래스를 예측하는 것은 대부분의 방법론이 잘 수행합니다. 문제는 그 구간 자체를 잘 만들어내는 것(localization)입니다.
위와 같은 접근법은 localization을 수행할 때 철저하게 attention weight의 quality에 의존할 수 밖에 없어 보입니다. 추출한 attention weight에 noise가 포함되어 있다면 당연히 제대로 된 action 구간을 예측해낼 수 없을 것입니다.
저자는 action 구간에 대한 temporal annotation이 없는 WTAL에서 localization 성능을 어떻게 올릴지 고민하게 됩니다. 자연스럽게 학습 과정에서 pseudo-temporal-label을 생성해 이를 localization의 GT로 활용하는 방식을 떠올리게 되고, 마찬가지로 pseudo-temporal-label에도 noise가 존재할 수 밖에 없으므로 이것을 어떻게 handling할지 연구합니다.
이를 해결하기 위해 저자는 학습 과정 중 두 가지 전략을 추가합니다. 첫 번째는 신뢰성 있는 pseudo label을 생성하기 위한 ‘Online pseudo label generation module’이고, 두 번째는 생성된 pseudo label의 noise를 최대한 제거하기 위한 ‘Uncertainty prediction module’입니다. 자세한 설명과 특징은 아래에서 말씀드리겠습니다.
논문의 Contribution 2가지를 정리해보겠습니다.
- 앞서 말한 두 가지 전략(module)을 포함하는 UGCT는 inference 시 time과 computational cost에 영향을 주지 않으며 성능을 많이 올릴 수 있습니다.
- 두 벤치마크 데이터셋 THUMOS14와 ActivityNet에서 21년도 당시 SOTA를 달성했습니다.
2. Approaches
2.1 Notations and Preliminaries
먼저 비디오, WTAL task에서 사용되는 용어들을 정리하고 넘어가겠습니다.
untrimmed video V를 받아, 겹치지 않는 16개의 frame을 하나의 segment로 정의합니다. 이 때 각 비디오에서 N개의 segment만 사용한다고 하면 하나의 비디오 V = \{v_{i} \in{} \mathbb{R}^{16 \times{} H \times{} W \times{} 3}\}_{i=1}^{N}로 표현할 수 있습니다. v_{i}가 하나의 segment를 의미합니다.
이후 각 segment v_{i}를 I3D 등의 feature extractor에 태워 d차원의 feature를 얻습니다. 하나의 비디오에 대한 feature \bold{X} = [x_{1}, x_{2}, \cdots{}, x_{N}]이고, 이는 학습에 사용할 video feature representation이라고 보시면 됩니다. d차원의 RGB frame feature와 d차원의 Optical flow feature를 모두 학습에 사용합니다.
각 비디오마다 존재하는 action 클래스에 대한 annotation은 가지고 학습을 수행합니다. 주어지는 GT label \bold{Y} = [y_{1}, y_{2}, \cdots{}, y_{C}]로 표현되고 만약 i번째 action이 비디오에 존재한다면 y_{i} = 1일 것이고, 존재하지 않으면 0일 것입니다.
이후 UGCT를 붙여 사용할 베이스 방법론들(다른 논문)에 대한 설명이 자세히 나오는데 이는 생략하도록 하겠습니다.
2.2 Uncertainty Guided Collaborative Training
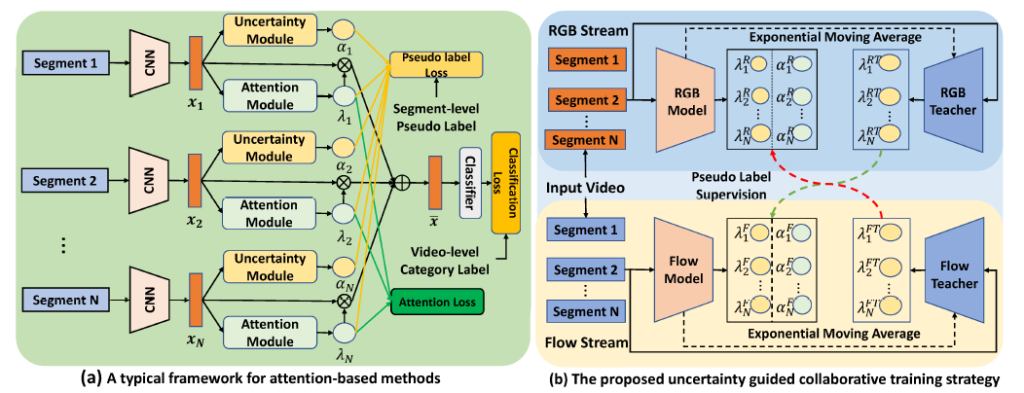
본격적인 방법론 설명입니다.
그림에서 (a)는 UGCT를 붙일 베이스 방법론들의 구조를 나타내는 것이고, (b)가 UGCT를 (a)에 붙인 그림입니다. (b)에 있는 RGB Model, RGB Teacher, Flow Model, Flow Teacher이 각각 (a)에 해당합니다.
정리하자면 여기서부턴 (b)에 대한 설명입니다.
UGCT의 핵심인 두 가지 모듈을 하나씩 나누어 설명하겠습니다.
2.2.1 Online pseudo label generation module
모듈 이름대로 pseudo label을 생성합니다. 학습 중 pseudo label을 계속 생성함으로써 online이라는 특성을 갖습니다.
앞서 뽑은 RGB feature와 Flow feature는 각각 RGB Teacher, Flow Teacher의 입력으로 들어갑니다. 그러면 각 Teacher들은 segment 별 attention weight를 뽑아냅니다.
- \mathit{\Lambda}^{RT} = [\lambda{}_{1}^{RT}, \lambda{}_{2}^{RT}, \cdots{}, \lambda{}_{N}^{RT}] \in{} \mathbb{R}^{N}
- \mathit{\Lambda}^{FT} = [\lambda{}_{1}^{FT}, \lambda{}_{2}^{FT}, \cdots{}, \lambda{}_{N}^{FT}] \in{} \mathbb{R}^{N}
\mathit{\Lambda}^{RT}는 RGB Teacher로부터 얻은 attention weight, \mathit{\Lambda}^{FT}는 Flow Teacher로부터 얻은 attention weight를 의미합니다.
이렇게 얻은 attention weight로부터 pseudo label을 만들어냅니다. 단순히 attention weight에 thresholding을 적용해 0 또는 1로 바꿔주는 것입니다.
attention weight의 평균을 threshold로 삼아 이진화 해주는 함수 \mathcal{G}를 적용해 0 또는 1로 이루어진 pseudo label을 각 모달 별로 얻을 수 있습니다.
- \mathcal{G}(\mathit{\Lambda})_{i} = 1, \; if \lambda{}_{i} > mean(\mathit{\Lambda})
- \mathcal{G}(\mathit{\Lambda})_{i} = 0, \; otherwise.
이게 online pseudo label 생성 과정 전부입니다. 이렇게 함으로써 얻을 수 있는 장점 또는 특징 3가지가 있습니다.
첫 번째는 teacher model로부터 pseudo label을 만들어낸다는 점입니다.
학습 과정에서 student model은 아직 수렴하지 못해 양질의 pseudo label을 만들어낼 수 없는 상황인데, teacher model은 historical information을 함께 고려함으로써 더욱 신뢰성 있는 pseudo label을 만들어냅니다. (teacher model은 moving average 방식으로 파라미터 학습)
두 번째는 Collaborative training입니다. RT에서 만들어 낸 pseudo label은 Flow 모델이 보고, FT에서 만들어 낸 pseudo label은 RGB 모델이 보고 학습합니다.
세 번째는 0 또는 1의 값으로 hard pseudo label이 생성되는데, 이를 보고 학습하면 더욱 sparse하게 0에 가까운, 또는 1에 가까운 확실한 방향으로 갈 수 있게 됩니다.
2.2.2 Uncertainty prediction module
위에서까지의 과정을 모두 거치면 pseudo label을 얻을 수 있었습니다. 그런데 아직 pseudo label에 noise가 존재하는 상태이기 때문에 noise를 제거해주는 과정이 필요해 보입니다.
Uncertainty prediction module이 noise 제거의 역할을 합니다.
- uncertainty = [\alpha{}_{1}^{*}, \alpha{}_{2}^{*}, \cdots{}, \alpha{}_{N}^{*}]
여기서 *은 RGB 또는 Flow를 의미합니다. \alpha{}를 이용해 아래 loss를 설계합니다.
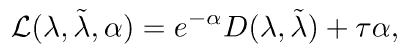
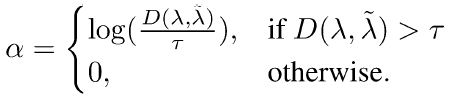
식에서 D는 거리 함수입니다. pseudo label과 attention weight 간 거리가 \tau{}보다 작으면 0, 크면 위 로그 식으로 uncertainty가 정의될 수 있습니다. 다시 말해 attention weight가 자신의 pseudo label에 가까울수록 uncertainty가 작다는 것입니다.
하지만 analytic solution을 적용하면 input feature를 보는게 아니라 그로부터 얻은 attention weight와 pseudo label 만을 고려하여 uncertainty를 측정합니다. 따라서 analytic solution 대신 input feature도 함께 고려해 uncertainty를 예측하는 Uncertainty prediction module을 사용합니다. Uncertainty prediction module을 사용하면, module이 noise한 segment feature의 공통적 특성을 파악할 수 있다는 장점이 생깁니다.
Uncertainty prediction module의 구조는 논문에 정확히 명시되어 있진 않지만 Bayesian-CNN을 이용하는 것으로 보입니다.
이 정도 설명이 논문의 내용 전부인데, Bayesian-CNN의 특성을 아직 완전히 이해하지 못해
https://github.com/kumar-shridhar/PyTorch-BayesianCNN 또는 http://dmqm.korea.ac.kr/activity/seminar/252
페이지를 참고해주시면 감사하겠습니다. 추후에 정리가 되면 내용을 수정하도록 하겠습니다.
결국 prediction module을 사용하는 최종 loss는 아래와 같습니다.
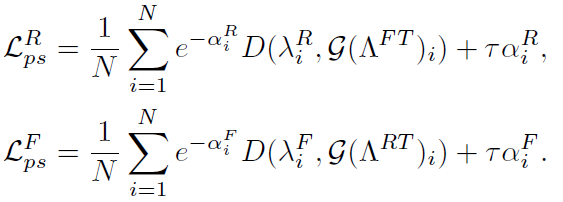
RGB 모델의 loss를 기준으로 설명드리면, FT로부터 나온 pseudo label과 RGB 모델의 attention weight의 거리가 작아지도록, uncertainty가 작아지도록 학습됩니다. uncertainty를 줄임으로써 noise에 학습에 따라 더욱 강인한 pseudo label이 생성되는 것입니다.
최종 loss \mathcal{L}은 기존 방법론에 있던 loss \mathcal{L}_base와 \mathcal{L}_ps의 가중합으로 계산됩니다. 이 때 w(t)를 학습 iteration에 따라 달리하는 gradual learning이 적용되었습니다.
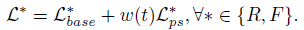
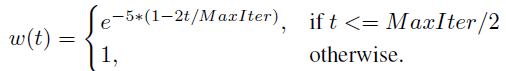
추가적으로 모델 파라미터 학습 방식에 대한 설명입니다.
RGB, Flow model은 기존 back propagation의 방식대로 파라미터가 갱신되는데, RT, FT model은 아래 식과 같이 exponential moving average 방식으로 파라미터를 갱신합니다.
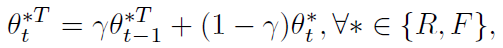
\gamma{}는 0.999로 설정합니다. 이러한 방식으로 파라미터를 갱신함으로써 Teacher model이 historical information을 고려하며 학습할 수 있게 되는 것입니다.
3. Experiments
Benchmark
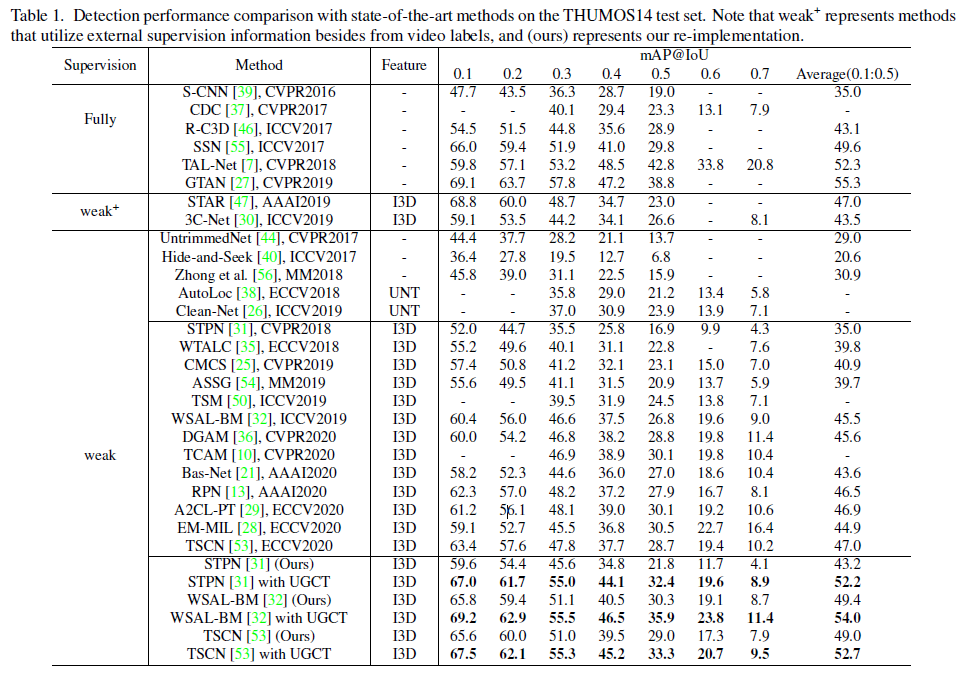
THUMOS dataset에서의 벤치마크 성능입니다. STPN, WSAL-BM, TSCN 방법론에 UGCT를 붙인 성능을 보시면 되는데, 모든 tIoU 기준으로 성능이 많이 오른 것을 볼 수 있습니다.
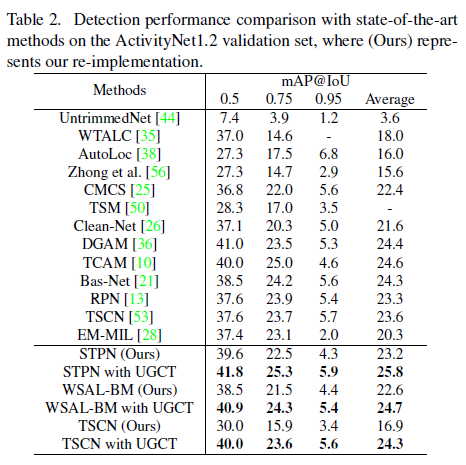
다음은 ActivityNet dataset 벤치마크 성능입니다. 마찬가지로 UGCT 학습 방식을 사용해 성능이 많이 올랐습니다. 주목할 점은 THUMOS dataset에선 WSAL-BM이 가장 높은 성능을 보였지만 ActivityNet에서는 STPN이 가장 높은 성능을 보인다는 것입니다.
저자는 이 이유에 대해 두 데이터셋의 특성 차이를 이야기 합니다. THUMOS는 상대적으로 비디오 길이가 짧으며 한 비디오 내에 여러 개의 action instance가 포함되어 있고, ActivityNet은 길이가 길고 한 비디오에 보통 한 개의 action instance가 존재합니다. STPN 모델은 background를 action이라고 잘못 예측하는 경우가 많은데, 데이터셋의 특성 상 긴 action이 존재하는 ActivityNet에서 그 특징이 WSAL-BM보다 높은 성능을 내게 한 것이 아닌가 분석하고 있습니다.
Ablation Studies
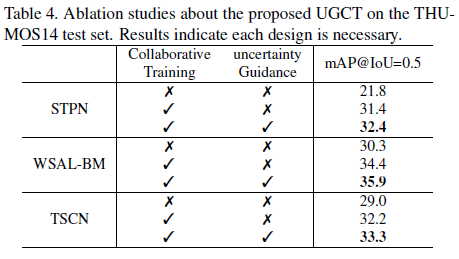
먼저 각 모듈의 사용 여부에 따른 성능 차이입니다. 확실히 두 모듈 다 성능 향상에 기여했음을 알 수 있고, 특히 서로 다른 모듈로부터 pseudo label을 제공 받아 학습하는 방식을 통해 성능이 두드러지게 향상된 것을 볼 수 있습니다. 또한 세 방법론 모두에서 성능이 올랐기 때문에 UGCT가 일반적으로 적용할 수 있는 모듈임도 알 수 있습니다.
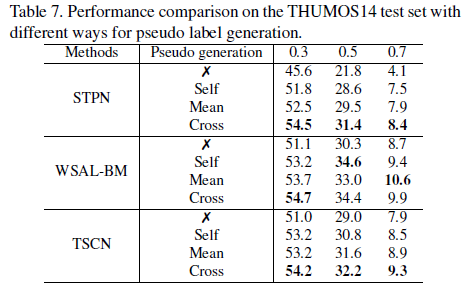
다음은 pseudo label을 만드는 방식 차이에 따른 성능입니다. X는 pseudo label을 사용하지 않은 경우, self는 RGB와 Flow가 각각 자신 모달의 teacher로부터 나온 pseudo label로 학습한 경우, mean은 각 모달에서 얻은 2개의 pseudo label을 평균 내어 학습에 사용한 경우, cross는 논문에서 소개된 방식입니다.
표를 통해 확실히 자기 자신 모달의 pseudo label 만을 사용하는 것보단 mean이든 cross든 다른 모달의 pseudo label을 사용하는 것이 성능이 더 높음을 알 수 있습니다.
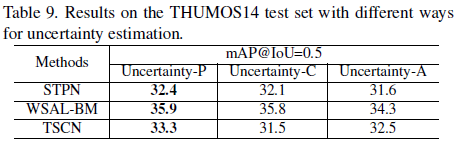
마지막으로 살펴볼 만한 실험은 uncertainty를 추정하는 방식에 따른 성능 차이입니다. P는 prediction module을 사용하는 논문에 소개된 방식이고, C는 consistency로 하나의 segment에 대해 서로 다른 두 random noise를 각각 적용한 후 Teacher model에 태워 두 개의 pseudo label을 얻습니다. 그리고 두 pseudo label 간의 차이를 uncertainty로 지정합니다.
하지만 이러한 방식은 모델이 하나의 segment에 대해 두 개의 output을 내야 하므로 computational cost가 크다는 단점이 있습니다. A는 논문에서 설명했던 analytic solution 방식대로 uncertainty를 구해 사용한 경우입니다.
C의 방식도 성능이 A 방식 보다는 높지만, P의 방식이 cost가 낮으면서 더 높은 성능을 보이는 것을 알 수 있습니다.
Conclusion
논문에 적용된 두 모듈 중 Uncertainty prediction module이 핵심적인 역할을 하는 것으로 보이는데, 수학적 방법론의 적용을 코드 없이 이해하려니 힘드네요.
목적이나 역할은 명확하지만, 정확히 어떤 과정으로 무엇을 보고 uncertainty를 예측해내는 것인지 관련 내용을 좀 더 찾아본 후 구체적으로 설명드릴 수 있도록 하겠습니다.
이상 리뷰 마치겠습니다.
RGB-FLOW를 co-training하는건 이미 앞선 논문들이 있었으니 uncertainty를 이용하는게 논문의 핵심같은데, 결국은 앞선 모델에서 attention weight로부터 pseudo label를 생성해내는 것은 이해했습니다. 그래서 이 모듈이 학습하는게 attention weight와 pseudo label이 같아지도록 학습하는 것에서 약간 모호한 느낌이 드는데요. 이 문제를 해결하는게 analytic solution 같은데, 이건 정확하게 어떤 해결책이라서 두 값만 고려해서 uncertainty가 측정되게 하는거죠?
analytic solution은 단순히 segment에 상응하는 attention weight와 pseudo label의 거리를 줄이는 방향으로 학습하게 됩니다. 하지만 이러한 analytic solution 방식으로 학습하면 segment의 feature나 분포를 명시적으로 보지 못하고 그로부터 얻은 attention weight만 보고 학습하게 됩니다.
그래서 analytic solution을 사용하는 대신 Bayesian CNN(uncertainty prediction module)을 통해 uncertainty의 예측값을 얻고, 이를 학습에 활용합니다. 결과적으로 analytic solution은 attention weight와 pseudo label의 거리를 기반으로 uncertainty를 측정하고, uncertainty prediction module은 Bayesian CNN을 통해 uncertainty를 측정한다는 것이 차이점입니다.
Bayesian CNN에 대해 간단히 추가 설명을 드리면, 기존 CNN에서는 학습이 끝나면 모델이 고정된 weight를 갖지만, Bayesian에서는 weight가 불확실성을 가지는 확률 분포로 이루어 진다고 합니다.
그래서 Bayesian에서는 output으로 기존 NN처럼 어떠한 하나의 예측값을 만들어내는 것이 아니라 uncertainty를 갖는 확률 분포를 만들어냅니다. 최종 출력값과 그에 대한 uncertainty를 같이 내뱉는 것으로 생각하시면 좋을 것 같습니다.
좋은 리뷰 감사합니다.
2.2.2 uncertainty prediction module에서 pseudo label에 noise가 있으니 제거해주는 과정이 필요하다고 하셨습니다. 제가 이해한 바로는 Online pseudo label generation module을 통해 생성된 pseudo label은 0 또는 1로 구성되어 있다고 이해하였는데, 여기서 noise라는 것이 label이 원래는 0이어야 하는데 1인 거 혹은 1이어야 하는데 0인 거를 말하는 걸까요? noise가 무엇을 의미하는 걸까요?
감사합니다.
noise는 말씀해주신 내용이 맞습니다.
Action의 시간 구간을 예측해야 하는데 이에 대한 annotation이 없기 때문에, 학습 중 시간 구간의 annotation으로 활용할 pseudo label을 모델이 만들어 내어 학습합니다. 이 때의 pseudo label도 결국은 학습 중인 모델이 만들어 냈으므로 완전하다고 볼 수 없습니다(noise 존재할 것).
이러한 noise를 최대한 제거해주기 위해 Bayesian CNN을 적용하여 얻은 uncertainty를 활용하는 것입니다.