안녕하세요. 이번 X-Review는 저번에 작성한 음성 인식 도메인 정리에 이어서 음성 감정 인식과 관련한 논문입니다.
<목차>
1. Introduction
2. Contributions
3. Related Work
4. Methodology
4.1 Multi-Scale Feature Representation
4.1.1 Multi-Scale Block
4.1.2 Multi-Scale Net
4.2 Global-Aware Fusion
4.3 Data Aument
5. Experiments
5.1 Experimental Settings
5.2 Results and Discussion
6. conclusion
1. Introduction
논문의 introduction에서는 논문의 저자가 제안하는 방법론이 왜 나오게 되었는지에 대한 내용이 들어있습니다.
SER(Speech Emotion Recognition)이 큰 발전을 이루게 된 시기가 있는데, 컴퓨터 비전이 부흥하면서 CNN을 이용하여 spectral feature를 이미지로 보는 기법이 등장하면서 큰 발전을 이뤘다고 합니다. 여기서 CNN은 fixed-scale feauter representation에서 local attention map을 학습합니다. 여기서 저자는 CNN이 feature representation과 attention map으로 이뤄져있다고 말합니다. 일반적으로 feature representation은 fixed-scale feature를 학습하고, attention map은 local fixed-scale feature 속에서 emotional information을 attend 합니다. 그런데, emotion은 시간에 따라 변화를 갖는 시간 축 기반의 spectral feature에 대해서 different scale을 가지는 조음 변화(입의 모양, 혀의 모양 등을 통해서 발생하는 발음의 변화)를 특징으로 가지고 있기 때문에 local fixed-scale feature를 기반으로 작동하는 CNN에 한계가 있다고 합니다. 그렇기 때문에 논문은 이를 해결할 수 있는 GLAM (GLoval-Aware Multi-scale) neural network를 제안합니다.
여기서 attention map이 무엇인지 궁금하실 것 같은데요. 논문의 저자가 attention map의 정의에 대해서는 다루지 않아서 Reference를 참고하였습니다. [8] Improve Accuracy of Speech Emotion Recognition with Attention Head Fusion을 참고하시면 3. MODEL ARCHITECTURE AND HEAD FUSION의 C. Self-Attention Layer and Head Fusion 부분이 있는데, 아래 그림을 통해 attention map을 어떻게 정의하였는지 확인할 수 있습니다.

CNN을 통해 생성한 feature map을 이용하여 Query, Key, Value를 사용하여 구한 값을 가지고 Softmax에 넣어 확률값을 구합니다. Softmax에 넣어서 얻은 확률을 attention score라고 말합니다. 이 attention score 행렬에 Value를 곱해서 얻은 행렬이 바로 attention map이라고 말할 수 있습니다. Query, Key, Value는 feature map에 trainable parameters인 W_k, W_q, W_v를 곱해 구할 수 있습니다.
이것을 생각하면서 위에서 저자가 말한 CNN이 feature representation과 attention map으로 구성되있다는 말을 다시 생각해보면, 저자가 말한 CNN은 self-attention 기법이 적용된 CNN이라 말할 수 있고, feature representation은 feature map이라 생각할 수 있고, attention map은 feature map을 attention 연산하여 얻은 행렬이라 말할 수 있습니다.
다시 Introduction으로 돌아와서, 저자는 위의 한계점을 극복하고자 multi-scale convolutional block을 사용하여 다양한 scale의 feature를 추출하고, global-aware fusion module을 사용하여 다양한 스케일에서 감정 패턴을 반영하는 중요한 information을 선택하는 방법을 제안합니다.
2. Contributions
contribution을 정리하면 아래와 같습니다.
- multi-scale feature representation 적용.
- 다양한 스케일에 대해서 emotional information을 잡기위한 global-aware fusion module 사용.
3. Related Work
Related work에서는 SER이 시간순서대로 어떻게 발전하였는지에 대해서 나와있습니다.
우선 처음 딥러닝을 사용한 방법론에서는 feature repersentation을 학습하여 feature segment의 emotion label을 예측하는 식으로 사용되었다고 합니다. 이후에 등장한 것이 feature segment를 이미지로 보는 방법입니다. introduction에서도 말씀드렸지만 CNN을 통해 feature segment를 이미지로 봄으로써 SER은 큰 발전을 이뤘습니다. 이 이후에 나온 방법론들은 ELM (extreme learning machin), capsule network, LSTM가 있는데, 모든 feature segment로부터 모든 feature representation을 fuse하기 위해서 나온 방법론 입니다. 여기서 중요한 점은 이러한 방법론들이 나왔음에도 불구하고 CNN은 여전히 fixed-scale local feature에 포커싱하고 있고, varied scale의 effect를 잘 활용하지 못하고 있다는 것입니다.
최근에는 attention을 기반으로 한 model을 SER에 이용하면서 많은 발전을 이뤘는데, 예를 들면, multi-head attention map 같은 경우, surrounding information으로부터 중요한 정보를 선택하여 convolution 연산을 진행합니다. 또 다른 예로 area attention 같은 경우, 다양한 범위의 convolution으로부터 importance를 계산합니다. 그런데, 현존하는 CNN 기반의 attention-based model은 CNN이 fixed-scale local feature에 포커싱하고 있기 때문에 global information을 인식하는 경향이 부족하다는 한계점이 있습니다.이를 극복하고자 논문의 저자는 global-aware fusion module을 제안합니다.
4. Methodology
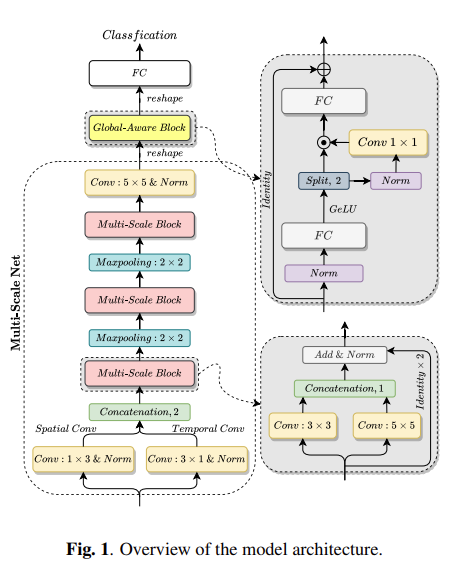
4.1 Multi-Scale Feature Representation
4.1.1 Multi-Scale Block
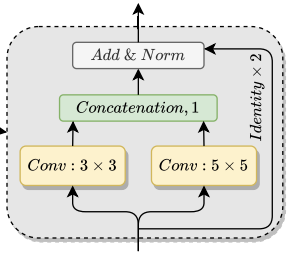
논문의 저자는 multi-scale Feature representation을 하기 위해서 Multi-Scale Block을 제안합니다. Multi-Scale Block은 위의 그림 구조를 가지는데, same level에서 multi-scale convolution layer를 병렬시키기 위해서 사용됩니다. Fig 1을 보시면 Multi-Scale Block을 여러번 사용하는 것을 확인할 수 있는데, 각각의 Multi-Scale Block은 다른 사이즈의 receptive field를 받습니다. 이를 통해서 multi-scale feature representation을 할 수 있습니다. 이때 channel size는 바뀌지 않습니다.
4.1.2 Multi-Scale Net
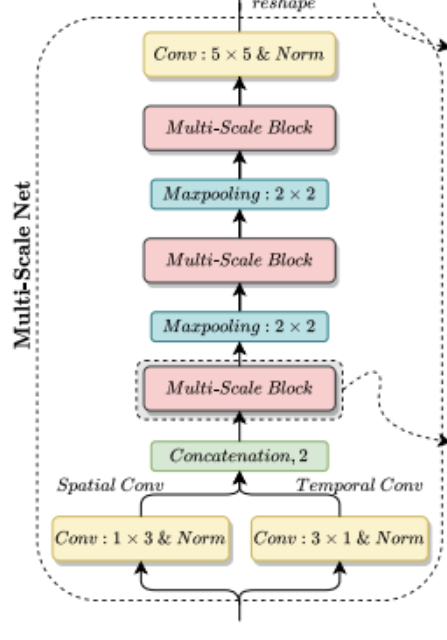
Multi-Scale Net 부분을 보면 input이 Conv 1X3, Conv 3X1에 들어가는데, 이를 통해 spatial feature와 temporal feature를 얻을 수 있습니다. 이때, out-channels는 모두 16 입니다. 처음 concatenation은 spatial dimension을 따라 concatenation 되고, 처음 concatenation을 제외한 나머지는 channel dimension을 따라 concatenation 합니다. 마지막 convolution layer는 5*5의 kernel size를 가지고, 모든 conv layer는 똑같이 padding 합니다.
4.2 Global-Aware Fusion
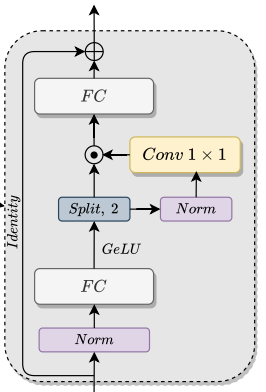
위의 그림을 통해 Global-Aware Fusion module 구조를 확인할 수 있는데, cross-scale feature communication을 강화하기 위해서 사용됩니다. 여기서 input으로 들어온 feature map이 C*d_f라고 한다면, C는 channel size를 말하고, d_f는 flattened feature map의 size를 말합니다. 이때, 첫번째 FC layer의 output dimension은 4d_f, 마지막 FC layer의 output dimension은 d_f를 가리킵니다.
GeLU로 projection 한 뒤에는 feature demension을 따라 split하여 나누는데, 이때 channel size는 달라지지 않습니다. split 한뒤에는 곱셉 연산을 하는데, 곱센 연산을 통해 channel dimension에 대해서 feature mixing을 강화한다고 합니다.
이렇게 하여 최종적으로 나온 output은 classification 하기 위해서 reshape하여 FC layer로 들어갑니다.
이렇게 Multi-scale Feature Representation과 Global-Aware Fusion이 어떻게 동작하는지에 대해서 작성하였습니다. 저는 처음에 논문에서 Multi-Scale Representation 부분을 봤을 때, 여러 multi-scale block으로부터 나온 다양한 size의 feature map이 모두 global-aware fusion으로 들어가서 multi-scale representation을 구할 수 있다고 말하는 줄 알았는데, 정확하게 확인하기 위해서 코드로 확인해 봤을 때, 최종 multi-scale block에서 나온 feature map만 global-aware fusion에 들어가는 것을 확인하였습니다.
코드를 통해 확인한 것을 가지고 여기서 말하는 multi-scale representation의 정확한 의미에 대해서 생각해 봤을 때, 위에서 제가 feature representation이 feature map이라고 말한 것처럼, 여러 multi-scale block이 매번 다른 사이즈의 receptive field를 받으니까 output으로 매번 다른 사이즈의 feature map을 얻고, 이 feature map을 input으로 가지는 conv에서 나온 feature map은 multi-scale을 가지는 feature map이라고 생각할 수 있습니다. 최종적으로, multi-scale feature map을 가지기 때문에 multi-scale feature representation을 가질 수 있다고 말할 수 있습니다.
Global-Aware Fusion도 module의 어느 지점에서 global information을 attend 하는 것인지 생각해봤습니다. module을 보시면 multi-scale representation이 FC를 통과한 뒤에 GeLU로 projection 합니다. 그 이후에 split 하여 나누게 되는데, GeLU로 projection 한 뒤 split 해서 나온 결과물을 A라고 한다면 A와 A를 Conv 1X1을 통과하여 나온 feature representation을 곱셈 연산하여서, feature mixing 함으로써 global information attend 하는 것은 아닌가 생각합니다.
4.3 Data Augment
여기서는 mixup이란 방법을 이용하여 data augment를 합니다. training example (x_i, y_i), (x_j, y_j) 를 아래 식을 통해 새로운 example로 만듭니다.
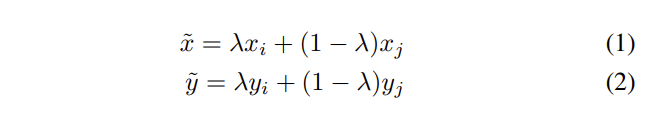
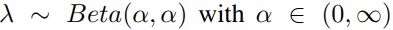
(x_i, y_i), (x_j, y_j) 는 training data에서 랜덤으로 선택하여 사용합니다. \lambda는 Beta 분포를 따르는 수로, 양의 실수 값인 \alpha를 베타 함수에 넣어 나온 값을 \lambda로 사용합니다.
5. Experiments
이제부터는 위의 방법론을 적용하여 실험한 결과에 관한 내용 입니다.
5.1 Experimental Settings
논문의 저자는 IEMOCAP이라는 데이터셋을 가지고 실험을 진행했습니다. 이 데이터셋의 경우, 10명의 배우가 감정적인 speech를 12시간 정도 연기하여 확보한 오디오 데이터셋입니다. angry, happy, sad, neutral 이렇게 4개 카테고리가 있습니다. 이 논문에서는 IEMOCAP 데이터셋을 3 타입으로 나눠 사용하였습니다. 배우가 즉흥으로 연기했으면 Improvisation, 스크팁트를 보고 연기했으면 Script, 즉흥 + 스크립트 합쳐서 Full, 이렇게 3가지로 나눠 데이터셋을 사용하였습니다.
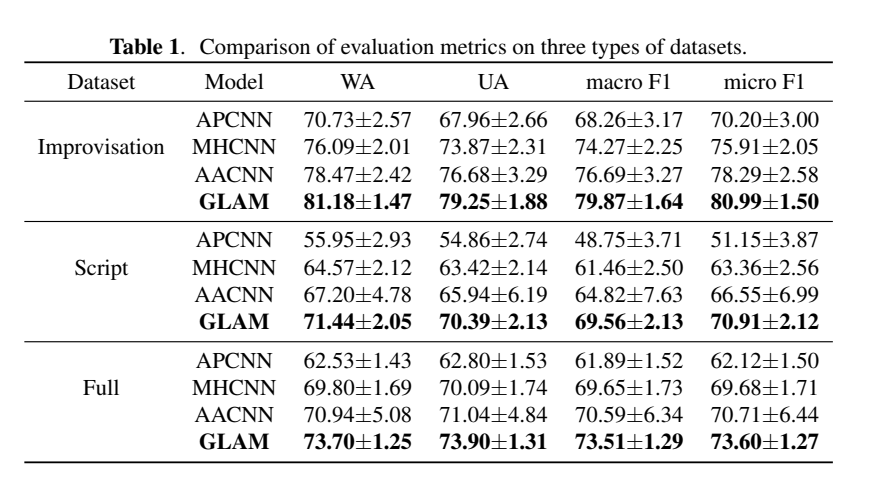
Table 1을 보시면 GLAM과 비교한 모델들의 이름을 확인할 수 있는데, APCNN (Area Attention CNN), MHCNN (Multi-Head Attention), APCNN (Attention Pooling CNN)으로 모두 CNN에 attention mechanism이 적용되었습니다. 이 논문은 여태까지 SER에서 쓰인 CNN 기법의 한계점을 극복하기 위한 방법론 제시하기 때문에 비교 모델들도 모두 CNN 기반으로 사용한 방법론 인데, CNN을 사용하지 않은 모델에서의 성능도 같이 비교하면 좋지 않았을까 생각합니다.
평가 메트릭으로는 WA (Weighted Accuracy), UA (Unweighted Accuracy), Micro F1 score, Macro F1 score를 사용하였습니다. 여기서 저는 Micro F1 Score와 Macro F1 Score의 차이점이 무엇인지 궁금하여서 더 찾아봤습니다.
F1 score는 2\cfrac{Precision * Recall}{Precision + Recall}로 표현할 수 있습니다. 이 식을 더 풀어서 작성하면 F1 Score = \cfrac{TP}{TP + \frac{1}{2}(FP + FN)}으로 표현할 수 있습니다.
Macro F1 Score는 클래스 별로 계산된 F1 score의 가중치 없는 평균이라 생각하시면 됩니다. 아래 식을 통해 확인할 수 있습니다.
Macro F1 Score = \cfrac{sum( F1 Scores )}{number of classes}
Micro F1 Score는 F1 Score 공식을 그대로 따라가지만, 각 클래스에서 개별적으로 계산되는 대신 True Positive(TP), False Positive(FP), False Negatives(FN)의 총 수를 사용하여 계산합니다. 아래를 보면 앞에서 설명한 F1 Score 공식을 따라가는 것을 확인할 수 있습니다.
Micro F1 Score = \cfrac{TP}{TP + \frac{1}{2}(FP+FN)}
Macro와 Micro는 중요한 차이점이 있는데, Micro score는 Macro 보다 imbalanced dataset에서 나쁜 성능을 보입니다. micro는 각 관측치에 대해서 동일한 importance를 부여하지만 macro는 각 clas에 대해서 동일한 importance를 부여하기 때문입니다. 그래서 불균형 데이터셋을 사용하는 경우, macro F1 score를, 반대라면 micro F1 socre를 사용합니다.
이렇게 평가 메트릭에 대해서 설명을 마무리하고, 더 디테일하게 실험 셋팅을 말씀드리자면, feature input으로는 mel-frequency cepstral coefficients (MFCCs)를 사용하였고 (추가 설명은 ‘음성 도메인 정리’ 참고), segment를 1.6초 정도 overlap 하여 2초 분량의 segment로 나누었습니다.
5.2 Results and Discussion
Table 1을 보시면 GLAM의 성능이 가장 좋은 것을 확인할 수 있는데, 표준편차 또한 크지 않다는 것을 확인할 수 있습니다. 표준편차가 작다는 것은 roubust하고 stable한 performance를 할 수 있다는 것을 나타내기 때문에 모든 것을 고려하여 비교했을 때 GLAM의 성능이 가장 좋은 것을 확인할 수 있습니다.
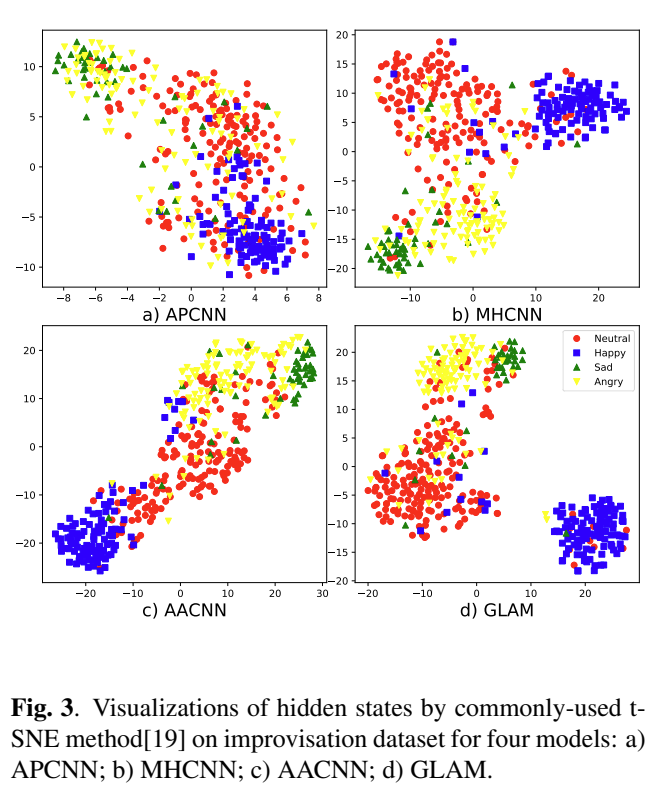
Fig 3은 t-SNE (t-distributed stochastic neighbor embeddings)을 이용하여 hight-level feature를 2D로 projection한 것을 시각화 한 것입니다. feature는 마지막에서 두번째 layer인 global-aware fusion module의 마지막 FC layer에서 뽑아 사용하였습니다.
Fig 3을 보시면, 각 모델이 얼마나 감정을 잘 분류했는지를 볼 수 있는데, a) APCNN 같은 경우, 감정들이 굉장히 겹쳐있는 것을 확인할 수 있습니다. b) MHCNN 같은 경우, happy가 확실하게 분리되어 있지 않고, c) AACNN 같은 경우, emotion들이 연속적으로 나열되어있는 것을 확인할 수 있습니다.
d) GLAM 같은 경우, 비교적 모든 emotion들이 잘 분류되어 있는데, 논문의 저자는 AACNN과 비교하여 GLAM의 sad와 angry의 간격이 더 낫다는 것을 강조하였습니다.
Fig 3에서 a, b, c, d 모든 모델에서 angry가 고르게 분포되어 있는 것을 확인할 수 있는데, 논문의 저자가 이를 언급하지 않아 의의였고, angry 분류가 왜 잘 안되었는지에 대해서 언급을 해줬다면 좋지 않았을까하는 아쉬움이 있습니다.
6.Conclusion
사실 논문을 읽으면서 가장 아쉽다고 생각한 부분은 위에서도 언급했지만, 저자가 제안한 모델과 성능을 비교할 때 CNN에 attention을 적용한 모델만 가지고 비교했다는 것입니다. 자신이 개선한 모델의 성능을 강조하기 위해서 그런 것 같은데 SER을 하기 위해서 나온 여러 방법론과 비교하여 성능이 오른 것을 보여줘야 저자가 왜 LSTM이나 Transformer 대신 굳이 CNN을 사용했고, global information을 추가했는지가 더 와닿았을 것 같은데 그렇지 않아 아쉬웠습니다.
부족한 리뷰 읽어주셔서 감사합니다. 이상 마치겠습니다.
안녕하세요 주연님 좋은 리뷰 감사합니다!!
1. Global-Aware Fusion에서 split 한뒤의 결과물을 a,b라 한다면 b에 norm , conv 1*1 연산을 해서 a와 곱셈 연산을 진행해서 feature mixing을 강화한다고 하셨는데 수식으로만 봤을 때 어떻게 이 연산이 feature mixing을 강화하는지 잘 이해가 되질 않습니다…혹시 추가적인 설명이 있을까요??
2. Multi-Scale Net에 input으로 들어가는 것은 하나의 feature map 뿐인가요? 아니면 다른 크기의 feature map도 들어가는 건가요?
3. 최근 SER에서는 CNN기법 이나 ELM , capsule network, LSTM 기법 등 어떤 기법이 가장 많이 사용되나요??
감사합니다!!
안녕하세요! 댓글 감사합니다.
1. Global-Aware Fusion에서 split 한뒤의 결과물을 a,b라 한다면 b에 norm , conv 1*1 연산을 해서 a와 곱셈 연산을 진행해서 feature mixing을 강화한다고 하셨는데 수식으로만 봤을 때 어떻게 이 연산이 feature mixing을 강화하는지 잘 이해가 되질 않습니다…혹시 추가적인 설명이 있을까요??
-> 여기서 주목할 점은 a와의 곱셈 연산인데요. 이 연산 과정을 통해서 feature를 섞는다, 즉 mixing을 진행한다고 생각하시면 될 것 같습니다. a, b라는 feature가 동일하게 있는데 이 중 b를 변형을 수행합니다. 그런 다음 a와 변형된 b를 곱하면 feature가 섞이게 되는 것이죠. 그래서 feature mixing을 강화한다고 표현한 것입니다.
2. Multi-Scale Net에 input으로 들어가는 것은 하나의 feature map 뿐인가요? 아니면 다른 크기의 feature map도 들어가는 건가요?
-> 하나의 feature map 입니다!
3. 최근 SER에서는 CNN기법 이나 ELM , capsule network, LSTM 기법 등 어떤 기법이 가장 많이 사용되나요??
-> 제가 생각하기에는 가장 많이 사용되는 방법론은 transformer를 응용한 방법론이 아닐까 생각합니다! 사실 정확히 말하자면 거의 대부분의 분야에서 transformer를 많이 사용하기 때문에 SER 분야에서도 transformer를 많이 사용하는 것이 아닌가 생각합니다. (성능도 보장되기 때문도 있겠지요)
감사합니다