
안녕하세요. 오늘은 비디오 근본…? 아무튼 학습에 대한 내용을 가지고 왔습니다. 길고 길었던 논문 작업이 끝이 보이고 ㅎㅎ… 다음 실험을 진행을 해야하는데 학습에 대한 내용을 제가 잘 모르는 것 같은데, 구상중인 실험을 진행하려면 필요할 것 같아서… 겸사겸사 읽어봤습니다.
Introduction
다크데이터 팀의 연구원분들이 이미지 기반에서의 self-supervised 방법론들을 많이 소개해주셔서 다들 익숙하실겁니다. (SimCLR, MoCo 등등) 이미지 기반의 self-supervised에서 놀라운 실험들이 보여주는 것을 기반으로 하여 이 논문에서는 비디오에 적용 가능한 self-supervised 방법론을 제안하는데요.
이 논문에서 제안하는 내용은 “과연 contrastive learning에서 데이터를 충분히 잘 활용하고 있을까?”라는 질문에서 시작합니다. 우리가 보통 Contrastive Learning을 논할때, Hard-negative의 중요성에 대해서는 잘 이해하지만 Hard-positive의 중요성은 놓친다고 합니다. 논문에서는 이를 증명하기 위해 InfoNCE Loss에 oracle 을 참고한 UberNCE를 만들어서 학습 했을 때 꽤 높은 성능이 나오는 것을 통해서 기존의 학습 방법론들은 데이터를 충분히 활용하지 않음을 증명합니다.
이에 CoCLR라는 self-supervised co-training method를 제안합니다. RGB와 optical flow를 활용하는 이 학습 방법론이 UberNCE의 성능과 유사한 점을 통해서 데이터 활용의 중요성을 강조하는 것이죠.
InfoNCE, UberNCE and CoCLR
Learning with InfoNCE and UberNCE
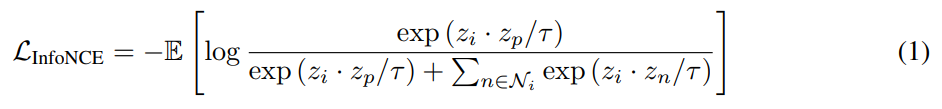
1번 수식은 InfoNCE Loss입니다. 다들 이제는 많이 보셔서 익숙하신 분들이 많으실텐데, 그래도 간단하게 설명을 덧붙이자면… z_i = f(x_i)입니다. 입력값이 되겠죠? 이에 대응되는 1개의 Positive z_p가 있고, N-1개의 negative z_n이 존재합니다. 이 논문에서 주장하는 대로 말해보면, InfoNCE는 Hard-positive와 Hard-negative에 대한 고려를 하지 않는 Loss입니다.
여기서 같은 수식이지만, Positive를 annotation을 참고해서
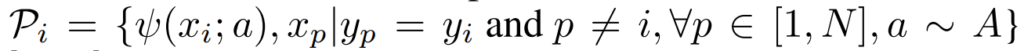
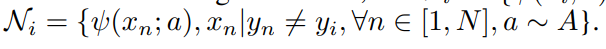
와 같이 샘플링을 하면, UberNCE Loss가 됩니다. UberNCE에서는 positive를 같은 class안에서 선택하고, Negative를 서로 다른 class에서 선택해서 augmentation(수식에서 \psi)을 수행하는 간단한 방법을 따릅니다. 이 방법이 논문에서 주장하는 Hard-positive와 Hard-negative를 고려하는 방법론입니다.
Self-supervised CoCLR
그럼 본 논문에서는 label 정보가 없는 상황에서 어떻게 UberNCE로 학습하는 상황과 유사한 상황을 만드는지를 이해해볼 필요가 있습니다.
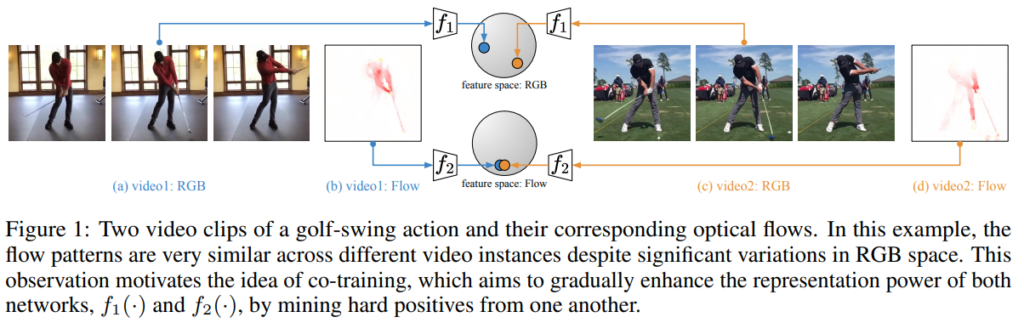
[그림 1]과 같은 상황이 있다고 가정을 해봅시다. 두 비디오 모두 골프를 치는 action에 대한 비디오이지만, 실내에서 치느냐 실외에서 치느냐에 따라 RGB에서의 표현력의 차이는 크게 발생합니다. 하지만 optical flow의 관점에서 보게된다면 두 비디오는 상당히 유사하다고 보일 수 있죠.
따라서 본 논문에서는 이러한 모달리티간의 표현력 차이를 활용합니다. Positive를 고를때, RGB에서는 다르게 보이더라도, optical flow에서 비슷하다면 positive로 고르고, Negative는 둘 다 다른걸 고릅니다.
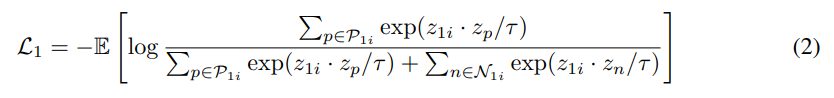
그래서 [수식 2]번이 등장합니다. 일단 아까 InfoNCE Loss와 달라진 점이 positive/negative를 고르는 방법만 달라지는데요. 거기서 모달리티로 RGB는 z_1, optical flow는 z_2로 표현하고 있습니다.

그래서 positive는 위와 같이 고르는데… 눈에 띄게 달라진 부분으로 topK(z_{2i}*z_{2j})가 보이네요. 이 부분이 optical flow의 유사도를 계산해서 그 유사도 중에 가장 유사한 K개를 고른 다음 그 K개에 해당하는 비디오들을 positive로 선택하고 나머지는 negative로 사용하는데요. 사실 이렇게 사용하면 positive가 여러개가 되어서, positive가 1개인 InfoNCE Loss와는 조금 다르죠? 그래서 Multiple positive를 사용하는 InfoNCE로 살짝 바뀐 모습도 볼 수 있습니다.
근데 이러면 optical flow에서의 유사도를 기반으로 RGB에서의 positive와 negative를 선택하게 됩니다. 이러면 RGB에서의 학습은 가능한데… optical flow는 그러지 못하겠죠? 그래서 반대로도 똑같이 해줍니다.
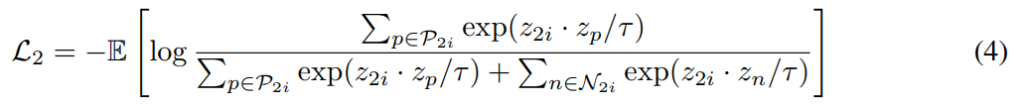
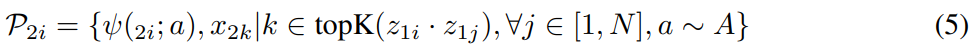
이제 [수식 4/5]는 RGB에서의 유사도를 계산해서, optical flow의 학습을 위한 positive/negative를 RGB에서 꺼내옵니다. 설명은 위의 내용과 정확하게 반대로 보면 되서 넘어가도록 하겠습니다.
The CoCLR algorithm
자 그래서 학습을 위한 Loss는 설명이 끝났습니다. 우선적으로 최초 학습은 RGB 모델과 Optical flow를 사용하는 모델이 개별적으로 Info-NCE Loss를 활용하여 학습을 진행합니다. 그래서 기본적인 표현력이 생기게 만든 다음 co-training을 수행합니다. Co-training 단계에서는 RGB를 사용하는 모델과 Optical flow를 사용하는 모델을 번갈아가면서 학습을 시킵니다. RGB에서는 L_1로 학습하고, Flow는 freeze 해둡니다. 그리고 RGB를 freeze하고, Flow를 L_2로 학습시킵니다.
Experiments
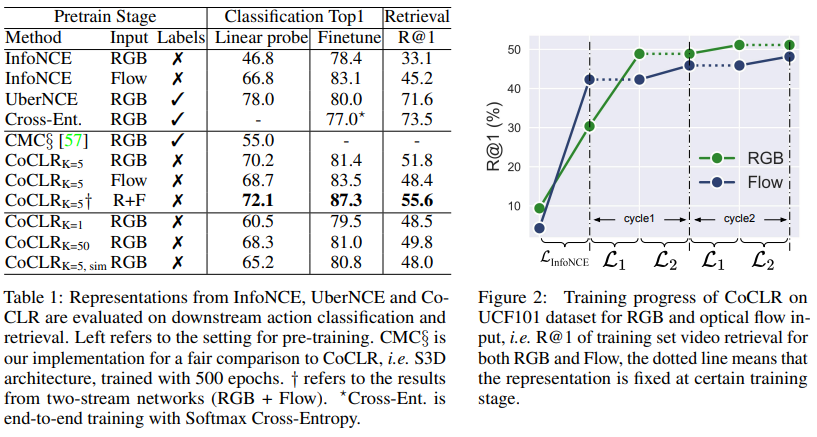
그래서 이런 학습 전략이 실제로 성능을 얼마나 끌어올리느냐를 보면 위의 [그림 2]를 먼저 보면 됩니다. 일단 표현력을 가질때까지 infoNCE로 학습한 다음에 개별 모델을 학습시키는 cycle을 거치는데요. 확실히 InfoNCE만 학습했을 때 보다, 두 모델이 다른 모델이 학습을 하면서 오른 성능을 바탕으로 성능이 오르는 것을 볼 수 있습니다.
그리고 이런 경향성은 실제로 [표 1]에서의 정량적인 수치로도 확인할 수 있습니다. Linear Probe라고 적힌 방식은 모델에 뒤에 FC 레이어 하나 추가해서 평가하는 방식으로 보시면 되고, Finetune은 모델 자체를 학습하는 방식입니다. 일단 co-training을 했을 경우 성능이 명확하게 오른다는 것은 확인할 수 있습니다. 이러한 것들 통해서 CoCLR를 통해 UberNCE의 성능과 유사한 성능에 도달했다 라고 보면 좋을 것 같습니다.
(표에 Input이 다르더라도, 학습은 모두 RGB+Flow로 했습니다. 평가때 feature를 뭘로 만드느냐의 차이입니다.)
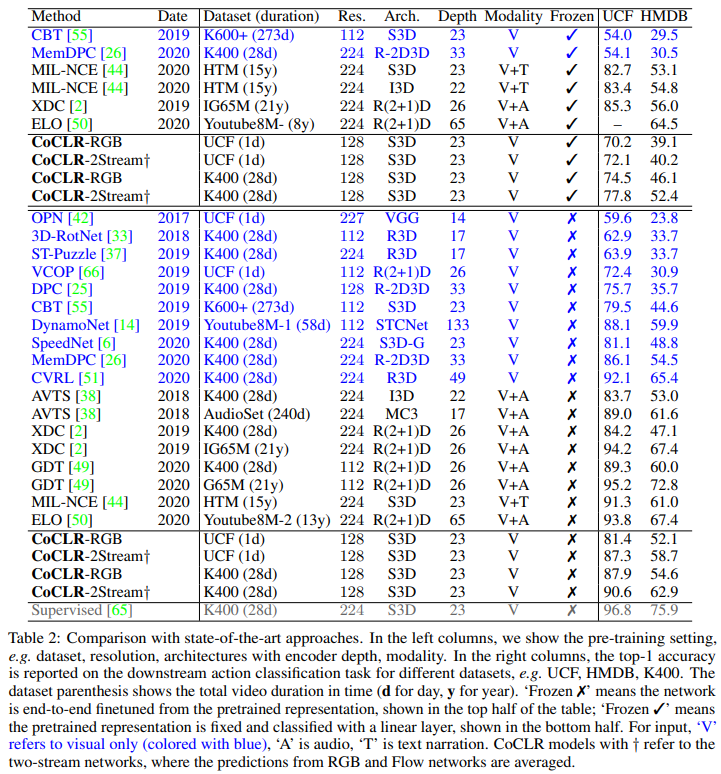
SOTA 방법론들과의 비교를 보면 조금 난잡하기는 한데요. 파란색으로 표시된 Visual 데이터를 사용한 경우에는 성능이 좋은 것을 볼 수 있습니다. 물론 더 성능이 좋은 모델도 있지만, 백본 차이가 있으니까요. 또 몰랐던 사실인데 Audio를 함께 사용하는 연구들이 많고, 성능도 꽤 준수하다는 것을 알게되었네요.
Conclusion
학습 전략에 대해서 조금 도움이 될까해서 읽어보긴 했는데. Action쪽에서는 확실하게 도움될 것 같고, 제가 중점적으로 쓰는 FIVR 같은 데이터셋에서는 어떻게 활용할 수 있을지… 고민을 조금 해봐야 할 것 같습니다. 그래도 Event bounday detection 쪽에서는 활용할 수 있을 것 같아 좀 더 고민해봐야 겠습니다.
친절한 리뷰 감사합니다.
마지막에 action dataset과 FIVR dataset에 관련하여 말씀해주신 부분에 질문이 있습니다.
비디오 관점에서 action dataset들과 FIVR dataset의 큰 차이점이 어떤 것이라고 생각하시나요?
용도가 다르다보니 비디오 하나하나를 봤을 때 비디오의 구성이나 시점, 내용 등에서 특성 차이가 클 것 같은데, 느끼셨던 차이점이 있는지 알려주시면 감사하겠습니다.
음… 아무래도 모션 정보를 활용할 수 있는지 아닌지가 큰 것 같습니다. FIVR에서는 이런 정보들을 활용할 수 없으니 이 논문과 같은 방법을 사용하기 위해서는 optical flow를 대체할 수 있는 무언가가 필요한데 그 무언가가 적당한게 없네요.