오랜만에 Active Learning 논문을 다시 들고 왔습니다. 해당 논문은 난잡했던 Active Learning 연구들을 시원하게 비판하면서 그 대안을 정리한 분석 논문입니다. 한줄로 요약해보자면 ….. 그동안 너네가 발표했던 Active Learning 성능 다 체리픽이고, 진짜 성능은 랜덤으로 뽑는 것과 다를 바 없다 라는 메세지가 되겠습니다. 제법 파격적네요 ..ㅎㅎ 저는 나름대로 설득이 된 부분이라 한번 리뷰해보도록 하겠습니다.
BackGround
이제 우리 연구실에 오래 계신 분들이라면 Active Learning에 대해 간단하게 아실 것이라고 생각이 듭니다. 쉽게 말하자면, 라벨링하더라도 더 좋은 데이터를 우선적으로 뽑아서 라벨링을 해보자! 라는 아이디어에서 시작된 태스크 입니다.
제가 지금 하고 있는 다크데이터 과제와 연관을 지어 보자면.. 다크데이터는 라벨링도 되어 있지 않고, 어떤 데이터인지 알 수 없는 엄청나게 많은 양의 데이터를 의미합니다. 자리만 차지하고 쓰지는 않는 데이터란 말이죠. 이렇게 낭비되고 있는 데이터를 쌓아두지만 말고 한번 활용해보자! 어떻게 활용할까? 가 바로 다크데이터 과제의 메인 태스크라고 할 수 있습니다.
이러나 저러나 데이터를 사용하기 위해서는 라벨링이 되어 있어야합니다. 어차피 라벨링을 해야한다면 즉, 라벨링 비용이 고정되었을 때 더 좋은 데이터를 선별하는 모델을 만드는 게 Active Learning 입니다. 여기서 “좋다”는 성능을 더 높일 수 있는 것이 그 예시라고 할 수 있을 것 같습니다.
따라서 Active Learning 은 좋은 데이터를 선별해내는 모델을 만드는 것이다 라고 요약할 수 있습니다. 관심있으신 분은 제가 리뷰했던 논문을 살펴보시는 것도 좋을 것 같네요. (이 분야를 처음 공부할 때 나름 열심히 정리를 했었거든요..)
[CVPR 2022] Towards Robust and Reproducible Active Learning using Neural Networks

Introduction
기존 Active Learning 에서는 가장 큰 이슈 3가지가 있습니다.
- Random Sampling의 성능이 논문마다 다르다
- 동일한 Active Learning 방법론일지라도 논문마다 보고된 성능이 다르다
- 서로 주장하는 바가 다르다 (Uncertainty논문은 Uncertainty 기반이 더 좋다 / 그 반대 진영도 마찬가지)
저도 이 부분은 약간 동의하는 바인데요. Active Learning 이라는 분야가 선행연구이기도 하고, 활발하게 연구되는 분야가 아니다 보니 그렇지 않을까 하고 그냥 지나쳤던 저에게 일깨움을 준 부분이었습니다. (제가 해당 논문을 읽게된 강력한 계기가 되기도 하였구요)
뭐 정리하자면 기존 연구들이 통일성 없이 진행되고 있다는 것이 가장 키포인트…일 것 같네요. 이것말고도 저자가 추가로 생각해낸 문제점은 (1) 기존 연구들에는 정규화가 고려되지 않고 (2) 매 iteration 마다 hyper-parameter 가 똑같다, 가 있습니다.
처음에 Introduction만 읽고 (1) 이 그렇게 critical 한 문제일까 라고 고민을 했는데, 논문을 다 읽고 다시 리뷰를 하려고 보니 왜 그런지 알 것 같네요. 기존 연구자들이 왜 성능을 다 다르게 리포팅하였을까요? 저자는 왜 그랬을지 그 이유를 고민하다가 정규화 때문임을 설명하려고 한 것 같습니다. 즉, 기존 Active Learning 에서는 정규화를 크게 고려하지 않았는데, 그렇기 때문에 매번 성능이 다르게 나오는 원인 중 하나다 라고 저자는 분석하였습니다.
따라서 저자는 이 논문을 통해 얘기하고 싶은 것은 다음과 같습니다.
Active Learning은 성능의 분산이 심한만큼, 실험을 여러번 반복하여 성능을 리포팅해야한다. 그리고 강력한 정규화 기법이 적용된 Random Sampling 보다 일관되게 뛰어난 성능을 보여야한다. (이를 위해 내가 가이드라인을 제공하겠다 …ㅎㅎ)
Regularization and Active Learning
우선 저자가 문제삼는 부분 2가지에 대해 설명하려고 합니다.
(1) 기존 AL에는 Regularization 기법이 고려되지 않는다! 많은 분들이 정규화에 대해서는 잘 아실것이라 생각이 듭니다. 심지어 이런 정규화 기법은 지금도 꾸준히 연구되고 성능이 리포팅되고 있죠. 그럼에도 불구하고 기존 Active Learning 에서는 이 정규화 기법이 고려되거나 사용되지 않았다는 것이 저자가 생각하는 첫번째 문제점입니다
그런데 이게 그렇게 중요한가? 라고 생각이 들 때 쯤! 저자가 생각하는 정규화의 중요성은 다음과 같습니다: 우선 정규화 기법이 딥러닝에서 성능 향상을 가져온 것이 자명한 사실인데, 기존 연구들이 이를 놓치고 있다면서 당위성을 주장합니다. 게다가 Active Learning 은 기존 데이터셋의 5% 혹은 10% 같이 아주 적은 데이터로 학습하는 방법론이기에 쉽게 과적합이 될 수 있기 때문에 더욱 필요하다고 합니다.
따라서 저자가 해당 논문에서 사용한 정규화 기법은 아래 4가지 입니다.
- parameter norm penalty
- random augentation (RA) … [NeurIPS 2020] Paper Link
- stochastic weighted averaging (SWA) [UAI 2018] Paper Link
- shake-shake (SS) Paper 설명
RA는 학습 시 랜덤하게 선택된 n개의 이미지들에 대해 왜곡 정도 m으로 변환하는 것이라고 합니다. 말 그대로 데이터 augmentation으로 이해하시면 좋을 듯 합니다.
그 다음으로 SWA는 최적화 과정 중 모델의 스냅샷을 저장한 다음, 다음 후처리 단계로 스냅샷을 평균화하여 모델에 적용하는 것입니다.
정규화는 크게 Data-Model-Metric에 적용될 수 있는데, 1)번은 Metric에 2)는 Data에 3)4)는 Model에 적용되었기에 이를 모두 적용한 것을 Strongly-Regularization이라고 하여 SR-Model 이라고 명명합니다.
Tuning Hyper-parameters
(2) 매 iteration마다 데이터 분포가 같은데, 왜 매번 고정된 하이퍼 파라미터를 써서 성능을 떨어뜨리는가? 에 대한 문제를 설명하는 파트인데요. 이 지적이 제법 합리적입니다. 분명 하이퍼 파라미터가 중요한걸 알면서 매번 데이터 분포가 달라지는 이터레이션에서는 고정된 하이퍼 파라미터를 쓰느냐? 라는 지적이죠.
따라서 저자는 매 이터레이션마다 하이퍼파라미터를 조정해보면서 이게 성능에 영향을 주는지도 실험하였습니다. AutoML이라는 툴을 사용하여 이터레이션마다 파라미터를 바꿔가는 것이죠. 정말 다른지는 실험을 통해 설명드리겠습니다.
Experiments and Results
Variance in Evaluation Metrics
모델 학습에는 다들 알고계시는 것처럼 initialization, augmentation, mini-batch selection, batchnorm 과 같은 확률적 구성요소가 포함됩니다. 이런 요소들은 서로 다른 최적화를 발생시킬 수도 있기 때문에, 동일한 실험을 여러 번을 진행해도 성능이 달라질 수 있는 것은 다들 익숙하실겁니다.
저자도 이 점을 고려해서 각 연구들이 서로 다른 초기 레이블링 데이터로 인해 발생하는 정확도의 variance를 평가하기 위해 5개의 랜덤하게 초기 레이블링된 세트를 구성하였습니다. 이 다섯개의 집한은 각각 랜덤 weights로 초기화된 기본 모델을 5번 학습하는 데에 사용하였습니다. 이렇게 구성된 샘플들 사이에 그리고 샘플들 간의 variance를 특성화하기 위해 총 25개의 모델을 학습하였습니다.
왜 이런 실험을 하느냐? 2가지의 의문을 해소시키기 위한 시도라고 생각이 드는데요. 하나, 초기 학습데이터를 어떤거로 사용하는지에 따라 성능이 다르고 이것이 바로 AL 방법론 간의 성능차이로 이어지는 것이다! 둘째, 그동안 발표된 논문 성능이 다 들쑥날쑥인데 뭐가 좋은건지 여러번 테스트 해보겠다! 이 가설을 확인하기 위해 실험을 진행하였습니다.
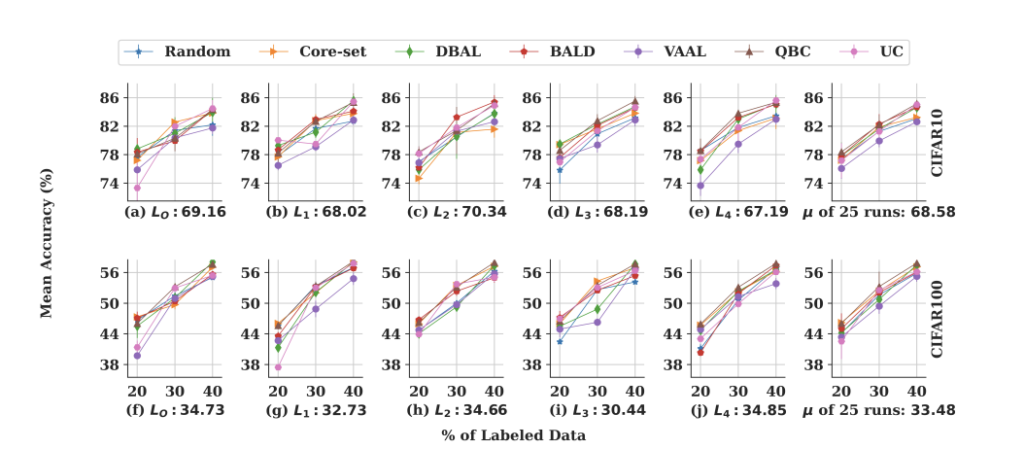
서로 다른 랜덤 초기화 시드에 의해 5번 학습되었고, 첫번째 시드에서는 AutoML로 하이퍼 파라미터를 조정하고, 나머지 4개 시드에서는 이 하이퍼파라미터를 다시 사용하였습니다. 가장 오른쪽 그래프는 25번 학습한 것의 평균을 나타낸 것인데요. 이 그림을 통해 알 수 있는 것은 특별히 어떤 하나의 방법론이 일관되게 좋은 성능을 보이는 게 없더라, 입니다. 허허, 제법 직관적이면서 설득적이라고 생각이 됩니다.
여기서 주목할만한 것은, 기존 연구들은 하이퍼 파라미터 튜닝과 같은 계산적 cost가 추가되었음에도 불구하고, 그 어떤 계산 과정도 없는 랜덤 샘플링에 성능이 특별히 대단한 방법론은 없다라는 것이죠..
매 이터레이션마다 하이퍼 파라미터가 업데이트 되겠지만, 다른 방법론도 만만치 않게 복잡한 연산들이 있따는 것을 감안하면 그동안의 연구들은 과연 뭐지..? 라고 생각이 듭니다. 실제로 저희가 연구를 진행하면서도… 랜덤 샘플링과 성능차이가 아주 적거나, 오히려 더 떨어지는 경우가 종종 있었던 것을 생각하면 이 가설이 틀린 가설이 아님을 느껴진다고나 할까요 …..?
Statistical Analysis of Variance
그리고 두번째, AL 방법에 의해 달성된 결과를 통계적으로 비교하기 위해 normality and variance를 평가합니다. 우선 normality assumption은 Kolmogorov-Smirnov test를 사용하였고, Levene’s test를 사용하여 homoscedasticity 가정이 평가되었습니다. 아래 테이블이 CIFAR-10과 라벨링 데이터 사용 퍼센트에 대한 확률적 분석을 나타낸 것이며, 각 방법론을 랜덤 샘플링과 비교한 결과를 보였습니다.
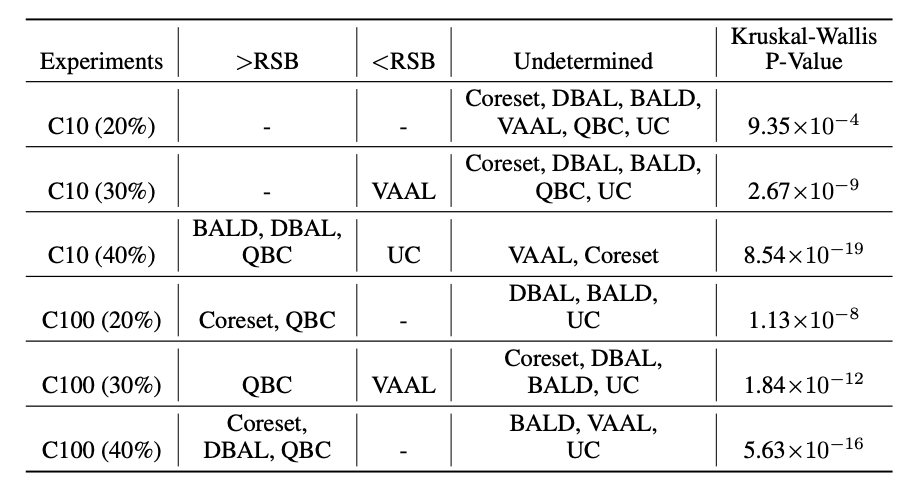
그 결과 평가된 방법 중 QBC(Query-by-Committee)가 6개의 실험 중 4개 실험에서 랜덤샘플링보다 우수하였고, 그 다음으로 Coreset 2/6, DBAL(Deep Bayesian Active Learning) 2/6, BALD (Bayesian Active Learning by Disagreement) 1/6 횟수로 랜덤샘플링보다 우수한 성능을 보였다고합니다. (제가 아직 이 확률적 기반의 수식 및 테이블을 이해하지 못하여 추가적인 공부가 필요할 것 같아서, 추후 이 점은 공부가 마무리되는 데로 어떻게 평가되는지 그리고 무슨 의미인지 추가하도록 하겠습니다)
결과적으로 저자는 해당 평가가 AL방법과 랜덤샘플링 방식과 공정하게 비교하기 위해 필요함을 주장합니다. 즉, 성능 매트릭에 성능이 얼마나 차이가 나는지 그 분산까지 평가할 필요가 있다는 것을 보였다고 합니다.
Differing Experimental Conditions
다음으로 라벨링 배치 크기, validation set, 그리고 class imbalance 에 대한 서로 다른 실험 조건을 수정하여 AL 방법과 랜덤 샘플링을 비교합니다.
Annotation Batch Size(b): 여기서 b는 어노테이터에게 다시 라벨링을 하라고 요구하는 데이터의 개수입니다. 다시 말해, 모델이 라벨링하라고 선별한 데이터의 수라고 할 수 있죠. 이전 연구에 이어 주석 배치 크기가 전체 표본수(L+U)의 5%와 10%로 설정하여 실험을 진행하였습니다. 그림 2가 그 결과인데요, 앞서 저자가 지속적으로 주장하듯 기존 연구에서 주장하는 것과는 다르게 랜덤샘플링과 AL 성능이 크게 차이가 나지 않음을 확인할 수 있었습니다. 다시 말해 어떤 방법도 지속적으로 좋은 성능을 보이지는 않았습니다.
아래 그림 2가 바로 그 성능 차이를 보여주는 것인데요, 왼쪽 (a)는 CIFAR10에 대해서, 오른쪽 (b)는 CIFAR100에 대해서 리포팅합니다. 예를 들어 CIFAR-10 에서 40% 라벨링된 데이터 및 b=10%에서 UC는 다른 모든 방법론보다 뛰어나지만, b=5%에서는 BALD가 가장 우수한 성능을 보였습니다.
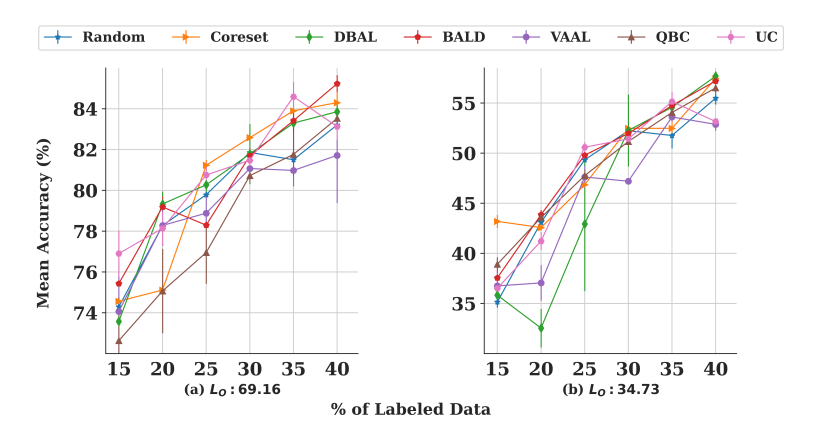
결국, 저자는 서로 다른 budget size를 사용하였을 때, 일관되게 좋은 성능을 보이는 방법은 없다라는 결론을 내렸다고 합니다.
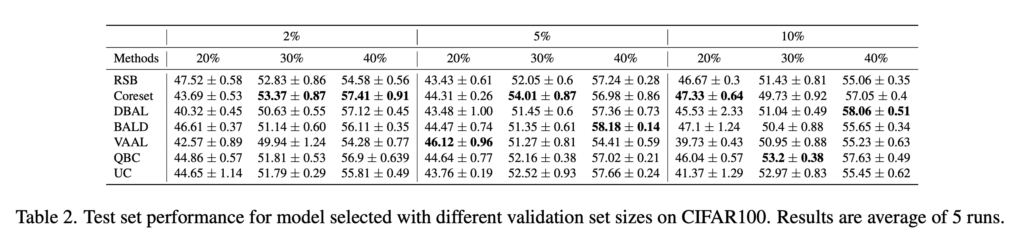
Validation Set Size(V)** 학습하는 동안, 가장 성능이 좋은 모델을 선택하여 테스트 세트에 대한 정확도를 보고하였는데요. V의 크기가 비교 실험에서 성능에 영향을 미치는 지를 평가하기 위해서 저자는 전체 샘플의 2%, 5%, 10% 크기로 CIFAR100에 대한 실험을 진행하였습니다. 아래 표 2가 그 결과입니다. 랜덤샘플링의 경우 각각의 V에 대하여 47.5%, 43.4%, 46.7%의 평균 정확도를 달성하였습니다. 그러나 라벨링된 데이터가 증가할 때의 정확도 값의 범위가 크지 않기 때문에, 레이블링된 데이터의 양이 많을수록 학습에 있어 정확도의 분산이 적다는 것을 알 수 있었습니다.
예를 들어, 40% 레이블된 데이터(L)에서 랜덤샘플링은 57.57%, 57.24%, 55.06%의 평균 정확도를 보였는데요, 이는 iteration에 비해 V 크기에 더 민감한 것으로 확인되었다고 합니다. 또한 이전 실험과 마찬가지로, V 의 크기가 변경됨에 따라 특정한 방법론이 일관되게 좋은 성능을 내는 것은 없었다는 결론을 내릴 수 있습니다.
Class Imbalance. 마지막으로 Class Imbalance 에 따른 각 방법론들의 강인성을 평가하였습니다. 이를 위해 CIFAR100에서 Labeled 데이터 세트인 L0를 구성하였습니다. 이는 다음과 같은 수식에 따라 샘플 수를 결정하였는데요: samples[i] = a + b ∗ \exp(αx) where i ∈ {1 . . . 100}; a = 100, x = i + 0.5, α = −0.046 and b = 400.i∈1…100
아래 그림 3을 통해 저자는 바로 랜덤샘플링과 최상의 AL 방법들간의 차이가 점점 더 많은 레이블링된 데이터에 따라 감소함을 확인할 수 있었다고 합니다.
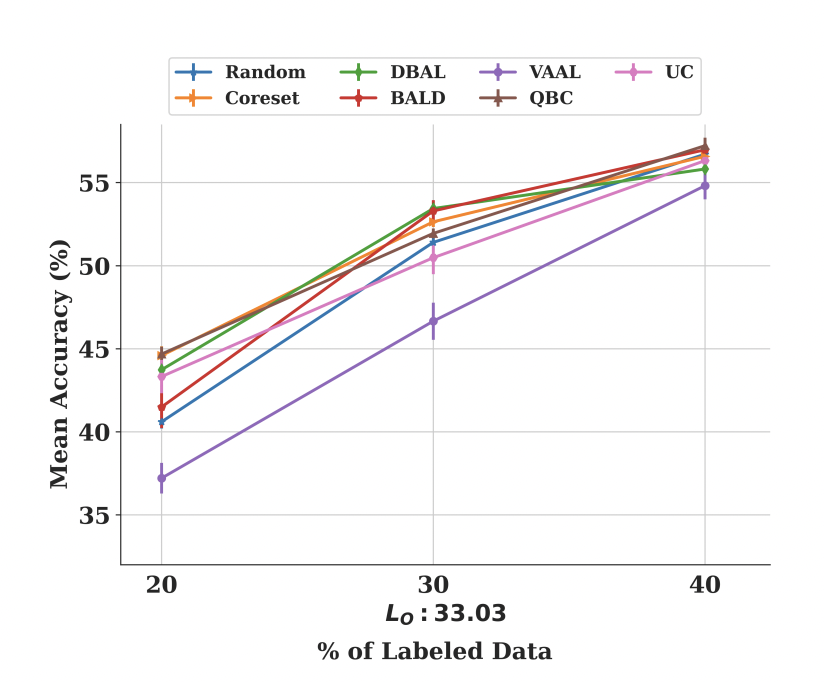
Regularization
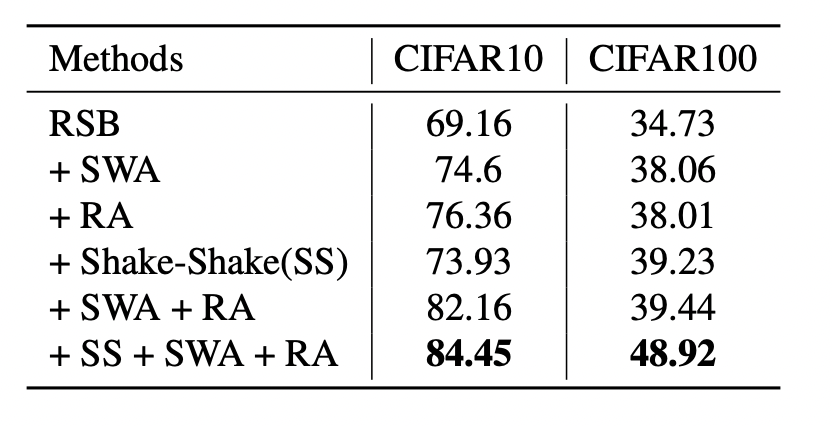
그리고 여기에서는 저자가 강력하게 주장하는 정규화에 대한 효과입니다. CIFAR10 및 CIFAR100 데이터 세트를 사용하여 실험을 하였는데요. L2-norm에 비하여 SWA, RA, SS와 같은 새로운 정규화 기법인 하이퍼 파라미터 변화에 강인하다는 결론을 얻을 수 있었다고 ㅎ바니다. 아래 테이블이 그 결과입니다. RandomSampling 에 대한 성능 그리고 왼쪽 그림은 다른 방법론과 비교한 결과입니다. 이를 토대로 정규화에 따른 성능 차이가 꽤나 크고, 잘못된 결과로 이어지는 것을 예방하고 게다가 성능의 분산을 크게 줄인다는 점읗ㄹ 알 수 있엇다고 합니다.
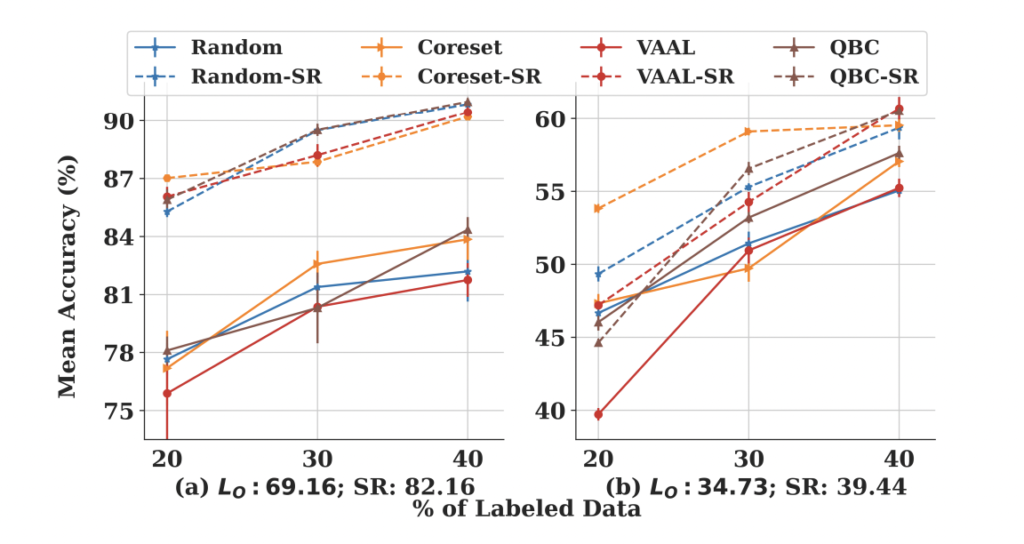
Conclusion
본 논문에서 수행한 광범위한 실험을 통해 Active Learning은 공통의 평가 플랫폼이 필요함을 주장하였습니다. 따라서 저자가 제시하는 가이드라인은 다음과 같습니다
- 실험은 모델 아키텍처 및 Budget size와 같은 다양한 환경에서 반복되어야 한다
- AL 결과의 재현성을 높이기 위해서는 공통 평가 플랫폼을 사용하여 평가 지표의 변동 원인을 최소화하려는 일관된 설정에서 실험을 수행해야 한다.
- 실험 설정값을 구성파일(ex. cfg, json 등)을 사용하여 공유해야한다.
- 데이터를 Train, Validation, Test 등으로 분할 하는데 사용되는 공용 데이터셋에 대한 인덱스 세트를 공유해야한다.
사실 해당 논문은 ImageNet에서 성능을 보였다는 것에서 주목하여 읽은 것인데요. 제법 설득적이고 날카로운 지적과 분석으로 배운 점이 많은 논문이었습니다. 어느정도 납득이 되는 점에 있어서는 추후 연구에도 고려를 해야할 것 같습니다.
재밌는 논문 리뷰 감사합니다.
제가 이해를 못한 것 같은데 새로운 정규화 기법들이 하이퍼 파라미터 변화에 강인하다는 것을 어디서 알 수 있는 건가요?
그리고 여기서 말하는 하이퍼 파라미터가 뭔지 궁금하네요.