Introduction
Speech Emotion Recognition 분야에서는 음성 신호로부터 감정을 분류하기 위해 많은 연구가 진행되었고 최근에는 딥러닝이 발전하면서 SER에 CNN 같은 기법을 사용하기 시작했습니다.
위의 알고리즘이 감정인식 모델에 성공적으로 적용되었으나 auto-encoder나 CNN같이 대부분의 네트워크에서는 고정된 차원의 input을 받는다는 점이 문제가 되었습니다. 발화 단위의 speech로 감정 인식을 수행해야 하는 task에서 input의 크기가 일정해야 한다는 것이 모순된다는 것이죠.
이러한 모순점을 해결하기 위해 다양한 길이의 feature를 입력으로 받는 모델을 설계하였는데 이때 사용되는 것이 LSTM으로 시간의 영향을 받는 sequence data를 처리할 수 있는 RNN모델을 기반으로 하고 있습니다.
그러나 LSTM 기반 모델에 단점이 존재하는데 하나는 연산량이 많다는 것이고 또 다른 하나는 sequence의 끝부분에 많은 비중을 두기 때문에 speech의 경우 emotion정보가 거의 없는 부분이 학습에 이용된다는 것입니다.
이러한 문제점을 해결하기 위해 저자는 LSTM의 내부 파라미터를 줄이는 self-attention 기법과 LSTM output을 효과적으로 활용하는 Attention on time/feature 방법을 제안하고 있습니다.
Related Works
LSTM
참고: Understanding LSTM Networks
LSTM 응용 모델들을 설명하기 전에 LSTM에 관해 간단히 설명하자면, 이전 입력값을 보존하는 RNN 네트워크라고 할 수 있습니다.

LSTM은 간단히 말하자면 forget gate를 통해 Cell state에 input 값을 얼마나 저장할 지 결정하고, input과 update gate를 거쳐 이전 Cell State인 C_{t-1}에 새로운 input인 x_t를 update 하여 새로운 Cell state인 C_t를 생성하고, 그 다음에는 C_t 값을 output gate에 통과시켜 모델의 최종 출력값을 생성합니다.
- peephole Connection LSTM model
[그림 2]와 같이 forget , input, output gate에 Cell State를 추가로 고려하는 모델로 C_{t-1}을 추가로 고려하여 연산량이 증가했으나, 성능 향상이 이루어진 모델입니다.

- Coupled forget and input gate
forget gate와 input gate가 합쳐진 모델로 이전 정보를 보존할 비율인 f_t를 계산하고 난 후, 새로운 정보를 받을 비율인 i_t를 따로 계산하지 않고 input x_t를 (1-f_t)만큼 update하는 모델입니다.

위의 기존 연구들과는 달리 저자는 LSTM 셀 내부에 집중하며 LSTM의 forgetting gate를 self-attention알고리즘으로 변형하였습니다. 변형된 forgetting gate는 기존 cell state에만 영향을 받기 때문에 input이나 직전 hidden state에 영향을 받는 기존 알고리즘보다 적은 연산량을 가지게 되었습니다.
Frame – Level speech Features
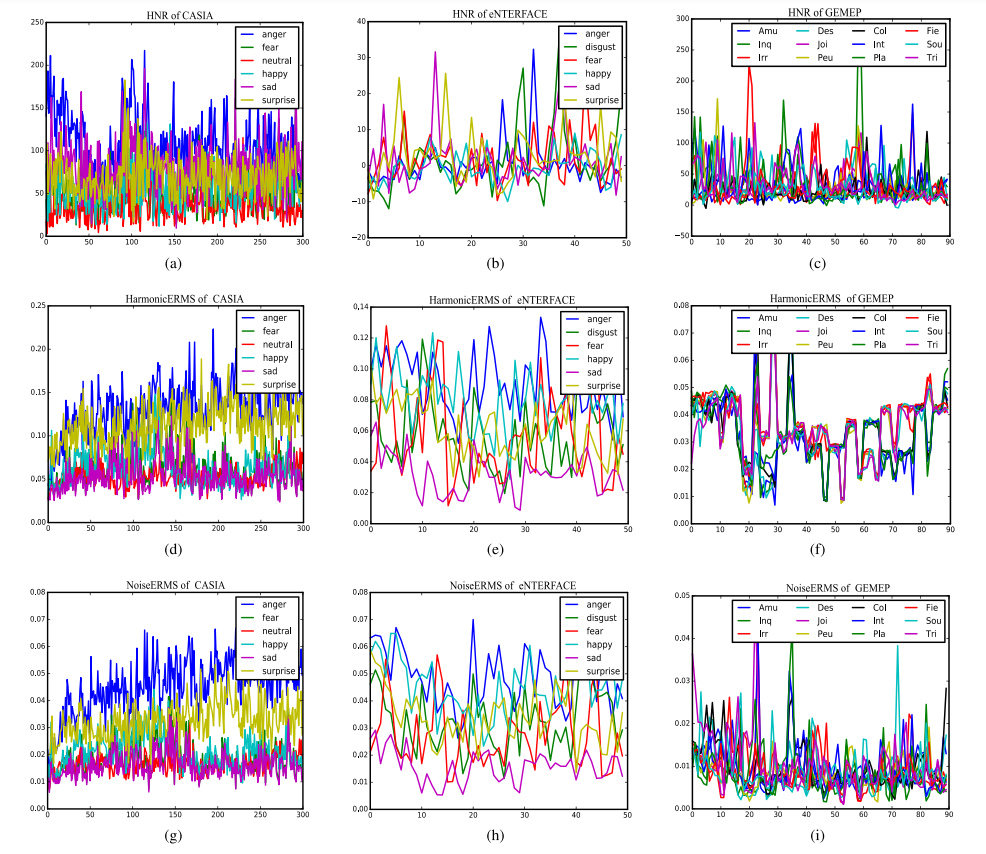
음성 데이터의 감정 인식을 위해서는 음성 신호에서 감정에 영향을 미치는 특징들을 찾아내야 합니다. 즉, 감정 상태에 따라 달라지는 audio signal의 특징을 찾아내야 하는데, 이를 emotion-related feature 라고 하며 이 논문에서는 이를 frame-level feature 라고 명명합니다. 감정이 anger 상태일 때, 일반적으로 목소리의 크기가 커지고, 음 높이의 변화가 발생하는 것을 알 수 있는 것처럼, 음성 감정 인식 task에서는 음성 신호의 pitch, energy, MFCC 등의 특징이 model의 input으로 활용되며, 이 논문에서는 Harmonic energy와 noise energy의 비율인 HNR을 사용합니다.
목소리가 거칠어지거나 쉰 소리가 날 때 harmonic 성분이 감소하고, noise 성분이 증가하여 HNR이 감소한다는 특징이 있어 CASIA나 EMODB 데이터셋을 활용한 감정 인식 feature로 사용되었다고 합니다.
그러나 이러한 feature들이 감정 정보를 포함하고 있기는 하지만, 그 정도는 데이터셋에 따라 다르게 나타납니다.
[ 그림 4 ]에 나타난 그래프들은 데이터셋 CASIA, eNTERFACE, GEMEP의 HNR, harmonicERMS, NoiseERMS를 각각 그린 것으로 특징 별 감정의 분포를 확인할 수 있습니다. x축은 각 데이터셋에서 추출한 sample 개수이며, HER에서 각 감정의 분포가 뚜렷하게 드러나는 CASIA와는 달리, eNTERFACE와 GEMEP은 그 분포가 뚜렷하지 않은 것을 볼 수 있습니다.
Attention-Based LSTM
이 논문은 Image Processing 분야에서 사용하는 attention 과 같이 입력 데이터의 모든 부분이 동일한 중요도를 가지지 않는다는 점에 영감을 받아 각 영역에 다른 가중치를 적용하는 self-attention기법을 제안하였습니다. LSTM의 forgetting gate에 self-attention기법을 적용하여 모델의 연산량을 줄이고, 성능을 향상시켰습니다.
동시에, 감정 인식에 사용되는 frame-level speech feature들은 time 정보와 feature-level 정보를 모두 포함하고 있으나 이러한 특징들은 classification performance에 있어 서로 다른 중요도를 가지고 있습니다. 따라서 모델의 최종 성능을 향상시키기 위해, lstm의 output에 attention 연산을 적용하였습니다.
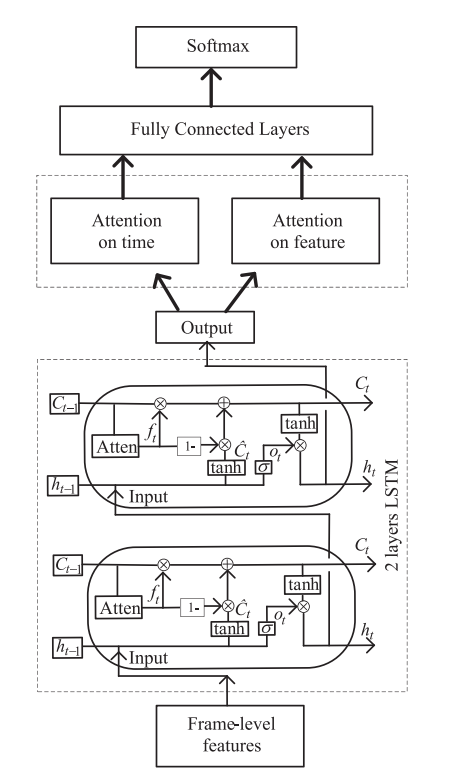
요약하자면 기본 LSTM구조의 forget gate를 변형하고, LSTM을 통과하고 나온 output을 time, feature 차원으로 나누어 각각에 attention을 적용해 주는 것입니다.
A. Attentin Gate
LSTM의 forgetting gate는 Cell state를 업데이트 할 때, 이전 Cell의 정보를 얼마나 보존할 지, 다른 말로 얼마나 잊어버릴 것인지를 결정하는 부분입니다. 아래의 [ 식 1 ]에서 x_t는 현재 input 값이고, C_{t-1}은 이전 Cell state로 직전 레이어까지 보존된 정보를 의미하며, h_{t-1}은 hidden layer output으로 직전 Cell 에서 x_{t-1}에 의한 출력값을 의미합니다.
아래의 식은 peephole LSTM 나타내고 f_t는 forget gate, i_t는 input gate, C_t는 업데이트된 cell state를 의미합니다.
f_t = \sigma(W_F\times[C_{t-1},h_{t-1},x_t]+b_f [식1]
i_t = \sigma(W_i\times[C_{t-1},h_{t-1},x_t]+b_i) [식2]
\tilde{C_t} = tanh(W_C\times[C_{t-1},h_{t-1},x_t]+b_C [식3]
C_t = f_t\bullet C_{t-1} + i_t \bullet \tilde{C_t} [식4]
[그림 5] 는 저자가 제안하는 self-attention LSTM 의 구조입니다.
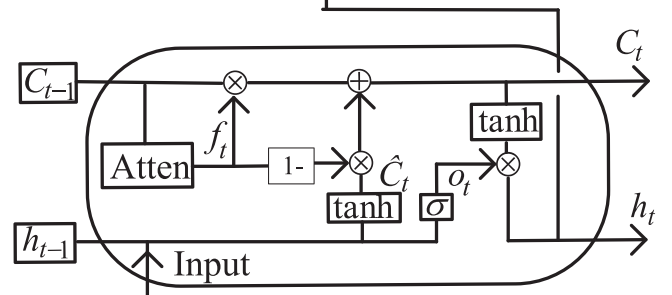
기존 lstm과 비교했을 때, forget gate의 입력으로 C_{t-1}만을 사용하고, (f_t - 1)을 input gate로 사용하고, 논문에서는 아래과 같은 방식을 self-attention model이라 하고, 이를 forget gate에 적용하였습니다.
f_t = \sigma(V_f\times tanh(W_f \times C_{t-1})) [식5]
[식 1 ] 과 [ 식 5 ]를 비교했을 때, h_{t-1}, x_t 만큼 가중치 파라미터인 W_f의 차원 수가 감소하여 연산량이 감소하고, 이로 인해 더 효율적인 LSTM모델 학습이 가능해졌습니다. 또한, 실험 결과를 통해 이러한 변화가 최종 성능에 영향을 미치지 않는다는 것을 보였습니다.
B. Output
frame-level speech feature의 길이는 원본 speech의 frame수에 따라 달라지는데, Traditional LSTM의 t번째 output은 다음과 같이 정의됩니다.
o_t=\sigma(W_o\times[C_t,h_{t-1},x_t]+b_o) [식6]
이때 lstm의 마지막 output인 o_{max\_time}은 마지막 frame의 결과로 B*1*N차원의 벡터입니다. 이때 B는 Batch size, 1은 시간 차원인데 마지막 time step의 결과이므로 1값을 가지게 됩니다.
이 논문에서는 모든 시간에 대한 output인 B*M*N 차원의 o_{all\_time}을 정의하고, 이 출력값의 time, feature 차원에 attention 가중치를 부여하고, weighted result를 방법을 제안합니다. 여기서 M은 time step수 입니다.
- Attention on Time Dimension
이 부분에서는 각 프레임이 포함하고 있는 감정 정보의 양은 다르기 때문에, 각 프레임이 감정 인식에 기여하는 정도가 달라지도록 가중치를 부여하는 방법에 관해 설명하고 있습니다. LSTM연산에 의해 o_{max\_time}는 가장 많은 정보를 축적하고 있습니다. 따라서 저자는 o{max\_time}을 기준으로 설정하였습니다.
시간 차원에서 attention을 적용하는 과정은 아래와 같습니다.
s_T = softmax(o_{max\_time} \times (o{all\_time}\times w_t)^H) output_T=s_T\times o_{all\_ time}w_t 는 NN차원의 학습 파라미터, s_T는 [B*1*M]차원의 time dimension attention 가중치 계수로 o_{max\_time}을 softmax에 통과시켜 o{all\_time}의 가중치를 확률로 나타낸 값입니다.
output_T는 o_{all\_time}에 가중치 s_T를 적용한 결과로 Time step인 M값이 frame 수인 N과 동일한 값을 가지고 있어 [B,1,N]차원의 출력값을 가지게 되며, [B,N]으로 reshape하여 다음 FC레이어의 입력값으로 사용합니다.
- Attention on Feature Dimension
논문에서는 output_T와는 달리 feature 간의 차이를 강조하기 위해 새로운 가중치 값인 s_F를 다음과 같이 정의하였습니다.
s_F=softmax(tanh(o_{all\_time}\times w_F)\times v_F) output_F = \sum_{time} s_F\bullet o_{all\_time}w_T와 마찬가지로, w_F, v_F는 [N*N] 학습 가능한 파라미터 값이며, N은 lstm의 hidden unit 개수이자 새로운 feature 공간을 의미합니다. s_F는 o_{all\_time}의 attention 가중치 값으로 output의 feature간 차이를 반영하는 값입니다. 즉, 어떤 feature가 더 중요하게 적용되는지를 나타내고 있는 값입니다.
output_F는 각 feature에 가중치를 적용한 값을 시간 차원으로 합하여 time dimension 에서의 평균 feature를 계산하는 것으로, output_T와 마찬가지로 [B,1,N] 차원을 가지며, [B,N]으로 reshape하여 최종적인 출력값이 됩니다.
두 차원에서 각각 얻은 output값은 [output_T, output_F] 형태로 concat하여 FC레이어에 입력값으로 활용합니다. 이로 인해 lstm의 출력값인 o_{all\_time}이나 o{max\_time}보다 key information이 향상된 feature를 나타낼 수 있게 됩니다.
앞서 언급했던 self-attention forget gate, attention on output 구조를 모두 연결하면 [ 그림 6 ] 과 같은 구조가 됩니다.
Experiments and Result Discussion
이 논문에서는 CASIA, eNTERFACE, GEMEP 데이터셋으로 실험을 진행하였습니다.
총 6가지의 모델을 비교하였으며 각각 normal LSTM, LSTM-T, LSTM-F, LSTM-TF, LSTM-at, LSTM-TF-at입니다.
LSTM-T는 Time dimension에, LSTM-F는 feature dimension에 LSTM-TF는 time과 feature모두에 Attention을 적용한 것이고, -at 모델들은 normal LSTM의 forget gate를 변형시킨 모델입니다.
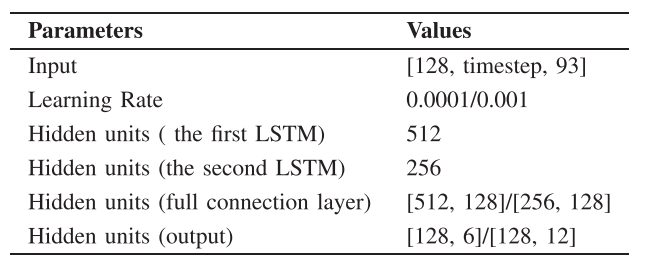
하이퍼파라미터는 [ 표 1 ]와같이 주어졌는데 input 차원은 [128, timestep, 93]으로 128은 batch size, timestep은 데이터의 프레임 수, 93은 speech에서 추출된 feature의 개수입니다.
평가는 각 감정 별 recall 값으로 진행되었습니다.
- 연산량 감소에 따른 학습 속도 상승
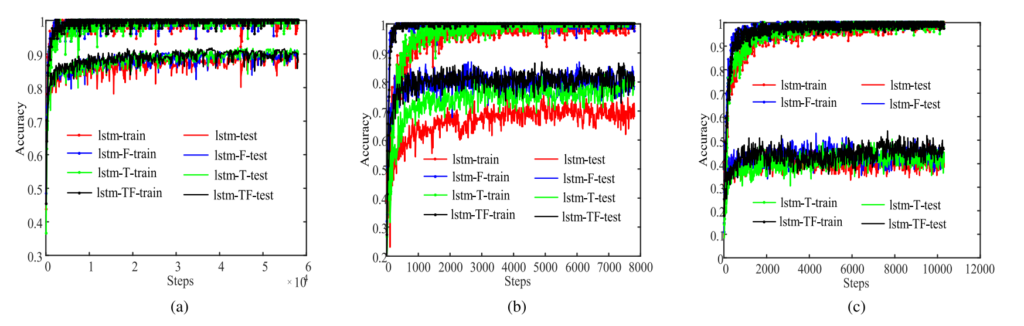
위의 [그림 7 ]은 training progress를 나타낸 것으로, forget gate에 self-attention이 적용된 LSTM-at, LSTM-TF-at 모델이 각각 LSTM과 LSTM-TF보다 더 빠르게 수렴하는 것을 볼 수 있습니다.
- Result
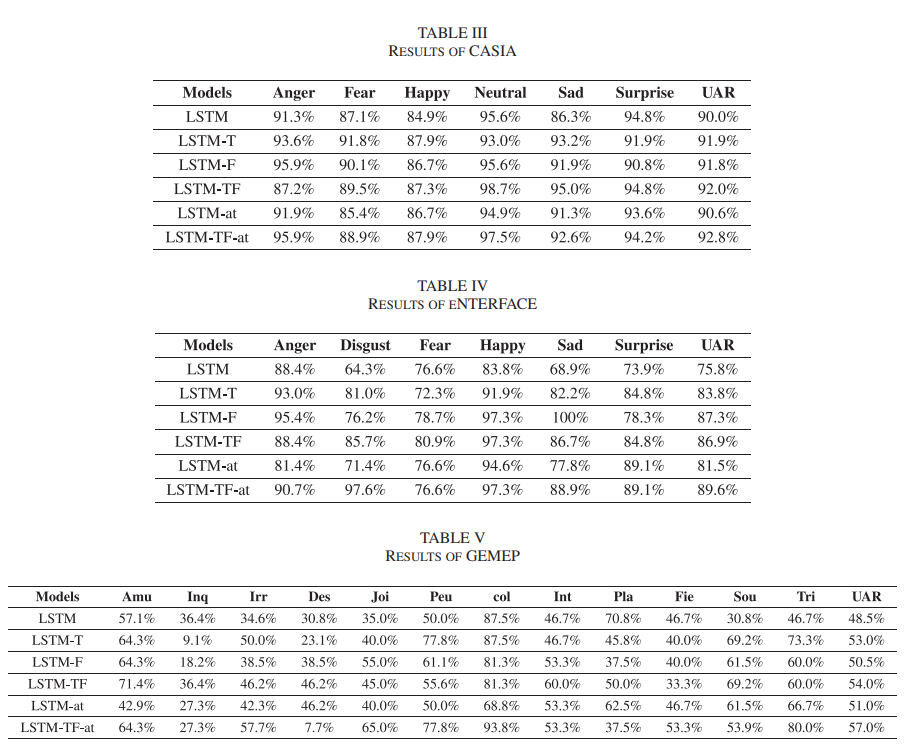
[ 표 2 ]는 각 모델 별 성능을 나타내고 있는데 각 감정 별 recall과 UAR를 표시하고 있으며, LSTM-TF-at의 성능이 가장 좋은 것을 확인할 수 있습니다.
안녕하세요. 분포에 대한 고민이 조금 있어서 리뷰를 보고 질문을 남깁니다.
HarmonicERMS과 NoiseERMS가 HNR을 이루는 구성 요소인 것으로 알고있는데, 그럼 HarmonicERMS과 NoiseERMS는 서로 반비레하는 관계인가요? 그리고 이 분포가 결국은 학습했을 때의 성능을 결정하는 것으로 보이는데, GEMEP 정도는 아니지만, eNTERFACE도 구분이 안되는걸로 봐야한다고 생각을 하는데요. GEMEP과 어떤 차이로 인해서 성능 차이가 발생하는지 논문에서 추가로 언급된 내용은 없나요?