제가 이번에 리뷰할 논문은 VIO(visual-inertial-odometry)논문이 아닌 VO(visual odoemtry) 논문입니다. 센서의 동기화가 맞지 않을 경우를 어떻게 알고 판단할 지를 고민하던 중 읽게 된 논문으로, 제가 생각하는 문제 상황과 일치하는 것은 아니지만, 예측된 pose 정보들 중 어떤 부분에 대한 조정이 필요할 지를 알아낼 수 있다는 점에서 적용 가능할 것이라 생각하여 이 논문에 대한 리뷰를 진행하게 되었습니다.
카메라 정보를 활용하는 VO(visual-odometry)는 여러 뷰의 기하학 정보를 이용하여 상대 pose를 추정하는 전통적인 방식은 카메라 파라미터와 환경 변화에 민감하다는 문제가 있었다고 합니다. deep learning기반의 방법은 조금 더 강인하였으나, 이미지 쌍을 활용하면 인접한 다른 프레임들을 고려하지 못하여 공분산을 측정하기 어렵고, local 하게만 pose를 최적화할 수 있다는 문제가 있었다고 합니다. 또한, 전통적 기법들과 일부 딥러닝 방식은 움직이는 객체를 해결하는 문제만을 고려하여, 굉장히 유사한 장소들이나 textureless인 장소에서 pose를 추정하기 어렵다는 문제가 있었다고 합니다.
이러한 문제를 해결하기 위해 이 논문에서는 confidence 평가를 이용하는 end-to-end의 unsupervised 방식을 제안하였습니다. 제안한 방법론은 2 stage 방식으로 우선 관련 이미지들에서 기하학적으로 대응되는 영역의 상대적 유사성을 측정하여 구한 confidence mask를 활용하여 상대 pose를 추정합니다. 이후 궤적의 기하학적 consistency를 기반으로 pose의 신뢰도를 평가하여 refine을 수행합니다.
Method
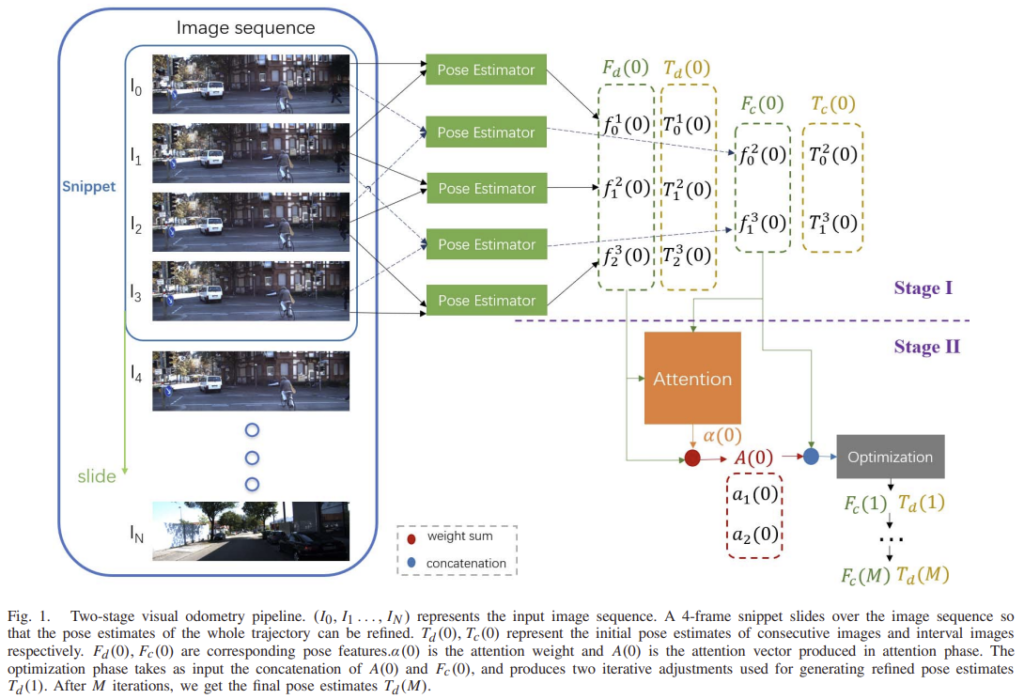
여러 쌍의 이미지를 이용하여 Pose estimator에서 상대 pose를 예측한 뒤, Pose optimization에 예측한 pose와 그에 대응되는 pose feature를 입력으로 받아 pose 추정을 refine합니다.
A. Pose Estimator
end-to-end의 unsupervised VO 알고리즘인 CM-VO(confidence mask based visual odometry)는 단일 뷰의 Depth CNN과 Pose RCNN으로 구성되어 있습니다. 이 두 네트워크는 unlabeled 이미지 시퀀스를 이용하여 함께 학습이 되고, test시에는 독립적으로 작동합니다. target view와 source view가 주어졌을 때 source view는 target 좌표로 와핑되어 합성 target view를 만들어 depth와 상대 pose를 추정합니다. 네트워크능 합성 target view와 target view의 차이를 최소화 하도록 학습됩니다.
1) View Synthesis
I_{k}와 I_{k+1}가 주어졌을 때 I_{k}는 target view가 되고, I_{k+1}은 source view가 됩니다. 위의 설명처럼 k+1을 k로 변환시켜 얻은 합성 이미지를 Depth CNN을 통과시켜 depth map \hat{D}_{k}, Pose RCNN을 통과시켜 상대 pose transformation \hat{T}_{k}^{k+1}(k에서 k+1로의 변환 관계)를 얻습니다.
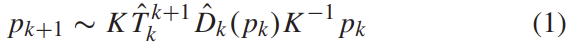
I_{k}의 좌표 p_{k}가 p_{k+1}로 투영된 좌표는 위의 식(1)을 통해 구할 수 있으며, 이떄 K는 카메라의 intrinsic matrix입니다.
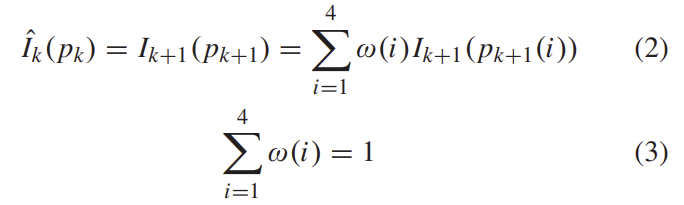
I_{k}로부터 합성된 이미지는 위의 식으로 정리할 수 있습니다. 이때 i는 p_{k+1}픽셀의 인접한 4-픽셀을 나타냅니다.
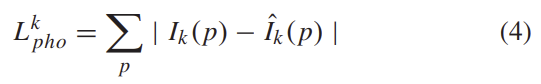
또한 view synthesis loss는 식(4)와 같이 계산됩니다.
2) Confidence Mask
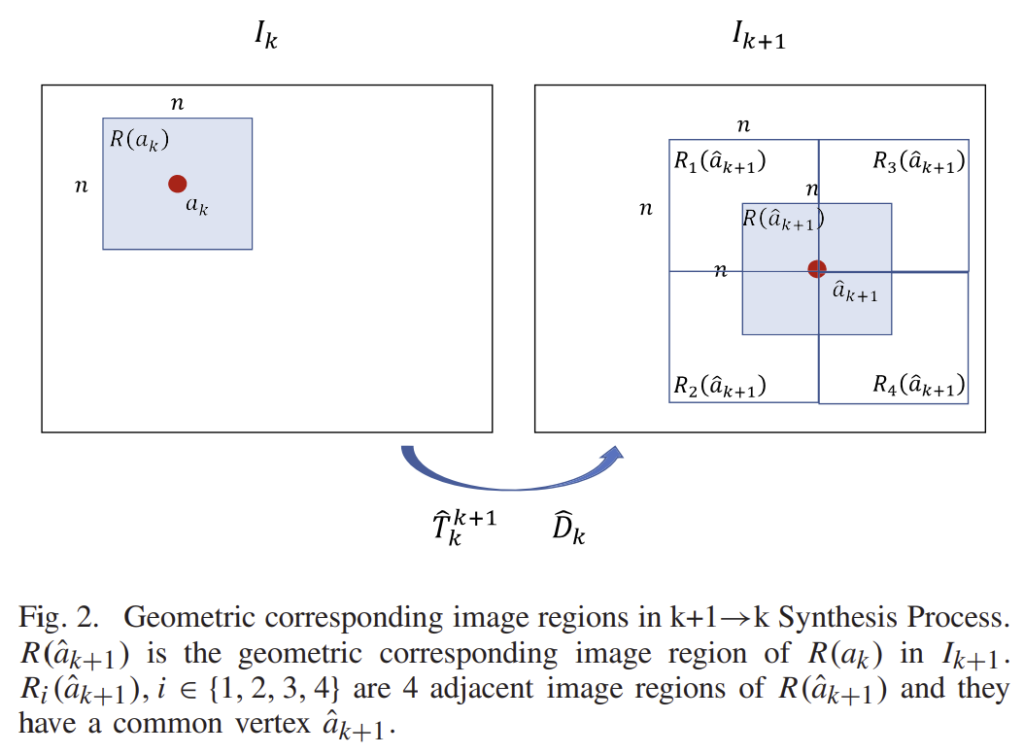
저자들은 기하학적으로 대응되는 이미지 영역이 유사할 수록, 정확한 pose 변환을 예측할 수 있을 것이라 보고, 이럴 경우 confidnece 값이 높아져야 한다고 합니다. 위의 그림2와 같이 중심점이 a_k인 nxn 윈도우 R(a_k)를 위의 식(1)을 이용하여 \hat{a}_{k+1}로 투영합니다. 이후 R(a_k)의 대응 영역인 R(\hat{a}_{k+1}) 부분을 crop하여 아래의 식 (5)와 (6)을 통해 두 영역의 유사도를 구합니다.
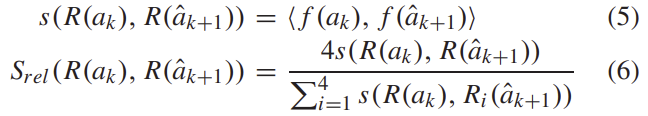
confidence 값은 이미지 전체를 통해 축적되고, normalization을 수행한뒤 confidence mask \hat{C}_k를 구합니다. (아래의 식 참고)
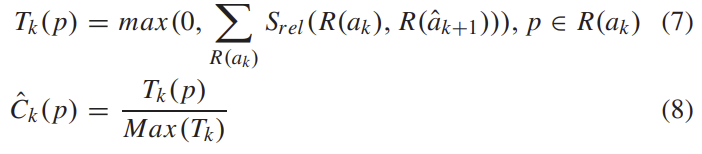
이렇게 얻은 \hat{C}_k는 앞서 구한 view synthesis loss에 가중치 역할을 합니다.
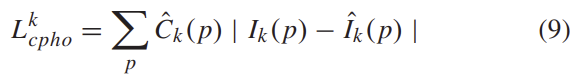
3) Loss Function
1)~2)의 과정은 k+1→k로의 합성 과정이였고, k→k+1로의 과정도 동일하게 수행하여 두 loss를 합쳐줍니다.
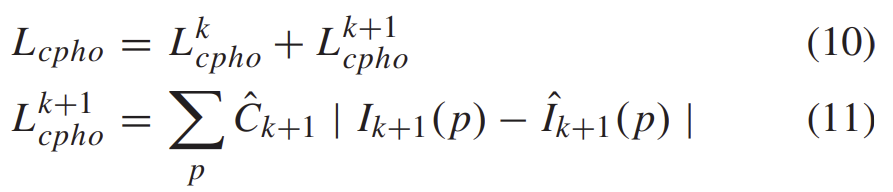
L_{cpho} loss 뿐만 아니라 SSIM loss도 k+1→k과, k→k+1에 대해 모두 구해서 더하여 loss를 계산해줍니다.
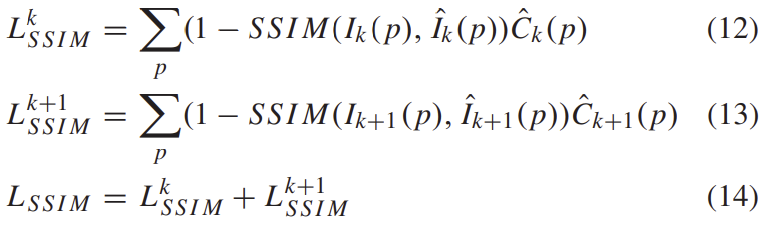
최종 loss는 아래와 같이 정리할 수 있습니다.
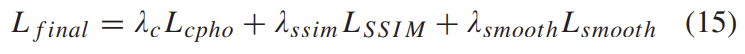
4) Network Architecture
Depth CNN은 DispNet을 이용하였고, Pose RCNN은 아래의 그림과 같이 구성된다고 합니다.
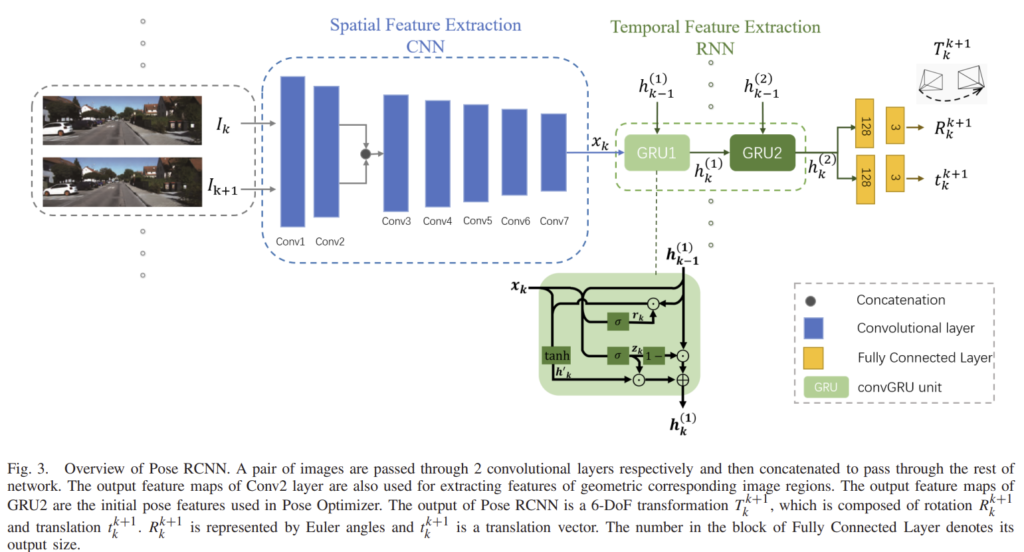
한 쌍의 이미지를 2개의 convolution을 각각 통과시켜 f(a_k),f(\hat{a}_{k+1})coarse한 외관 정보를 추출하고, concat하여 이후의 특징 추출에 사용합니다. 이후 LSTM의 변형인 GRU를 이용하여 pose를 추정합니다.
B. Pose Optimizer
local pose 최적화는 attention 기반의 방식을 이용하였다고 합니다. (I_{t-1}, I_t, I_{t+1})이라는 이미지 snippet이 있다고 하면 변환 matrix (T^t_{t-1}, T^{t+1}_t, I^{t+1}_{t-1})는 아래의 식 (20)을 만족해야 합니다.
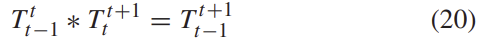
이는 V-SLAM 알고리즘의 전통적인 pose graph optimization방식이라 합니다.
image snippet (I_{0}, I_1, I_2, I_3)이 주어졌다고 했을 때, 최초의 consecutive 이미지에 대한 pose 추정 값은 T_d(0) = (T^1_0(0), T^2_1(0), T^3_2(0))이고 interval 이미지 간의 pose 추정 값은 T_c(0) = (T^2_0(0), T^3_1(0)), 각각의 대응되는 pose feature는 F_d(0) = (f^1_0(0), f^2_1(0), f^3_2(0)), F_c(0) = (f^2_0(0), f^3_1(0))라 하고 최적화 하는 과정에 대해 설명하도록 하겠습니다.
첫번째 반복시에 pose optimizer는 최초 pose feature를 입력으로 받아 interval 이미지에 대한 F_c(1)와 consecutive 이미지의 초기 pose 추정치를 출력합니다.
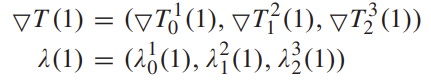
F_c(2)에 대해 다시 한번 반복하여 ![]() 를 구하고 M번 반복하여 최종적인 pose 추정 값인 T_d(M)을 구합니다.
를 구하고 M번 반복하여 최종적인 pose 추정 값인 T_d(M)을 구합니다.
이런 pose optimization 단계는 이미지 snippet에 soft-attention을 통해 정보를 전달하는 attention 단계와 이미지 snippet의 정보를 모으는 optimization 단계로 구성된다고 합니다.
1) Attention Phase
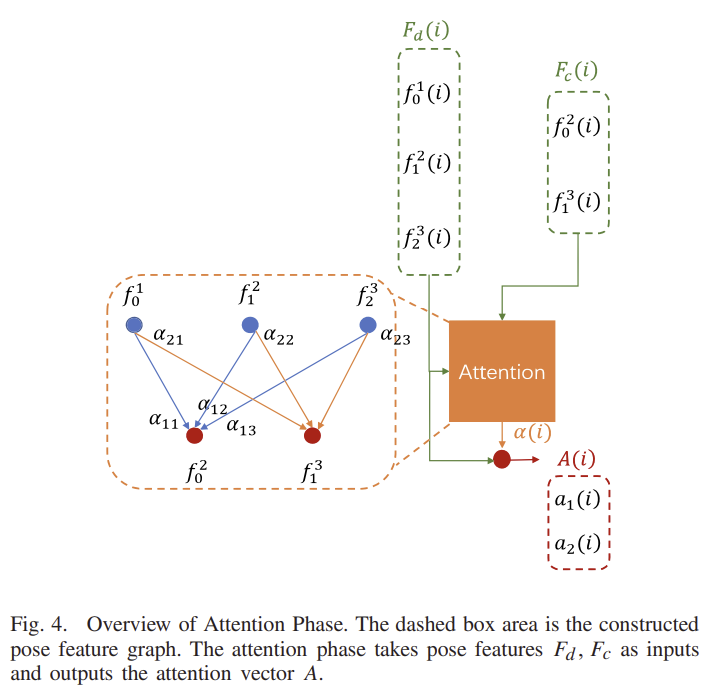
pose의 uncertainty를 측정하여 attention의 가중치를 계산하는 방식을 제안하였습니다. 위의 그림4와 같이 F_d(i)와 F_c(i)를 입력으로 하며 아래의 식(22)와 같은 방식을 이용하여 K(i) = (k^2_0(i), k^3_1(i))를 구합니다.
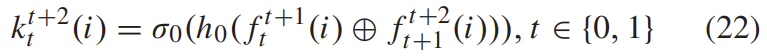
이후 아래의 과정을 거쳐 attention 가중치 \alpha (i)와 attention vector A(i)를 구합니다.
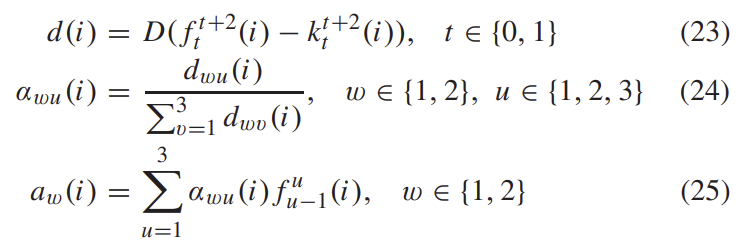
2) Optimization Phase
attention vector A(i)=(a_1(i),a_2(i))와 interval 이미지에 대한 pose feature F_c(i)=(f^2_0(i),f^3_1(i))는 concat하여 L개의 1D convolution과 ReLU를 layer를 통과합니다.
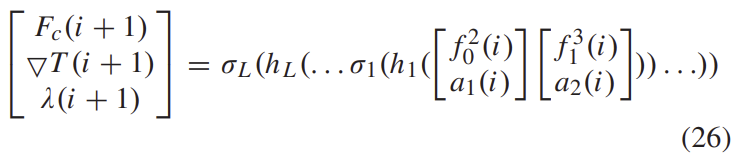
이렇게 pose optimizer를 통해 pose값을 refine하고, 보다 robust한 결과를 예측하게 됩니다.
Experiments
Dataset
- KITTI Odometry 데이터셋을 이용하여 제안한 방법론을 평가하였습니다.
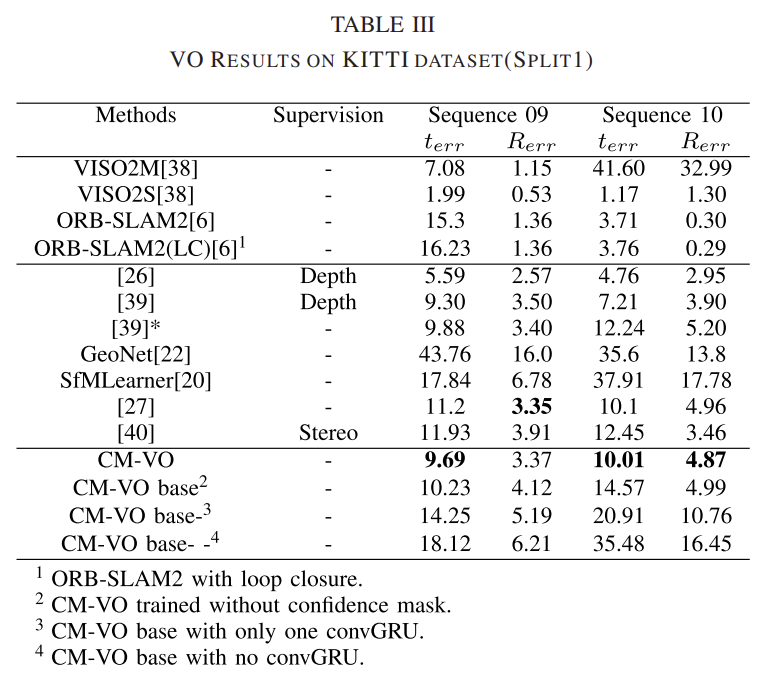
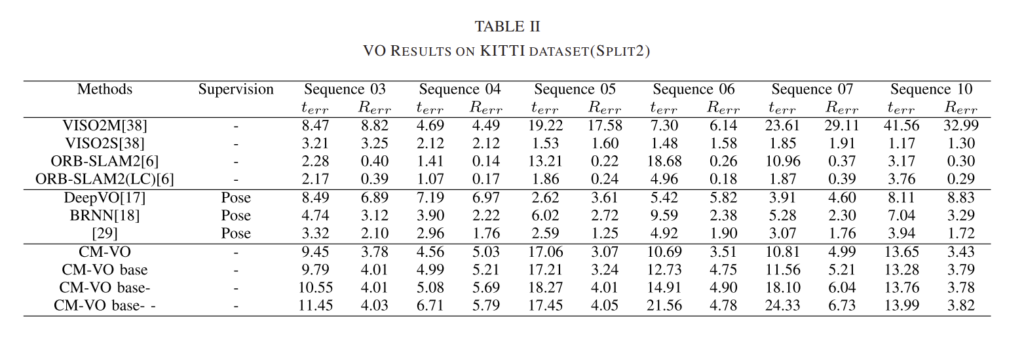
Quantitative Evalutation
선을 기준으로 첫번째 방식들은 전통적인 VO 방식, 두번째 줄은 딥러닝 기반의 VO 방식, 마지막 줄은 제안한 방식을 나타냅니다. 위의 표3을 통해 제안한 CM-VO 방식이 대부분 SOTA를 달성한 것을 확인할 수 있습니다.
Qualitative Evalutation
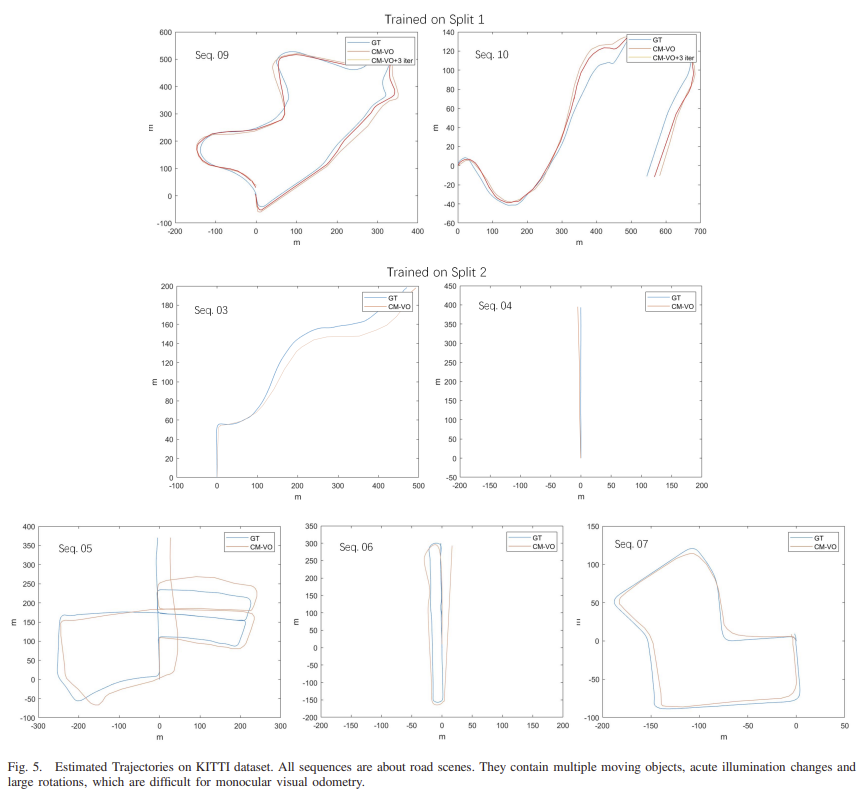
위의 그림 5는 궤적을 시각화 한 것으로 split1에 대한 결과들을 통해 3번 최적화를 반복한 경우 GT와 조금 더 유사해지는 것을 확인할 수 있습니다.

또한 그림6은 confidence mask를 시각화 한 것으로 움직이는 물체 영역과 유사하거나 textureless인 영역(바닥과 하늘)에 대해 식별하는 것을 확인할 수 있습니다.
리뷰 잘 봤습니다.
본 논문에서 pose estimator가 예측한 pose라는것이 sequence 사이의 camera pose 변화를 의미하는게 맞는거죠 ??
네 맞습니다.