오랜만에 본업으로 돌아와서 관련 논문을 리뷰할 수 있게 되었네요. 이제 10월이 되었으니 부지런히 저의 연구를 위해 달려봐야 겠습니다. 제가 이번에 리뷰할 논문은 몇개월 전에 리뷰한 PCGrad의 뒤를 잇는 Multi-task learning의 최적화 어려움을 해결하고자 제안된 논문입니다.
►—— 지난번 PCGrad 리뷰 링크 [NeurIPS 2020] Gradient Surgery for Multi-Task Learning
최근 다크데이터 회의를 가면서 Multi-modal 과 Multi-task를 혼동하는 분들이 꽤 많다는 것을 느꼈기에.. 간단히 그 차이를 정리하고 글을 시작해보려고 합니다.
Multi-task는 동시에 여러 개의 task를 학습하는 것을 의미합니다. 예를 들어본다면, Object Detection과 Retrieval을 같이하는 것과 말이죠. 따라서 Multi-task Learning 에서는 output이 여러개입니다.
해당 연구는 인간의 뇌의 작동 과정을 모사하여 제안이 된 것인데요. 여러 task를 동시에 학습할 때 그 task끼리 상호보완되어 성능을 높일 수 있다는 것에서 제안된 것이죠.
그에 반해 Multi-modal은 서로 다른 input이 여러개가 들어가는 것이라고 말할 수 있을 것 같습니다. 감정인식 과제에서 Text, Audio, Video를 사용하여 감정인식을 하려는 시도와 같죠. 대신 output은 감정 한가지 겠죠?
그런데, 제가 리뷰하려고 하는 논문은 Multi-task Learning 의 모델을 제안하는 것이 아닙니다. Multi-task Learning (이하 MTL 이라고 하겠습니다) 은 두 개의 서로 다른 태스크를 동시에 학습하는 것인데, 동시에 성능도 높이고 메모리도 확보할 수 있는 ideal 한 장점이 있습니다..만 실제로는 성능을 높이는데에 많은 어려움이 있습니다. 굳이 힘들게 MTL을 사용했지만, 단독으로 학습하는 것보다 성능이 떨어지는 경우가 꽤 많습니다.
그 이유 중 가장 큰 문제를 최적화 문제라고 할 수 있습니다. 왜냐, 서로 다른 태스크라고 한다면 Objective 역시 여러개이기 때문에 한번에 업데이트 만으로 두 개의 태스크를 만족하지 못하고 최적화가 되지 않아 학습이 되지 않는 상황으로 이어지기 때문입니다. 그렇기 때문에 최적화 문제가 가장 골치덩어리(??) 라고 할 수 있는데요.
제가 리뷰하려는 논문은 이렇게 태스크가 여러개 일 때 최적화가 되지 않는 문제를 중점으로, 이를 어떻게 해결할지 방법을 제안합니다. 지금부터 해당 논문은 정확히 어떤 점을 문제로 삼았고, 해결하려고 했는지 리뷰를 시작하겠습니다.
[Neurlps 2021] Conflict-Averse Gradient Descent for Multi-task Learning

Introduction
앞서 말씀드린 것처럼, MTL은 단일 모델로 서로 다른 여러개의 태스크를 학습하는 것을 의미합니다. 서로 다른 태스크 간에 파라미터를 공유하면서 개별적으로 학습하는 것보다 성능을 올릴 수 있다는 것이 메인 아이디어죠.
그러나.. 최적화가 어렵다는 문제가 있습니다. 실제로 많은 MTL 방법론에서는 모든 태스크의 평균 Loss를 사용하여 최적화를 진행하였는데요. 왜 어렵다는 것일까요? 예를 들어봅시다. A 태스크의 학습 방향과 B 태스크의 학습 방향이 다를 때, 이를 평균 취해 버리면 두 태스크 모두 이상한 방향으로 업데이트가 되어 학습이 되지 않은 상황이 있을 수 있습니다.
이러한 현상을 정의한 것이 PCGrad 논문이었는데요. 해당 논문에서는 이 상황을 학습 방향이 충돌한다고 하여 Gradient Conflict라고 정의하였습니다.
이를 해결하기 위해 기존 연구들은 그래디언트를 직접 수정한다거나, 휴리스틱하게 Objective를 수정하는 방식을 취했었다고 합니다. (전자의 경우 PCGrad가 그 대표인데, 후자는 아직 읽어본 적이 없어 추후 공부해보며 그 방식을 이해해봐야겠습니다)
그러나 해당 방법으로는 최종적으로 수렴하는 지점이 초기 모델의 파라미터에 따라 크게 좌우 되거나, 하나의 태스크만 지배적으로 최적화가 된다는 문제가 발생합니다. 아래 그림이 그 상황을 표기한 것입니다. 3개의 태스크를 서로 다른 initial point에서 3번의 최적화를 진행한 경우, Adam의 경우, 하나의 Task만 수렴하고 나머지는 수렴하지 않는 상황을 의미합니다.
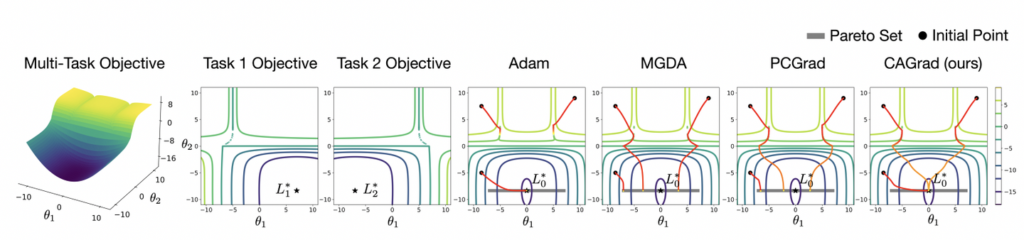
따라서 저자는 기울기 간의 충돌을 줄이면서, 간단하게 평균 Loss를 사용하면서 수렴할 수있는 Conflict-Averse Gradient Descent 방식을 제안하였습니다. 어떤 방식을 사용하였기에 정말 수렴할 수 있던 것인지는 다음 챕터에서 설명드리겠습니다.
Method
(1) Conflict-Averse Gradient Descent
우선 \theta' ← \theta - \alpha d 로 업데이트한다고 가정합니다. 여기서 \alpha 는 step size고, d는 업데이트 벡터 입니다. 해당 방법론은 전체 평균 Loss 인 L_0 뿐만 아니라, 개별 Loss 모두를 줄이는 것을 목표로 하기 때문에, 이를 고려하여 Loss를 설계하였습니다.
아래는 저자가 제안하는 방법론의 알고리즘입니다.

따라서 결국 해당 방법론을 요약하면 아래와 같습니다. PCGrad는 Gradient Conflict 가 발생하면, projection 시켜 그래디언트를 수정하는 방식을 채택했습니다.
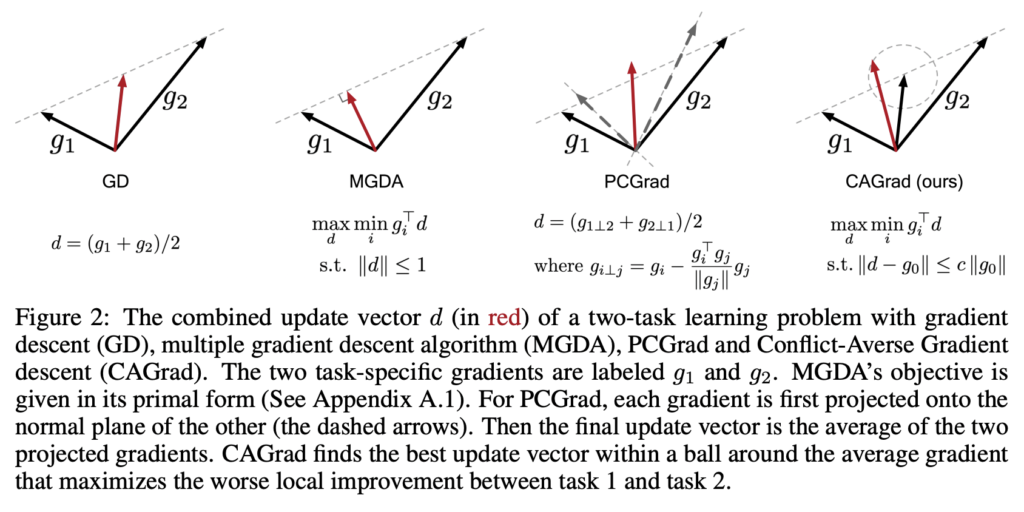
Experiment
우선, 저자는 아래 세 가지 질문에 답변하기 위한 실험을 수행하였고, 입증하였다고 합니다.
질문 (1) CAGrad, MGDA 및 PCGrad는 실제로 이론적 특성과 일관되게 움직이는가? (YES)
질문 (2) CAGrad는 상수 c를 변화시킬 때 GD와 MGDA를 복구하는가? (YES)
질문 (3) 감독, 준감독 및 강화 학습 설정에서 까다로운 멀티태스킹 학습 문제에 대해 CAGrad는 이전 SOTA 방법에 비해 성능과 계산 효율성 모두에서 어떻게 수행되는가? (CAGrad는 모든 설정에서 기존 SOTA에 비해 개선되었음)
우선 (1), (2)에 답변하기 위해, 간단한 Toy 최적화 문제를 만들어 비교 실험을 진행합니다. c를 조절하면서 CAGrad가 GD와 MGDA를 복구하는 것을 보이기 위해, LeNet으로 멀티 패션 MNIST에서 실험을 진행하였습니다.
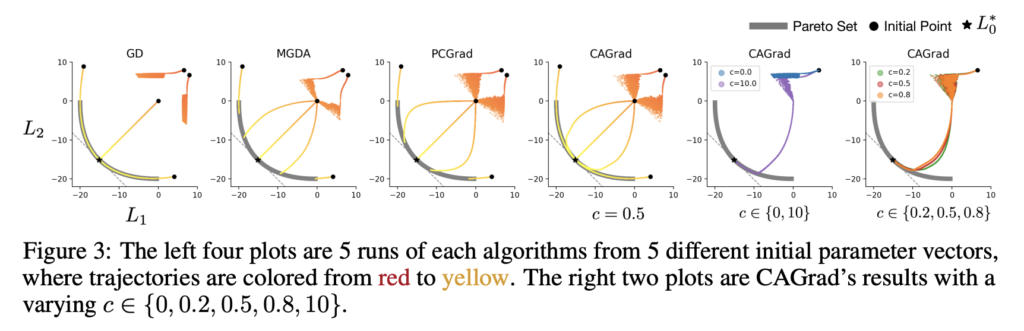
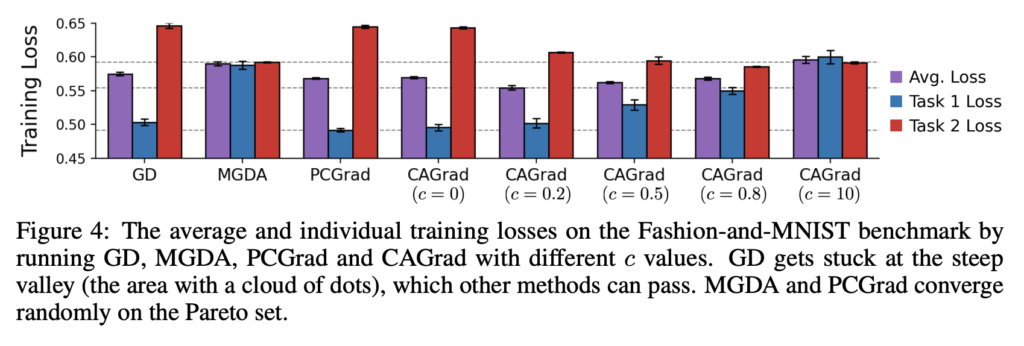
[2] Multi-task Supervised Learning
이제 여기서부터는 3번재 질문에 답변하기 위해 PCGradd와 동일한 설정에서 실험을 진행하였습니다. NYU-v2와 CItyScapes 데이터셋에서 실험을 진행하였는데, NYU-v2에는 class semantic segmentation, Depth estimation, surface normal prediction가 포함됩니다. 즉 3가지의 MTL이 수행됩니다. Cityscapes에서는 7개의 클래스 단위로 Semantic Segmentation, Depth Estimation 2가지의 태스크가 수행도비니다.
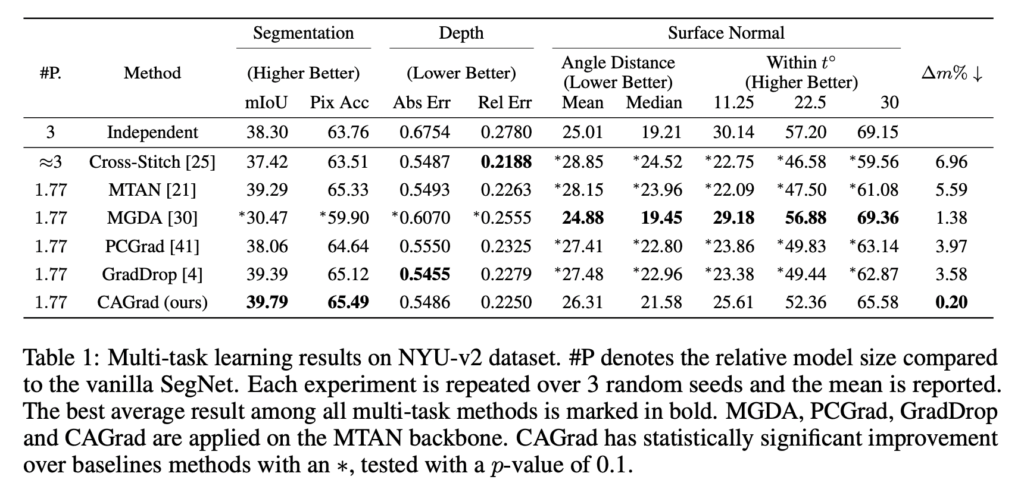
특정 태스크의 Loss의 최소 감소율을 명시적으로 최적화하는 동시에 평균 Loss로 수렴하는 알고리즘이었습니다. 제가 PCGrad를 사용하면서 느낀점은 굉장히 메모리 소비도 많고 느리다는 것인데, 해당 방법론도 직접 코드를 통해 확인해봐야겠습니다.
CAGard 실험에서 c가 의미하는 바는 무엇인가요?
좋은 리뷰 감사합니다.
PCGrad를 사용했을 때 수렴하는 지점이 초기 모델의 파라미터에 따라 크게 좌우 되거나, 하나의 태스크만 지배적으로 최적화가 된다는 문제가 발생하는 이유는 뭔가요?
CAGrad의 알고리즘을 살펴보면 g_{0} 와 파이(phi)가 의미 하는 것은 이해 했으나 아래의 min F(w)는 어떤 w를 찾는 과정인지 이해가 조금 어렵습니다. 부연 설명 부탁드립니다.
감사합니다.