안녕하세요. 제가 요즘 논문 막바지 실험 값을 뽑는 중에 감정인식 중간발표가 갑자기 생겨서 따로 논문을 볼 시간이 없더라고요. 그래서 리뷰로 가져온 논문은 감정인식 실험에서 사용했던 논문을 가져왔습니다. 리뷰… 라기보다는 사실 교훈에 가까운 리뷰입니다.
Introduction
본 논문에서는 감정인식의 중요성에 대해서 다루는데요. 여러 부분은 넘어가고 음성에서 감정을 인식하는 두가지 방법에 대해서 생각해봅시다. 화가 나면 언성이 높아지는 것과 같이 어조에 차이가 발생할 수 있습니다. 이런 어조만을 보는 방식이 하나가 있고요. 음성이라는 것이 말이라는 것이기 때문에 화자가 말하는 문장에서 정보를 보는 방식이 있습니다. 이 논문에서는 문장에서는 복잡한 감정을 인식하기 어렵기 때문에, 음성에서 더 많은 정보를 얻어내는 것에 목표를 두고 음성 감정 인식 모델에 대한 모델을 만들었습니다.
시작하기전에 본 논문에서는 MFCC라는 Feature를 사용했는데요. 해당 Feature에 대한 자세한 설명은 http://server.rcv.sejong.ac.kr:8080/2022/09/18/speech-recognition-domain-정리/ 에서 보시면 좋을 것 같습니다. 이 MFCC를 활용하는 방법에도 여러가지가 있습니다만… 본 논문에서는 매 초마다 총 40개의 coefficients를 뽑고, 평균을 내서 하나의 Feature로 사용합니다. (다른 논문에서는 2초 간격에 1.6초씩 overlap되도록 뽑는 것을 보면 하나의 하이퍼 파라미터 정도로 생각하면 될 것 같습니다.)
THE PROPOSED MODEL
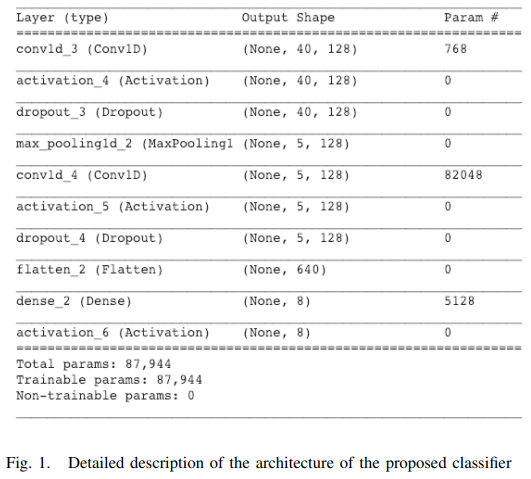
[그림 1]이 논문에서 제안하는 모델을 보여줍니다. 복잡하지 않은 구조인 것을 볼 수 있는데요. 단순하게 conv1d로 구성된 분류기로 볼 수 있습니다. 이는 대부분의 음성 감정인식 모델이 Raw-level feature에서 시작하는 것이 아니라 MFCC와 같이 Hand-crafted feature를 사용하고 있고, 이로 인해서 분류기를 어떻게 잘 만드느냐의 싸움으로 이어지지 때문에 Feature를 뽑을때 해당 데이터셋에 최적화된 세팅 & 분류기 튜닝으로 이어지기 때문인 것 같습니다.
그럼 왜 MFCC를 쓸까요? MFCC는 spectrum에서 Mel-frequency cepstrum를 고려한 방법입니다. 이 특성은 음파의 진폭을 compact한 vector 형태로 표현할 수 있다고 합니다. 사실 변환하는 방법에 대해서는… 기계학습 수업을 들으신 분들은 아시겠지만 똑같습니다. fast fourier transform을 고정 크기의 window 사이즈 만큼 적용해서 spectrum을 뽑고, ”Mel” frequency scale에 따라 정규화를 수행해줍니다. 그런 다음에 feature를 뽑을때는 40으로 고정해서 뽑았습니다.
데이터셋은 RAVDESS를 사용했습니다.

위와 같이 전문 배우들이 촬영한 데이터셋인데요. 보통 영문 음성 감정인식 데이터셋들이 같은 문장을 여러 감정으로 녹음을 하고 있습니다. 그리고 비교적 감정에 대한 폭이 크게 드러납니다. 실제로 Sad라는 감정에서 흐느끼는 형식으로 녹음이 되어있습니다. 다른 감정에서도 똑같은 원리로 녹음되어 있습니다.
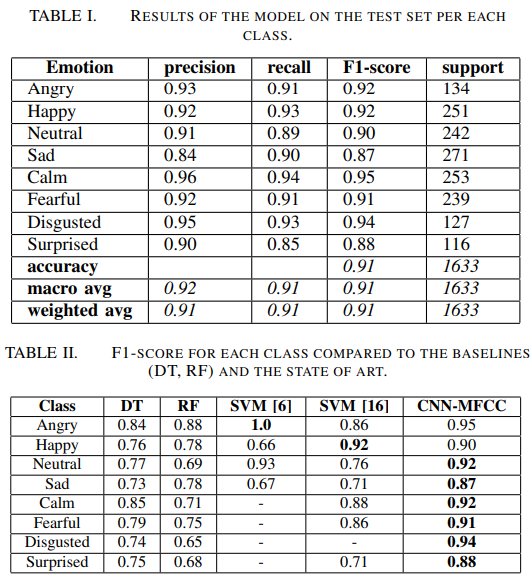
이런 데이터셋에서의 Cross-Validation 결과를 보면 위와 같습니다. 매우 높은 성능을 보이는 것을 보아 데이터셋의 특성 자체가 학습/평가 데이터셋이 분할되어 있지 않으면서 단순한 데이터셋이라 성능이 높게 나오는 것이라고 생각하고 마무리를 하려고 했는데요…
부록
하지만 이 논문 성능에는 가장 큰 문제가 있습니다. 너무 높은 성능을 내고 있는 것인데요. 비교적 간단한 모델에서 이정도 성능을 보이는게 이상하다는 생각은 했지만, 어쨋든 출판된 논문이니까 문제가 없을 것이라고 생각했습니다. 물론 이 생각은 실험을 하면서 잘못된 생각이었음을… 깨닫게 되는데요…
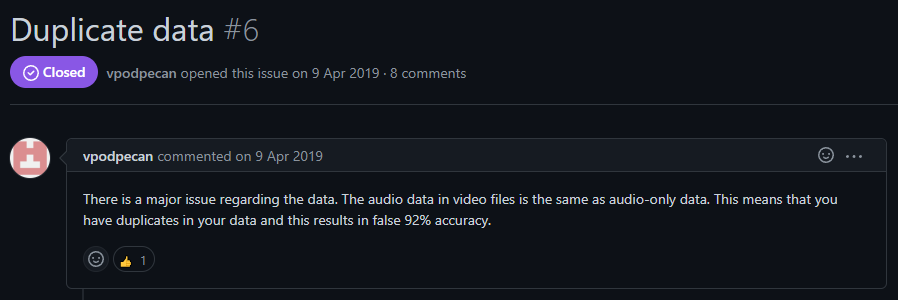
이 논문에서 사용하는 데이터셋(Ravdess)는 테스트 데이터를 따로 제공하지는 않아서, Cross-Validation을 해야하는데요. 그 과정에서 같은 데이터를 2번 넣어서 데이터를 나눌때 train/test가 함께 사용되었다는 이야기입니다… 어떻게 붙을 수 있었을까… 약간 놀라운 부분이었습니다.
물론 논문에서는 이 부분은 48MHz와 44.1MHz의 차이가 있어서 노이즈의 차이가 있기 때문에 오히려 학습 데이터를 강화한다는 설명이 붙어있기는 하지만 근본적으로 같은 데이터를 오디오 데이터로 가져왔는가 혹은 비디오 데이터로 가져왔는가의 차이이기 때문에 같은 데이터로 봐야 맞는 것 같습니다. 데이터셋 논문에서 이 부분도 명확하게 설명하고 있고요. 어쨋든 이 문제로 인하여 실제 성능은 저만큼 나오지 않는다는 문제점이 있었습니다. 그러면 원래 기본 성능은 어느 정도가 나올까요? 한번 확인해봅시다.
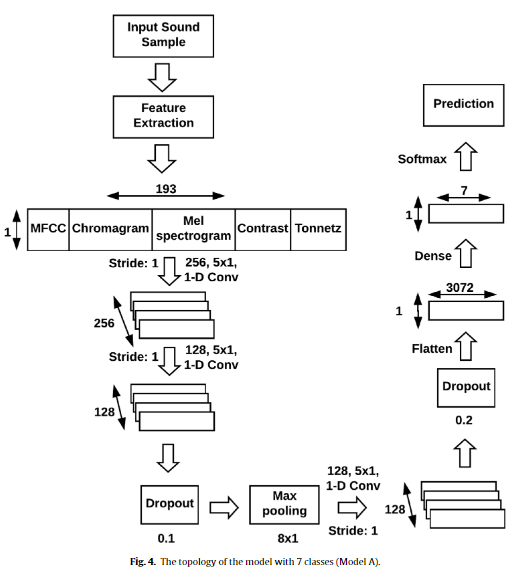
“Speech emotion recognition with deep convolutional neural networks”라는 논문에서 같은 데이터셋을 이용하여 71.61%의 정확도를 달성한 모델입니다. 모델은 위의 논문의 모델과 비슷하지만 여기서는 Feature를 여러개 사용한 것을 보실 수 있습니다. 다들 처음 보실텐데요. Chormagram의 경우에는 음악 분석에서 사용하는 feature로 음악할 때 사용하는 12음계(도레미파 솔라시도 같은 음계입니다)로 가공한 feature입니다. Contrast 같은 경우에는 영문 그대로입니다. MFCC와 Mel-scaled spectrograms의 차이를 바탕으로 계산되고요. Tonnetz는 Chromagram과 유사하지만 Tonal Centroid Space라는 6차원의 음성 높낮이를 가진 feature라고 합니다. 즉, MFCC가 가지고 있는 부족한 부분을 음악 분석에서 사용하는 Feature로 보완한 방법론이라고 보시면 됩니다.
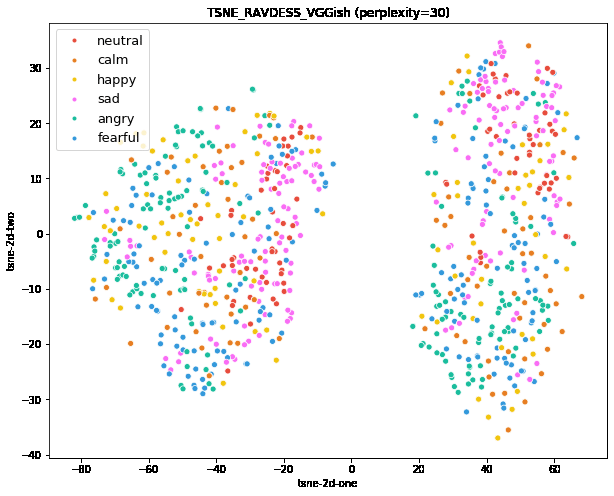
실제로 데이터셋 분포는 위와 같습니다. 이 논문은 아니고 위의 T-SNE 그림도 다른 논문에서 찍은 결과인데요. 참고용으로 확인을 해보면 비교적 감정의 분포가 균일해서 이 상태에서 Cross-Validation으로 나눠서 평가하면 성능이 어느정도 까지는 나올 수 있다고 생각할 수 있습니다.
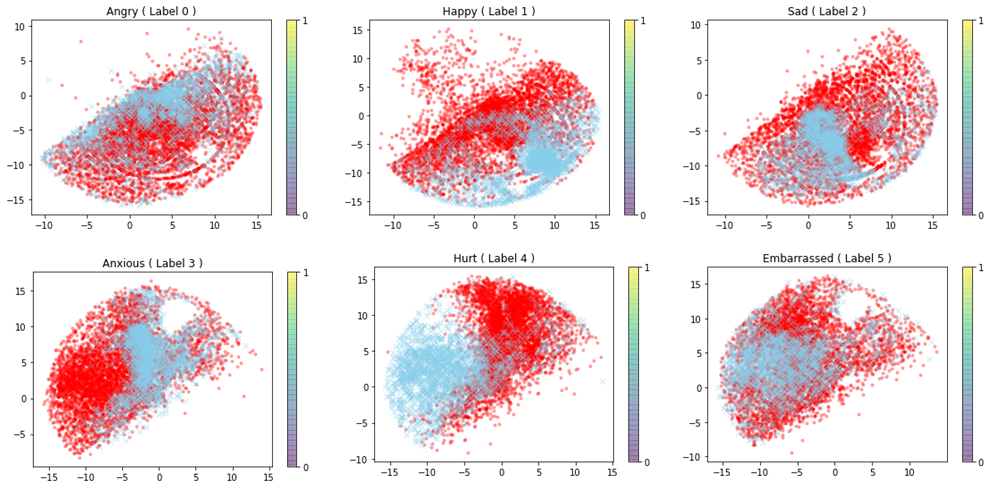
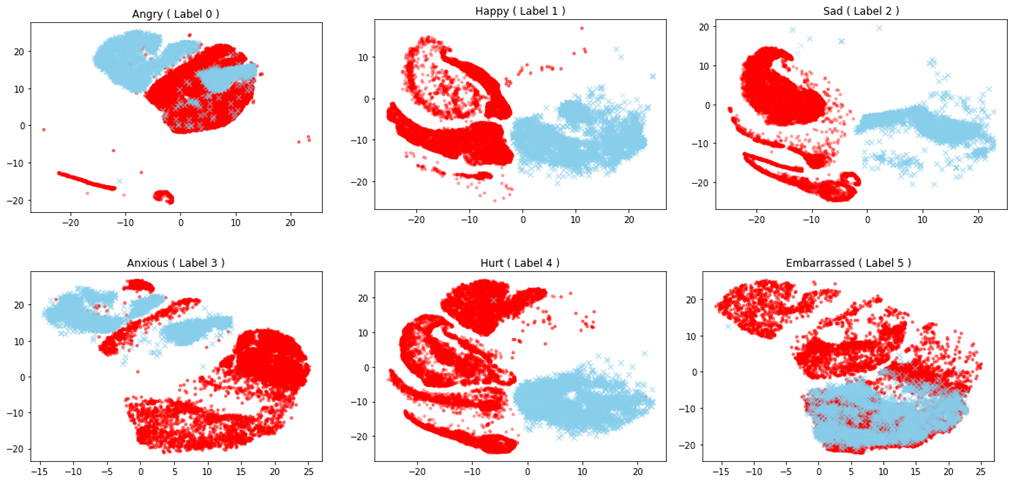
그래서 위의 베이스라인을 가지고 좀 더 복잡한 모델에서 학습을 하면 전혀 작동하지 않습니다. 이 부분을 T-SNE로 확인을 해 볼 경우 위의 그림과 같이 나오는데요. 위쪽 그림은 MFCC에서의 T-SNE이고, 아래는 학습 후의 T-SNE 그림입니다. 빨강색이 학습 데이터, 파란색이 평가 데이터인데요. 학습 전부터 일부 라벨은 전혀 분포가 일치하지 않는 것을 볼 수 있습니다. 따라서 음성에서의 “어조” 만으로 감정인식을 하는 것에 한계가 있을 수 있다는 것을 보여주는 부분입니다.
Conclusion
쓰다보니 논문 리뷰를 가장한… 실험 리뷰가 되어버렸습니다. 성능이 나온다는 논문의 설명만 믿고 실험한거였는데 참 아쉽네요. 실제로 MFCC를 활용한 음성 감정인식 방법론들이 많이 활용되고 기본적으로는 성능이 어느정도 높은 것도 맞지만, 그 높았던 성능은 문제가 있던 성능이었고… 복잡한 데이터셋에서 전혀 대응하지 못하는 것으로 파악하였습니다. 앞으로 논문을 볼 때 신뢰도에 대해서도 좀 더 잘 고민해야겠다고 생각되는 논문이었습니다.
공유해주셔서 감사합니다 ?
혹시 기존 연구와의 성능 간격이 매우 크지는 않았던걸까요? 리뷰어가 매우 큰 성능차이면 지적을 했을듯한데 그러지 않은것 같아 궁금하네요..
앞선 연구에서 71.61%를 달성한 연구가 있기는 하고, 다른 코드에서 80%를 달성한 연구가 있긴 한데… 90% 달성했다고 보고한 이 논문과는 성능 격차가 좀 큰 편이라 그 부분에서는 의아하긴 합니다.