Here’s
학습을 위해서 가공이 되지 않은, 비가공 데이터로부터 학습을 가능하게하는 self-supervised learning은 다양한 연구가 진행되어왔다. 또한 현시점에서 일반적으로 다음의 3가지 관점으로 나뉜다: 1) contrastive learning(MoCo), 2) asymmetric network methods(BYOL), 3) feature decorrelation methods(Barlow Twins). 흥미롭게도 본 논문은 이러한 접근법을 통합할 수 있다고 주장한다. 또한 통합된 형식으로 다양한 실험하여 각 방법론을 비교하였으며 결론적으로 momentum encoder가 성능 향상의 주요 요인임을 확인했다고 주장한다. 최종적으로, momentum encoder라는 성능 향상 요인에 입각하여 UniGrad를 설계하였으며 memory bank와 predictor없이 SOTA 성능을 달성하였다고 한다.
Overview
Self-supervised learning은 가공되지 않은 데이터 x로 부터, x를 표현할 수 있는 방법을, 직접 네트워크에 학습시키는 것이다. 해당 연구는 앞서 언급하였듯이 크게 3가지 방법(contrastive learning, asymmetric network methods, feature decorrelation methods)으로 연구가 되고있으며, 각 접근법에 대한 설명은 아래와 같다.
- contrastive learning
특징: need positive(oneself) and negative - asymmetric network methods
특징: need positive(oneself) only - feature decorrelation methods
특징: minimize the amount of information in batch
Detail
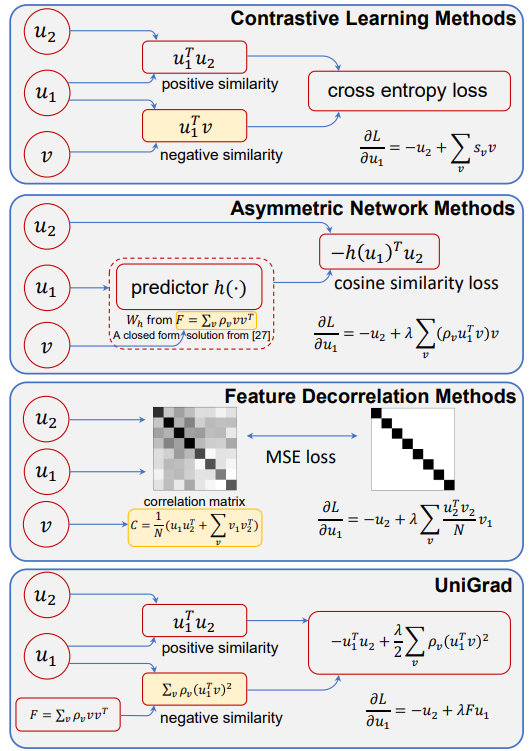
본 논문은 overview에서 소개한 세가지 접근법을 gradient 관점에서 통합하였다. 먼저 각 방법을 3가지 요소로 나누었는데 이는 다음과 같다:positive gradient, negative gradient, a scalar that balances theses two terms. 예를 들어 positive gradient와 negative gradient는 contrastive learing에서 positive sample, negative sample의 영향과 유사하다. 즉, contrasive learning은 위의 3가지로 구성된 gradient의 specific formula중 하나이다. 저자들은 이러한 unified framework를 UniGrad라고 이름지었는데, positive samle간의 유사도를 최대화 시키고, negative sample간의 유사도는 0에 수렴하도록 학습하기 위한 메커니즘을 명시적으로 가지고 있다. [그림1]을 참조하여 각 접근법에 대해 간단히 소개한것은 아래와 같다.
- Contrastive Learning Methods: sample간의 positive 관계와 negative 관계를 사용하는 대표적인 학습법으로 InfoNCE와 같은 loss를 이용해 positive pairs간의 표현은 유사해지고, negative sample간의 표현은 서로 멀어지도록 학습한다. 대표적인 예시로 1)MoCo가 있는데, target branch에 momentum encoder를 차용하고 memory bank는 target branch의 이전 output인 previous representations을 저장하여 negative samples로 사용한다. 또 다른 예인 2)SimCLR은 같은 batch내의 자기자신을 제외한 모든 samples들을 negative samples로 사용한다.

- Asymmetiric Network Methods: negative sample을 사용하지 않고 positive sample만으로 feature representation을 배우는 방법론이다. negative를 사용하지 않고 collapse를 피하기 위하여 해당 방법론은 predictor를 설계하여 주로 사용하며 모델 학습시 두 브렌치 중 하나는 stop gradient 상태가 일반적이다. 대표적으로는 Simsiam, BYOL이 있다. BYOP은 momentum encoder를 사용하였으며 Simsiam은 momentum encoder를 옵션으로 사용하였다.
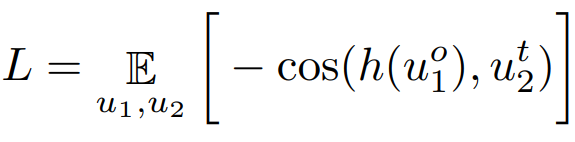
- Feature Decorrelation Methods: feature에서 관찰되는 redundancy를 줄여 collapse를 피하는 방법론이다. 대표적으로 Barlow Twins, VICReg가 있다.
저자들은 다양한 접근법을 통합할 수 있는 간결하고 효율적인 gradient form을 발견했다고 한다. 관찰에 따라 아래 수식1의 gradient를 제안했으며 UniGrad라고 명명하였다. 수식을 보면 위의 수식1, 2를 일반화한 형태임을 알 수 있다. 같은 context를 갖는 u1과 u2에 대한 유사도로 loss를 구성하며, negative와의 거리를 의미하는 F 를 두번째 term으로 가지고있다. 수식만 보면 negative sample을 사용하는 contrastive learning과 매우 유사하다고 느낄 수 있는데, 가장 큰 차이점은 negative와의 유사도가 positive와의 유사도보다 작아지도록 학습하는 InfoNCE와 다르게 negative와의 유사도가 그 자체로(명시적으로) 최소화(즉, 0이되도록) 설계하여 InfoNCE보다 직관적이고, 일반화된 표현이라고 할 수 있다. 또한 Asymmetric과의 차이는 predictor의 유무이다. Unigrad는 predictor를 사용했다고 한다.(허나 predictor는 negative를 사용하지 않고 collapse를 막기 위한 대책으로 알고있다. negative를 사용하는 ungraid는 당연히 predictor가 필요하지 않은것 아닌가 하는 의문이 있다.) 마지막으로 Feature Decorrelation와의 관계는 (명시적으로 적혀있지는 않지만) cross-correlation과 같은 feature decorrelation의 optimization 함수를 사용하지 않아도 유사한 방향으로 학습되었다고 주장했다.
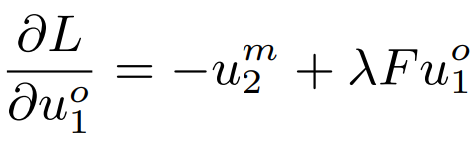
Proof
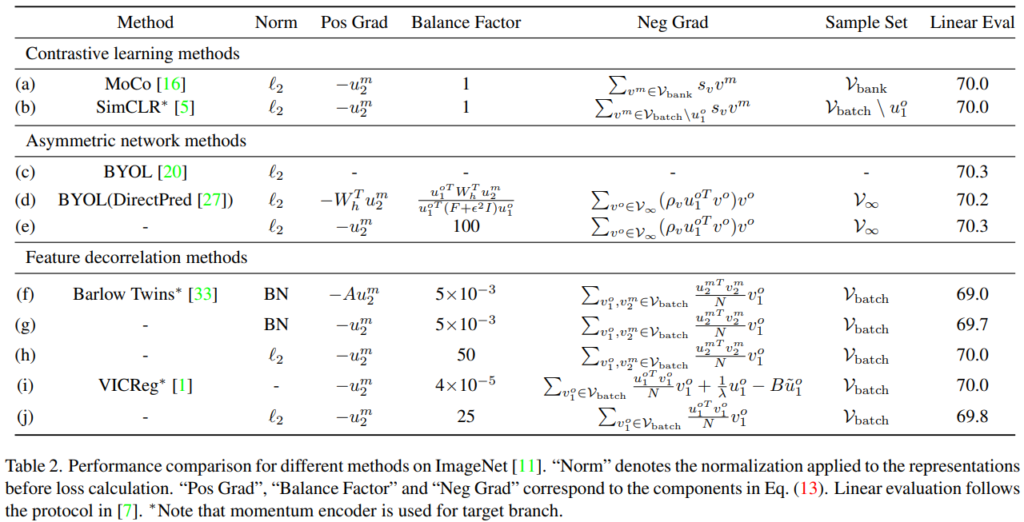
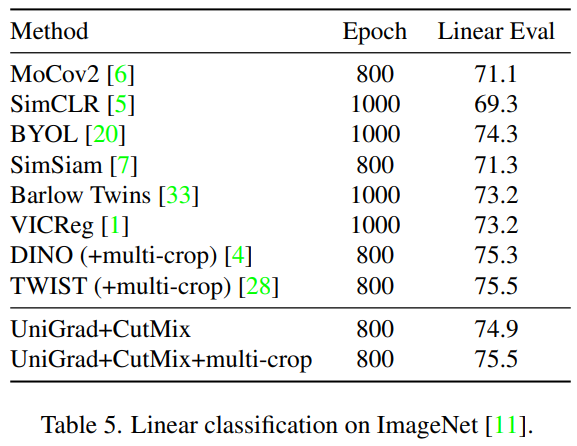
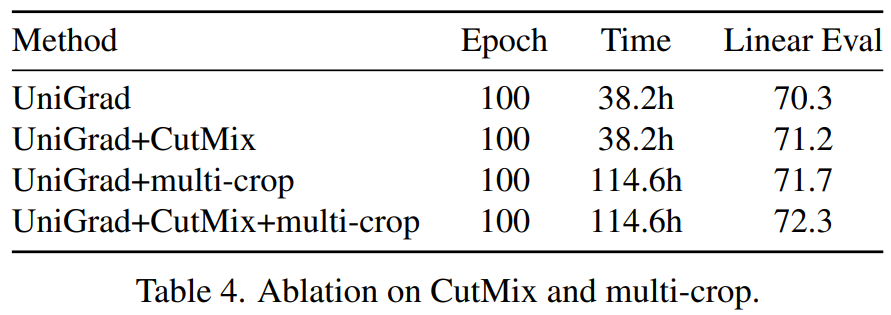
다음은 imagenet데이터에 대한 모델의 표현력을 입증하는 linear classification 실험이다. 동일한(혹은 유사한) 학습 epoch 기준으로 높거나 같은 성능을 보여 모델의 표현력을 입증하였다. 또한 multi-view를 생성할 때 사용한 augmentation option(cutmix or cutmix+multi-crop)에 따른 리포팅을 제공한다. 이러한 조합은 [표3]의 ablation study 실험에 따라 선정된 듯 한데, multi-crop에 context 손실이라는 변수(앞선 소개 논문 LEWEL에서 해결하고자 했던 문제)가 있음에도 명확한 성능향상을 보이는것이 흥미로웠다.
좋은 리뷰 감사합니다.
오… 결국 한 시대를 풍미했던 self learning 의 3대장 (MoCo, BYOL, Barlow Twins)를 합친 것인 것 같네요… 혹시 저자가 왜 Gradient에 관심을 가지게 되었는지 어떤 문제점이 있었는지, 그리고 그 문제점은 어떻게 밝혀냈는지 얘기를 하나요? 이 질문을 하는 이유가… 다름이 아닌 저희가 저번에 얘기했던 논문과 내용은 다르지 Contribution으로 가져가려고 한 부분이 비슷한 것 같아서요. 새로운 프레임 워크 제안, 그리고 그로 인해 파생된 문제를 Gradient로 풀어냈다 정도로 ..? 참고하면 꽤나 좋은 인사이트를 줄 수 있지 않을까 싶네요. 추가로 질문드리고 싶은 것은 BYOL과 MoCo는 Negative 를 사용하느냐 사용하지 않느냐에서 큰 차이가 있는데 이걸 어떻게 합친거죠 …? 저자가 말한 다른 것도 아닌 이 세 가지 연구를 합친 이유가 있을까요? 감사합니다