오늘도 비디오의 Weakly-supervised Temporal Action Localization (WTAL) task에 관한 논문입니다. 2021년도 ACM MM에 게재된 ‘Cross-modal Consensus Network for Weakly Supervised Temporal Action Localization’ (CO2-Net) 에 대해 정리해보겠습니다.
WTAL은 video-level label 정보만을 이용하 Temporal action localization task를 수행하게 됩니다.

바로 논문으로 들어가겠습니다.
1. Introduction
많은 연구에서 원래의 RGB 프레임과 더불어 Optical flow가 사용됩니다. 특히 시간 축에 따라 변화하는 영상을 다룰 때 많이 사용되는 것으로 알고 있는데, 비디오에서도 마찬가지로 연속적이고 많은 움직임들이 나타나기 때문에 optical flow가 담고 있는 motion 정보를 활용합니다.
기존 연구들이 WTAL task를 수행할 때 raw video를 어떻게 embedding 하는지부터 알아보겠습니다. 물론 방법론마다 차이가 있겠지만, 대부분의 방식은 아래와 같습니다.
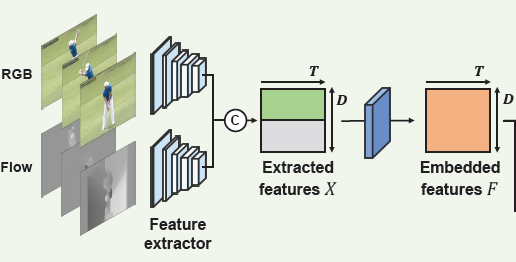
먼저 raw video를 겹치지 않는 16 frame 단위의 segment로 쪼갭니다. 비디오마다 길이(전체 프레임 개수)가 다르기 때문에 고정된 T개의 segment만을 샘플링 한 뒤, backbone network (사전 학습된 I3D 등)에 태워 RGB feature와 Optical flow feature를 얻습니다. 그 다음부터는 RGB feature와 Optical flow feature를 concat 한 후 다시 한 번 Convoluition layer를 거친 Embedded feature로부터 시작합니다.
이 과정 속에서 저자가 짚은 두 가지 포인트가 있습니다.
- Backbone network (I3D)는 WTAL이 아닌 Trimmed Action Classification task dataset으로 사전학습 되어있다.
- 비디오로부터 추출한 RGB feature와 Optical flow feature를 단순히 concat 해서 사용한다.
Trimmed Action Classification (TAC) task는 잘 가공된 video를 보고 어떤 action인지 만을 분류합니다. 잘 가공되었다는 것은 비디오 내에 action과 background가 번갈아 나타나지 않고 action만 온전히 존재한다는 의미입니다.
하지만 우리가 수행하는 WTAL은 한 단계 더 나아가 action을 찾아내기까지 해야하므로 둘의 결이 다르다고 볼 수 있습니다. 아무래도 잘 가공된 비디오만으로 학습하였다면 background를 본적이 없으므로, temporal 한 정보를 상대적으로 덜 담고 있을 수 밖에 없겠죠. 이렇게 TAC dataset으로 사전학습된 모델로부터 feature를 뽑아 localization을 수행하게되는 상황을 ‘task-irrelevant information redundancy’라고 정의합니다.
제가 예전에 작성한 리뷰 중 [ICCV 2021 workshop] TSP: Temporally-Sensitive Pretraining of Video Encoders for Localization Tasks 에서도 마찬가지로 TAC task로 사전학습된 backbone network의 문제성을 지적하였었습니다.
이러한 맥락 속에서 TSP는 TAL에 맞게 temporally-sensitive한 feature를 새로 뽑는 방식(finetuning the feature extractor)을 제안하였다면 여기서는 그보다 이미 얻은 feature를 개선(re-calibrate)해서 사용하는 방식을 제안합니다.
어떤 방식으로 redundancy를 해결하는지 간단하게 소개하고, 방법론으로 넘어가겠습니다.
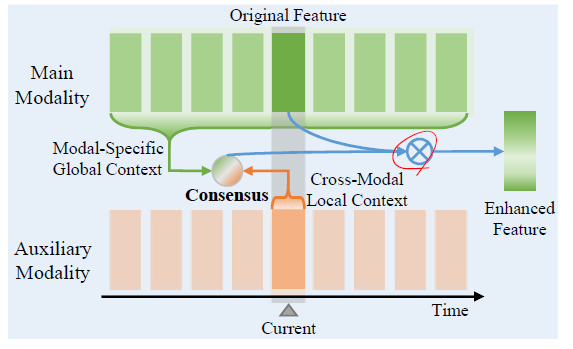
RGB는 공간 면에서 appearance 정보를 담고 있고, flow는 시간 측면에서 motion 정보를 담고 있다고 볼 수 있습니다. 저자는 redundancy를 걸러내기 위해 RGB와 flow 각 모달이, 이처럼 하나의 데이터를 서로 다른 관점으로 보고 있다는 점에 주목합니다. Cross-modal Consensus Module(CCM) 2개를 사용하여, RGB feature와 flow feature가 각각 정제되도록 모델을 설계합니다.
2. Method
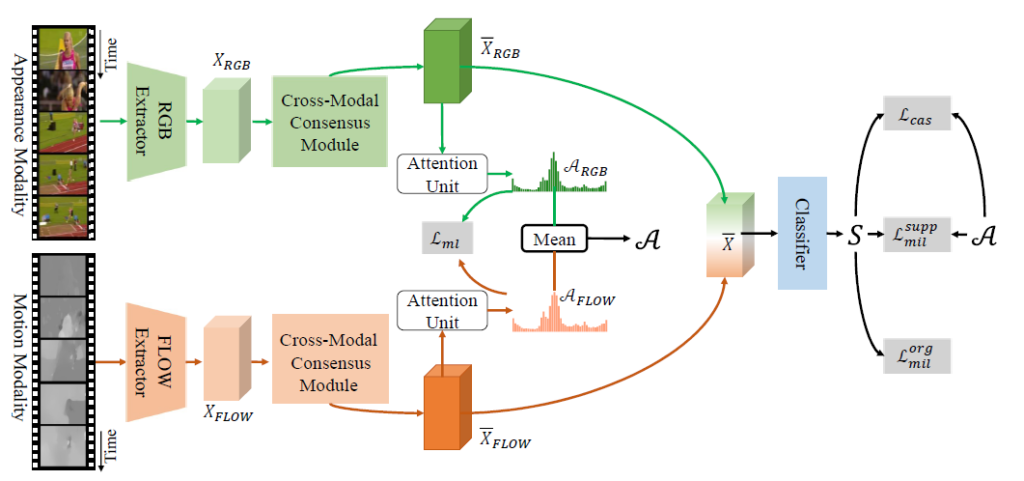
2.1 Pipeline
Feature Extraction
먼저 CO2-Net에서 이미 학습된 feature extractor는 건드리지 않기 때문에, I3D로부터 RGB feature X_{RGB}와 flow feature X_{FLOW}를 뽑는 과정까지는 위에서 설명한 다른 방법론들의 feature extraction 과정과 똑같습니다.
2.2 Cross-modal Consensus Module
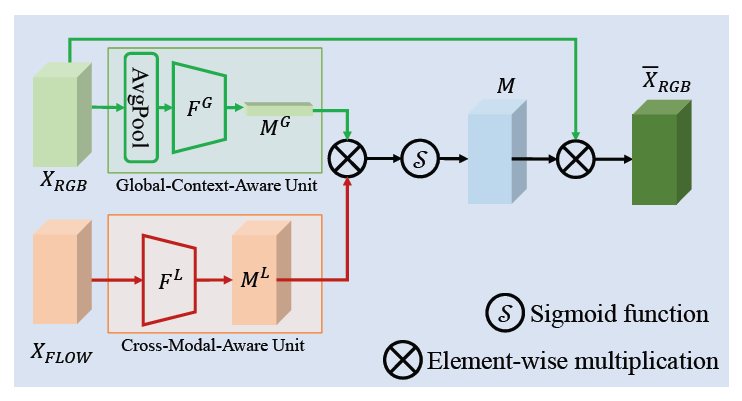
CCM은 본격적으로 X_{RGB}와 X_{FLOW}에서 redundant 정보를 갖는 부분을 찾아내고, re-calibrate 하는 역할을 수행합니다.
RGB를 메인, FLOW를 보조로 갖는 CCM 하나, FLOW를 메인, RGB를 보조로 갖는 CCM 하나로 총 2개의 CCM이 존재하고 각 CCM은 global-context-aware unit과 cross-modal-aware unit으로 이루어져 있습니다. 설명은 RGB를 메인으로 하고, FLOW를 보조로 두는 CCM을 기준으로 하겠습니다.
Global context aware unit
global context aware unit에서, main modal인 RGB feature의 global context를 추출합니다. 기존 RGB feature X_{RGB} \in{} \mathbb{R}^{T \times{} D}에 대해 시간 축으로 average pooling하여 하나의 video-level feature X_{g} \in{} \mathbb{R}^{D}를 얻습니다. 이후 X_{g}를 convolution layer에 태워 RGB에 대한 global descriptor M^{g} \in{} \mathbb{R}^{D}를 추출합니다.
\psi{}는 average pooling, F^{G}는 convolution 연산을 의미합니다.
X_{g} = \psi{}(X_{RGB})
M^{G} = F^{G}(X_{g})
Cross modal aware unit
main modal의 feature를 좀 더 강화하기 위해, 보조 modal의 정보도 함께 사용해줍니다. 앞 unit에서 main modal의 global 정보를 가져갔다면, 여기서는 보조 modal의 지역적인 정보를 추출합니다. modal은 다르지만 local context와 global context 정보를 합쳐 이용하는 것이 TSP와 비슷하네요. flow feature X_{FLOW}를 convolution layer에 태워 flow local feature M^{L}를 얻습니다.
M^{L} = F^{L}(X_{FLOW})
이제, M^{G}와 M^{L}을 element-wise 곱 연산을 수행하여 feature recalibration에 사용할 channel-wise descriptor M을 만들어줍니다. 그리고 M에 sigmoid를 태워 기존 RGB feature X_{RGB}에 다시 element-wise 곱을 수행합니다. M^{G}와 M^{L}가 각각 트랜스포머의 Q, K 역할과 유사하다는 것을 저자도 밝히고 있습니다.
M = M^{G} \otimes{} M^{L}
\bar{X}_{RGB} = \sigma{}(M) \otimes{} X_{RGB}
이렇게 얻은 \bar{X}_{RGB}가 개선된 RGB feature에 해당합니다. 다른 CCM에서도 main modal을 flow로, 보조 modal을 RGB로 두고 같은 과정을 거쳐 \bar{X}_{FLOW}를 얻을 수 있겠죠.
2.3 Dual Modal-specific Attention Units
이제 개선된 feature를 얻었으니 이를 task에 사용해야합니다. \bar{X}_{RGB}를 3개의 convolution layer에 태워 클래스에 관계 없이 action일 확률에 해당하는 actionness score \mathcal{A}_{RGB}를 추출합니다. \bar{X}_{FLOW}로 \mathcal{A}_{FLOW}도 추출하게됩니다. 그리고 두 modal의 특성을 모두 갖는 \mathcal{A}는 단순히 둘의 평균으로 만들어냅니다.
\mathcal{A}_{RGB} = F^{A}_{RGB}(\bar{X}_{RGB})
\mathcal{A}_{FLOW} = F^{A}_{FLOW}(\bar{X}_{FLOW})
\mathcal{A} = \frac{\mathcal{A}_{RGB} + \mathcal{A}_{FLOW}}{2}
그리고 두 feature \bar{X}_{RGB}, \bar{X}_{FLOW}를 단순 concat 후 convolution layer에 태워 T-CAM \mathcal{S} \in{} /mathbb{R}^{T \times{} (C+1)}을 만들어냅니다. C+1번째 클래스는 background를 의미합니다.
2.4 Optimizing Process
이전 과정까지 수행했을 때 얻어낸 것들이 무엇인지 한 번 정리하고, 어떤 loss들로 학습하는지 살펴보겠습니다.
- original feature X_{RGB}, X_{FLOW}
- redundancy filtered feature \bar{X}_{RGB}, \bar{X}_{FLOW}
- actionness attention \mathcal{A}_{RGB}, \mathcal{A}_{FLOW}, \mathcal{A}
- Class Activation Sequence \mathcal{S}
이제 학습에 사용되는 loss들을 살펴보겠습니다. 총 loss는 아래와 같습니다.
\mathcal{L} = \mathcal{L}_{mil} + \mathcal{L}_{cas} + \mathcal{L}_{ml} + \mathcal{L}_{oppo} + \mathcal{L}_{norm}
이 중 \mathcal{L}_{mil}, \mathcal{L}_{cas}, \mathcal{L}_{norm}은 다른 방법론들에서 흔히 사용되므로 간단하게만 설명하겠습니다.
\mathcal{L}_{mil}은 CAS에서 top-k 점수만을 평균내어 실제 video-level label과의 CrossEntropyLoss이고, 원래 CAS에 대해서 뿐만 아니라 attention을 곱해 background가 억제된 CAS에 대해서도 학습을 수행한다는 점만 추가됩니다.
\mathcal{L}_{cas}는 co-activity similarity loss로 점수가 높은 지역의 feature끼리 비슷해지도록 학습합니다.
\mathcal{L}_{norm}은 attention weight들을 sparse하게 만들어주기 위한 L1 loss에 해당합니다.
- \mathcal{L}_{ml}
목적은 두 attention weights \mathcal{A}_{RGB}와 \mathcal{A}_{FLOW}의 정합이 맞도록 둘을 서로 비슷하게 만들어주는 것입니다.
\mathcal{L}_{ml} = MSE(\mathcal{A}_{RGB}, \phi{}(\mathcal{A}_{FLOW})) + MSE(\mathcal{A}_{FLOW}, \phi{}(\mathcal{A}_{RGB}))
식에서 \phi{}는 detach()의 의미라고 보시면 됩니다. 각 attention weights가 상대 modal의 pseudo label이 되어 둘이 유사해지도록 학습하는 것입니다. 거리 측정 방식으로 MSE를 사용한 이유는 다른 거리 측정 함수들에 비해 가장 최적화가 잘되어서라고 이후 실험 파트에서 밝히고 있습니다.
- \mathcal{L}_{oppo}
우리가 갖고 있는 \mathcal{A}_{RGB}, \mathcal{A}_{FLOW}, \mathcal{A}는 어떤 클래스이든 관계 없이 일단 action일 확률 분포인데, 이는 CAS \mathcal{S}에서 background일 확률을 나타내는 분포와 반대로 나타나야 합니다. 그래서 다른 loss에 의해 한 쪽이 커진다면 반대 쪽은 작아지도록 학습하는, 둘의 총합이 1이 되도록 학습하는 loss를 설계합니다.
\mathcal{L}_{oppo} = \frac{1}{3}\left(|\mathcal{A}_{RGB}+s_{c+1}-1| + |\mathcal{A}_{FLOW}+s_{c+1}-1| + |\mathcal{A}+s_{c+1}-1|\right)
2.5 Inference
Inference 시에는 CAS에 대해 top-k mean pooling을 통해 비디오에 존재하는 action을 추려냅니다.
추려진 action에 대해 다시 CAS로 돌아가 attention weights \mathcal{A}를 곱해주어 background에 해당하는 segment들은 모두 지워줍니다.
이후 thresholding하여 전체 비디오에서 action이 될만한 구간들을 만들어냅니다. outer-inner contrast score를 계산하여 구간의 점수를 매기고, 이를 바탕으로 soft-NMS를 적용하여 최종 proposal을 예측합니다.
3. Experiments
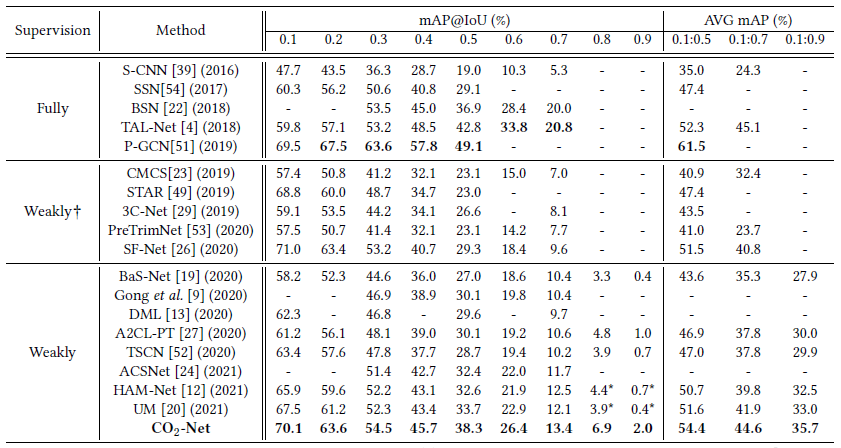
THUMOS dataset에 대한 벤치마크 성능입니다. 당시 SOTA를 달성하고 있고 CO2-Net은 THUMOS 기준 22년에 나온 일부 방법론들보다도 조금 높은 성능을 보이는 방법론에 해당합니다.
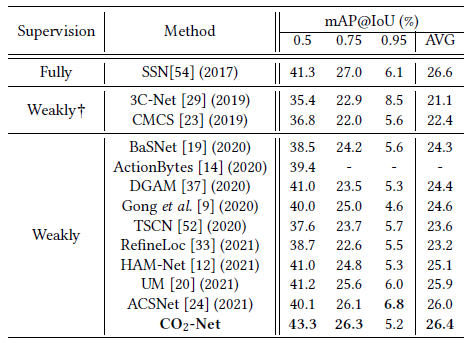
ActivityNet v1.2 dataset에 대한 성능이고 마찬가지로 평균 mAP 기준 SOTA를 달성하였었습니다. 높은 IoU 기준으로는 다른 방법론들보다 성능이 꽤 떨어지긴 하지만 낮은 IoU 기준에서는 높은 성능을 보여주네요. 저자가 따로 IoU에 따른 성능 차이를 분석하고 있지는 않고, 성능 향상 폭이 THUMOS보다 낮은 것이 ActivityNet annotation의 coarse함 때문이라고 이야기하였습니다.
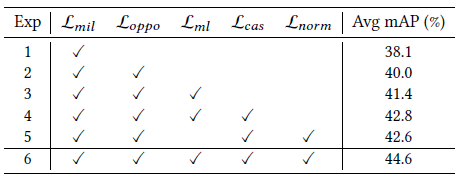
loss 구성 별 ablation 실험 결과를 보여주고 있습니다. 우선 모든 loss가 성능 향상에 기여하고 있는 것을 볼 수 있고, 특히 각 모달이 서로의 pseudo label로서의 역할을 하여 비슷해지도록 학습하는 \mathcal{L}_{ml}이 큰 역할을 한 것을 알 수 있었습니다.
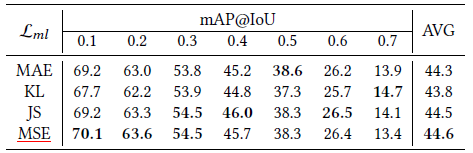
다음은 \mathcal{L}_{ml} 계산 시 어떤 거리 함수를 사용했는지에 따른 성능 결과입니다. 실험적으로 MSE가 가장 좋은 성능을 보였다고 하네요. 계속되는 실험에서 분석보다는 단순히 이게 성능이 좋았다, 안정적이었다, 적합했다, 등의 평가만 나와 있어 조금 아쉽습니다.

CO2-Net의 구조에서 CCM의 역할에 대한 실험 결과입니다. 기존 연구들에서는 단순히 두 modal의 feature를 concat하여 사용하는 방식이 주를 이루었는데, 이에 비해 제안한 CCM을 사용하는 경우 THUMOS 기준 4.9%의 성능 향상을 보였다고 합니다.
Conclusion
다른 연구들에서는 주목하지 않았던 부분에 대한 문제를 정의하여 성능을 많이 올렸다는 점이 인상깊었습니다. 처음에는 방법론이 어떻게 redundancy를 제거하는건지에 대해 의문이 들었지만 읽다보니 아마도 그냥 학습을 통해 feature를 개선 시킴에 따라 이러한 효과가 생긴다고 이야기 할 수 있는 것이 아닌가.. 하고 이해하게 되었습니다.
조금 아쉬운 점이 있다면, 두 modal이 한 비디오에 대해 서로 다른 특성을 잡아내고 있다는 점을 이용해 각 CCM을 modal의 특성에 맞추어 서로 다른 구조로 설계했으면 어땠을까 하는 생각이 듭니다. 이 부분에 대해서는 제가 잘 이해하지 못한 것일 수도 있으니 다른 의견이 있으신 분은 알려주시면 감사하겠습니다.
이상으로 리뷰 마치겠습니다.
처음에 task-irrelevant information redundancy를 제거할 수 있는 framework라 소개 돼서 조금 흥미를 가지고 읽어봤지만 뭔가 조금 부족한 느낌이 들어보이네요.
Classfication으로 사전학습 됐기 때문에 Localization에 맞지 않는다 라는 주장은 자명하게 들리지만 결국 본 논문의 Loss도 Classification으로 학습이 되는 것 같아 근본적인 해결책이 아니라는 느낌이 드네요.
저도 전부터 W-TAL을 수행할 때 action-domain에서는 flow feature를 단순히 concat 해서 사용하는 것이 아니라 따로 처리를 해줘야한다고 생각하고 있었는데 비슷한 컨셉의 논문이 있었네요.
리뷰를 잘 작성해주셔서 별다른 궁금한 부분은 없습니다. 저도 다음에 한번 읽어봐야겠네요.