시각 정보와 inertial 정보를 결합하여 ego-motion을 추적하여 이동 궤적을 알아내는 VIO task에는 카메라와 IMU 센서를 서로 상호보완하여 두 정보를 최대한 활용하는 것이 여전히 문제로 남아있습니다. 이 논문은 이러한 이슈에 대한 연구로, 새로운 attention guided 방식을 제안하였습니다.
해당 논문은 1차원 inertial encoder를 이용하여 IMU 정보를 독특한 방식으로 conat하여 활용함으로써 inertial 정보를 빠르고 효율적으로 추출합니다. 또한 inconsistency 문제를 해결하기 위해 cross-domain channel attention block을 통해 adaptive 하게 두 feature(visual 정보와 inertial 정보)를 결합하기 위한 연구를 수행하고 실험으로 증명하였다고 합니다.
Introduction
VIO는 visual feature 추출, inertial feature 추출, 두 feature 융합 3가지에 대한 문제가 있었다고 합니다. 첫번째 visual feature에 대한 문제는, VO 연구가 진행됨에 따라 CNN을 적용하는 방식으로 해결하여 만족할만한 정확도를 달성하였다고 합니다.
그러나 두번째 inertial feature 추출 방식은 연구가 적게 되기도 하였고, 6가지의 숫자로 구성된 정보는 적은 정보를 가지고 있으며, 일반적으로 많이 사용하는 LSTM기반의 방법론들은 낮은 효율과 부적확한 결과를 가져왔다고 합니다. 이를 해결하기 위해 저자들은 효율적으로 feature를 추출할 수 있도록 one-dimension inertial feature encoder를 설계하였다고 합니다.
마지막으로 feature를 융합하는 문제는 두 데이터 분포 간의 갭을 고려하지 않고 중요한 정보를 적절히 사용하지 못하는 방식으로 연구가 되어왔었고, 이를 해결하기 위해 저자들은 attention guided visual-inertial feature fusion 방식을 제안하였습니다.
contribution
- 빠르고 효율적인 inertial encoder
- fusion 단계에서 데이터 분포 사이의 불일치를 해결하기 위해 새로운 attention module 연구
- SOTA VIO 방식과 비교를 위한 다양한 실험과 경쟁력 있는 성능 달성
Method
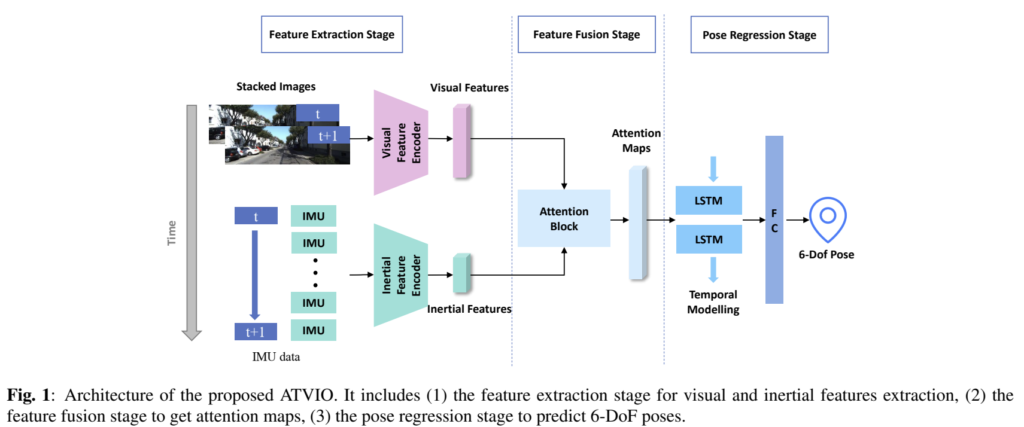
위의 그림은 논문에서 제안한 전체적인 ATVIO 프레임워크로 feature 추출, feature fusion, pose 추정 3가지 단계로 이루어져 있습니다.
1. Visual Feature Encoder
CNN을 이용한 시각 feature 추출 방식에서 높은 성능을 달성하였으나, 일반적으로 사용하는 VGG나 ResNet은 기하학적 정보를 포착하기 어렵다는 문제가 있다고 합니다. 따라서 VONAS-A라는 VIO를 위해 디자인 된 architecture search 방식을 사용하였다고 합니다.
2. Inertial Feature Encoder
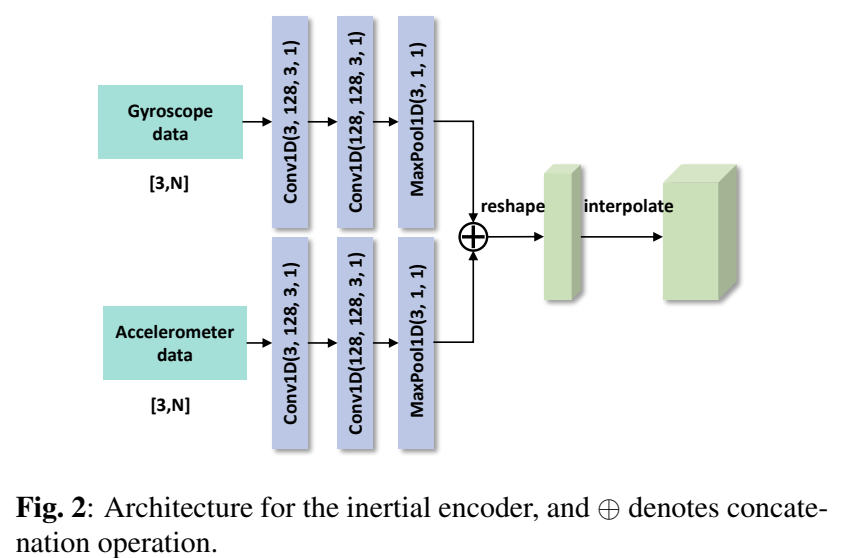
대부분의 기존 VIO들은 LSTM을 이용하여 IMU 데이터를 처리하였고, 이 방식은 시간이 다소 오래 걸렸습니다. 저자들은 훨씬 적은 파라미터를 이용하여 feature를 추출 할 수 있는 1D Convolution Neural Netork를 제안함으로써 이 문제를 해결하고자 하였고, 위의 그림2가 네트워크 구조에 해당합니다. 두 브랜치의 output을 concate하여 256×7 feature map을 만들고, visual feature와 동일한 width height를 만들기 위해 reshape(128x2x7)하고 interpolate를 하여 (128x4x13)의 inertial feature를 만들어줍니다.
3. Attention Guided Feature Fusion
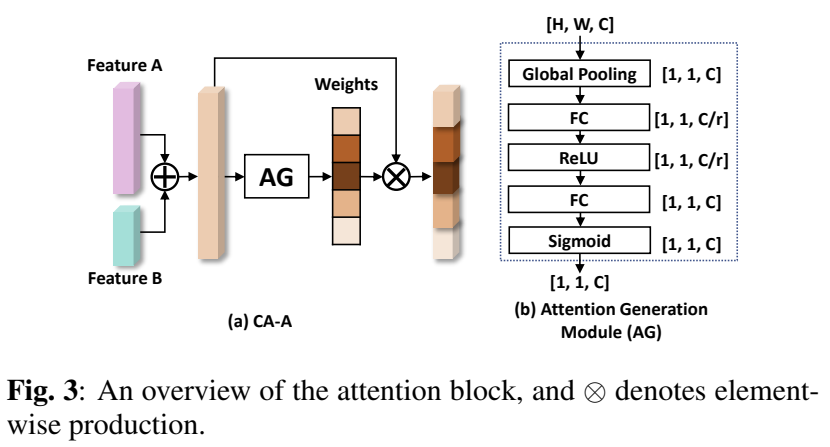
단순히 concat하는 방식은 다른 분포를 가진 두 데이터에 적절하지 않으므로 저자들은 cross-domain channel attention 구조를 디자인하였다고 합니다. CA-A~D 구조를 설계하였고 위의 그림3이 가장 좋은 성능을 보인 CA-A 구조입니다.(CA-B,CA-C,CA-D 구조는 ablation study에 추가로 설명합니다.)
두 입력 feature A(visual feature), B(inertial feature)는 크기는 동일하지만 서로 다른 채널 수를 가지고 있습니다.(A=[a_1,a_2,...,a_{C_1}], A=[a_1,a_2,...,a_{C_2}], C_1≠C_2 ) 제안된 attention module은 다음과 같이 작동합니다.
- A와 B를 concat하여 feature M = [m_1,m_2,...,m_C](C=C_1+C_2)를 얻습니다.
- Attention Generation 모듈(AG)에 넣어 채널의 가중치 값인 W를 구합니다.
- 가중치를 feature M에 할당하여 feature Y=[w_1m_1, w_2m_2,...,w_cm_c]를 구합니다.
AG 모듈은 채널의 가중치를 생성하는 부분으로, Squeeze-and-Extraction(SE)블록을 이용합니다. SE블록은 채널간의 상호의존성을 모델링하므로써 CA-A는 입력 feature의 상관 관계를 구축하고, 갭이 큰 feature간에는 적절한 가중치를 할당할 수 있도록 해준다고 합니다.
4. Pose Regression
LSTM은 연속성에 따라 모델링을 할수 있으므로 VIO서 사용됩니다. pose regression단계는 2개의 LSTM과 128개의 hidden state로 구성하였고, fully connected layer를 이용하여 인접한 두 프레임 간의 6-DoF의 상대 pose 정보를 구합니다.
이때 아래의 식 (1)로 정의되는 adaptive loss를 이용하여 모델을 학습한다고 합니다. (식 (1)은 <Jonathan T Barron, “A general and adaptive robust loss function,”>에서 제안된 loss라 합니다.)
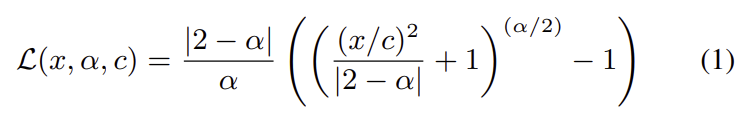
total loss는
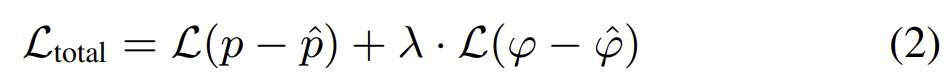
로, p는 translation, ϕ rotation(euler angle)를 나타냅니다.
Experimental Result
KITTI Odometry 데이터셋을 이용하여 실험을 진행하였다고 합니다. monocular image와 raw IMU 데이터를 이용하였고, 이때 IMU는 100Hz, 이미지는 10Hz로 촬영된 데이터입니다.
Comparison with SOTA approaches
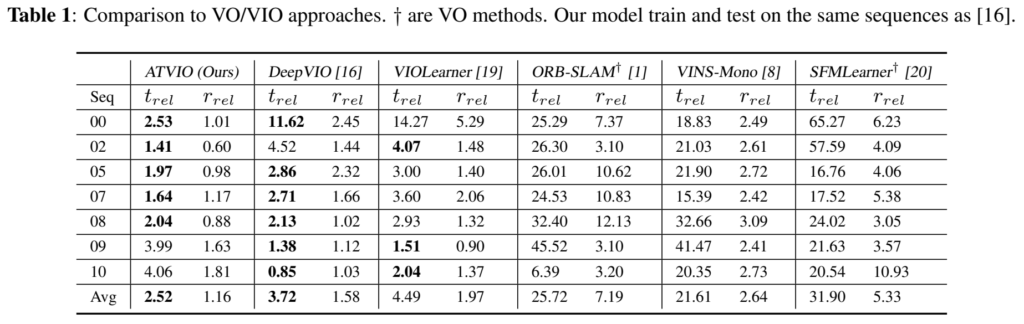
DeepVIO, VIOLearner(DeepVIO 이전의 학습기반 SOTA VIO), ORBSLAM(전통적인 VO 기법), VINS-Mono(전통적인 VIO 기법), SFMLearner와 비교하였고, 전통적인 방식들(ORB-SLAM,VINS-Mono)과 비교했을 때 딥러닝을 적용한 방법론들이 성능이 좋았고, 기존의 SOTA방식(DeepVIO, VIOLearner)와 비교했을 때 ATVIO가 평균적으로 좋은 성능을 달성한 것을 확인할 수 있습니다.
Ablation Study
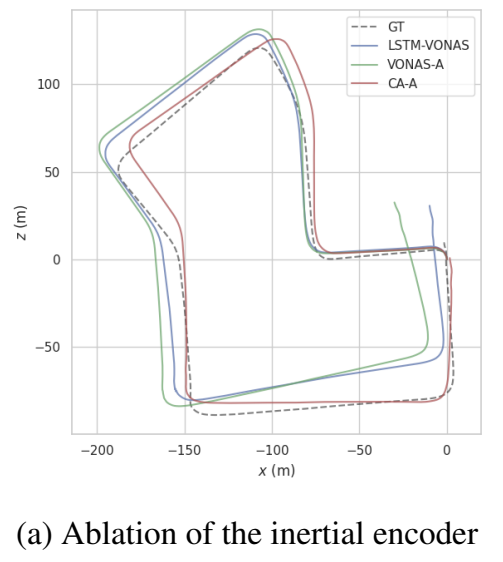
1. Inertial encoder
encoder 부분을 2-layer LSTM으로 변경한 경우(LSTM-VONAS)와 inertial encoder를 제거한 경우(VONAS-A)에 대한 실험 결과로, 논문의 방식(CA-A)가 가장 좋은 성능을 나타내었고, 시간 측면에서도 제안한 방식은 0.11MB, LSTM-based encoder는 2.54MB로 효율성을 확인할 수 있었다고 합니다.
2. Attention module
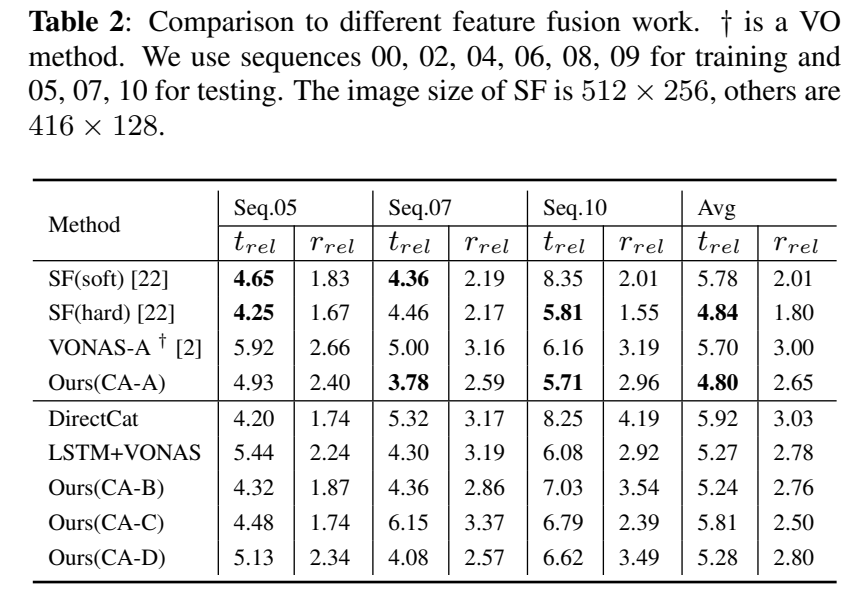
SelectiveFusion(SF)방식과 비교하였을 때 translation에서 조금 더 좋은 성능을 보이는 것을 확인할 수 있었다고 합니다.
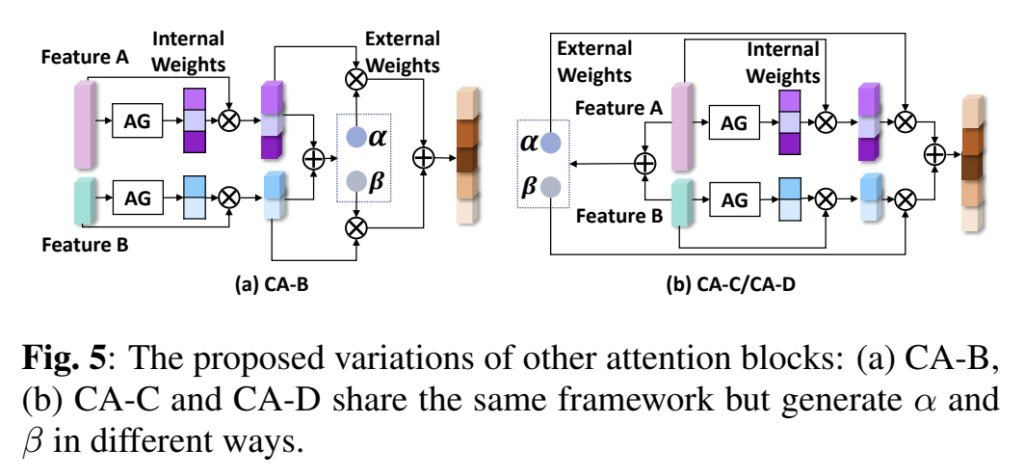
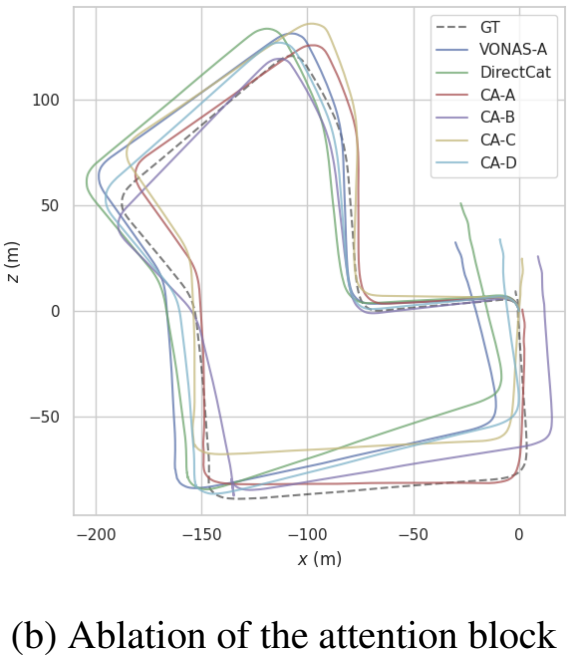
시각 feature와 inertial feature의 잠재적 관계를 확인하기 위해 위의 그림5와 같이 CA-B~CA-D를 구성하여 실험을 하였다고 합니다. CA-B는 각 feature마다 internal 가중치를 구하여 feature를 변형한 후, 두 attention map을 이용하여 external 가중치를 구해 fusion을 하는 방식입니다. CA-C와 B는 두 feature를 이용하여 inter 가중치와 external 가중치를 만들고, 이를 이용하여 fusion을 수행합니다.(정리하자면 B와 C/D의 차이는 external 가중치를 만들 때, 바로 feature를 이용하느냐, 가중치로 변형된 값을 이용하느냐의 차이라 생각하시면 됩니다.) 이때 -C와 -D는 AG가 {CNN/Pooling}, {Pooling FC}라는 차이가 있다고 합니다. 이에대한 실험 결과도 위의 표2에 나타나 있으며, 아래의그림이 경로를 시각화 한 결과입니다. 실험 결과를 통해 CA-A가 가장 좋은 성능을 가지는 것을 확인할 수 있고, 이는 채널별 feature를 연결하고, 두 feature를 global 방식으로 처리하기 때문에 inter/exter-class 관계를 동시에 학습하기 때문이라고 해석하였고, 이러한 실험을 통해 제안한 융합 방식이 효과적임을 보였습니다.
좋은 리뷰 감사합니다.
우선… inertial feature가 무엇인지 추가 설명을 요청합니다..허허 제가 잘 몰라서요.. 허허
그런데 LSTM이 오래걸려서 inertial feature을 추출할 때 사용하지 않지만… pose estimation에서는 여전히 사용하는 건가요? 그럼 동일한 문제점이 pose estimation에서는 발생하지 않는건가요?
이건 저희 음성인식 과제로 확장하여 생각해볼 수 있는 질문일 것 같은데요. 혹시 inertial feature를 추출하는 것에 있어서 기존 LSTM 과 1D CNN을 비교실험한것이 있을까요? 그리고 그에 대한 장단과 같은 분석은 없을가요?
생각보다 질문이 많네요,.. 허허 리뷰 잘 읽었습니다