Here! (용어가 익숙하지 않으신 분은 overview 먼저 읽으시는 것을 추천드립니다.)
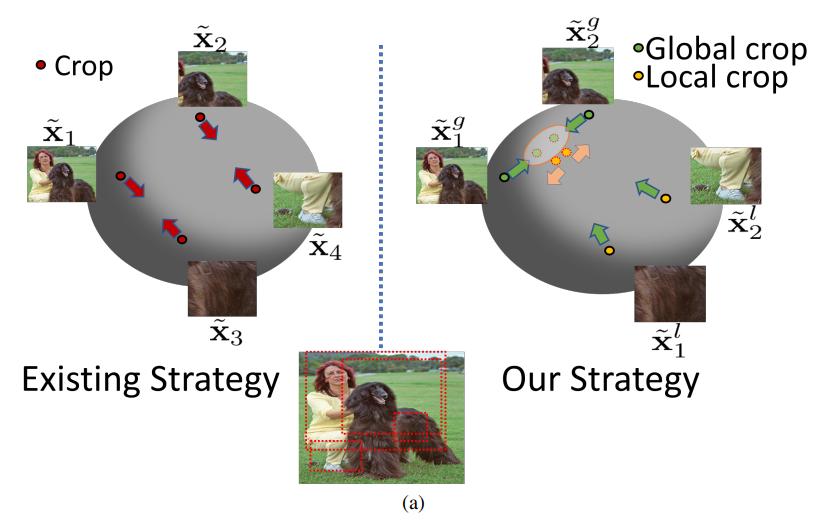
본 논문은 multi-view 기반의 self-supervised learning 연구에서 많은 세종 rcv의 연구원들이 의문을 가졌던, “consistency regularization기반의 학습에서 mulit view 생성을 위해 random crop augmentation 적용 시 share object, share context가 제거, 손상되면 어떡하죠?” 라는 질문을 해결하기 위한 연구 중 하나입니다. fig1이 해당 논문의 전략을 잘 보여주는데요, 기존 방법론은 하나의 이미지 x에 대해 random crop을 포함한augmentation T1, T2를 적용해 새로운 view인 T1(x), T2(x)를 생성하고, 두 인스턴스 사이의 거리가 가까워지도록 학습을 하였습니다. 제안하는 전략은 이미지 전체 정보를 포함할 수 있는 global crop과 비교적 좁은 영역을 대상으로하는 local crop을 나눈 후, local crop의 결과물들이 global crop과 가까워지도록 학습합니다. 이를 통해 각 이미지가 하나의 cluster에 뭉치는 것 처럼 학습을 하게 되어, 기존 방법론보다 조금 더 깊은 의미(단순 두 인스턴스(T1(x), T2(x))가 유사해지는것이 아닌, 이미지x라는 정보끼리 유사해지도록)의 유사성을 학습할 수 있게 됩니다.
Overview
self-supervised learning 은 label 없이 학습을 하는 unsupervised learning의 일종입니다. 최근의 많은 해당 분야의 연구들은 데이터 x에 image translation을 적용시 context는 변하지 않는다(view-invariant)는 점을 이용하여, 이미지에 translation을 적용해 새로운 view를 생성하고, 생성된 이미지의 의미하는 바가 유사하다는 점을 이용하여 학습을 진행합니다. translation에는 다양한 data augmentaiton이 적용될 수 있는데, Color shifting, Roatation, Gaussian Blur등 인공지능 모델의 학습시 적용하는 다양한 변환방법 뿐만 아니라, CTAugment, RandAugment과 같은 강한 변형 방법도 hard translation으로 사용되곤 합니다. 대표적인 translation 방법 중 하나가 random cropping 인데요, 이는 영상의 일부 정보를 손실하기 때문에 종종 이미지의 대상 object에 손상을 가하기도 합니다. x이미지에서 강아지라는 context를 공유할것이라고 예측되는 두 translated image T1, T2에서 random crop으로 인해 어떤 이미지는 실제로 강아지를 포함하고 있지 않을 수 있다는 것이지요. 여기서 T1과 T2가 확실히 공유하는것은 x의 일부 정보를 가졌다는 점 입니다. 이 정보를 이용하여, x를 하나의 cluster처럼 작용하도록 하는것이 제안하는 방법론 Local and Global crops(LoGo)입니다.
Detail
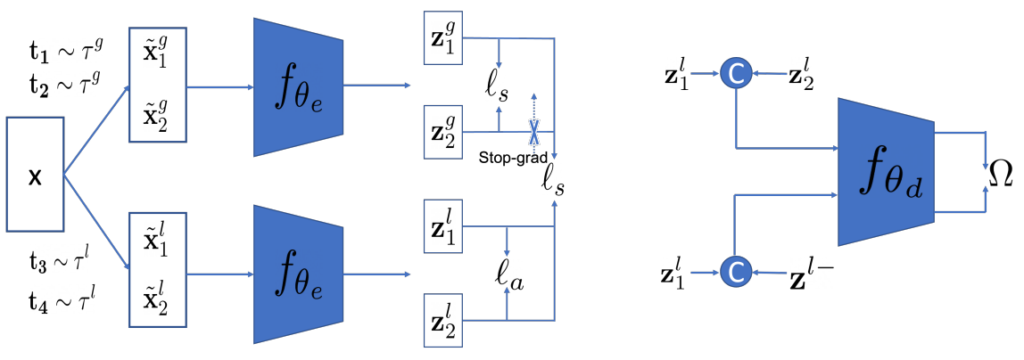
제안하는 방법론의 목적은 fig1의 예시와 같이 random crop으로 잘못된 방향으로 학습될 수 있는, 여러 대상이 포함된 복잡한 이미지에 대해서도 학습할 수 있도록 하는것 입니다. 이를 위해서 제안하는 방법론은 기존 연구의 큰 branch인 contrastive전략과 non-contrastive전략을 모두 사용하도록 framework를 설계했습니다. (contrastive전략: 대표적으로 InfoNCE같이 positive와 negative pair를 구성하는 학습방법론. negative pair로 모델이 모든 입력에 대해 동일한 출력을 갖도록 학습하는 mode collapse로 현상의 발생을 막았다/non-contrastive전략: BYOL과 같이 negative pair를 구성하지 않는 방법론. stop gradient등을 이용한 비대칭 구성으로 mode collapse 발생을 막았다.) fig2에서 볼 수 있듯이 l_s(similarity loss), l_a(proposed)의 두가지 loss 구성을 가지고 있으며, 입력이미지 x에 local crop을 적용하는 변환은 τ^l, global crop을 적용하는 변환은 τ^g라 한다. 이후, 각 변환을 통해 변형된 이미지는 x^l, x^g로 표기된것을 그림으로 확인할 수 있다.
- similarity loss(l_s)
positive pair간의 유사도를 최대화하기 위한 loss이다. 논문에서는 기존 self-supervised learning(SSL)분야에서 많이 쓰는 InfoNCE(batch내에서 자기자신 제외 모두 negative) loss와 cosine loss를 사용하였다. - proposed loss(l_a)
해당 loss는 논문에서 제안하는 loss로 global-to-global(l_gg), local-to-global(l_lg), local-to-local(l_ll) 세가지로 구성되었다(l_a=l_gg+l_lg+λl_ll, λ=0.0005 in MoCo, 0.0001 in SimSiam).
이때 각 loss는 다음과 같다. l_gg=E(l_s(z^g_1, z^g_2)) / l_ll=E(l_s(z^l_1, z^l_2)) / l_lg=E[Σi=1,2(l_s(z^l_i, stop(z^g_2)) + l_s(z^l_i, stop(z^g_2)))]
Proof
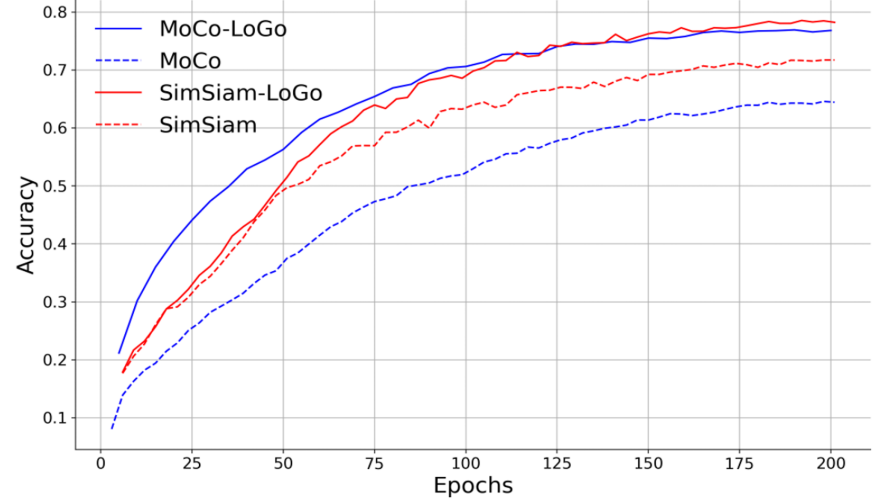
먼저 fig3을 통해 제안하는 LoGo가 기존 학습 방법론(MoCo, SimSiam)의 성능을 높일 수 있음을 확인할 수 있습니다. 이를통해 제안하는 방법론이 feature representation을 좋은 방향으로 이끄며, 기존 방법론에 적용될 수 있음을 알 수 있습니다.
다음으로 실험을 통해 기존방법론과 비교한 결과는 아래와 같습니다. (knn/linear clssification/transfer learning)
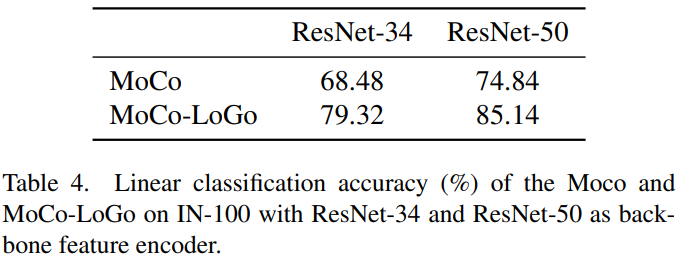
먼저 feature representation 능력 비교를 위한 knn과 linear layer를 적용한 classification 성능은 table 1,2,3와 같으며 ResNet-34와 ResNet-50으로 backbone을 확장해 비교한 실험은 table4와 같습니다.
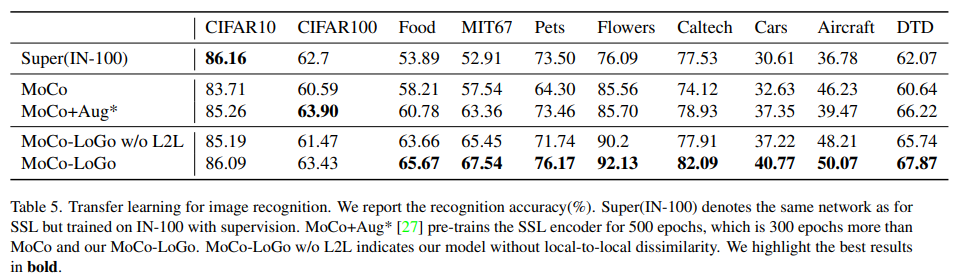
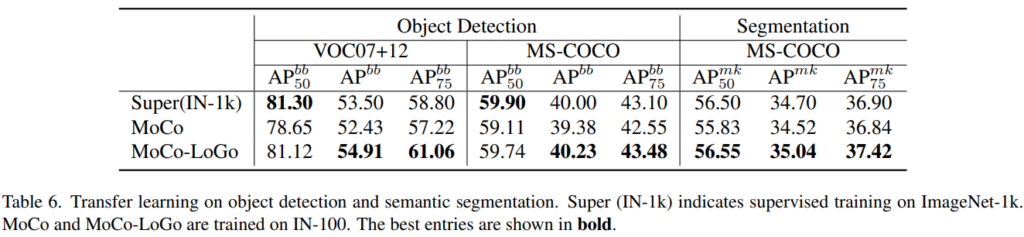
이후 dataset을 확장한 transfer learning은 table5, task를 object detection(VOC07+12/MS-COCO)과 segmentation(MS-COCO)으로 확장 적용한 성능은 table6과 같습니다.

self-learning에서 사용하는 아주 어마무시한 batch 사이즈같이… 물량빨(???) 로 밀어붙였을 때random-crop으로 인한 이슈가 해소되는 듯 보였으나.. 해당 논문에 의하면 랜덤 크롭으로 인한 차이가 있다고 증명하는 것 같습니다…
그런데 혹시 global crop과 local crop은 어떻게 구분되나요? global 한 건지 local 한건지 이것도 학습에 포함되나요? 그렇다면 crop 의 영역이 굉장히 다양해져서 학습 속도도 느려질 것 같은데, 해당 내용에 대하여 리포팅 할까요?
최근 비전 트랜스포머를 백본으로 하는 self-learning 에 의하면 random crop 말고도 color jitter 과 같이 원본을 손상시키는 augmentation 이 오히려 성능에 역효과를 준다고 리포팅한 것을 보았는데요. contrastive 기반의 self learning 에서도 혹 어떤 augmentation 방법이 성능을 저하시키는 것이 있는지 궁금해지네요. 좋은 리뷰 감사합니다.
local crop과 global crop 방식에 대한 설명을 제가 추가하지 못했네요 죄송합니다. 두 augmentation은 crop size에 대한 threshold로 구별되는데요 global crops의 lower bound를 의미하는 rg와, local crops의 upper bound를 의미하는 rl를 선언하여 구별하게 됩니다. 그런데 해당 하이퍼파라미터 정보가 아직 공개되지 않은 듯 합니다. 코드가 공개된다면 확인해보아야 할 듯 하네요
두번째에 대해서는 제가 접하지 못했던 정보네요..ㅎㅎ 논문 추천해주시면 열심히 읽어보겠습니다. 허허..