이번 X-Review도 비디오 분야의 Weakly-supervised Temporal Action Localization task에 관련된 논문을 소개해드리겠습니다. 올해 저널에 게재된 논문으로 해당 task 서베이 중 굉장히 높은 성능을 보여 읽게 되었습니다.

해당 저널에서 새로운 전체 프레임워크를 제안한것은 아니고, 기존 WTAL에서 좋은 성능을 내는 다른 프레임워크들에 덧붙여 사용할 수 있는 모듈을 제안하였습니다. 바로 논문으로 들어가보도록 하겠습니다.
1. Introduction
논문 제목에서도 알 수 있듯, 저자는 기존 방법론들이 간과하던 한 가지의 문제점을 지적합니다.
바로 비디오 내 action instance들이 서로 다른 움직임의 pace를 가질 수도 있다는 점입니다.
예를 들어 THUMOS14 데이터셋에는 스포츠, 운동 관련 비디오들이 속해있는데, 그 중에는 “창 던지기” action을 갖는 비디오가 존재합니다. 비디오 내에서 초반에는 선수가 정상적으로 창을 던지는 장면이 재생되고, 이후 다시 한 번 슬로우모션으로 하이라이트를 재생해주는 부분도 재생됩니다. 이 때 두 장면 모두 action에 속하지만 같은 클래스임에도 정상적인 속도로 재생되는 창 던지기와 다시 재생되는 슬로우 모션의 창 던지기는 서로 굉장히 다릅니다.

위 그림은 창 던지기 action을 포함하는 하나의 비디오에서 같은 sampling rate를 적용하여 가져온 프레임들입니다. 쉽게 생각해서 같은 비디오의 normal motion 부분에서 3초, slow motion 부분에서 3초씩에 속하는 프레임들을 가져왔다고 가정해보겠습니다. 윗 행의 normal motion은 창을 던지기 시작해 던진 후 넘어지는 장면까지 포함하는 반면, slow motion은 같은 시간이 흘렀음에도 창을 던지는 모습만이 나타납니다.
정확히 어떤 기준으로 측정한 것인지는 나와있지 않지만 위 그림과 같이 일반적인 motion 보다 느리게 action이 수행되는 부분을 slow motion이라고 정의하였을 때, 저자는 THUMOS14 데이터셋의 비디오 중 64% 이상, 전체 action instance 중 26.4% 이상이 slow motion을 포함하고 있다고 합니다.
기존 방법론들은 맨 처음 추출한 video feature를 시간 축에서 고정된 rate로만 샘플링하여 학습과 inference에 사용했기 때문에 slow motion에 잘 대응할 수 없었습니다. 그리고 톻상적으로 사용되는 rate는 normal motion에만 알맞도록 고려되어 설정된 것이기 때문에 slow motion에 제대로 대응할 수 없게 됩니다.
논문의 핵심 아이디어는 간단합니다. 모델이 slow motion 샘플을 충분히 학습함으로써 slow motion에도 잘 대응할 수 있도록 하자는 것입니다. 위와 같은 상황을 바탕으로 저자는 pace가 다른 “normal motion”과 “slow motion” 모두에 잘 대응할 수 있는 Slow-Motion Enhanced Network (SMEN)을 제안합니다.
2. Methodology
A. Notations and Preliminaries
기존 방법론들과 동일하게 untrimmed video V를 겹치지 않는 16개의 프레임 덩어리인 segment로 나눠줍니다. 총 T개의 segment가 존재하고 V = \{v_{i} \in{} \mathbb{R}^{16\times{}H\times{}W\times{}3}\}_{i=1}^{T}와 같이 표현할 수 있습니다.
이후 backbone network에 태워 d차원의 video representation X = [x_{1}, x_{2}, \ldots{}, x_{T}] \in{} \mathbb{R}^{T\times{}d}를 만들어 냅니다.
각 비디오의 GT label을 학습에 사용하는데, Y = [y_{1}, y_{2}, \ldots{}, y_{C}, y_{C+1}] \in{} \mathbb{R}^{T\times{}d}와 같이 나타낼 수 있고 C개의 클래스 존재 유무에 따라 y_{c}값은 0 또는 1로 들어갑니다. y_{C+1}은 비디오 내 background 여부를 의미합니다.
B. Review of ACM-NET
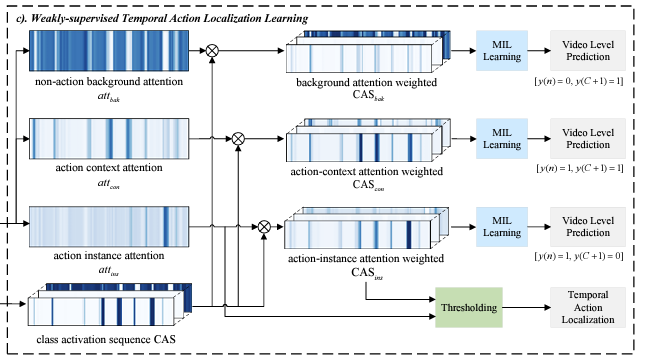
리뷰 처음에 SMEN은 다른 WTAL 방법론들에 추가로 적용할 수 있는 모듈이라고 말씀드렸었습니다. SMEN은 CAS generation backbone으로 기존 방법론인 ACM-NET을 선택하였기 때문에 ACM-NET에 대해 간단히 설명하고 넘어가겠습니다.
이미 ACM-NET을 아시거나 SMEN만의 방법론이 궁금하신 분들은 뒷 부분으로 넘어가셔도 좋을 것 같습니다. 또한 다른 backbone에 SMEN을 붙인 성능도 실험 부분에서 살펴볼 예정이니 참고해주시기 바랍니다.
ACM-NET에서는 맨 처음 video feature를 입력으로 받은 후 classification branch를 통해 initial CAS를 생성해냅니다. initial CAS는 3개의 branch로 이루어진 class-agnostic attention module로 들어갑니다. 총 3개의 branch에서 아래와 같은 3개의 attention weight를 뽑아냅니다.
- discriminating action instance
- discriminating action context
- discriminating non-action background
Attention weights group A = \{(attn_{ins}(t), attn_{con}(t), attn_{bac}(t))\}_{t=1}^{T} \in \mathbb{R}^{T \times{} 3}는 T개의 segment 각각이 action instance, action context, non-action background일 확률을 담고 있습니다.
맨 처음 video feature로부터 얻은 initial CAS와 3종류의 attention weights를 통해 3개의 CAS를 만들어낼 수 있습니다.
CAS_{*} = attn_{*} \times CAS
이 때 *은 앞서 구한 {ins, con, bac}에 해당합니다. 이후 3개의 video-level classification score를 각각 만들어냅니다. 이제 3개의 score 각각 학습할 라벨이 필요한데,
- Y_{ins} = [y_{c} = 1, y_{C+1} = 0]
- Y_{con} = [y_{c} = 1, y_{C+1} = 1]
- Y_{bac} = [y_{c} = 0, y_{C+1} = 1]
위와 같이 설정하여 각 branch의 특성에 맞게 학습을 진행합니다.
ACM-NET 방법론이 더 세부적으로 궁금하신 분은 [논문]을 확인하시면 좋을 것 같습니다.
C. Slow Motion Enhanced Network
본격적으로 SMEN의 방법론이 소개됩니다.
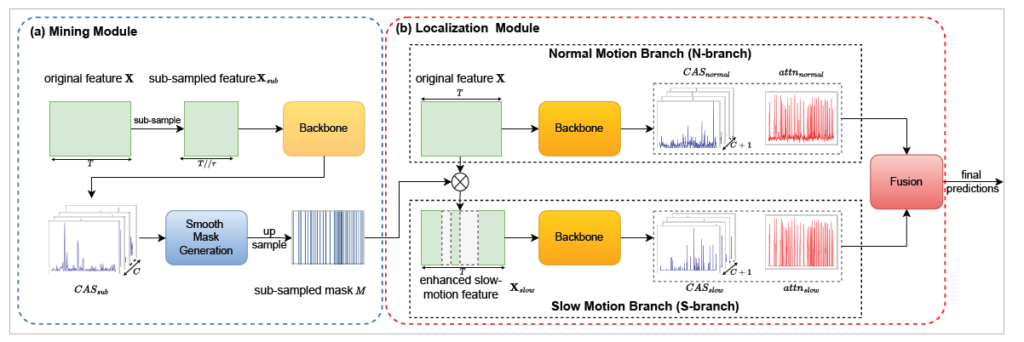
그림은 SMEN의 전체 구조를 나타냅니다. 크게 Mining module과 Localization module로 나눠 볼 수 있고 무언가 기존 feature를 sub-sampling 후 mask를 만들어내어 사용한다는 것 정도를 알 수 있겠습니다. ‘Backbone’에는 ACM-NET 또는 CAS를 만들어내는 기존 방법론들 무엇이든 들어올 수 있습니다.
Introduction에서 저자의 핵심 아이디어는 모델이 normal motion 뿐만 아니라 slow motion도 충분히 보고 학습함으로써 두 motion 모두에 대응할 수 있도록 만들어주는 것이었습니다. 그러기 위해서는 일단 video feature 중 slow motion과 관련 있는 부분이 어디인지 찾아내야 합니다. 해당 역할을 수행하는 Mining module 먼저 살펴보겠습니다.
Slow motion Mining
video feature에서 slow motion과 관련된 부분이 어디인지 찾아야 하는데, 그러기엔 slow motion action이 딱히 큰 특징도 없고 normal motion처럼 salient 한 것도 아니라는 점이 걸림돌이 됩니다. 이를 극복하기 위해 저자는 우선 normal video feature를 rate \tau{}로 sub-sampling 함으로써 slow motion action의 “actionness”를 올려줍니다. THUMOS 데이터셋에서 \tau{}는 4로 지정하였다고 하네요.
subsampling 된 video feature X_{sub} = \mathbb{R}^{(T//\tau{})\times{}d}가 되고 이는 speed-up video feature로도 볼 수 있습니다. 아까 위에서 본 창 던지기 action을 생각해 보았을 때 slow motion 장면을 subsampling 하여 다시 이어붙이면 마치 normal action처럼 상대적으로 normal motion에 가까운 pace를 갖게 될 것입니다. 이제 우리가 찾던 slow motion을 이 X_{sub}의 normal action으로 간주할 수 있게 된 것입니다.
이후에는 X_{sub}로부터 slow motion mask M을 만들어 slow motion feature X_{slow}를 만들어주어야 하는데, 마스크 M을 만들어내는 방법도 간단합니다.
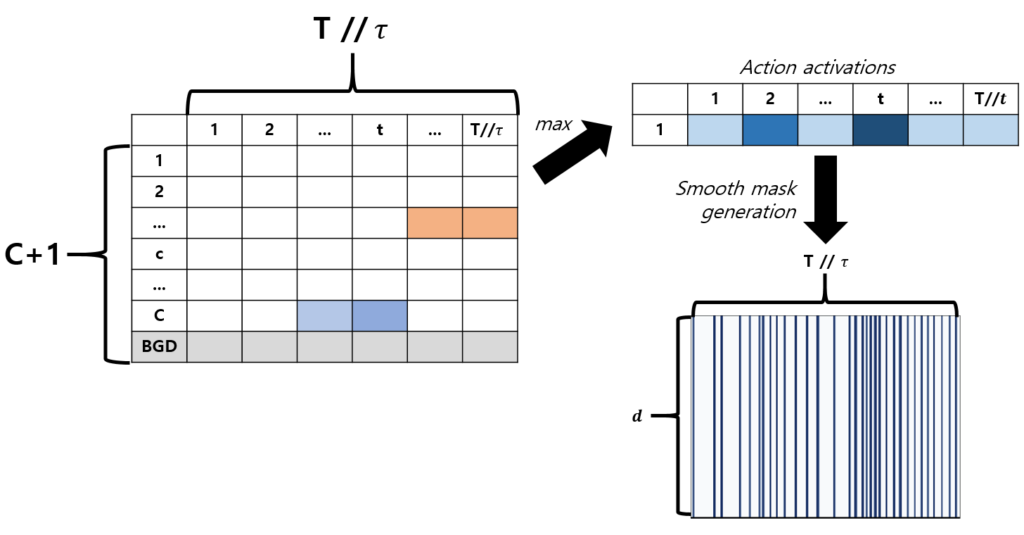
우선 X_{sub}를 ACM-NET에 태워 CAS_{sub}를 만들어내고, Smooth mask generation mechanism을 거칩니다.
Smooth mask generation 과정은 아래와 같습니다. CAS_{sub}에서 클래스에 관계 없이 한 segment 별 최대값을 action activation 값으로 가져오고, MinMax normalization을 수행해줍니다. 이후 그 값들을 d차원으로 펴 M^{norm}을 만들어냅니다.
M^{norm}에 Coefficient of Variation Smoothing 기법을 적용하여 M^{smooth}를 얻게 됩니다.
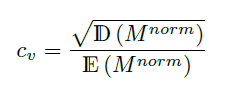
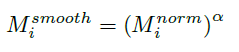
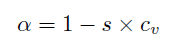
위 식에서 \mathbb{D}는 분산, \mathbb{E}는 평균, s는 scale factor를 의미합니다. CAS_{sub}로부터 얻은 마스크가 시간적으로 조금 더 잘 이어질 수 있도록 이러한 smoothing 과정을 거치면 thresholding 후에 보통 noise로 간주되는 짧은 segment들이 제거되는 효과를 얻을 수 있는 것으로 이해하였습니다.
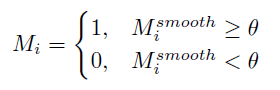
이후 thresholding을 거쳐 1, 0으로 이루어진 최종 마스크 M \in{} \mathbb{R}^{(T//\tau{}) \times d}을 얻게 됩니다. 실제 threshold는 0.4를 사용하였다고 하네요.
이제 feature에 마스크 M을 곱해주기만 하면 slow motion에 해당하는 feature만 남길 수 있게 됩니다.
Temporal Localization
앞서 Mining module을 통해 얻은 마스크 M을 original video feature X에 곱해 slow motion feature만 남은X_{slow}를 얻을 수 있습니다.
이후에는 Normal-branch와 Slow-branch로 나뉘는데 이들은 각각 X와 X_{slow}를 입력으로 받아 ACM-NET을 거칩니다. 각 branch에서 CAS_{normal}와 CAS_{slow}를 얻은 후 두 CAS에서 max 값만을 취해 최종 CAS를 만들어내어 localization을 수행합니다.
최종 CAS로부터 top-k pooling 후 action thresholding을 통해 localize 할 action class를 정하고, 다시 CAS로 돌아가 grouping을 통해 proposal을 만들어내는 형태입니다.
아무래도 다른 방법론에 붙이는 모듈이다보니 이 부분에서는 크게 설명할 것이 없네요.
Inference
Inference 시에 Mining module은 사용되지 않습니다. Localization module의 두 branch가 각 특성에 맞게 잘 학습되었다고 가정하고 original video feature X를 두 branch의 입력으로 줍니다. 이후에는 똑같이 max pooling을 통해 CAS를 합치고, proposal을 만들어내는 과정을 거쳐 이를 평가합니다.
Experiment
Comparison with the State-of-the-arts Methods
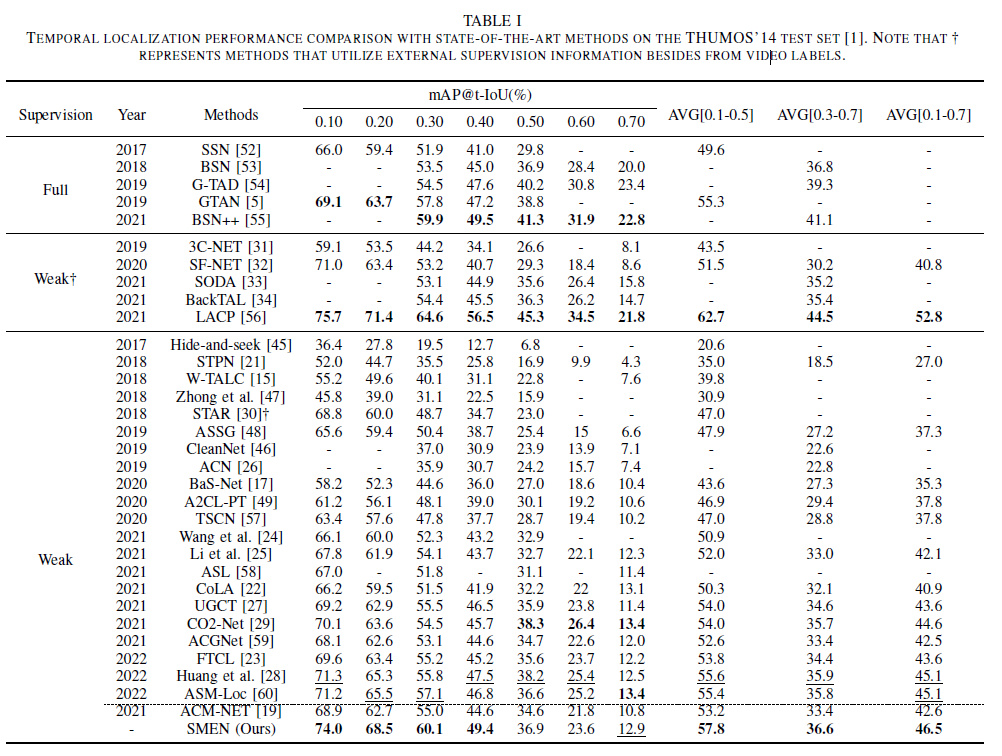
먼저 THUMOS14 데이터셋에 대한 벤치마크 성능입니다. ACM-NET을 베이스로 사용하였는데, 이에 비해 IoU 0.1-0.7 기준 mAP가 무려 4% 가까이 향상된 것을 볼 수 있습니다.
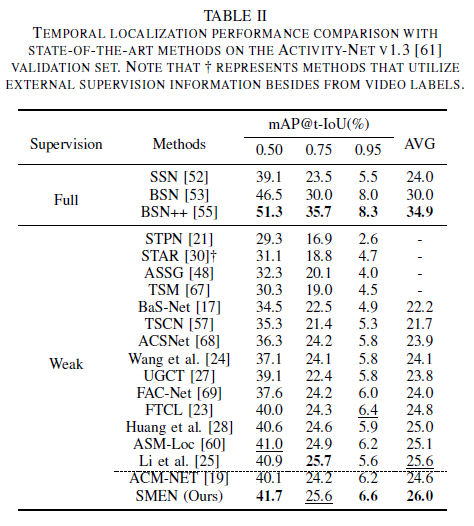
다음은 ActivityNet1.3에 대한 벤치마크 성능입니다. ActivityNet은 THUMOS 데이터셋과 다르게 잔디 깎기, 요리 하기 등 대부분이 일상적인 action을 담고 있습니다. 그래서 저자가 처음에 slow motion의 예시로 든 스포츠 하이라이트 부분이 많지 않아 THUMOS 데이터셋에만 좀 유효하지 않을까 하는 생각이 있었는데 ActivityNet에서도 slow motion을 학습한다면 기존 ACM-NET에 비해 꽤나 성능이 향상되는 것을 확인할 수 있었습니다.
Model analysis
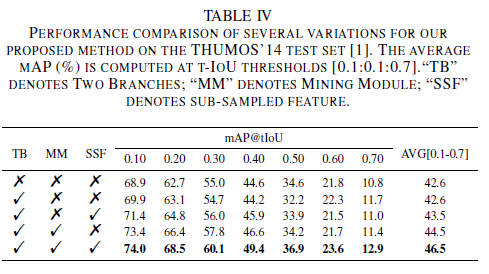
각 branch를 붙였을 때에 따른 성능 표입니다. Mining module을 통해 slow motion을 모델링해줌으로써 얻는 성능 향상이 컸고, 다른 모듈들도 붙임에 따라 성능이 향상되는 것을 보여줍니다.
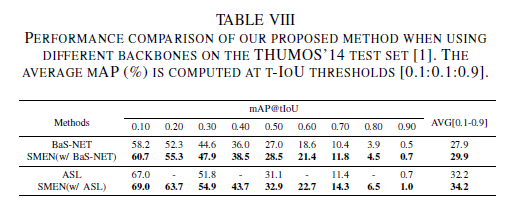
ASM-NET이 아닌 다른 backbone에 SMEN을 붙였을때의 성능도 있습니다. backbone에 관계 없이 slow motion을 찾아내어 모델 학습에 사용하는 것 자체가 유효하다는 것을 알 수 있네요.
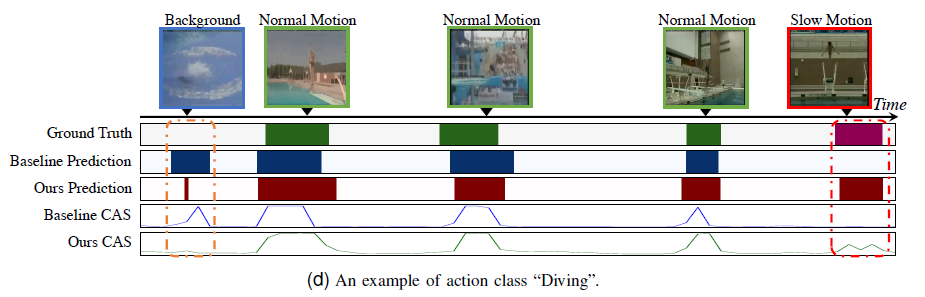

정성적 결과에서 저자는 성공적인 케이스와 실패한 케이스 모두 보여주고 있습니다. 성공적인 케이스에서는 기존 baseline 모델들이 잡아내지 못하던 slow motion을 잘 localize 할 뿐만 아니라 false positive도 잡아주는 것을 볼 수 있습니다.
실패한 케이스(보라색 박스)에 대해서 저자는 baseline과 SMEN 모두 잡지 못했는데, 이에 대해 저자의 자세한 분석은 나와 있지 않았고 action instance가 너무 짧아 두 모델 다 제대로 모델링 하지 못한 것으로 보인다고 합니다. future work로 남겨둔다고 하네요.
저널인만큼 다양한 실험과 분석 결과가 논문에 있으니 더욱 궁금하신 분들은 찾아보셔도 좋을 것 같습니다.
비디오의 특성과 핵심을 잘 파악한 후 간단한 아이디어와 모델링을 통해 기존 방법론 대비 큰 성능 향상을 보여주었다는 점이 인상깊은 논문이었습니다.
이상으로 리뷰 마치겠습니다.
문제 정의가 간단해서 인상 깊네요. 성능은 또 왜 이렇게 높은건지..
요즘 FIVR 데이터셋으로 Localization 실험을 조금 해본 것으로 아는데, FIVR에서도 효과가 있을 거라고 생각하시나요? 의견이 궁금합니다.
FIVR 데이터셋의 특성이나 분포를 다 알지는 못하지만, ActivityNet이나 HACS 데이터셋처럼 스포츠 이외의 일상적인 action class를 주로 가지는 데이터셋에 대해서도 성능 향상이 있었다고 하는 것으로 보아 FIVR에서도 충분히 성능 상의 효과가 있을 것으로 예상됩니다.
좋은 리뷰 감사합니다.
같은 장면에서 속도가 다른 비디오를 가지고 모션과 관련하여 성능을 개선하고자 한것이 재밌네요. 이제부터 스포츠 뉴스 볼때 다른 시각으로 볼거 같습니다ㅎㅎ
리뷰을 읽으면 질문이 있습니다.
video feature 중에 slow motion과 관련있는 부분을 찾는 기능을 하는것이 mining moduel이라는 것인데, 여기서 video feature에서 slow motion과 관련된 부분을 찾을 때 slow motion action이 큰 특징이 없고 noral motion처럼 salient 한 것이 아니여서 video featrue를 sub-sampling을 진행한다고 이해했습니다.
1) 여기에서 slow motiom action이 왜 normal motion처럼 salient하지 않다고 하는 걸까요?
2) slow motion action이 딱히 큰 특징이 없다고 하였는데, 이 부분을 ‘단순한 motion과 slow motion을 구별할 수 있는 큰 특징이 없다’라고 이해하였는데 맞는 걸까요?
감사합니다.
1) normal motion은 시간 축에서 프레임 간 차이가 상대적으로 크고, 모델이 학습할만한 의미를 갖고 있는데 slow motion의 경우에는 프레임 간의 차이도 background처럼 상대적으로 적어 FN으로 분류될 수도 있습니다. 또한 지금까지 연구된 방법론들은 normal motion의 pace에 알맞는 action을 찾도록 feature나 아키텍쳐가 설계되어 있기 때문에 기존 방법론들이 slow motion을 잡아내기에는 부족하다는 의미이기도 합니다.
2) normal motion과의 구분이라기 보다는, slow motion을 학습하기 위해 먼저 slow motion을 찾아야 합니다. 그러려면 slow motion의 특징을 파악해 feature 중 그러한 특징을 보이는 부분을 잡아 내야 하는데, 그 특징이 딱히 없다는 의미입니다.