오랜만에 x-review를 작성하네요. 이번에 소개드릴 논문은 CVPR2022 Oral paper로 선정된 Splicing ViT~~입니다. 해당 논문의 task는 Image Translation이라고 이해하시면 좋을 것 같습니다.
Intro

일단 논문에서 하고자 싶은 목표는 그림1과 같습니다. 기존의 Image Translation방법론들 처럼 A도메인의 영상을 B도메인으로 변환하기 위해서 입력 데이터로 A 도메인의 영상을 넣어서 B 도메인과 유사한 영상을 생성하게 됩니다.
Image Translation에 대하여 그림1의 예시에서는 의미론적인 부분들(예를 들어 황소와 얼룩소가 매칭되어 얼룩무늬가 정확히 들어가는 반면에, 바닥은 또 바닥끼리 매칭되어 조금 더 산뜻한 초록잔디로 바뀌는 그런 느낌)이 잘 매칭되어 변환이 되는 모습입니다.
이러한 task를 잘 수행하기 위해서는 입력 영상과 모델 학습에 사용될 영상에 대하여 style과 content를 잘 분리해야할 뿐만 아니라, 두 영상 사이의 의미론적인 대응정보를 잘 구해야만 합니다. 저자는 이를 위해서 self-supervised manner로 사전학습된 ViT(DINO-ViT)를 활용하여 영상의 appearance와 structure 정보를 추출하도록 하였습니다.
갑자기 뭐 VGG나 Resnet같은 CNN기반의 모델이 아닌 굳이 자기지도학습으로 학습한 DINO-ViT를 활용했는가?가 사실 이 논문의 중요한 포인트가 될 수 있습니다. 저자가 주장하는 바에 의하면, CNN모델들은 content/style의 표현력이 region에 기반한다기 보다는, global한 특성을 지니고 있다고 합니다.
하지만 DINO-ViT의 경우에는 global token(즉 CLS token)이 해당 영상의 visual appearance를 잘 표현하고 있어 영상의 텍스쳐 정보 뿐만 아니라 물체의 부분부분들에 대한 global 정보를 가지고 있다고 합니다. 또한 가장 깊은 레이어에서 추출한 feature의 경우에는 매우 높은 구조적 정보와 의미론적인 정보를 담고 있기 때문에 저자의 목표와 매우 적합하다고 주장합니다.
즉 저자는 ViT에서 추출할 수 있는 global token을 통해 영상의 appearance를 추출하고, deep layer의 key값에 대한 self-similarity를 계산함으로써 structure 정보를 표현할 수 있다고 합니다.
또한 저자가 제안하는 방법론은 이러한 ViT를 통해 필요한 loss를 다 계산할 수 있으므로, 따로 GAN과 같은 adversarial loss를 활용하지 않으며, 기존의 image translation 방법론들처럼 어떤 도메인의 데이터셋이 필요한게 아닌, 그냥 영상 한쌍으로도 generator를 학습시킬 수 있다고 합니다. 그리고 GAN을 활용하지 않았기 때문에 고해상도의 영상 또한 변환이 가능하다고 하네요.
Method
그럼 본격적으로 방법론에 대해서 다루도록 하겠습니다.
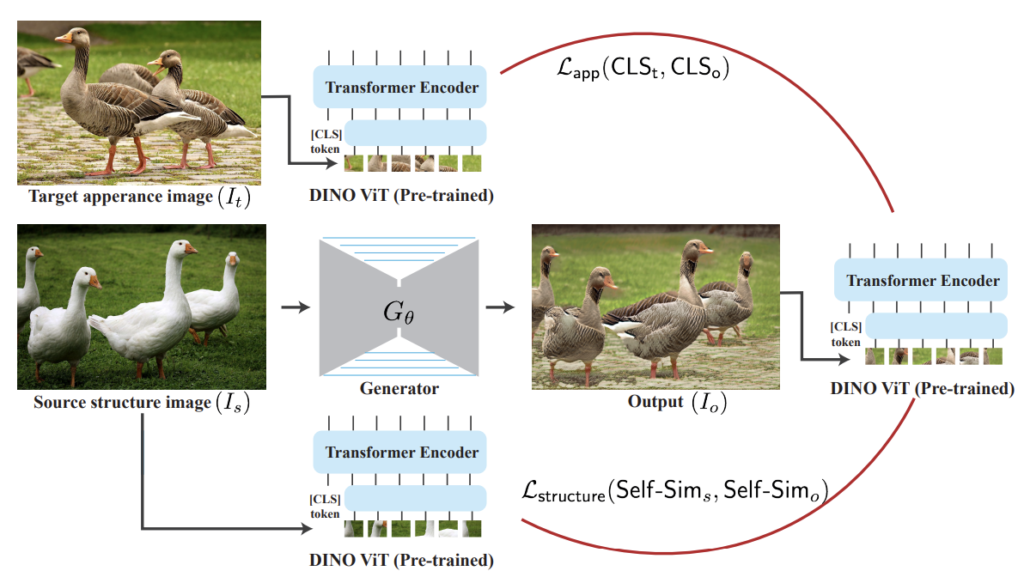
먼저 모델의 학습 과정은 그림2처럼 진행이 됩니다. Style Transfer 쪽 논문을 읽어보신 분이라면 매우 쉽게 이해하실 수 있으며, 해당 분야에 익숙치 않은 분이시더라도 직관적으로 이해가 가능하실 겁니다.
요약하자면 Source image( I_{s})는 Generator를 타고 나와 변환된 영상 I_{o}로 탄생하게 됩니다. 이렇게 변환된 영상과 appearance image( I_{t})의 appearance 정보를 서로 비교해야하는 loss term이 존재를 하고 있고, 또한 structure 정보에 대해서는 입력 영상 [latex]I_{s}와 변환 영상 I_{o}가 서로 같아야만 하기에, 이를 비교해주는 loss term이 필요하게 됩니다.
대충 이런식으로 appearance와 structure 정보에 대하여 각각 비교를 해야하기 때문에, 영상에 얽혀있는 이 정보들을 정확하게 구분해줄 수 있는 loss network와 필요하게 되는 것이며, 해당 network로 기존에도 다양한 방법들이 있었지만, 해당 방법론에서는 DINO-ViT를 활용한다는 점입니다.
ViT에 대해서는 굳이 자세하게 다루지는 않으려고 하며, 그냥 Multi-head Self-attention 연산을 하기 위해서 transformer block 내에서 query, key, value라는 특징을 가지는 feature를 뽑아서 attention 연산을 수행한다고 아시고 넘어가면 될 듯 합니다.
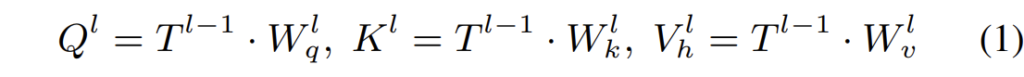
즉 위와 같이 T라는 feature에 대해 각각 다른 weight를 곱해서 Q, K, V를 생성하게 되는 것이죠.
그리고 여기서 이 K에 대하여 self-similarity를 계산하게 되면 이것이 영상의 structure 정보를 담고 있다고 합니다. 그래서 저자는 아래 수식처럼 cosine 유사도를 통해 영상의 structure 정보를 표현합니다.
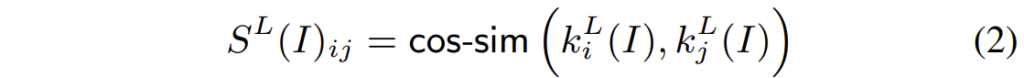
사실 이 key 값에 대한 코사인 유사도가 구조적 정보를 나타내는지에 대해서는 해당 논문에서 직접 밝히는 것이 아닌, 21년도에 나온 논문을 참고했다고 합니다. 21년도 논문에서도 PCA를 통해 feature map을 시각화 하는 형식으로 확인하는 것은 봤는데, 어째서 이렇게 되는지에 대해서는 해당 논문을 참고해봐야 할 것 같습니다.

또한 아까 영상의 appearance를 VIT의 CLS token으로 대체가능하다고 했는데, 이것을 증명하기 위해서 저자는 feature inversion 방법론을 활용하게 됩니다. feature inversion이라는 어떠한 영상이 주어졌을 때, 먼저 해당 영상에 대한 target feature를 추출합니다. 그 다음에 사전에 뽑아놓은 target feature와 동일하게 매칭되도록 하는 영상을 최적화하는 작업을 의미합니다.
그런데 영상을 최적화하는 방식은 수렴이 잘 안된다는 기존의 연구결과들을 토대로, 저자는 Deep Image Prior 방법론과 동일하게 고정된 random noise z를 출력 영상으로 변환시키는 CNN F_{\theta} 의 weight를 최적화하는 방식으로 Feature conversion을 수행하였습니다.
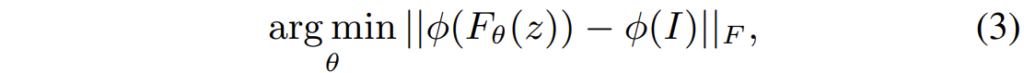
여기서 \theta(I) 는 target feature를 의미하며 저자는 이 target feature를 CLS token으로 지정하고 실험을 하였습니다. 이때의 inverting 결과는 아래와 같습니다.

그림4의 결과를 살펴보면 CLS token에 대한 특성을 다음과 같이 정리해볼 수 있습니다.
먼저 첫째는 CLS token이 얕은 레이어에서 깊은 레이어로 진행될 수록, inversion 결과가 local texture부터 global information을 표현하는 것을 알 수 있습니다. 그래서 저자는 appearance 정보를 추출하기 위해서는 deep layer에서 추출한 CLS token이 필요하다는 것이구요.
또한 둘째로 CLs token은 spatial 정보에 대하여 상당히 유연한 특징을 지닌다는 점입니다. 예를 들어 다른 객체의 part들은 늘어나거나 대칭되거나 변형되는 등 매우 공간정보들이 유연하게 변형된다는 것이죠.
Objective Function
결과적으로 이 방법론은 매우 간단합니다. DINO-ViT를 통해 영상의 appearance와 structure 정보를 다 추출할 수 있으니 이를 통해서 변환 모델을 생성하자는 것이죠. 그래서 목적 함수도 아래와 같이 나타낼 수 있습니다.
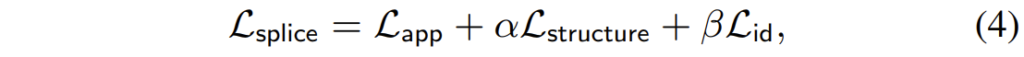
여기서 app는 appearance loss로 target image의 CLS token과 변환된 영상의 CLS token끼리의 차이를 계산한 것입니다.
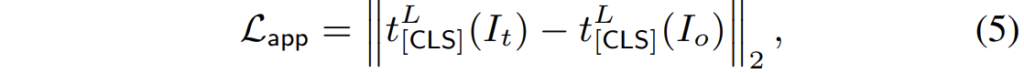
그리고 structure의 경우에는 입력 영상과 변환 영상의 self-similarity map의 오차를 계산하는 방식으로 진행됩니다.
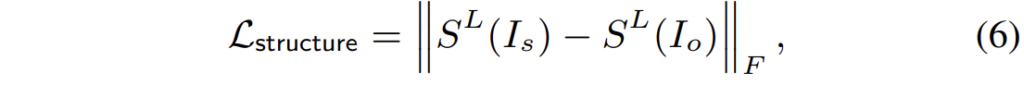
id loss의 경우에는 일종의 regularization term으로 보시면 될 것 같은데, 만약 target 영상을 generator에 넣게 된다면, target image의 key값은 기존의 key 값과 동일해지도록 하는 것입니다. 사실 이렇게 하는 이유에 대해서는 논문에서 디테일하게 설명을 하지 않아서, 잘 모르겠네요ㅎㅎ..
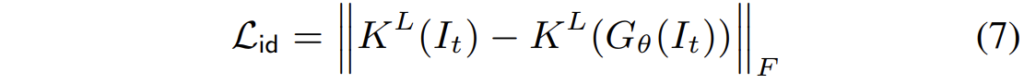
Experiments
그럼 실험 결과 리포팅하고 리뷰 마무리하도록 하겠습니다.
먼저 정성적 비교 결과입니다.

보시면 STROTSS의 경우 Color가 번지는 color bleeding 현상이 종종 발생하는 것을 확인하실 수 있으며, WCT의 경우에는 global color로 영상이 도배되버리는 현상이 발생합니다. 즉 semantic한 정보를 잘 고려해서 필요한 부분에 대해서만 색감이 입혀져야하는데 그냥 appearance 이미지의 평균 색감을 그대로 입혀버리는 것이죠.
반면에 저자가 제안하는 방법론은 실제 의미론적인 정보들이 딱딱 매치가 되어 올바르게 변환된 것을 확인하실 수 있습니다. 물론 체리픽이기 때문에 완전히 신뢰하지는 않습니다ㅎㅎ..

위의 결과는 Image Translation 방법론인 SinCUT과의 비교 결과입니다. Image Translation 기법은 첫번째행처럼 low-level의 정보들 사이에서는 변환이 잘 되는 것을 볼 수 있으나, 2번째 행같이 조금 복잡한 의미론적 정보에 대해서는 올바르게 변환이 되지 못하는 것을 확인할 수 있습니다.

다음은 Ablation study에 대한 정성적 결과 비교 입니다. loss를 모두 활용한 경우에는 구조적 정보도 온전하면서 style이 잘 입혀진 것을 확인할 수 있습니다만, appearance loss를 적용하지 않을 경우에는, 과일의 표현력이 잘 담기지 않는 것을 확인할 수 있습니다.
또한 structure 관련 loss가 빠지면 당연히 입력 영상의 구조적 특성을 잘 따라하지 못하는 것을 볼 수 있구요. id loss가 없게 되면 모델이 잘 변환시킨 것처럼 보이긴 하지만, 세부적인 디테일 측면에서 어색한 것을 확인할 수 있습니다.

마지막으로 위의 결과는 appearance image와 structure 이미지가 의미론적으로는 같지만 실제와는 다른 경우거나, 또는 의미론적인 정보도 다르고 class 카테고리도 다른 경우 등에 대해서 변환 결과를 나타낸 것입니다. 아무래도 두 영상 사이의 의미론적인 정보가 겹치지 않게 되면 모델이 학습을 정확히 할 수가 없어 결과가 썩 좋지 못한 것을 확인할 수 있습니다.
결론
기존의 방법론들은 CNN기반의 네트워크를 가지고 영상 속 style과 content를 구분하려는 시도들을 많이했지만, ViT는 전혀 그런 것들이 없었는데, 해당 방법론에서 무언가 속시원하게 ViT도 할 수 있다는 것을 잘 보여준 것 같습니다. 하지만 해당 논문에서 평가를 할 때 이미지 한쌍만으로 모델을 학습시키는 것인지, 만약 기존처럼 다수의 영상이 존재하는 이미지 세트로 학습할 경우는 어떻게 되는지 그런 자세한 정보들이 나와있지 않아서 조금 아쉬웠습니다. 해당 궁금증에 대해서는 공개된 코드를 직접 돌려봐야 알 수 있겠네요.
리뷰 잘 봤습니다. ViT 에 대해 깊게 아는것이 아니라서 직관적으로 많이 와닿지는 않네요 ㅎ
초반부에 ‘CNN모델들은 content/style의 표현력이 region에 기반한다기 보다는, global한 특성을 지니고 있다’ 라는 표현이 있었습니다. 이 부분을 언급하면서 ViT를 도입해야 한다고 저자가 서술했을 거 같은데, CNN같은 경우 제가 생각했을땐 kernel이 움직이면서 region을 위주로 판단을 한다고 생각합니다. 이 부분에 대한 추가적인 저자의 설명이나, 신정민 연구원의 견해가 있으신가요 ??
음 물론 앞 스테이지에서의 low-level feature의 경우에는 권석준 연구원님이 하신 얘기가 맞을 수 있겠으나, 리뷰 글을 잘 살펴보시면 deep layer 즉 high-level feature 부분에서 CNN이 global한 특성을 지닌다고 언급하고 있습니다.
즉 layer가 점점 깊어지면 resolution이 점차 다운샘플링 되면서 receptive field가 넓어지고 결국 global 정보를 담게 되는 것이죠.
좋은 리뷰 감사합니다.
해당 방법론은 ViT를 이용하여 이미지의 CLS token으로 appearance을, cos-sim을 이용하여 structure를 학습한 것으로 이해하였습니다.
id loss는 key값이 동일하도록 하기 위해서라 하셨는데, 이는 앞부분에 언급하셨던 “의미론적 대응”을 위한 loss로 이해하면 되나요??
음 그럴 수도 있을 것 같긴한데 사실 잘 모르겠습니다.
애초에 source image가 아닌 target image를 왜 generator에 한번 태우는 것인지에서 부터 그 의미를 이해하기가 어려워서 음.. 만족스러운 답변을 드리기는 힘들 것 같네요^^;