이번에도 음성 감정인식 관련 논문 리뷰입니다.
일단 저는 음성 감정인식 과제에서의 1차년도 정량적 목표를 위해 실험을 하고자 하였습니다. 우선 간단하게 설명을 드리자면 저희 과제에서는 1차년도에 음성 감정 인식을 목표로 하고 있습니다. 특히 최종적으로 실제 로봇으로 실증을 해야하기 때문에, Real-World에서 동작하는 그런 강인한 모델을 생성해내야 하였습니다. 따라서 그냥 감정인식이 아닌 노이즈가 포함되는 데이터셋에 대하여 디노이징 과정을 포함하는 모델을 제안하는 것을 목표로 합니다. 지난번 이광진 연구원의 리뷰가 바로 올해 디노이징 모델의 베이스라인으로 잡았던 논문입니다.
그러나… 해당 논문은 기계학습 방법론에서 딥러닝을 사용한 디노이징의 처음 시도라는 점 때문인지는 몰라도, 정량적인 성능을 보여주지 않았습니다. 사실 노이즈 제거라는 것이 정성적인 것도 중요하기 때문에 실제로 이쪽 분야에서는 많이 사용하는 정성적인 결과라고는 합니다만… 꽤나 큰 이슈가 있었지만,, 저자가 공개한 모델로 뽑은 디노이징 음원들이 성능이 심각하게 저조한 탓에 급하게 서베이를 새로 하였습니다.
최근 트랜드는 당연히 트랜스포머를 사용하는 것이겠지만, 우리 과제의 칩셋 이슈가 있어 트랜스포머를 사용할 수는 없습니다. 따라서 이런 제한을 기반으로 서베이를 시작하게 되었습니다. 베이스라인으로 선정한 모델은 WaveNet이라는 구글에서 공개한 TTS모델을 변형하여 만든것인데요. 그 다음 트랜드(?) 가 바로 WaveNet에 U-Net을 적용한 방법론입니다. 제가 이번에 리뷰할 논문은 거기에 추가로 어텐션 모듈까지 구현한 것입니다.
그럼 리뷰 시작하겠습니다.
U-Net
[MICCAI 2015] U-Net: Convolutional Networks for Biomedical Image Segmentation ( 논문 바로가기 )
WaveNet에 대한 설명은 지난번 이광진 연구원의 리뷰 에 나와있으니 생략해보도록 하겠습니다. 해당 방법론이 WaveNet에 U-Net을 추가한 것이라고 하니… U-Net이 어떤 아키텍처인지 살펴볼 필요가 있습니다. (왜냐하면 저는 잘 몰랐기 때문이죠 허허) 일단 U-Net은 의료 분야에서 segmentation을 목적으로 만들어진 End-to-End 형식의 Conv 기반 모델이라고 합니다.
아래의 이미지처럼 U 모양의 architecture 형태로 인해 U-Net이라는 이름이 붙여진 것이 특징입니다.
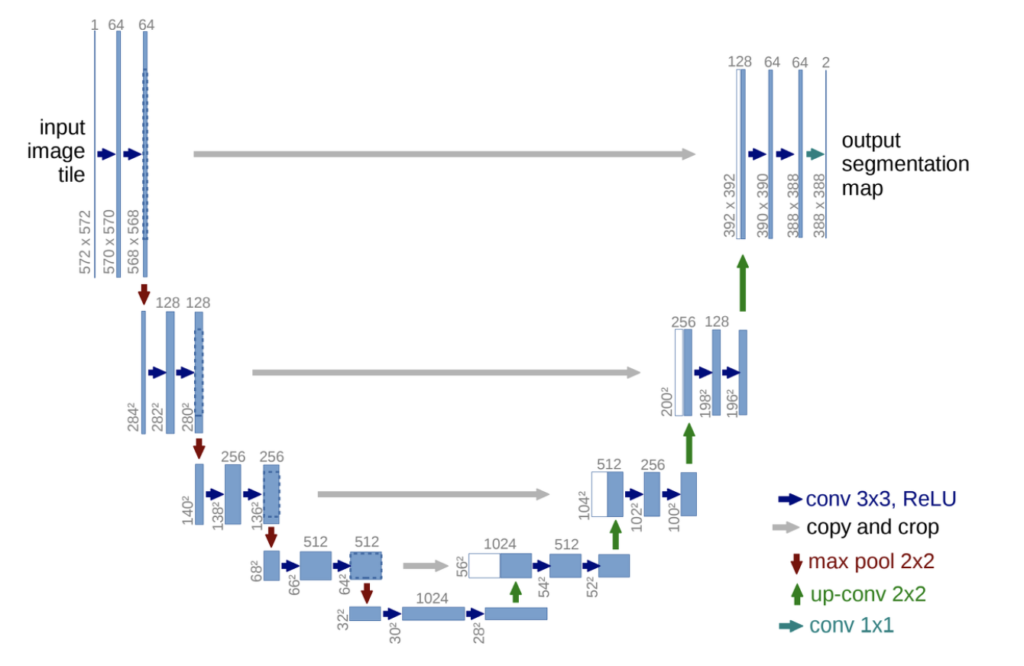
U자의 중심을 기준으로 앞부분을 feature 의 크기가 줄어드는 Contracting path, 뒤부분을 feature의 크기를 다시 늘려주는 Expanding path라고 부릅니다. Contracting path에서는 이미지의 context한 영역을 포착하고 Expanding path에서는 세밀한 localization을 진행하게 됩니다. 마치 인코더-디코더의 일종이라고 이해해주시면 좋을 것 같습니다.
단순히 피처맵을 줄였다가 키우는 것보다는 해당 모델의 메인 아이디어는 바로 skip architecture 라고 합니다. 위에 그림에서는 U자의 가운데를 가로로 가로지르는 회색의 화살표가 바로 그 역할을 합니다. 즉, expanding path 각 단계에서 동일한 단계의 앞부분의 피처를 그대로 가져와서 concat하였습니다. (크기가 안맞으면 expanding / crop 등 진행) 이를 통해 기존 정보를 보존해서 그대로 사용하겠다는 것이죠.
그리고 가장 마지막에서는 input image을 그대로 skip connection 해줍니다. 이제 Segmentation인만큼 채널을 label 의 수로 맞춰주며 segmentation을 진행하는 것입니다. 뭐 사실 간단한 구조라고 할 수 있습니다. 그런데 이제 제가 리뷰하려는 논문의 연식이 있다보니.. 특히 딥러닝 방식의 디노이징 방식도 제안된지 얼마 안됐으니 해당 모델이 사용되지 않았다 싶습니다.
Wave U-Net
[Arxiv] WAVE-U-NET: A MULTI-SCALE NEURAL NETWORK FOR END-TO-END AUDIO SOURCE SEPARATION
그렇다면 Wave를 위한 U-Net인 Wave U-Net의 구조는 어떨까요? 이번 리뷰에서는 정말 간단하게 설명을 작성할테니, 자세한 내용은 상단 논문을 참고해주시면 좋을 듯 합니다.
하단 그림이 바로 Wave U-Net의 아키텍처입니다. U-Net에서의 인코더(Contracting path)에 해당하는 부분이 왼쪽 노란색 부분이고, 업샘플링을 진행하는 디코더(Expanding path)는 오른쪽 연두색 부분에 해당합니다.
당연하겠지만 이미지 기반의 U-Net과 달리 1차원 신호이기 때문에 1d conv 를 사용했다는 차이가 있습니다. 또한 업샘플링 과정에서 생기는 artifacts를 막기 위해 추가적인 input context를 주었다는 핵심 아이디어가 있습니다.
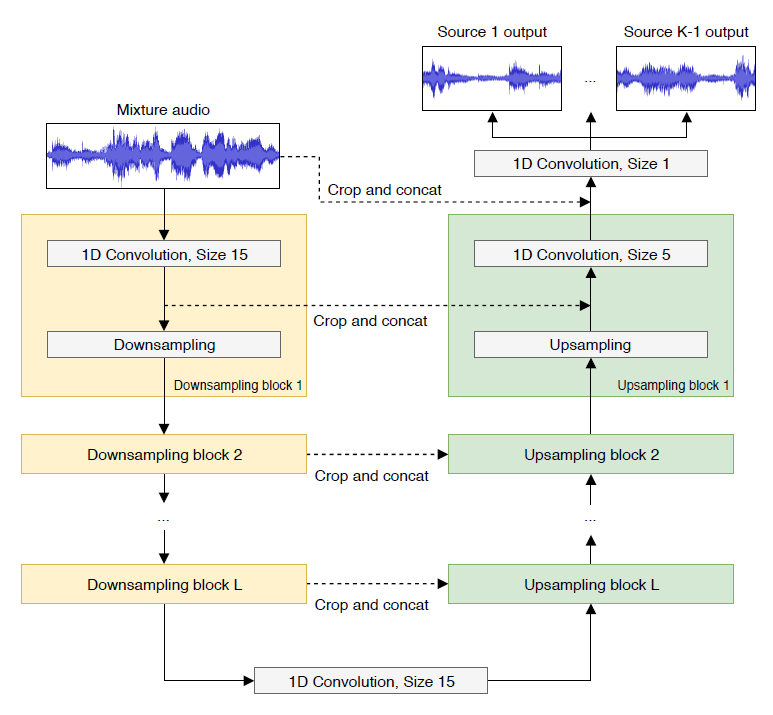
결국 1D 시그널을 위한 U-Net을 만들기 위해 Wave U-Net 구조가 완성된 것입니다
Model
이제 본격적으로 해당 논문의 방법론을 설명하는 파트네요.
그 전에 다시 한번 정리하자면, 이 논문은 Wave U-Net에 어텐션 모듈을 붙혀서 제안한 방법론입니다. Wave U-Net 은 원형 음원을 그대로 사용하기 위해 U-Net의 2차원 conv를 1차원으로 변형한 것이며, 원형의 음성을 사용하기 때문에 타임 도메인 신호에서 직접 작동하게 됩니다.
따라서 최종적인 본 논문에서 제안하는 모델의 구조는 아래와 같습니다.
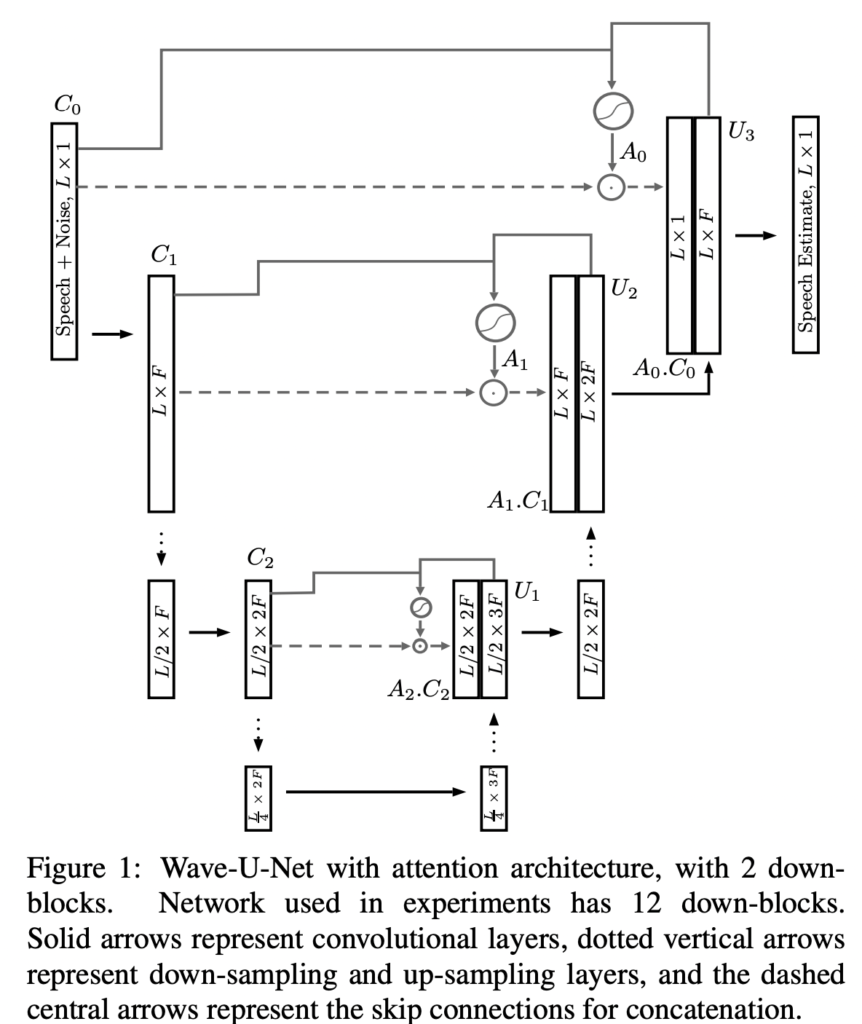
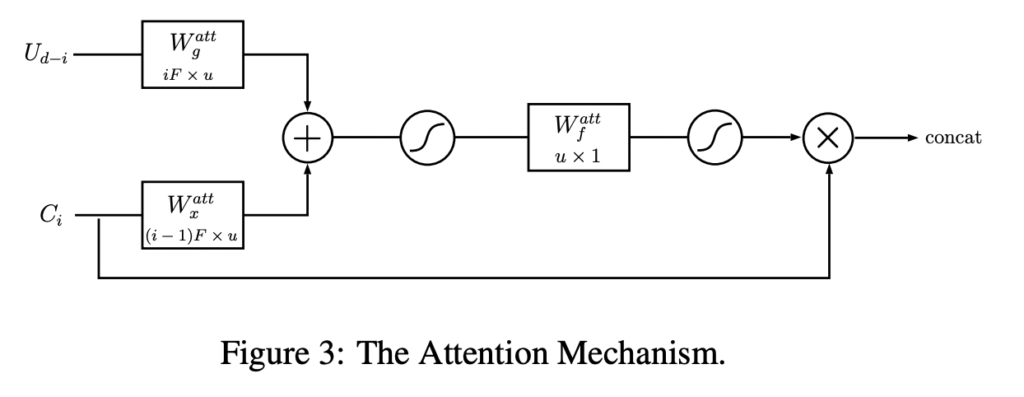
본 논문의 메인은 Attention 모듈입니다. 기존 유넷에서의 스킵 커넥션 부분에 어텐션 게이트를 사용하여 위의 그림과 같이 어텐션 마스크를 곱해서 다운블록에서 피처를 인식하는 것입니다.
이를 모델링하기 위해, 커널 크기1의 추가적인 1차원 W_x, W_g가 필요하며, 이를 통해 어텐션 마스크를 설계하였습니다. 생각보다 간단한 방식입니다.
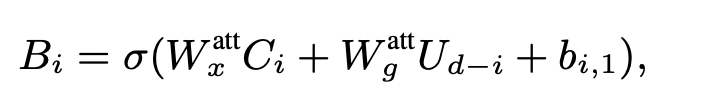
Experiment
실험은 이광진 연구원이 리뷰한 Wavenet과 동일한 데이터셋을 사용하였습니다.
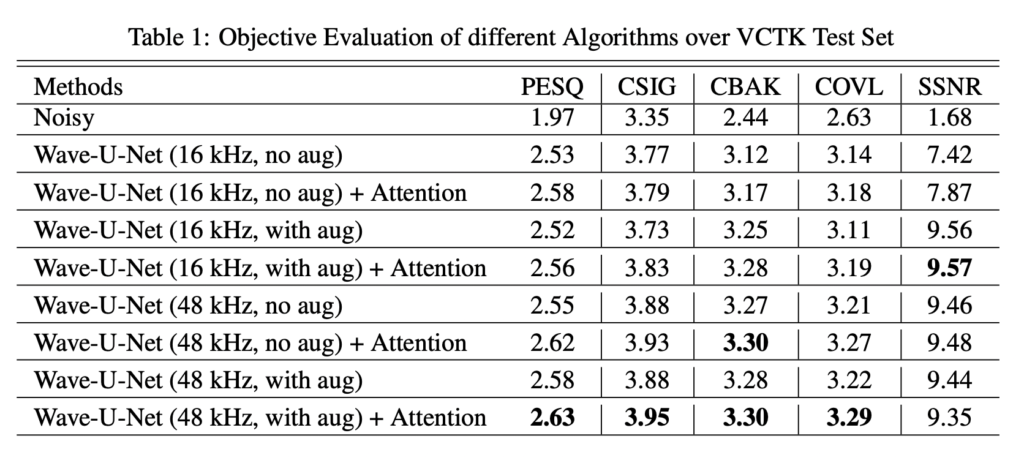
우선 해당 논문은 기존에 베이스라인으로 선정한 논문과는 다르게 정량적인 지표를 제안한다는 점에서 차이가 있습니다. 특히 저는 PSEQ 지표에 집중하였고 그리하여 해당 논문을 선정하게 된 것이 큽니다. (일단 참고로 .. 기존 베이스라인에서 뽑힌 PESQ는 1.초반대였습니다… 작을수록…나쁜거랍니다/..,,,) 그런데 해당 논문의 Noisy가 벌써 1.97이니… 허허,..
우선 하단 테이블은 소음의 크기 및 어텐션 모듈 등 ablation study라고 봐주시면 좋을 것 같습니다.
딥러닝의 적용은 음성이라고 이미지와 다르지 않습니다. 이미지 도메인과 비슷하게 미리 정의한 feature를 추출하는 기계학습적 방식에서, 딥러닝 방식의 등장은 Raw wave 를 직접 사용하여 노이즈를 제거하는 방식으로 이어진 것입니다. 아래 테이블은 기존에 SOTA라고 불리는 아래 4가지 방법론과 기계학습적 디노이징 필터들과 비교하였습니다
- SEGAN [8]: 생성적 적대 네트워크로 최적화된 Time domain U-Net based network
- Wavenet [19]: 베이스라인으로 선정했던 논문 (WaveNet-denoising)
- Wave-U-Net [6]: source separation에서 수정된 Time domain U-Net based network
- Deep Feature Loss: classifier에서 feature loss로 학습된 Time-domain dilated convolution network
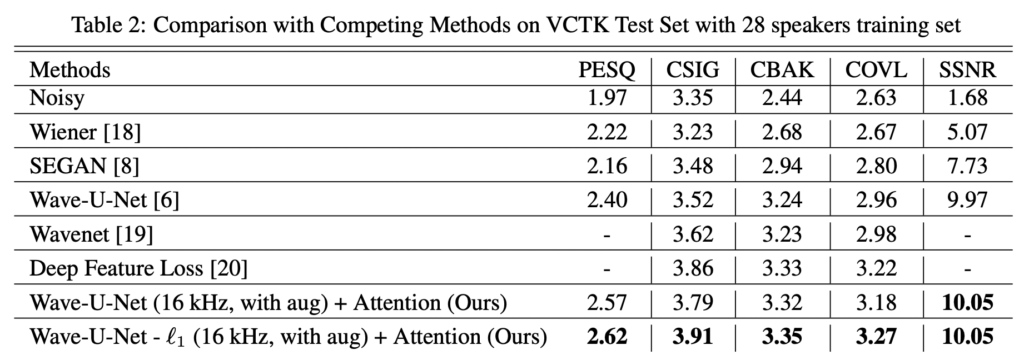
상단 테이블2를 통해 본 논문에서 제안한는 방식이 가장 좋은 성능을 발생하는 것을 알 수 있었습니다.
우선 어텐션 모듈까지 있는 이 논문보다는 웨이브 유넷을 한번 사용해봐야겠습니다. 사실 본 논문은 정량적 결과가 있어 원복 확인용으로 사용하고자 하였었는데요. 어려움이 있을 경우, 후속 논문을 살펴봐야겠습니다.
안녕하세요
그럼 실험 테이블에 noisy 부분 성능이 baseline의 clean 입력에 대한 예측치보다 좋은건가요..?
UNet과 같은 다양한 backbone 학습 기술을 적용한 다른 음성기반 감정인식 논문도 있는지 궁금하네요
좋은 리뷰 감사합니다.
좋은 댓글 감사합니다.
일단 현재까지 파악한 바로는 그렇긴 하지만 아직 노이즈의 dB에 따른 실제 정량적 비교는 아직까지여서 그렇다고 단언하기는 어려운 상황이긴 합니다. 질문해주신 바는 제가 현재 잡고 있는 감정인식 베이스라인이 완료되면 찾아보려고 합니다. 🙂