이번에 리뷰 논문으로 오랜만에 Visual-Inertial Odometry (VIO) 논문을 들고 왔습니다. 이승현 연구원과 기본 연구에 대해 상의하던 중 떠오른 아이디어로 VIO와 GAN를 융합하여 사용해보자는 아이디어가 나왔는데 고민했던 내용의 방법론과 굉장히 유사했던 논문입니다. 논문을 이해해보고 제가 생각해낸 아이디어에 대해 다시 한번 고민해보니… MonoDepthV2랑 굉장히 유사하더라구요… 역시 새로운 구조를 가진 방법론을 고민하기 어려운 것 같습니다.
Intro
Visual-Inertial Odometry (VIO)는 사람이 눈을 이용한 시각적 기능과 내이 기관을 이용한 ego motion을 파악하여 이동한 궤적을 추정하는 생물학적 기능을 모티브 삼아 시각 능력에 해당하는 카메라와 내이 기관에 해당하는 IMU 센서를 이용한 odemtry 입니다. VIO는 카메라만을 이용하는 VO에 비해 IMU를 사용하기 때문에 외부 환경의 변화에 대해서 강인성을 가지며, ego motion만으로 추정하는 IMU odemtry의 잔차로 인한 오류를 극복할 수 있는 가능성을 가지기 때문에 연구 커뮤니티에서는 VIO의 잠재적인 성능 향상을 기대하고 있는 추세입니다.
최근, VIO와 VO 태스크에서는 depth esitmation을 이용한 방법론이 대세를 이루고 있습니다. 영상으로부터 추론된 깊이 영상은 영상과 실제 세계를 이어지는 유용한 정보로 카메라의 이동 궤적을 파악하기 유용합니다. 이와 같은 방법론들은 사전 학습된 depth estimation을 이용하기 때문에 추론된 depth map의 정확도에 의존적이라는 한계가 존재합니다.
다른 한계로는 카메라, IMU와 depth sensor로부터 추론된 depth 정보와 같이 서로 다른 3가지 센서를 활용하면서 생기는 문제들이 있습니다.
첫번째, 카메라와 IMU 간의 데이터 전송, 센서 지연, OS overhead로 인한 지연으로 인해 미정렬 문제가 발생하게 된다. 이로인해 두 센서 정보간의 융합에서 미정렬 데이터들은 노이즈로 작용하여 성능에 영향을 끼치게 됩니다. 두번째로 LIDAR와 같은 structured light depth senseor에서도 노이즈오 인공물로 인한 미정확한 GT를 생성하게 됩니다. 특히 반사, 투명, 어두운 표면을 가진 물체로 인해 노이즈가 발생하게 됩니다. 세번째로 depth sensor와 카메라 간의 뷰포인트를 일치시키는 과정에서 offset이 발생하면서 오차가 누적되게 됩니다. 이러한 문제들은 정답 데이터를 이용한 학습 기반의 방법론에서 문제가 발생하게 됩니다. 이러한 사유로 저자는 비지도 학습을 이용한 학습 방법을 사용할 것을 제안합니다.
또한 저자는 depth estimation과 VIO를 결합한 최초의 self-supervised method라고 소개하며, 기존 VO 접근 방식과 달리 포즈 및 깊이 추정을 위해 카메라와 IMU 간의 엄격한 시간적 또는 공간적 보정이 필요하지 없다고 합니다.
Method
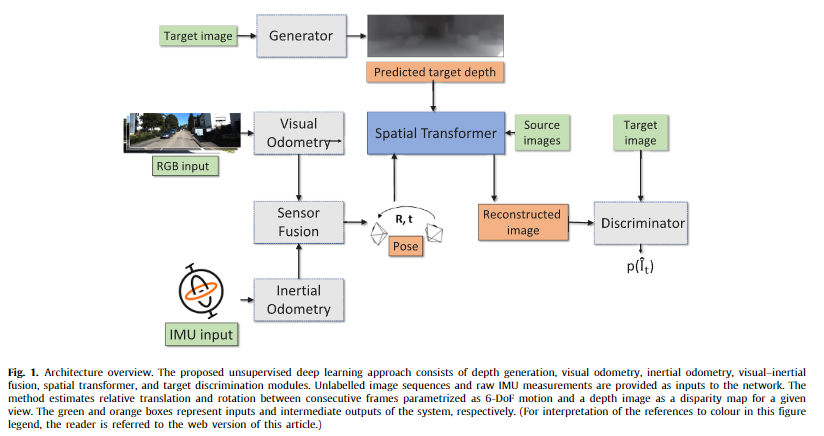
Self-supervised monocular VIO and depth estimation architecture
전반적인 구조는 fig 1과 같습니다. 먼저, 단안 RGB 이미지 시퀀스와 raw IMU 데이터가 주어지면 두 센서 별로 특징을 추출하여 융합한 후, 6-DoF 카메라 모션(Pose~[R, t])을 회귀합니다. 단안 RGB 이미지 시퀀스 영상 중 메인이 되는 타겟 뷰 I_t로부터 depth esitmation(Generator)으로부터 depth map을 추정합니다. 해당 depth map은 Spatial Transformer에서 카메라 파라미터로부터 3D point cloud로 변환되어져, 해당 값과 t-1 ~ t ~ t+1 간의 6-DoF 변화를 3D point cloud를 t-1, t+1로 변화을 수행합니다. 변환된 3D point cloud은 영상 좌표계로 투영되어져 source image(I_t-1, I_t+1)을 reconstructed image I_t’로 변환합니다. 그 후, discriminator로부터 target image와 reconstructed image의 진위 여부를 구분하는 구조를 가집니다.
++ Spatial Transformer에 대해서 쉽게 설명드리자면 포테닛에서 열화상 영상을 컬러 스테레오의 disparity를 이용하여 픽셀을 옮기는 방법을 떠올리시면 이해하기 쉽습니다. 여기서는 스테레오 정보를 시퀀스 영상간의 [R, t]로 옮기는 작업이 추가되었다고 생각하시면됩니다.
+++ 추가로 해당 방법은 MonoDepthV2와 매우 유사합니다.
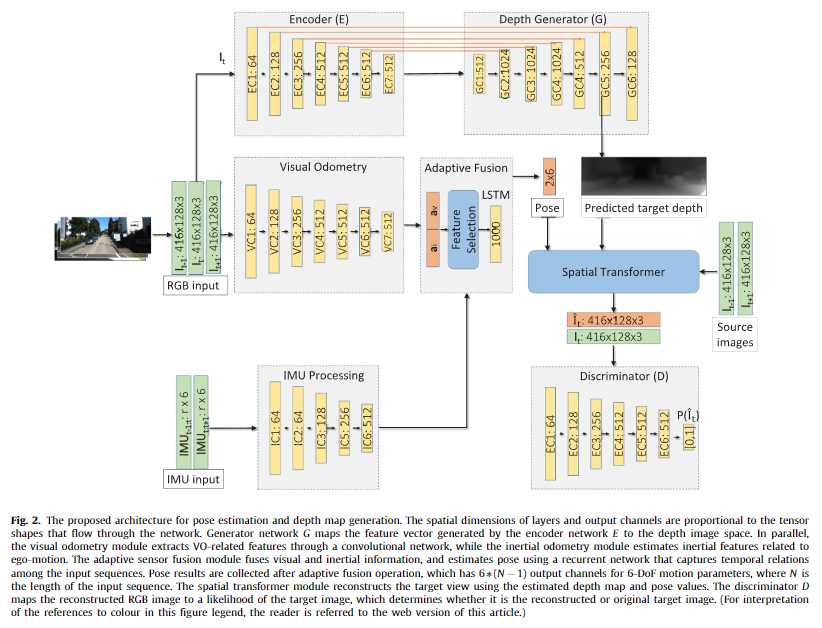
Depth estimation. 가장 먼저, generator에 해당하는 depth estimation은 fig 2의 상단에 위치한 모델 구조와 같이 U-Net 구조를 가진 모델을 구축했다고 합니다. 또한 GAN 구조를 가져가면서 보다 날카롭고 정확한 표현이 가능해졌다고… 합니다…
++ GAN 구조를 사용한 이점에 대해서는 주장만 있을 뿐, 뒷받침하는 근거가 없네요…
Visual odometry. VO는 세장의 시퀀스 컬러 영상을 결합하여 사용합니다. 모델은 fig 2 중간에 위치한 visual odometry와 같이 7개의 conv로 구성되어집니다.
Inertial odometry 아래와 같은 raw IMU 데이터를 입력으로 수용합니다.
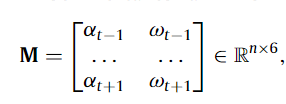
선형 가속도 \alpha 와 각속도 \omega 에 해당하며 각각 3축을 가진 정보로 구성되어집니다. n은 t-1 ~ t+1 동안 생성된 IMU 데이터의 수에 해당합니다. 위와 같은 구조로 입력된 데이터는 6채널을 가진 영상 데이터와 동일한 취급으로 convolution에 태워집니다. 구조는 Fig 2의 하단에 위치한 Inertial odometry에서 확인이 가능하며 아래의 그림에서도 볼 수 있습니다.

Self-adaptive visual–inertial fusion
위에서 설명된 visual odometry와 inertial odomety로부터 각각 t-1과 t+1 사이의 Euclidean transform 예측하도록 학습을 진행합니다. 저자는 두 센서 값의 정확도에 따른 적응적 융합을 주기 위해 아래의 수식과 같은 방법의 융합 방법을 제시합니다.

sigmoid \omega 에 해당하며, W_i와 W_v는 각 모달리티에 해당하는 weight입니다. 수식 1과 2를 통해 두 모달리티를 고려한 개별적인 attention 정보를 생성합니다. 그 다음 아래의 수식을 이용하여 상대적인 중요도를 고려한 퓨전 정보를 생성합니다.

++ 수식 3에서 오타가 있는 것 같습니다. 뒤 쪽에 존재하는 S_v는 S_i라고 보고 있습니다. 글에서 따로 설명이 없고, 공개된 코드가 없어 정확한 확인이 불가능하네요…
W_fused는 1000 hidden units를 가진 RNN(two-layer bi-driectional LSTM)에 넘겨져서 이전 시퀀스 정보들을 고려하여 학습을 진행되어집니다.
Spatial transformer
해당 모듈에서는 소스 영상을 타겟 영상으로 재구성하여 다음 수식과 같이 potometric error를 줄이는 방향으로 학습을 진행하게 합니다.

해당 방법은 MonoDepthV2와 유사한 방법을 가지며, 이를 수식화하면 아래와 같습니다.
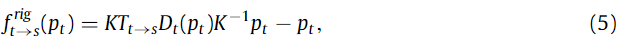
K는 4×4 카메라 transformation matrix이며 p_t는 타겟 영상에 대한 homogeneous coordinates에 해당합니다. D_t는 타겟 영상에서 추론된 depth map에 해당합니다. 해당 방법에 대해 자세한 내용은 MonoDepthV2를 참고하시면 좋을 것 같습니다…
View discriminator
해당 모듈에서는 depth의 정확도 향상을 위한 학습 모듈로 아래와 같은 수식으로 학습이 진행되어집니다.
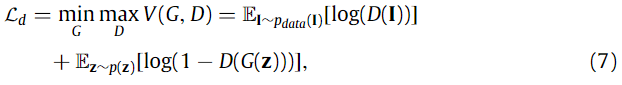
G는 depth esitmation, D는 분류기에 해당합니다. discriminator에서 사용된 GAN은 PatchGAN을 기반으로 설계하였다고 합니다.
최종적으로 모델은 아래 수식을 이용하여 학습을 진행합니다.

즉, GT Pose와 GT Depth 없이 자기 지도 학습을 진행합니다.
Experiment
해당 방법론은 KITTI, EuRoC, Cityscapes에서 평가를 진행하였습니다.
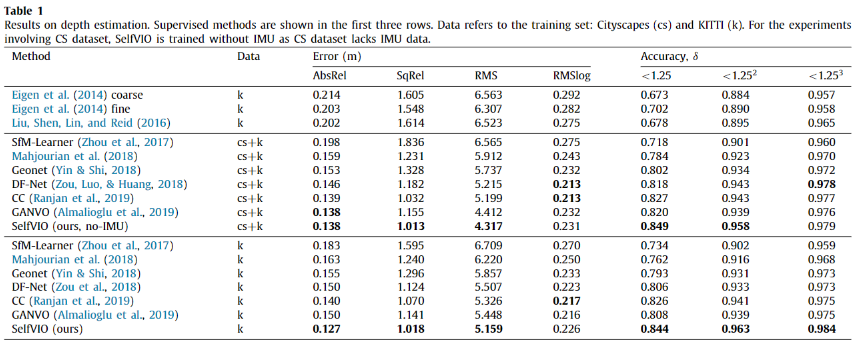
가장 먼저, odometry 태스크에서 활용되어지는 depth estimation 성능 비교 실험입니다. 가장 상단은 지도 학습 기반의 방법론에 해당합니다. 다른 방법론에 비해 확실히 좋은 성능을 보이고 있습니다.
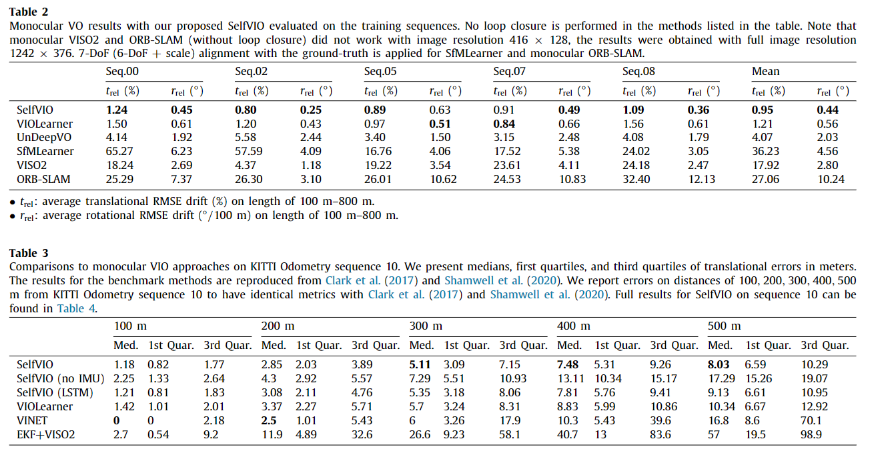
Tabel 2에서는 IMU 없이 monocular VO를 수행한 결과이며, Table 3은 KITTI seq 10에서의 VIO 결과에 해당합니다. 각각 모두 SOTA를 달성한 결과를 보여줍니다.

Depth 값에 대한 정성적 결과 입니다.
+ MonoDepthV2에 대한 결과가 없는 이유는 해당 방법론은 VIO 태스크이며 이에 해당하는 모델들과만 비교 분석을 진행합니다.
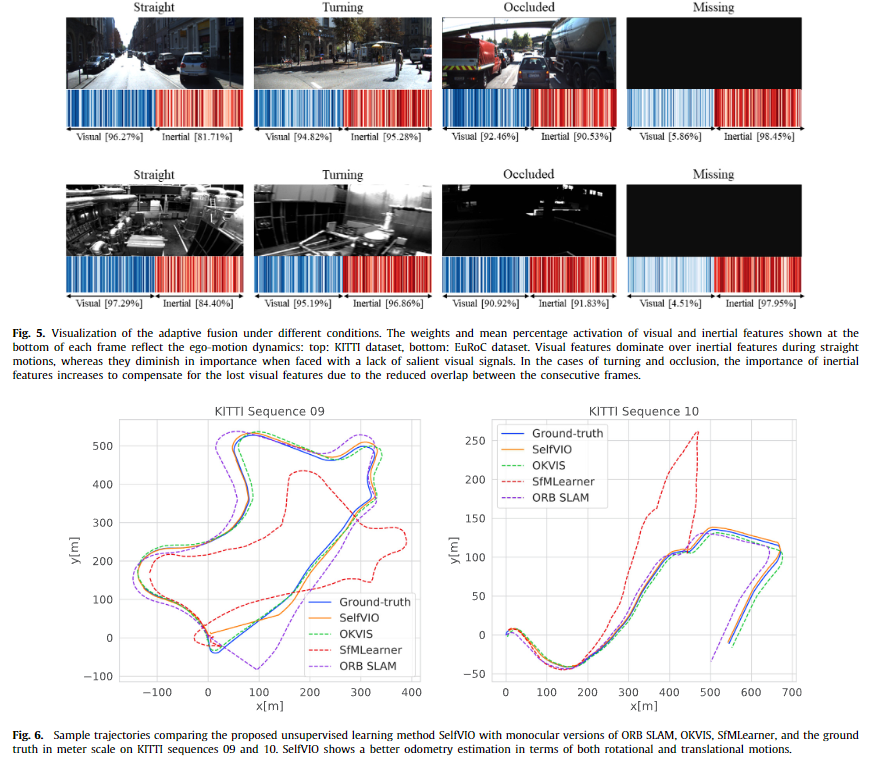
Fig 5에서는 challenge 환경 별 카메라 센서와 IMU 센서의 가중치가 강인하도록 배치되는지에 대한 정성적인 결과 입니다. 보이는 바와 같이 Missing과 Occluded와 같이 영상 정보가 소실되는 경우에 IMU에 가중치가 높아지는 결과를 볼 수 있습니다.
Fig 6은 KITTI seq 09, 10에서의 정성적 결과 입니다. 자기 지도 학습 기반의 방법론인 것에 반해 좋은 결과를 보여주고 있습니다.
해당 방법론을 이해하고 솔직히 든 생각은 MonoDepthV2에서 PoseNet의 결과를 추가적으로 활용한 방법론 같다는 생각이 듭니다. 그래서 리뷰를 하면서 이게 맞나 싶어하면서 읽었습니다. 쨋든 뭔가 불편한 부분이 있는 논문이네요.
리뷰 잘 봤습니다.
리뷰 결론부에서 말씀해주신 것처럼, 그저 monodepth2를 가져다가 Camera pose network의 입력으로 IMU만 하나 더 추가해서 학습시킨 것처럼 보이네요.
게다가 학습 loss도 photometric loss가 아닌, Discriminator를 활용한 GAN loss를 활용하는 것 자체도 자신들의 논문이 차별점이 있다는 것을 보여주기 위한 구색 정도로만 생각이 들고 실제 필요성에 대해서는 의문이 많이 남는 논문인 것 같습니다.