

오늘 리뷰할 논문은 ICLR 2013에 게재된 논문 “Zero-Shot Learning Through Cross-Modal Transfer” 입니다. 거의 10년 전에 나온 논문으로, zero-shot learning 이라는 키워드를 검색했을 때 인용 수가 가장 많은 논문이라 읽게 되었습니다. 이전까지는 video retrieval 관련 논문들을 주로 읽다가 갑자기 zero-shot learning 관련 논문의 리뷰를 하니 조금 의문이 드실 수 있겠습니다만, 결론적으로는 video retrieval 연구를 위해 읽게 되었습니다.
현재 video retrieval 연구를 진행하면서 막혀있던 문제 중 가장 큰 문제는 학습 데이터의 주제의 분포가 너무 넓다는 것 입니다. 이는 video retrieval이라는 연구가 여러 action, scene, causality 등등을 모두 포함하는 event 인식이라는 점에서도 다양한 조합의 event가 표현될 수 있어 비디오 주제의 넓은 분포가 기인되기는 하지만, 학습 데이터로 사용되는 VCDB 라는 데이터 셋의 문제이기도 합니다.
VCDB 데이터 셋은 본래 copy detection 전용 데이터 셋으로, 두 비디오의 이 부분이 유사하다라고 나타내는 annotation을 포함한 core dataset과 아무런 메타 데이터가 없는 background dataset으로 나뉩니다. 여기서 core dataset은 약 400개 정도의 비디오로, background dataset은 약 100,000 개의 비디오로 구성되어있습니다. 이 VCDB는 video retrieval 연구가 딥러닝 기반으로 시작되어가는 시점에 존재하는 비디오 데이터 셋 중 규모가 큰 데이터 셋 중 하나였고, 과거 ECCV 2018에 게재되어 유명해진 ViSiL이라는 video retrieval 연구에서 이 데이터 셋을 학습 데이터로 활용하였기에, 이후 연구들은 공정한 비교를 위해 이 데이터 셋으로 학습하는 절차를 거치곤 했습니다.
주로 retrieval 연구에서는 class가 분명하게 나눠져 있지 않은 상황을 가정하기에 한 데이터를 기준으로 유사도를 계산하게 되고, 이를 학습시키기 위해 임의로 triplet 혹은 positive pair를 생성하게 됩니다. 여기서 triplet은 기준이 되는 데이터 인 anchor, 이와 유사한 데이터라고 선별한 positive, 유사하지 않은 데이터라고 선별한 negative로 구성됩니다. 때문에 triplet을 두고 학습을 하든 혹은 positive pair만을 두고 학습을 하든 결국 유사한 관계에 놓인 positive pair가 필요하게 됩니다. 그리고 이 positive pair가 모델의 인식 성능을 높이는 데 있어 가장 큰 영향을 미치는 것으로 알려져 있습니다.
Video retrieval 분야에서는 앞서 언급했듯, 이 VCDB 데이터 셋에서 만들어진 positive pair로 모델 학습의 절차를 거치게 되는데, copy detection 데이터 셋이라는 특성 상 만들 수 있는 positive pair는 주로 거의 동일한 scene을 포함하는 비디오 pair 밖에 존재하지 않게 됩니다. 또한, triplet 학습 시 negative로는 아무런 정보가 없이 모인 background video를 활용하게 되는데, core dataset과 background dataset의 비디오 수에는 큰 차이가 있어 전자의 경우 만들 수 있는 조합이 적기 때문에 모델로 하여금 쉽게 positive를 찾아낼 수 있게 하여 학습 데이터 셋에 overfitting 된다는 문제점이 존재하게 됩니다. 실제로 다른 video retrieval 방법론들의 코드를 돌렸을 때도 이 같은 경향을 볼 수 있었고, feature를 직접적으로 projection하는 layer가 많을 수록 더 overfitting 되는 것을 확인했었습니다. 또한 반대로 overfitting이 되지 않는 경우 대부분은 많이 underfitting 되는 경우였습니다. 예를 들어, backbone network에서 A라는 feature를 projection 시켜 B라는 feature로 만들어 평가했을 때 (backbone의 경우 backward 없이 pretrain 사용) 학습 과정 중간중간 validation 성능으로 보면 향상이 있는 것 같지만, 사실을 학습되지 않는 A feature보다 못한 성능을 내고 있던 경우도 있었습니다.
서두가 조금 길었는데, 여튼 이러한 video retrieval 연구의 학습 데이터 문제를 해결하기 위해 한동안 여러 방향을 서베이 했었고 그러던 와중 zero-shot learning에 대해 눈길이 가서 이번 리뷰를 진행하게 되었습니다. Zero-shot learning이라는 단어는 이전부터 알고 있었지만, 관심이 없어 정확히 의미하는 바는 알지 못했었으나 이번 기회를 알게 되었는데, 이 논문에 따르면 한번도 보지 못한 데이터 (zero-shot)를 인식하는 분야라고 합니다. 기존 video retrieval의 문제점으로 여겨지는 overfitting은 결국 학습 과정에서 본 데이터에만 편향되는 현상이기 때문에, 이러한 zero-shot learning의 컨셉으로부터 실마리를 얻고자 합니다.
본 논문은 이전 논문들이 unseen 데이터들만 구별 가능했던 것과는 달리 seen 데이터도 동시에 구별 가능한 방법을 소개하며, 이를 위해 word의 distribution으로부터 image representation을 생성합니다. 자세한 내용은 아래서 설명드리도록 하겠습니다.
1. Word and Image Representations
본 논문에서 소개하는 방법은 이전 연구들이 제안한 word representation과 image representation 으로부터 시작됩니다. word representation으로는 unsupervised 기반으로 특정 길이 window 내 local context와 global document context를 활용하는 방식을 사용하며, 이는 흔히 GloVe라고도 알려진 방법입니다. 그리고 image representation으로는 본 논문의 교신저자님께서 이전에 쓰셨던 논문 중 vector quantization 관련 방법이 활용되었는데, 이 방식은 자세히 설명되어 있지는 않아 관심이 있으신 분은 [링크] 를 통해 확인해주시길 바랍니다.
2. Projecting Images into Semantic Word Spaces
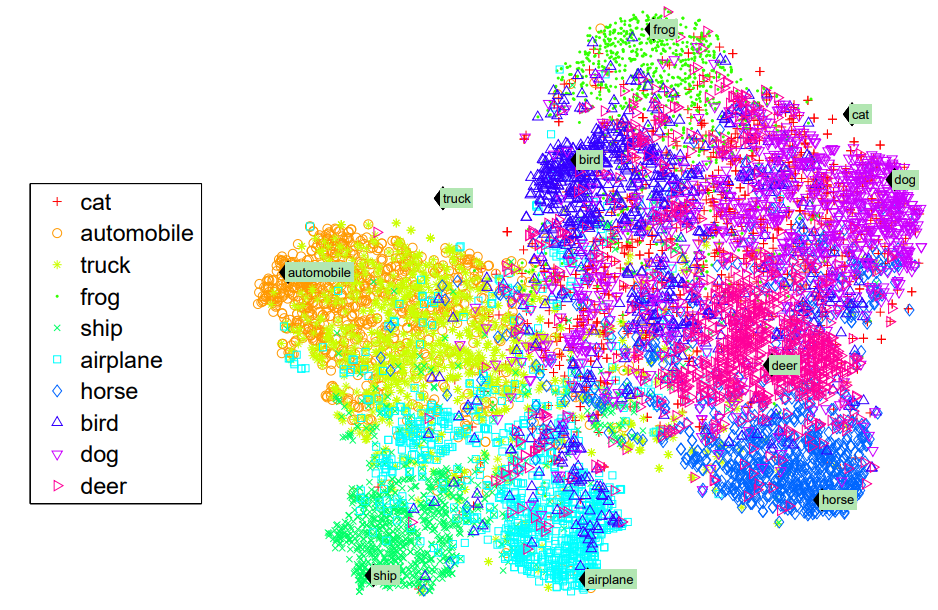
두번째 과정으로는 앞선 Image representation을 word representation이 존재하는 word space로 projection하는 과정을 거치게 됩니다. 이는 해결하고자 하는 문제가 image에 대한 zero-shot learning인 이유로 당연히 image representation에 특정 과정을 거치는 것이기도 하지만, word representation이 대용량의 text corpora에서 unsupervised 기반으로 학습이 되었기에 semantic한 특징을 잘 파악하기 때문입니다.
Projection을 위해 우선 Y 개의 class가 있는 데이터 셋에서 class 기준으로 seen 데이터와 unseeen 데이터가 나누어졌습니다. 여기서 seen 데이터에서만 학습이 진행되며, 평가 시에서는 두 종류 데이터 모두에서 진행됩니다.
Image representation을 word space로 projection 시키기 위해 두 개의 FC layer를 통과시켜 word representation과 동일한 dimension을 갖게 합니다. 그리고 각 이미지에 해당 되는 word representation과의 L2 Loss를 통해 projection된 image representation이 word에 가까워지도록 학습시킵니다.
이러한 과정으로 학습된 모델의 seen 과 unseen 데이터에 대한 평가 결과는 Fig 2와 같습니다. 여기서 cat과 truck이 unseen 데이터에 해당하며 나머지는 seen 데이터에 해당합니다. 이 결과를 통해 대부분의 seen 데이터들은 word를 중심으로 잘 cluster되어 있지만, unseen 데이터들은 전혀 그러지 못하고 있다는 것을 알 수 있습니다. 다만, 논문의 저자에게 가장 아이디어를 주었던 점은, unseen 데이터의 image representation이 semantic하게 유사한 class와 가까운 위치에 놓여있다는 것이며, cat의 경우 dog나 horse에 가깝고 car나 ship이랑은 멀게 놓여진 것에서 이를 확인할 수 있습니다.
3. Zero-Shot Learning Model
3.1. Strategies for Novelty Detection
일반적인 classifier는 학습 때 존재하지 않던 class에 대해 예측할 수 없기에, classifier를 통한 결과를 산출해내기에 앞서 먼저 입력 데이터가 seen 데이터 인지 unseen 데이터 인지 판별하는 과정을 먼저 거치게 됩니다. 여기서 Seen 데이터 인지 unseen 데이터 인지 판별하는 것은 novelty라고 불리웁니다. Novelty를 판별하기 위해, 저자는 앞선 섹션에서 소개했던 아이디어로부터 착안하여 unseen class의 이미지가 비록 학습 데이터와는 다르지만 semantic하게 연관된 seen class와는 가까울 것이라는 가정을 두고 두 종류의 outlier detection으로 접근하였습니다.
첫번째 방식은 isometric, class-specific Gaussian 방식입니다. 여기서 isometric이란 동일하게 측정되는 이라는 의미로 특정 원형 region을 설명하기 위해 사용된 것으로 보입니다. 그리고 class-specific하다는 명칭과 같이, 각 class 마다의 word reprensentation을 기준으로 이 feature의 평균과 이 word label에 할당된 데이터들의 공분산으로부터 class 별 Gaussian을 표현하는 방식입니다. 이렇게 표현된 Gaussian 확률 분포에 대해 일정 threshold보다 낮은 경우 outlier로 선정하는 간단한 방식으로, threshold의 경우 실험 부분에서 다루도록하겠습니다.
두번재 방식은 특정 데이터가 실제로 outlier인 확률을 알 수 없다는 첫번째 단점을 보완하고자 unsupervised 기반으로 outlier 확률을 판단하는 LoOP [논문]을 차용하였습니다. 이 방식은 seen class와 unseen class 사이의 weighted combination으로 조건부 확률을 구하는 방식이며, 특정 데이터 포인트에 대해 k 개의 nearest neighbor를 구한 뒤 이들 간의 probabilistic set distance를 계산하여 outlier일 확률을 도출해내는 방식입니다.
3.2. Classification
앞선 두 종류의 detection 방식을 각각 사용했을 때, seen 데이터로 판별될 경우, image representation에 softmax가 사용되어 class를 추론합니다. 반대로 unseen 데이터로 판별될 경우, 그 데이터를 중심으로 isometric Gaussian 분포를 추정하여 새로운 class가 할당됩니다.
4. Experiments
4.1. Seen and Unseen Classes Separately
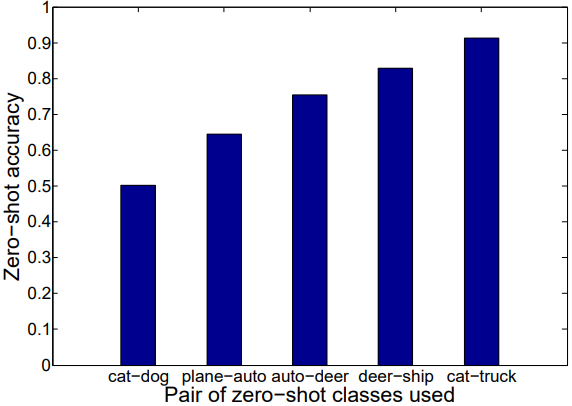
실험은 CIFAR-10에서 진행되었으며, Fig 3은 unseen으로 구분한 class pair 별 zero-shot accuracy를 나타냅니다. 이는 이전 설명드렸던 내용 중 저자에게 아이디어를 주었다는 부분으로부터 둔 가정인 “unseen class의 이미지가 비록 학습 데이터와는 다르지만 semantic하게 연관된 seen class와는 가까울 것”을 확인하기 위한 실험입니다. Unseen class는 두 개로 두고 실험되었으며, 그림에서 볼 수 있듯이 cat-truct 혹은 deer-ship 처럼 전혀 다른 두 class가 unseen class로 선택되었을 때 가장 높은 정확도를 나타냈습니다. 반면 cat-dog의 경우 가장 낮은 성능을 보였는데, 이는 zero-shot learning에서 seen 데이터에 dog과 같이 (cat이 unseen임을 가정) 의미론적으로 유사한 class 가 있는 것이 성능에 영향을 많이 끼치는 것을 의미하며, cat-dog일 경우는 서로 유사한 class가 unseen으로 선별되어 seen 데이터에는 이 class들과 유사하지 않은 class의 비중이 커져 낮은 성능을 보이는 것으로 분석되었습니다.
4.2. Influence of Novelty Detectors on Average Accuracy
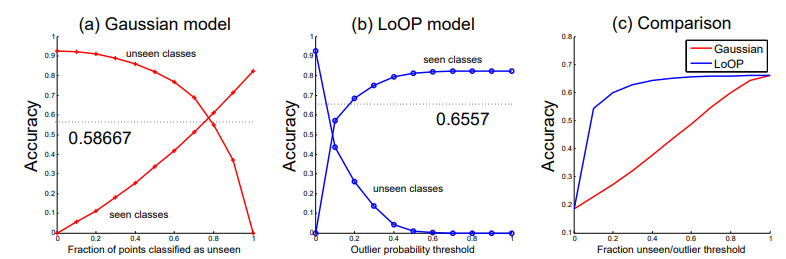
Fig 4는 두 종류의 novelty detection 방식에 대한 비교입니다. (a)와 (b) 모두 왼쪽으로 갈수록 더 많은 이미지를 unseen 데이터로 여기며, 반대의 경우 seen 데이터의 비중이 높아지게 됩니다. 중간에서는 서로 다른 경향세로 seen과 unseen에 대한 accuracy가 나타나며, 이는 (a)의 경우 (b)보다 unseen 데이터를 지정하는 데 일정 threshold만 넘기면 되는 자유로움이 있기에 unseen 데이터의 비중이 높아졌기 때문이라고 합니다. (c)는 이 둘에 대한 전반적인 평균 accuracy를 의미합니다.
4.3. Extension to CIFAR-100 and Analysis of Deep Semantic Mapping
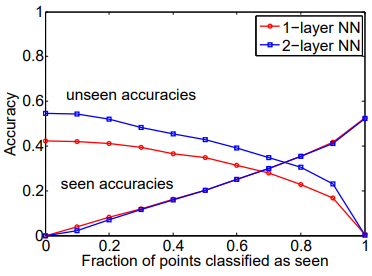
Fig 5는 CIFAR-10에서만 진행하던 기존 실험을 CIFAR-100으로 확장시켰을 때, projection을 위해 사용되는 FC Layer 수에 관한 성능 비교입니다. CIFAR-100에서 ‘forest’, ‘lobster’, ‘orange’, ‘boy’, ‘truck’, ‘cat’ class가 unseen class로 선별되었으며, FC layer가 좀 더 dense 해졌을 때 높은 성능을 보였다고 합니다.
5. Reference
[1] https://arxiv.org/abs/1301.3666
[2] https://nlp.stanford.edu/~socherr/SocherGanjooManningNg_NIPS2013.pdf