갑자기 멀티모달을 왜 읽었느냐….에 대해서는 이번에는 감정인식 때문은 아니고요. 네이버 쇼핑에서 데이터를 수집해서 논문을 쓰고있는데… 갑자기 네이버 쇼핑에서 멀티모달로 무엇인가를 하는 논문을 냈다고 홍보하는 네이버 쇼핑 개발 블로그의 글이 보이더라고요 ㅎㅎ… 다행이 저랑 겹치지는 않는데 그래도 혹시 몰라서 읽어두려고… 가져왔습니다.
CLIP?
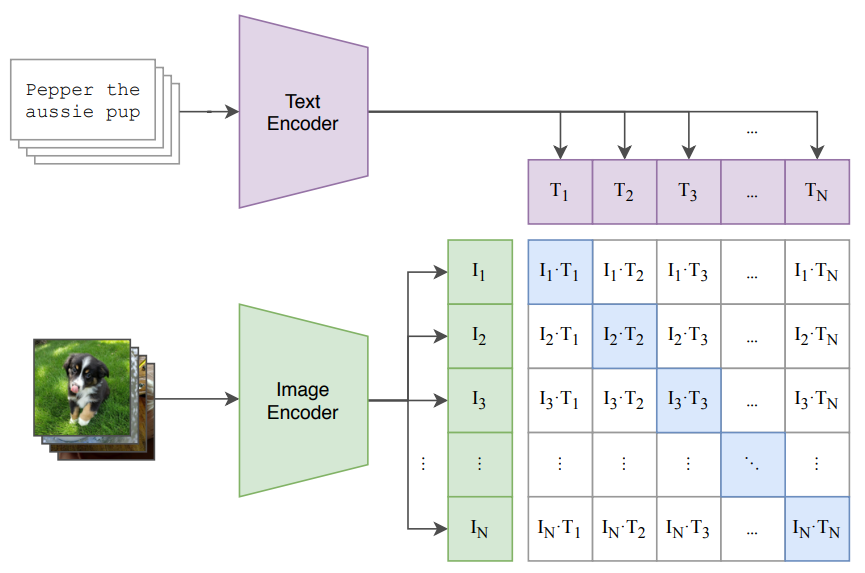
CLIP은 텍스트와 이미지를 이용하는 멀티모달 학습 방법론입니다. 대표적으로 위의 그림으로 설명할 수 있는데요. 기본적으로 학습에서 이미지와 텍스트 쌍을 이용한 contrastive learning을 합니다. 배치 단위의 학습을 수행할 때 배치 크기가 N이라면 N*N개의 이미지-텍스트 페어를 만들고, Cross-Entropy Loss로 Positive Pair(그림의 파란색 영역으로, 올바르게 매칭된 페어)는 가깝게 Negative Pair는 멀어지게 학습을 합니다.
여기서 Text Encoder는 Transformer를 고정하고 Image Encoder는 여러가지(Resnet, ViT 등등)를 사용합니다. 그래서 뭐… 이미지랑 텍스트랑 같은 embedding space에 위치하면서도 위와 같은 학습 방식으로 잘 학습을 했다 정도로 보면 될 것 같습니다.
그리고 또 하나의 특이점은 이미지에 대한 정확한 라벨?이 존재하는 것이 아니라 이미지를 설명하는 문장이 존재합니다. 위의 예시 그림처럼 강아지 이미지가 있다면, 어떤 강아지라는 GT가 존재하는 것이 아니라, “Pepper the aussie pup”와 같은 캡션이 존재하고 이를 통해서 학습을 수행합니다. (캡션-이미지 데이터는 쉽게 구할 수 있어서, 대용량 데이터셋을 구축해서 학습을 돌리면 모델이 강아지 그림과 pepper라는 단어를 추론하는 방향으로 학습됨)
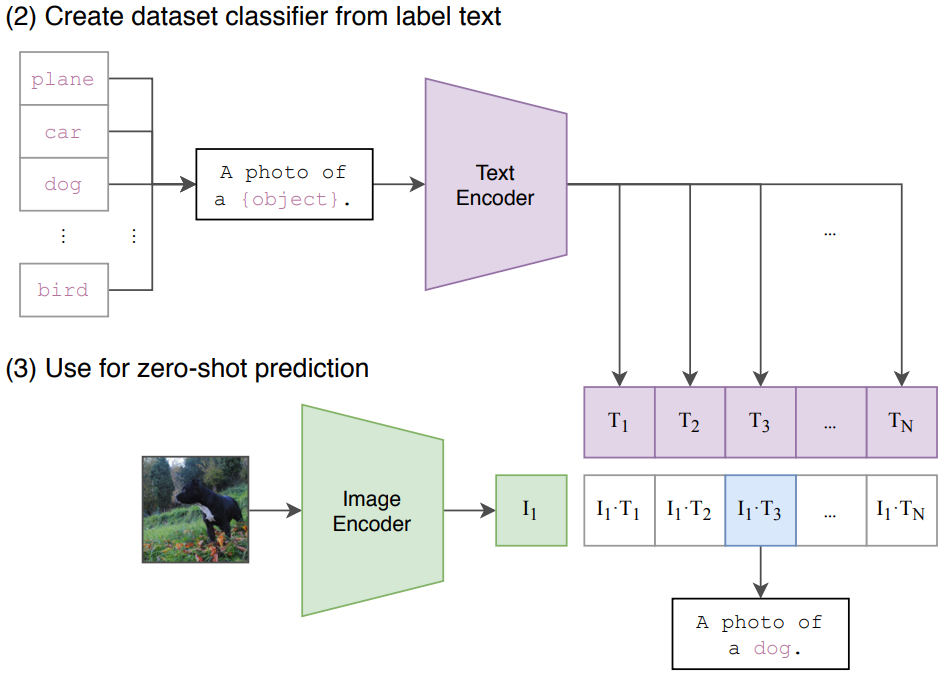
또 이런 특성으로 인해서 Zero-Shot prediction의 성능이 다른 방법론에 비해 상당히 높다는 생각이 있습니다. 처음 보는 물체가 포함된 이미지를 넣어도 전체적으로 어떤 class가 존재하는지만 알고 있다면, 이미지에 대한 예측을 수행할 때 모든 class에 대한 확률을 다 계산하고 가장 높은 확률을 보이는 값을 선정하는 방식입니다. 다른 모델들도 이렇게 할수는 있지 않냐 싶겠지만, 학습할때 캡션으로 학습하는 특성 때문에 CLIP에서 성능이 매우 높게 나옵니다.
Introduction
논문에 CLIP에 대한 내용은 없어서 압축 정리를 위에 했는데요. 이 CLIP을 네이버 쇼핑에서는 E-commerce에 결합하여 활용할 수 있도록 약간의 수정을 했습니다. 일단 여러 문제점을 제시하는데 e-commerce에 CLIP을 적용했을 때 발생하는 문제점만 정리를 조금 해보면 아래와 같습니다.
- 데이터에 노이즈가 많을 수 있음
- 같은 상품이 서로 다른 판매자에 의해 똑같이 올라와짐
- 상품 텍스트가 문법적으로 의미가 있는 문장이 아니거나, 제품 코드와 같이 의미 없는 단어가 포함됨
따라서 네이버 쇼핑의 데이터를 활용한 e-CLIP 제안합니다. Contibution으로는 아래와 같습니다.
- 최초의 대칭형 unified multimodal transformer model
- 중복 제품이 존재하는 상황에서 잘 작동하는 e-CLIP
- 5개의 downstream task에 대한 풍부한 실험과 증명
- Online 측면과 Offline 측면 모두 실험을 수행함
- 이미 산업에 적용되고 있음
SYSTEM ARCHITECTURE
Pre-training Method: e-CLIP
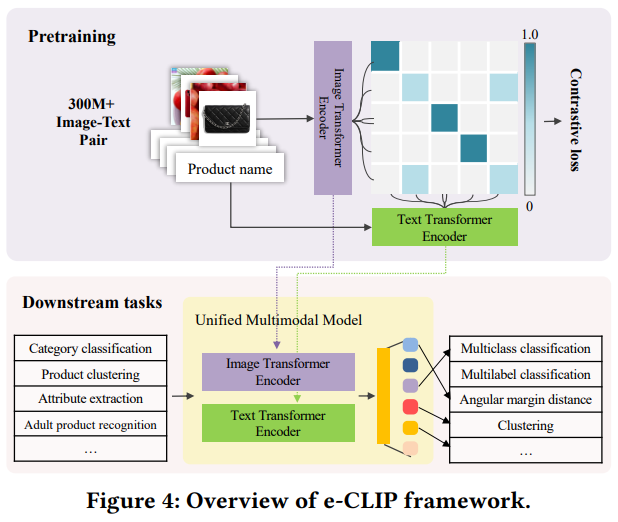
사실 위의 그림만 보면, CLIP과 달라진 부분이 무엇일까 싶을 수 있는데요. 잘 보시면 CLIP의 유사도 맵과 다르게 유사도 맵이 직선이 아닌 것을 볼 수 있습니다. 즉, 이미지에 대응되는 텍스트가 여러개일 수 있게 됩니다. 이 부분이 e-commerce 데이터셋의 학습에서 문제가 됩니다.
기존의 CrossEntropy Loss를 사용하는 CLIP의 관점에서 A 이미지에 대응되는 B 텍스트만 존재할 수 있습니다. 하지만 e-commerce 데이터셋을 사용하게 되면 A 이미지에 대응되는 C 텍스트도 존재할 수 있고, 이러한 데이터가 많을 수 있습니다. 그래서 네이버 쇼핑에서는 catalog-based soft labeling이라고 InfoNCE Loss를 기반으로 수정한 Loss를 통해 Contrasitve Learning을 수행합니다.
일단 CLIP과 동일하게 배치 단위 학습을 수행하는데요. 입력이 들어왔을 경우에 catalog_id를 기반으로 배치 내에서 동일한 상품이 있는지를 확인할 수 있습니다. 그래서 이 동일한 상품의 갯수에 따라서 \tilde{z}<em>{ij} = 1 / |{j \leq N : c</em>{id}[i] = c_{id}[j]}|로 soft label을 생성합니다. (Z는 위의 그림의 유사도 맵, ij는 각각 이미지와 텍스트 데이터, c_{id}는 catalog id) 그러니까 예를 들어서 배치 내에서 A개의 동일 상품이 있으면 그 A개의 상품에 대한 라벨링은 CLIP이라면 0아니면 1이었지만, e-CLIP에서는 1/A로 지정됩니다.
저도 동일한 플랫폼에서 ㅎㅎ;; 데이터셋을 수집을 좀 해본 결과, 아무리 세부 카테고리를 기준으로 분류를 해도 동일한 물체가 나온다는 보장이 없어서 결국은 수동으로 많이 고쳤는데요. 따라서 이 catalog_id 자체가 정확할 수 없는데 이 학습 방법론이 정확하게 작동하나 싶었는데요. 이 부분은 기존에 내부적으로 사용하고 있던 동일 상품을 확인하는 모델을 통해서 분류되는 예측값을 사용한다고 하네요.
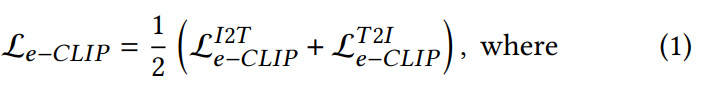
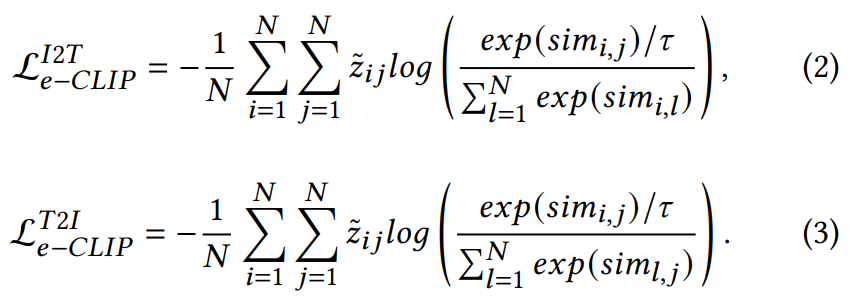
그래서 최종적으로는 위와 같은 Loss를 가지게 됩니다.
그리고 추가적으로 성능을 올리기 위해서 category-based negative sampling이라는 이름으로 negative sample을 선정하는 방법도 적용할 수 있다고 합니다. 이건 이제 쇼핑몰의 카테고리를 생각해보면 되는데요. 쇼핑몰에서 대분류/중분류/소분류/세분류로 상품을 분류하고 있는데, 그럼 같은 카테고리의 물품이라면 아무래도 비슷한 특성을 공유하면서도 이 차이점을 잘 학습해야 성능이 오르겠죠? 이런 논리에 따라서 학습이 어느정도 진행되고 나서 부터는 카테고리 기반으로 어려운 negative 들을 골라서 학습을 수행합니다.
EXPERIMENTS
실험 설명하기 전에, 이렇게 학습을 해서 어디에 쓸 수 있는지. downstream task에 대해서 간단하게 알아봅시다. 일단 5가지에 대한 실험을 수행했는데요. Product Clustering / Product Matching / Attribute Extraction / Category Classification / Adult Product Recognition 입니다. 실험은 다 있는데 분류와 관련있어 보이는 Product Matching / Product Clustering / Category Classification 위주로 설명하겠습니다.
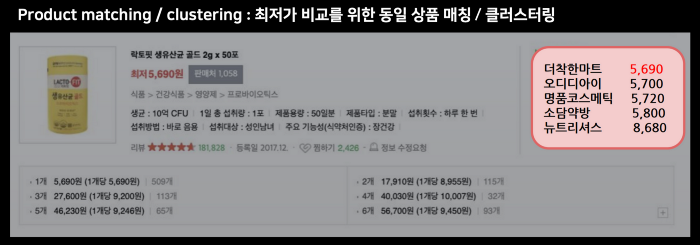
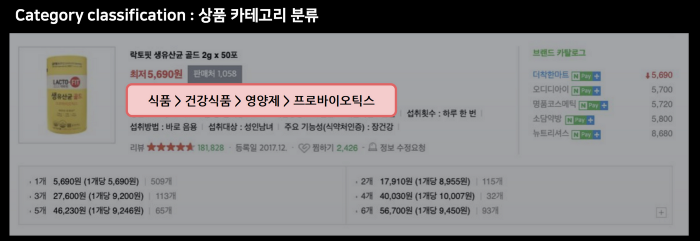
(참고로 위와 같은 task입니다. 마침 블로그에도 예시가 있어서 가져왔습니다.)
또 성능을 보려면 모델을 알아야 비교가 가능하죠? 제안하는 방법론 e-CLIP에 대해서도 3가지 종류가 존재하는데요. 차이점은 아래와 같습니다.
- e-CLIP : 네이버 쇼핑 데이터셋을 사용한 베이스라인 모델
- e-CLIP (filter) : 위의 모델에서 데이터셋을 사용할 때, 중복 데이터셋을 제거해서 330M개의 데이터 중에서 270M개만 사용한 모델
- e-CLIP (hard) : 330M개의 데이터를 사용하되, category-based negative sampling을 적용해본 모델
비교군으로는 멀티모달 방법론들인데, KELIP와 e-LiT의 경우에는 네이버 쇼핑 데이터셋이 포함된 데이터셋으로 사전학습 된 상태입니다.
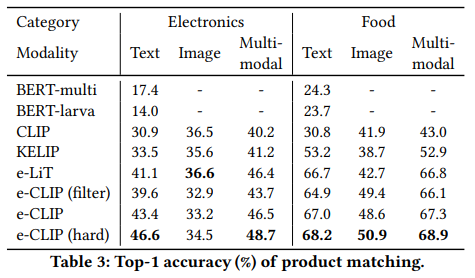
이러한 점에서 product matching에서 e-CLIP의 성능이 높은 것을 볼 수 있습니다. 텍스트 보다 이미지가 낮은 이유는 사실 GPU 종류는 겉모습만 보면 모르고, TV도 겉모습만 보면 몰라서 이런 상품들의 경우에는 텍스트 정보가 중요합니다. 그리고 베이스라인 방법론인 CLIP과 비교해도 성능이 높고, 네이버 쇼핑 상품에 관한 데이터가 포함된 KELIP나 e-LiT와 비교해도 성능이 높다는 두 부분을 모두 감안하면 e-CLIP이 잘 작동했음을 보입니다.
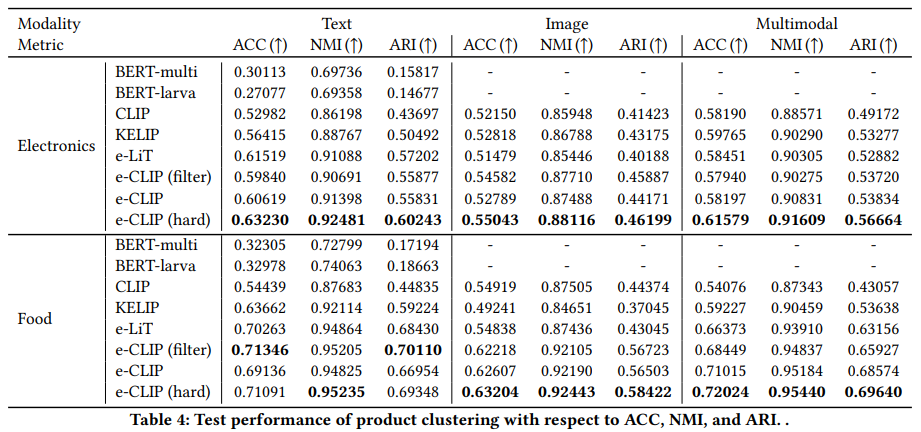
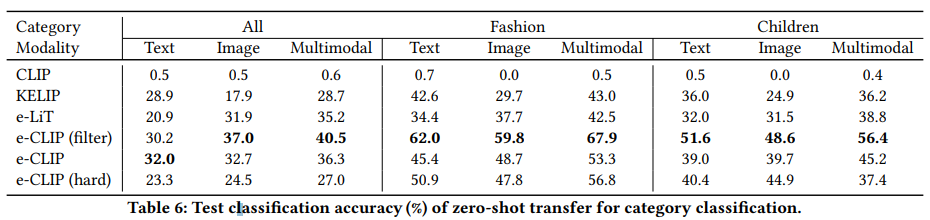
나머지 clustering과 classification에서도 비슷한 경향성을 보입니다. 특히나 새로운 상품이 등장할 수 있는 쇼핑몰의 특성상 zero-shot transfer 성능이 중요한데요. 여기서도 기존 방법론 대비 높은 성능을 보이는 것을 알 수 있습니다.
안녕하세요 좋은 리뷰 감사합니다.
캡션형식의 label을 이용한 학습에서는 foreground, background 에 대한 context 분류를 하려는 접근이나 관련된 이슈가 있는지 궁금하네요 ㅎㅎ 혹시 이광진 연구원님은 어떻게 생각하시나요?
리뷰에 대해서 질문은 Zero-Shot prediction에서 학습할때 캡션으로 학습하는 특성 때문에 CLIP에서 성능이 매우 높다고 하셨는데, 해당 학습법이 feature representation 능력을 키워서 인지 아니면 두 테스크간의 연관성이 있기 때문인지 궁금합니다. 후자라면 제가 이해를 잘 못한듯 하네요..
이상입니다 다시한번 감사합니다 ㅎㅎ
딱히 이슈는 없는데, 데이터가 많아야 가능한 방법인 것 같긴 합니다. CLIP도 결국은 데이터셋이 작아서 따로 수집한 데이터셋으로 학습시키니까요. zero-shot prediction에서 성능이 높은 이유는 feature representation이 향상되서라고 보는게 맞는 것 같습니다.
안녕하세요. 좋은 리뷰 감사합니다.
e-clip 부분을 읽으면서 궁금한 점이 있어 질문합니다.
유사도 맵 이미지가 나와있는 부분에서 이미지에 대응되는 텍스트가 여러개인 것이 문제가 된다고 하였는데 왜 문제가 되는 것일까요….? 1대1 대응이 아니면 모델이 학습하기 힘들어서 때문일까요..?
아직 공부가 부족해서 때문인지 굉장히 허접한 질문을 드려 죄송합니다ㅜ
감사합니다.
Contrastive learning에서 Poisitive의 distance는 작아지고, Negative의 distance는 커지게 학습을 수행합니다. CLIP에서의 Positive는 이미지 A에 대응되는 텍스트 A 하나고, Negative는 나머지 페어 전부입니다. 만약 이미지 A에 대응되는 텍스트 B가 존재한다면, 실제로는 Positive지만 Negative에 포함되어 학습되게 되어 distance가 커지는 것에 한계가 있습니다. 그래서 문제입니다.