저 역시 이광진 연구원과 마찬가지로 기존에 리뷰하지 않던 “음성 도메인”의 논문을 읽어봤습니다. 해당 논문은 감정인식 과제 중 1차년도 베이스라인으로 선정한 논문입니다. 해당 논문은 음성 감정인식에서의 노이즈를 생성시키는 연구로, 해당 컨셉을 계속 생각하면서 리뷰를 읽으시면 도움이 될 것 같습니다.
Introduction
음성 감정인식 연구가 활발하게 진행되고 있으나, 대부분의 연구는 클린한 음성 데이터를 기반으로 최적화되어 있습니다. 그렇다보니 잡음이 많은 현실적인 환경에서는 성능이 저하될 수 밖에 없습니다.
본 논문에서는 데이터에 노이즈를 추가하는 multi-conditioned & data augmentation의 일종으로 “노이즈 생성 모델” 을 제안합니다. 즉, 기존에 있던 깨끗한 데이터에 노이즈를 추가하는 모델을 제안한 것입니다. 이를 통해 real 한 음성 감정 인식이 가능할 것이다 라는 것이 해당 논문의 메인 아이디어가 되겠습니다.
Multi-conditioning for Robust Speech Emotion Recognition
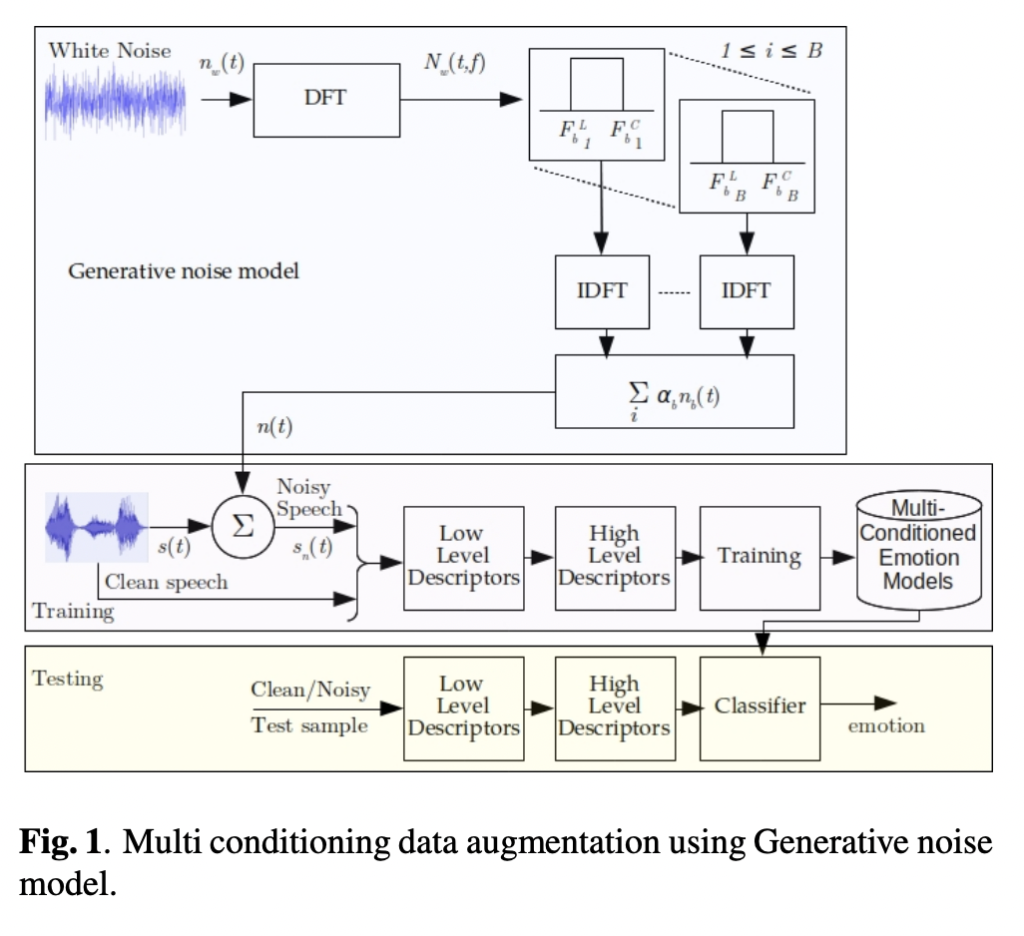
상단 그림의 바로 논문에서 제안하는 multi-conditioning 감정 모델에 대한 전반적인 그림입니다. 즉, 생성 노이즈 모델을 사용한 multi-conditioning data augmentation 방법론이죠.
1) Modeling using Generative noises
- (1) Generative model for noise
결국 해당 논문의 메인이 되는 아이디어가 바로 “노이즈를 생성하여 데이터를 합성하느냐” 입니다. 따라서 지금부터는 저자가 노이즈 생성 모델을 어떻게 설계하였는지 서술하겠습니다.
우선, 저자는 이 생성 모델을 설계하기 위해, MFBE(Mel-Filter Bank Energy)를 고려하였습니다. 이 때, MFEB는 overlapping triangular filterbank(TFB)를 사용하여 Short-time Fourier Transform(STFT)의 magnitude를 필터링하여 계산됩니다.
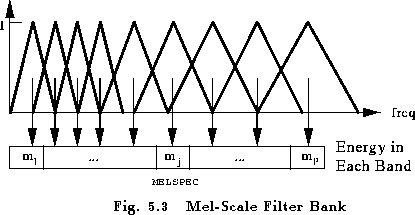
상단 그림이 Mel-scale filter bank 이며, 그림 출처는 다음과 같습니다 – https://labrosa.ee.columbia.edu/doc/HTKBook21/node54.html
(해당 내용은 음성 데이터의 피처를 추출하는 데 흔히 사용되는 기법입니다. 신호 처리의 기술이 집약적으로 사용되는 분야답게 푸리에 변환이 사용되는 데요. 일단 간단하게 푸리에 변환을 일정 윈도우 단위로 수행한 specturm을 사용하였다 정도로 이해하시면 좋을 듯 합니다)
저자는 생성 모델을 위해 magnitude of TFB filter를 두 부분으로 분리하였습니다. 이를 통해 왼쪽은 입력 신호의 전반부부을 커버하고, 오른쪽 부분이 나머지 부분을 커버하게 됩니다. 저자가 변형한 TFB 필터를 수식적으로 나타내면 아래와 같습니다.
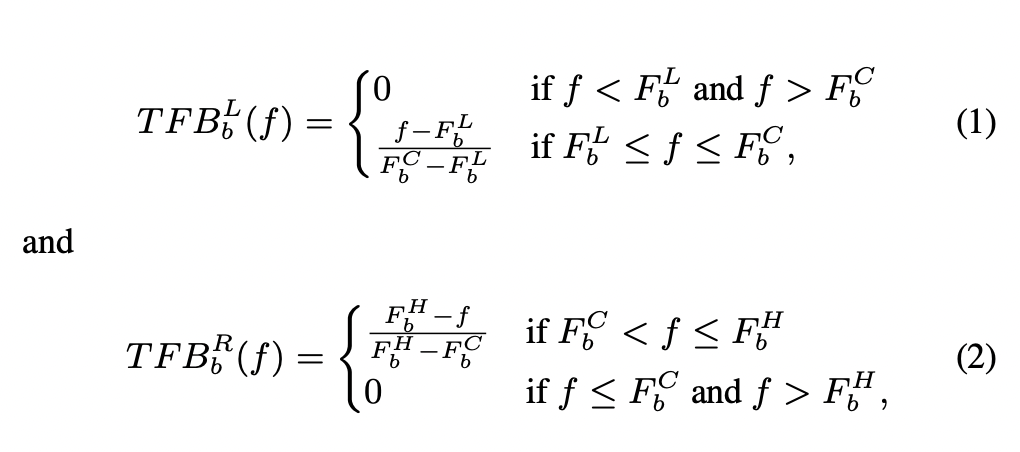
다시말해 TFB_b^L(f), TFB_b^R(f)은 각각 b_th번째 필터에 대한 주파수 응답인 것이죠. 그리고 F_L^b , F_C^b , F_H^b는 각각 lower, center, higher frequency of b th filter in TFB 를 의미합니다.
이제 앞서 정의한 신호에 따라 n_b(t)의 magnitude of STFT에 대한 대역 제한은 다음과 같이 설계하였다고 합니다.
(참고로, band-limited 대역제한이란 특정 유한 주파수 이상 에서 신호의 주파수 영역 표현 또는 스펙트럼 밀도 를 0으로 제한하는 것입니다. 말이 어렵지 특정 고주파 및 저주파 대역을 0으로 만들어 버려, 일정 주파수 대역에만 제한하는 것입니다.)
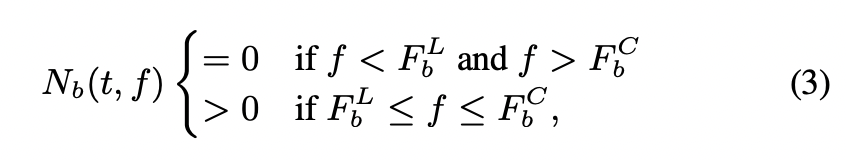
(3)번 수식에서 N_b(t, f)는 signal n_b(t)의 STFT magnitude 입니다. (3)번 수식을 통해 신호 n_b(t)는 F_b^L ~ F_b^C사이로 제한되는 것을 알 수 있습니다.
따라서 이렇게 정의된 신호에 따라 TFB 각 필터의 에너지는 다음과 같이 재정의됩니다.
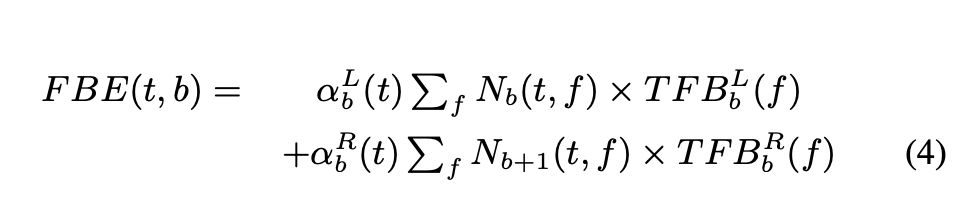
여기서 FBE(t, b)는 신호의 t번째 프레임에 대한 b번째 필터 뱅크의 에너지입니다.
결국 (4)번 수식에 따라, 각 대역의 에너지는 서로 다른 N_b(t, f)와 그 dot product과 TFB 필터 반응의 선형 결합 n(t)으로 구성된다고 해석할 수 있습니다.
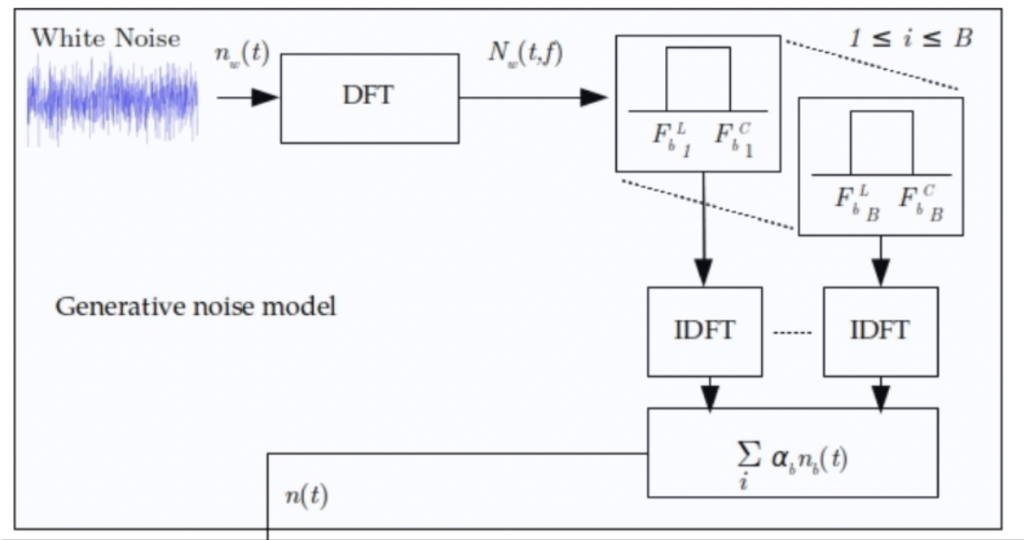
즉, (4)번 수식을 통해 노이즈 생성 모델이 완성되는 것입니다. 이를 다시 아래 그림을 통해 정리해보면 다음과 같습니다:
- white noise의 입력 신호 n_b(t)를 STFT를 이용하여 N_b(t,f)로 변환합니다.
- 신호의 앞부분과 뒷부분을 나눠 TFB 필터를 태운 뒤, 선형결합으로 노이즈 샘플n(t) 을 생성하게 됩니다.
- (2) Noise sampling from the Generative model
여기서부터는 앞서 정의한 생성 모델을 사용하여 노이즈를 샘플링하는 방식에 대해 서술하겠습니다.
앞서 정의한 노이즈 생성 모델로 저자는 실험에 24개의 노이즈 베이스를 사용하였습니다. 그러니까 24개의 화이트 노이즈 (백색 소음)이 있는 것이죠.
이렇게 구해진 노이즈 샘플을 클린한 스피치에 포함시켜 생성한 노이즈를 set_C라고 하였습니다.
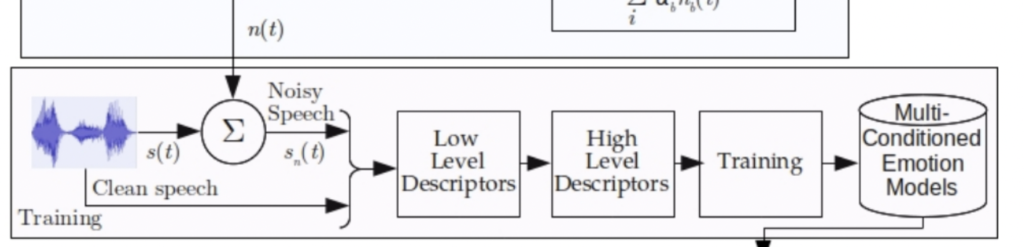
Multi-Conditioning using recoded noises
이제 NOISE-92 데이터셋에 녹음된 노이즈를 사용하여 깨끗한 발화를 손상시키는 과정에 대해 서술합니다.
총 9가지의 노이즈가 있으며 set_A에는 5가지(1:Voice Babble, 2:Factory noise, 3:HF radio channel, 4:F-16 fighter jets, and 5:Volvo 340) 의 노이즈가 포함됩니다.
그리고 나머지 4가지의 노이즈는 set_B(1:Bucaneer, 2:Machine gun, 3:Destroyer ops, 4:Destroyer engine)에 포함되며 학습에는 사용되지 않는 unseen 으로 설정하였습니다.
Experiments
Dataset
본 논문에서는 두 개의 데이터셋을 사용하였습니다.
- Berlin Emotional Database (Emo-DB) : 상당히 깨끗한 환경에서 수집된 535개의 연기된 발언으로 구성된 데이터셋
- Interactive Emotional Dyadic Motion Capture Database (IEMOCAP): 스크립트로 작성된 두 개의 녹음 데이터셋. 두 개의 데이터셋 중 하나는 참가자들이 외운 대본을 리허설하는 방식으로, 나머지 하나는 특정 감정을 끌어내기 위해 설정된 몇 가지 가상 상황을 즉흥적으 만들어 수집되었다는 특징을 가집니다.
Data Augmentation
저는 이 부분을 읽고 띠용 (?) 했는데요…. 데이터셋으로 80%를 학습에 20% 테스트에 사용하였다고 적혀있습니다. 그래도 과적합을
Noisex-92의 경우, set_A 노이즈로 깨끗한 음성을 corrupt 시키고, 생성 노이즈의 경우 set_C로 멀티 컨디셔닝하여 각각 5 SNR 수준(0dB, 5dB, 10dB, 15dB, 20dB)에서 훈련 데이터를 25배 증가시켰다고 합니다. 이 때, Kaldi 를 사용하여 깨끗한 음성을 노이즈를 포함시키도록 사용하였다고 하네요.
Model training
감정 인식 즉 분류를 위해 DNN을 사용하였는데요. 총 3개의 모델을 학습시켰다고 합니다. (1) 먼저, 깨끗한 샘플로만 학습한 모델로 두개의 데이터셋에 대한 베이스라인을 설정하였습니다. (2) Clean+[Augmented speech with Noisex-92] and Clean+[Augmented speech with Generative model] 두개의 모델을 각각 학습시켰습니다. 즉, 기존 노이즈를 추가하는 방식과 저자가 제안하는 생성 모델을 사용하는 방식을 비교하기 위해 setA, B vs C로 모델을 각각 학습시킨 것이라고 볼 수 있습니다.
Results and analysis
하단의 그림 2(a)가 바로 보이지 않는 소음 조건인 set_B에 대한 EmoDB의 다양한 augmentation fold 에서 달성된 정확도를 보여주는 데요. NOISEX-92 데이터를 사용한 augmentation의 경우, 학습 데이터의 증가에 따라 성능이 8폴드 증가하다가 점차 감소하였다고 합니다.
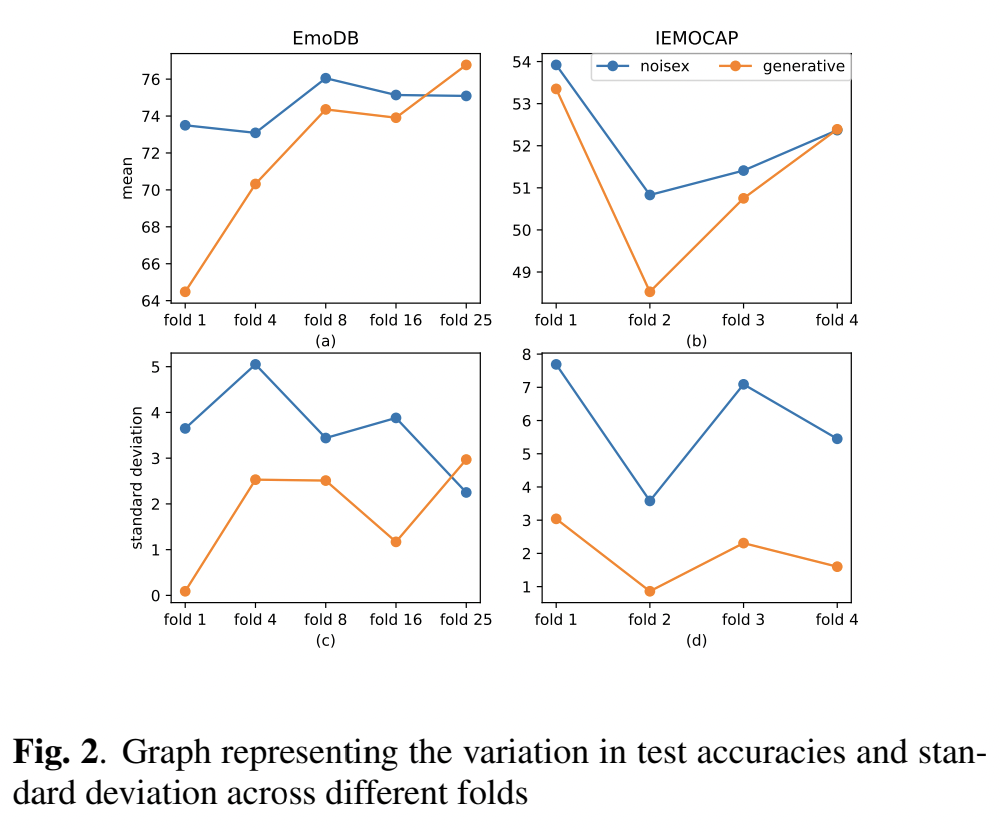
아래 테이블 1은 깨끗한 샘플로 훈련되고 노이즈가 많은 샘플에서 테스트된 모델의 정확성을 나타냅니다. 여기서 각 열은 해당 세트의 특정 노이즈 유형에 대한 결과를 나타낸 것입니다.
주목해야하는 것은 소음이 심한 환경에서 테스트 하는 경우, 깨끗한 모델의 성능 저하를 발견하였다는 것입니다.
또한 표2와 3은 seen & unseen 모두에서 주어진 기법과 결과에 대해 얻은 SOTA를 보여주었다고 합니다. 표3과 같이 생성 노이즈 모델이 경우 setA, B가 unseen임에도 불구하고 노이즈를 잘 일반화하고 있음을 확인할 수 있습니다. 또한 EmoDB에서의 생성 모델이 달성한 성능은 기존 multi-conditioning 방식을 뛰어 넘지만, IEMOCAP에서는 두 가지 모두의 성능이 비슷하다고 할 수 있습니다.
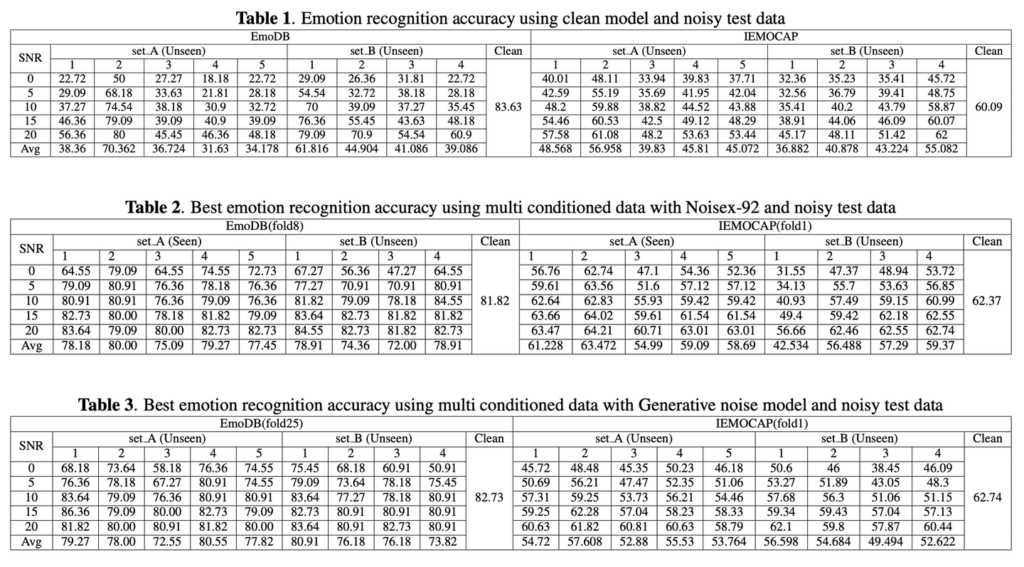
정리하자면, 해당 논문을 통해 감정인식의 평균 정확도는 EmoDB에서 46.72%에서 76.77%로, IEMOCAP에서 44.01%에서 53.35%로 향상되었습니다.
아무래도 음성 데이터가 익숙하지 않다보니 해당 논문을 이해하는 데 시간이 많이 필요해보입니다. 추가적인 공부를 통해 해당 리뷰를 더욱 상세하게 작성해보도록 하겠습니다.
안녕하세요. 좋은 리뷰 감사합니다.
1) generative noise model로 생성한 노이즈 샘플 n(t)는 TFB 필터를 태운 뒤 선형결합으로 생성된다고 적혀있는데, 이때 TFB 필터를 태운 뒤 나온 결과물은 spectrum 일까요?
2) 노이즈 생성 모델 그림을 보면 역푸리에 변환 하기 때문에 노이즈 샘플n(t)가 wave data라고 생각되는데 제 생각이 맞는지 궁금합니다