제가 이번에 리뷰 할 논문은 카메라 센서(Visual 정보)와 IMU 센서(Inertial 정보)를 활용하여 움직임의 변화 정도를 측정하는 task인 VIO(visual-inertial odometry) 논문으로 ECCV 2022에 제출되었다고 합니다.
딥러닝 기반의 VIO는 연산량이 많고, 에너지 사용량이 많기 때문에 실제로 활용하기에는 어려움이 있다고 합니다. 저자들은 영상 정보가 데이터 처리 비용이 IMU 데이터보다 많이 들지만, 시각 정보가 항상 도움이 되는 것은 아니라고 주장하며, 포즈 정확도를 높이기 위해 adaptive 하게 시각 정보를 활용하는 방식을 제안하였습니다. policy network를 학습하여 현재 상태와 IMU 값을 기반으로 시각 feature 추출을 비활성화시킬지 결정하도록 하며, 이때 policy 네트워크는 end-to-end로 학습하였다고 합니다.
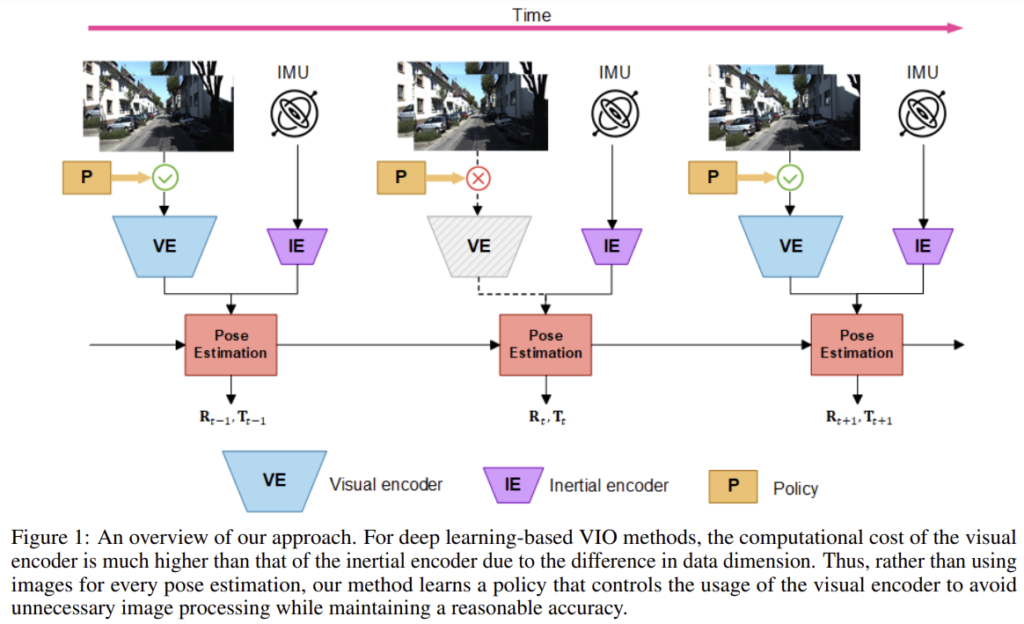
위의 그림이 이 논문의 전체적인 파이프라인입니다. policy network를 통해 시각 센서 정보를 사용할 지 결정합니다. 이때 높은 차원의 이미지와 다르게 IMU센서는 낮은 차원의 인코더를 이용하므로, IMU 센서는 항상 사용합니다. 이미지 처리 과정을 생략함으로써 연산량을 줄이고 에너지를 덜 사용할 수 있었다 합니다. 또한, 저자들에 따르면, 시각 센서가 연산량에 비해 정확도에 항상 좋은 결과를 가져오지는 않는다고 합니다.
해당 논문의 contribution을 정리하면 다음과 같습니다.
- 시각 정보를 adaptive하게 활용하여 연산량과 에너지 사용량을 줄이는 새로운 딥러닝 기반의 VIO 시스템을 제안
- pose 추정과 policy(시각 정보를 활용할 지 결정하는 네트워크) 네트워크를 함께 end-to-end로 학습
(end-to-end 학습을 위해 Gumbel-Softmax라는 트릭을 이용함) - KITTI Odometry 데이터셋에 대해 두드러지는 성능 저하 없이 최대 78.8%의 연산량을 줄임.
또한 policy네트워크는 해석 가능하고 패턴에 적응할 수 있음을 확인
Method
비디오 프레임을 \left\{ V_i \right\}^N_{i=1} , IMU 측정값을 \left\{ I_i \right\}^{Nl}_{i=1} 라 할 때 frequency l은 비디오 프레임 속도보다 빠르며 P_tT_{t→t+1} = P_{t+1}일 때 V_{t→t+1} = \left\{ V_t, V_{t+1} \right\}이고 I_{t→t+1} = \left\{ I_{tl}, I_{(t+1)l} \right\}이 됩니다. (즉, 두 프레임의 이미지 사이의 변화를 측정할 동안 IMU데이터는 훨씬 많은 데이터를 얻는다고 이해하시면 됩니다.)
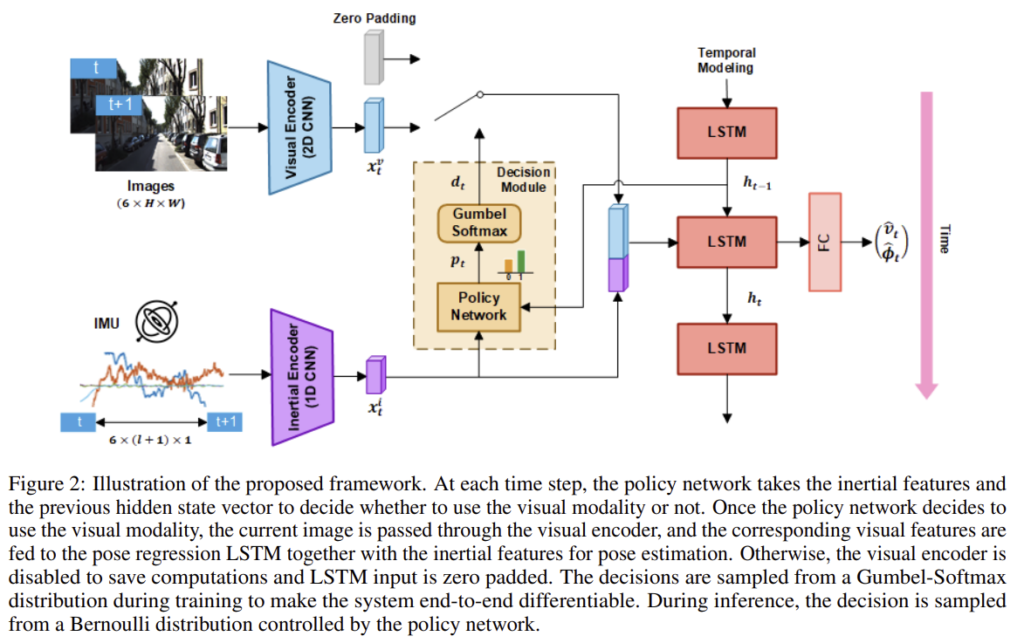
1. End-to-end neural visual-inertial odometry
end-to-end의 VIO 방식은 시각 정보의 encoder인 E_{visual}과 inertial 정보의 encoder인 E_{inertial}로부터 feature를 추출합니다.
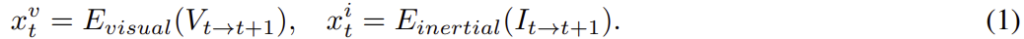
두 feature가 합쳐져(concat이나 attention 방식으로) z_t가 되고, 정확한 포즈 추정을 위해 이전 프레임에서 추정한 pose값이 함께 사용됩니다. 이러한 시간적으로 연속적이라는 특성을 위해 RNN을 이용하여 상관 관계를 학습합니다.

2. Deep VIO with visual modality selection
앞서 언급한 내용처럼, 시각 도메인이 많은 처리 비용이 들고, 항상 성능을 향상시키지 않기 때문에 시각 정보를 사용할지를 결정하는 decision module가 제안되었습니다. 결정 d_t는 베르누이 분포(이항분포)로 가벼운 policy network Φ의 확률값에 의해 결정됩니다.

이때 d_t∈\left\{0,1\right\}는 Gumbel-Softmax연산자를 이용하여 결정이 됩니다. d_t=0일 경우 영상 정보는 모두 0의값을 갖게 되고, d_t=1일 경우는 입력 이미지가 그대로 사용됩니다. 또한 여기서는 두 feature를 결합할 때 concat 방식을 이용하였습니다.
3. Training with Gumbel-Softmax
위에서 언급한 대로, 이항 분포는 미분 불가능하여 학습을 하기 어렵고, 따라서 Gumbel-Softmax를 이용하여 역전파가 가능하도록 하였다고 합니다. Gumbel-Softmax를 이용하는 것은 범주형 분포를 reparameter화 하는 트릭이라고 합니다.
** Gumbel-Softmax?
k_{th} 카테고리의 확률이 p_k(k=1,2,...,K)라 할 때 Gumbel Max 트릭을 이용하여 target 분포를 따르는 이산 표본 \hat{P}다음과 같이 나타낼 수 있다고 합니다.
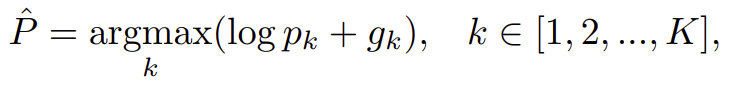
이때 g_k = -log(-log U_k)는 균일한 분포 U(0,1)로부터 랜덤 변수 U_k를 추출한 표준 Gumbel 분포라고 합니다.
여기에 미분 가능하도록 softmax 함수를 적용하여 얻은 아래와 같은 식을 Gumbel-Softmax라고 한다고 합니다.
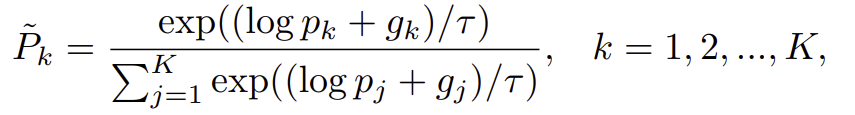
4. Loss function
MSE loss를 학습에 이용하여 pose 추정값의 정확도를 높이도록 학습을 하였다고 합니다.
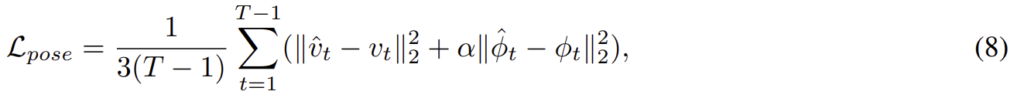
이때 T는 학습 시퀀스의 길이, v_t와 φ_t는 GT 변환,회전 벡터를 의미하며 α는 변환 및 회전 loss의 가중치를 의미하고 이 논문에서는 α를 100으로 설정하였다고 합니다.(다른 VIO, VO 논문들에서 설정한 값을 따라 사용한 것이라 합니다.)
게다가 visual encoder를 비활성화 할 수 있도록 학습하기 위해 visual encoder에 추가적인 페널티를 주었다고 합니다.

위의 두 loss, 식(8)과 식(9)를 합하여 최종 loss를 구하고 end-to-end로 학습을 수행한다고 합니다.
Experiments
Dataset
- KITTI Odometry 데이터 셋을 이용하여 해당 방법론을 평가
- 22개의 stereo 시퀀스로 구성되어 시퀀스 0~10은 GT 궤적을 포함하고, 11~22는 평가를 위해 GT궤적을 제외
- 시퀀스 00, 01, 02, 04, 06, 08, 09로 모델 학습, 시퀀스 05, 07, 10으로 테스트 진행
- 영상 데이터는 10Hz, IMU 데이터는 100Hz로 기록
- IMU와 영상 데이터가 완벽하게 동기화 되지는 않은 상태로, 누락된 IMU값은 이미지와 GT pose를 통해 보간
Metric
- RMSE를 이용하여 정확도 측정.
- 속도
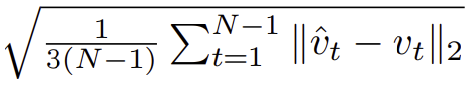
- 각도
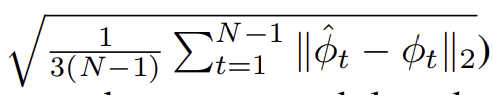
- 속도
- GFLOPS(giga floating-point operations per second)로 연산량 측정
Result
λ(visual encoder에 대한 페널티 factor) 조정
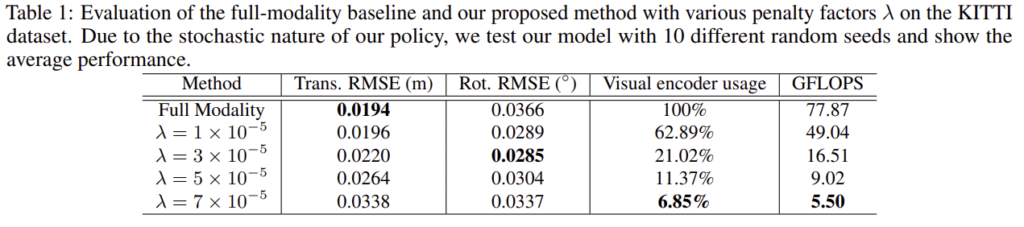
이 실험 결과를 통해 페널티 값이 커질 수 연산량이 줄어드는 것을 확인할 수 있고, translation에 대한 RMSE성능은 조금 악화되지만, rotation에 대한 RMSE의 경우 시각 정보를 일부 사용하지 않을 경우 성능이 더 향상되는 것을 확인하였다.
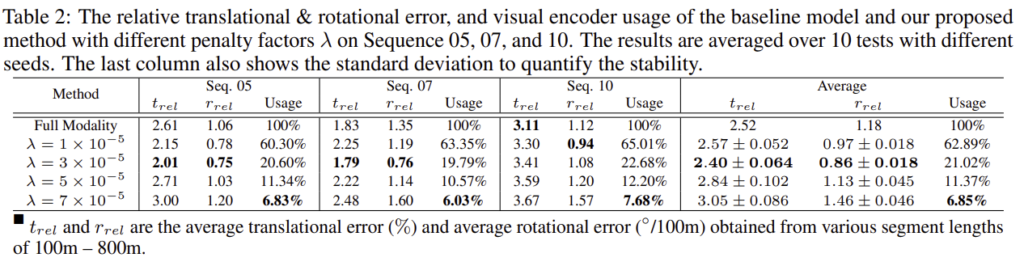
또한 상대 translation & rotation error를 확인해본 결과 시각적 encoder에 페널티를 준 경우 λ=3x10^{-5}에서 가장 좋은 성능을 보였으며, 표준편차를 통해 저자들이 제안한 방식이 안정적임을 보였다고 합니다.
시각 정보 사용을 결정하는 방식에 대한 ablation study
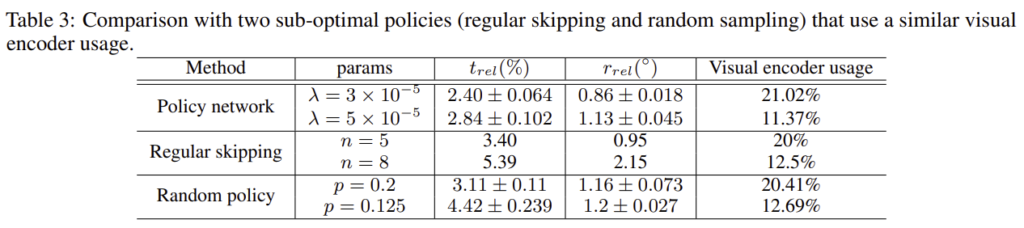
policy network가 저자들이 제안한 방식, ragular skipping은 일정 간격마다 사용하지 않는 방식, random policy는 랜덤하게 사용하지 않는 방식을 의미합니다.
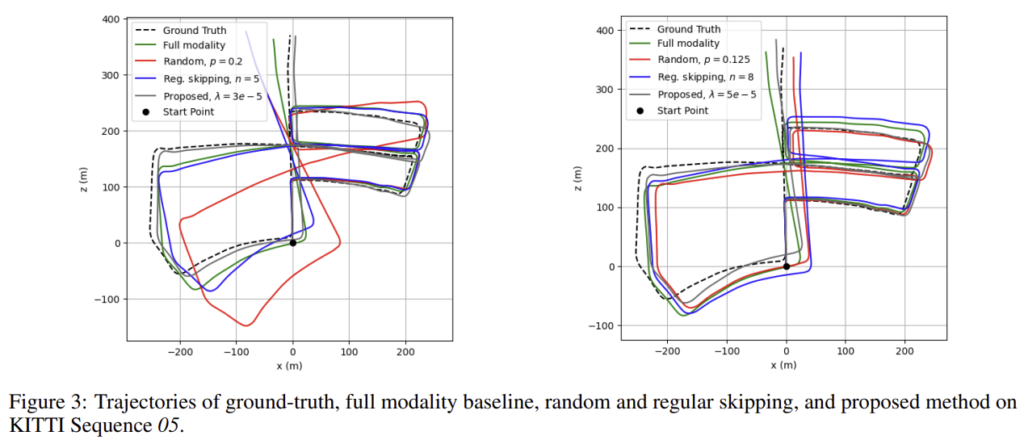
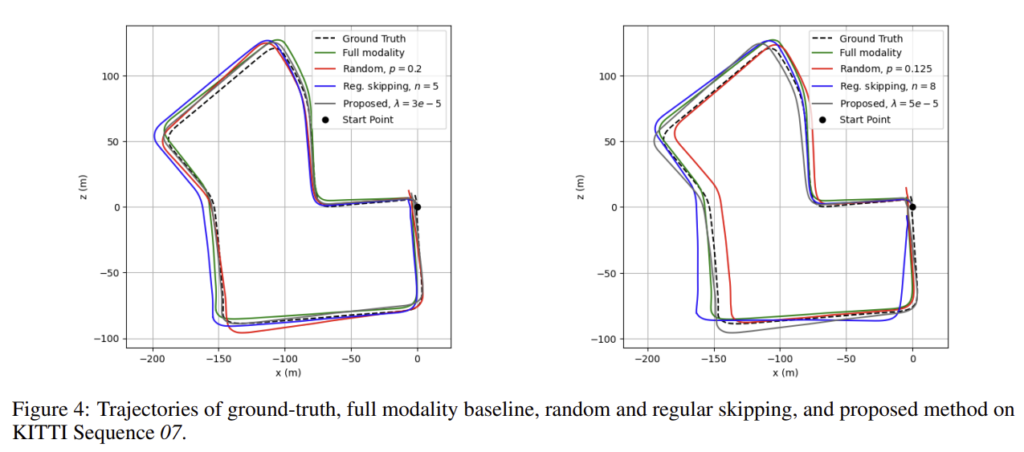
시퀀스 05와 07에 대한 궤적을 정성적으로 표현한 그림도 함께 있으며, 정성적, 정량적 결과를 통해 제안된 방식인 policy network를 이용하는 것이 가장 신뢰도 있는 결과를 가져온다는 것을 확인할 수 있습니다.
다양한 VO/VIO 베이스라인과의 성능 비교
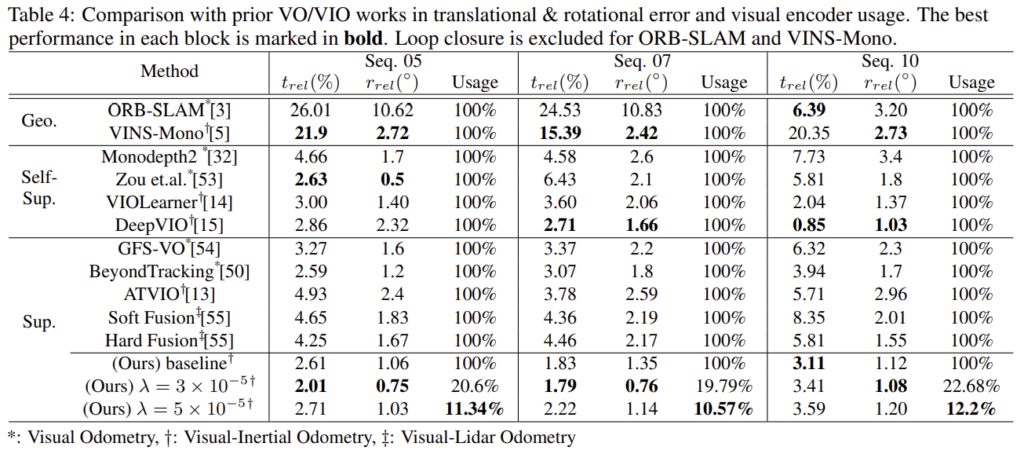
다른 방법론들과 비교했을 때 경쟁력 있는 성능을 기록하는 것을 볼 수 있으며(VIO의 SOTA방법론은 [14],[15]) 시퀀스 05와 07에서는 최대 성능을 달성하는 것을 볼 수 있습니다.
시퀀스 07을 이용한 Policy에 대한 해석
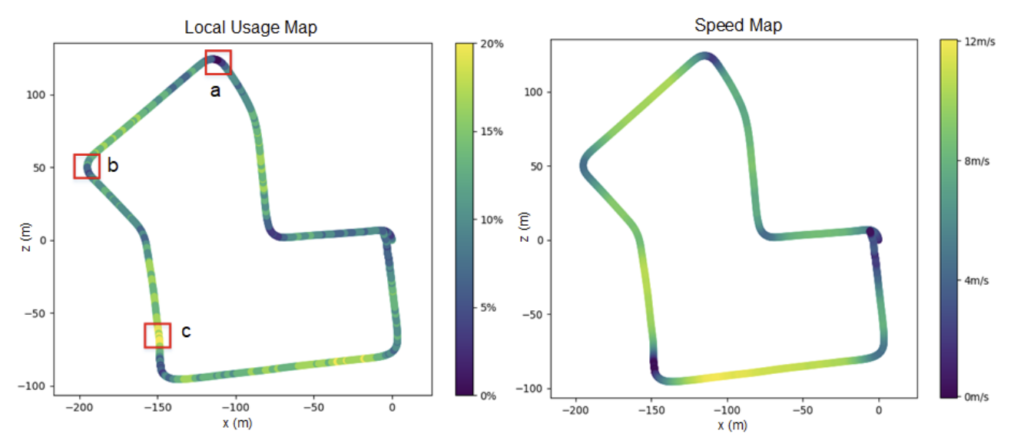
그림 5의 좌상단 이미지는 시각 정보를 사용하는 비율을, 우상단은 속도 정보를 나타냅니다. 둘을 비교해보시면 속도 및 가속도와 상관 관계가 있는 것을 확인하실 수 있습니다. 분석 결과 속도가 느리거나 방향 전환이 있을 경우는 시각 정보를 조금 사용하며 빠르고 직진을 할 경우에는 시각 정보를 많이 사용하는 것을 확인할 수 있다고 합니다.
시각 정보 사용률을 줄인다는 것이 조금 아쉽긴 하지만 그림5를 보면 센서 데이터와 차량의 변화 정보가 상관 관계가 있다는 것이 흥미로웠고, 반대로 IMU센서의 활용도를 조절할 경우 어떤 결과가 나오는 지 궁금합니다.
안녕하세요
policy를 통한 해석의 경우 다른 방법론과의 비교분석이 필요하지 않은지가 궁금합니다.
지금은 제안하는 방법론에 대해서만 분석을 진행하였는데 기존 퓨전 방법론도 비슷한 경향을 보일까요?
좋은 리뷰 감사합니다
다른 방법론도 각 센서의 가중치가 얼마나 활용되는지를 분석하여 센서와의 상관 관계를 제시하였다면 시각 정보를 선택적으로 사용하는 방법론이 연산의 효율 뿐만이 아니라 정확도 측면에서도 도움이 된다는 점의 설득력을 높일 수 있었을 것이라는 생각이 듭니다.
이 논문은 연산량 측면에서 시각 정보의 사용을 줄이고자 한다는 주장을 하기 때문에 다른 방법론과의 비교를 하지 않은 것 같습니다. 대신 시각 정보의 사용을 줄여도 성능이 크게 하락하지 않고, 더 좋은 경우도 있음을 보이는 방향으로 저자들의 주장을 뒷받침 한 것으로 보입니다.
또한 기존의 퓨전 방법론도 비슷한 경향을 보일 것인지 질문을 주셨는데 이에 대해서는 명확하게 말씀드리기 어렵네요… 다만 해당 방법론의 경우는 시각 정보를 사용하는 것에 대해서도 패널티를 주기 때문에 기존의 방법론과 차이가 있을 것으로 판단이 됩니다. 더 알아보고 실험도 해보고 말씀드리도록 하겠습니다..